







使用过的mysql中sql的函数整理
一、部分函数整理:
-
获取字段中某个字符后的内容,比如获取最后一个“,”之后的所有内容
substring_index( “字段”, ‘,’, - 1 ) -
格式化为年月日
DATE_FORMAT( “时间字段”, ‘%Y-%m-%d’ ) -
拼接多个字段
CONCAT(“字段1” ,“-”, “字段2”) -
计算两个日期的差值 ,单位可为day、hour、minute等 可以自行在搜索一下
TIMESTAMPDIFF(“单位”,“开始时间”,“结束时间”) -
字段替换
replace(“字段”,“要替换的内容”,“替换内容”) -
保留两位小数
CONVERT(“字段”,DECIMAL(10,2)) -
这个可以解决需要满足整个list条件 但不能用in的函数,把某个状态字段,拼接成一个字段
GROUP_CONCAT(“字段”) -
查询昨天之前的数据
DATEDIFF(n.update_time,NOW()) <=-1 -
也是查询昨天之前的数据 可看下DATE_SUB()函数的用法
DATE_FORMAT(n.update_time,‘%Y-%m-%d’) <= DATE_FORMAT(DATE_SUB(now(), INTERVAL 1 DAY),‘%Y-%m-%d’)
带有业务解释(或示例)的函数
-
返回参数中的第一个非NULL值。如果所有参数都为NULL,那么它将返回NULL。
COALESCE(“字段1”,“字段2”,…)
业务中我是用来比较一个商品是否有活动价格,有,返回活动价格,无,返回原价格 -
RANK() 是字段排名,分配排名给每一行,相同值的行会获得相同的排名,后续排名会跳过。排名有可能不连续。如:
SELECT
id,
NAME,
RANK() OVER ( ORDER BY name ASC ) AS rn
FROM
tbl_goods
WHERE
shop_id = 3271;
这里根据name排序 因为name会有重复就会出现同等名次(这里类比考试分数排名),排名不连续
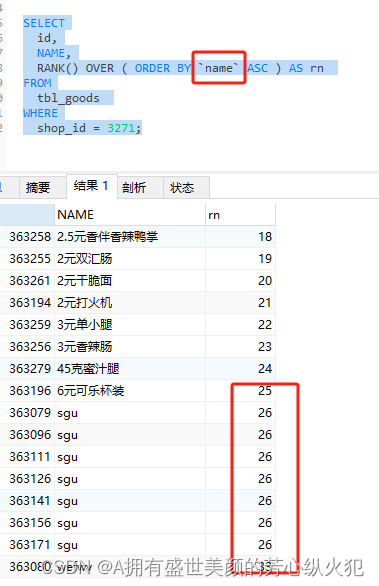
-
DENSE_RANK(): 类似于RANK(),但没有跳跃的排名。相同值的行会获得相同的排名,但后续排名是连续的。
这里也展示下name相同的排名
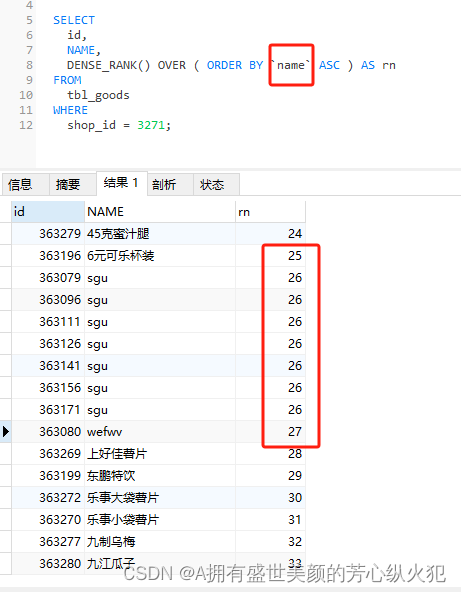
-
返回各门店(数据是到门店下的员工,所以PARTITION BY不仅有主键,还有人员工号)最新一天的消息数据之和,这里消息数据是一个统计值——即截止当前门店(人员)消息总数,所以需要先以门店码,员工号分类后,再根据时间倒序排名,取排名=1的值求和
SELECT
latest.shop_name AS shopName,
SUM( latest.msg_total ) AS groupMessagesCount
FROM
(
SELECT
主键,
shop_name,
msg_total,
ROW_NUMBER() OVER (PARTITION BY 主键,工号 ORDER BY dt_date DESC) AS rn
FROM
XXX_table
<where>
dt_date <![CDATA[ <= ]]> CURDATE()
</where>
) latest
WHERE
latest.rn = 1


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









