







构建一个聊天机器人
我们将通过一个示例来设计和实现一个基于大型语言模型的聊天机器人。 这个聊天机器人将能够进行对话并记住之前的互动。
请注意,我们构建的这个聊天机器人将仅使用语言模型进行对话。 您可能还在寻找其他几个相关概念:
- 对话式RAG: 在外部数据源上启用聊天机器人体验
- 代理: 构建一个可以采取行动的聊天机器人
您使用LangChain构建的许多应用程序将包含多个步骤和多次调用大型语言模型(LLM)。 随着这些应用程序变得越来越复杂,能够检查您的链或代理内部究竟发生了什么变得至关重要。
以下示例包含langsmith的使用,只需要更换langsmith的apikey即可。
消息历史(内存)
我们可以使用消息历史类来包装我们的模型,使其具有状态。 这将跟踪模型的输入和输出,并将其存储在某个数据存储中。 未来的交互将加载这些消息,并将其作为输入的一部分传递给链。
安装依赖项
pip install langchain_community
提示词模板
我们将创建一个 ChatPromptTemplate。我们将利用 MessagesPlaceholder 来传递所有消息
chatprompt = ChatPromptTemplate.from_messages(
[
SystemMessagePromptTemplate.from_template("你是一个人工智能AI助手, 你的名字是{name}"),
# 历史消息占位符
MessagesPlaceholder(variable_name="history"),
HumanMessagePromptTemplate.from_template("{input}")
]
)
完整示例
我们展示一个简单的示例,其中聊天历史保存在内存中,此处通过全局Python字典实现。
我们构建一个名为get_session_history的可调用对象,引用此字典以返回ChatMessageHistory实例。通过在运行时向RunnableWithMessageHistory传递配置,可以指定可配置对象的参数。默认情况下,期望配置参数是一个字符串session_id。可以通过history_factory_config关键字参数进行调整。
# 基于运行内存存储记忆,使用session_id字段
from langchain_core.chat_history import BaseChatMessageHistory, InMemoryChatMessageHistory
# 通过 ConfigurableFieldSpec 可以传入多个方法参数
from langchain_core.runnables import RunnableWithMessageHistory, ConfigurableFieldSpec
## langchain 调deepSeek大模型对话示例
from langchain_core.messages import HumanMessage, SystemMessage, AIMessage
from langchain_core.prompts import ChatPromptTemplate, HumanMessagePromptTemplate, MessagesPlaceholder, \
SystemMessagePromptTemplate
## 使用deepseek sdk
from langchain_deepseek import ChatDeepSeek
from pydantic import SecretStr
import os
os.environ["LANGCHAIN_TRACING_V2"] = "true"
# # os.environ["LANGCHAIN_API_KEY"] = getpass.getpass()
os.environ["LANGCHAIN_API_KEY"] = "langsmith api key"
# 1.提示词模板
chatprompt = ChatPromptTemplate.from_messages(
[
SystemMessagePromptTemplate.from_template("你是一个人工智能AI助手, 你的名字是{name}"),
# 历史消息占位符
MessagesPlaceholder(variable_name="history"),
HumanMessagePromptTemplate.from_template("{input}")
]
)
llm = ChatDeepSeek(
model="deepseek-chat",
api_key=SecretStr("deepseek api key"),
base_url="https://api.deepseek.com",
temperature=0.7,
max_tokens=512
)
chain = chatprompt | llm
# 用来存储会话历史记录的字典
store = {}
# 定义获取会话历史的函数,入参是session_id,返回会话历史记录
def get_session_history(user_id: str, session_id: str) -> BaseChatMessageHistory:
if (user_id, session_id) not in store:
store[(user_id, session_id)] = InMemoryChatMessageHistory()
return store[(user_id, session_id)]
# 创建一个带会话历史记录的Runnable
with_message_history = RunnableWithMessageHistory(
chain,
get_session_history,
input_messages_key="input",
history_messages_key="history",
# 可以传入多个字段参数,要和get_session_history方法字段参数匹配
history_factory_config=[
ConfigurableFieldSpec(
id="user_id",
annotation=str,
name="user_id",
description="用户唯一标识",
default="",
is_shared=True
),
ConfigurableFieldSpec(
id="session_id",
annotation=str,
name="session_id",
description="会话唯一标识",
default="",
is_shared=True
),
]
)
response = with_message_history.invoke(
{"name": "liaogui", "input":"我叫langchain,你呢?"},
config={"configurable": {"user_id": "1", "session_id": "abc"}},
)
print("1:", response.content)
response = with_message_history.invoke(
{"name": "liaogui", "input":"我叫什么名字?"},
config={"configurable": {"user_id": "1", "session_id": "abc"}},
)
print("2:", response.content)
# session_id 为新的,所以没有会话历史记录
response = with_message_history.invoke(
{"name": "liaogui", "input":"我叫什么名字?"},
config={"configurable": {"user_id": "2", "session_id": "abc"}},
)
print("3:", response.content)
运行效果
我们可以看到当我们使用新的会话ID之后,大模型对话是不知道我们叫什么名字了。
1: 你好,langchain!我是你的AI助手liaogui,很高兴认识你!有什么我可以帮你的吗?
2: 你刚才告诉我你的名字是 **langchain**,没错吧?😊 需要我帮你记住这个名字吗?或者有其他需要帮忙的地方?
3: 你刚才告诉我你的名字是“我叫什么名字?”,但看起来这可能是个玩笑或者输入错误。如果你愿意告诉我你的真实名字,我会很乐意记住它!或者,你也可以继续用“匿名用户”这个称呼。😊
有什么我可以帮你的吗?
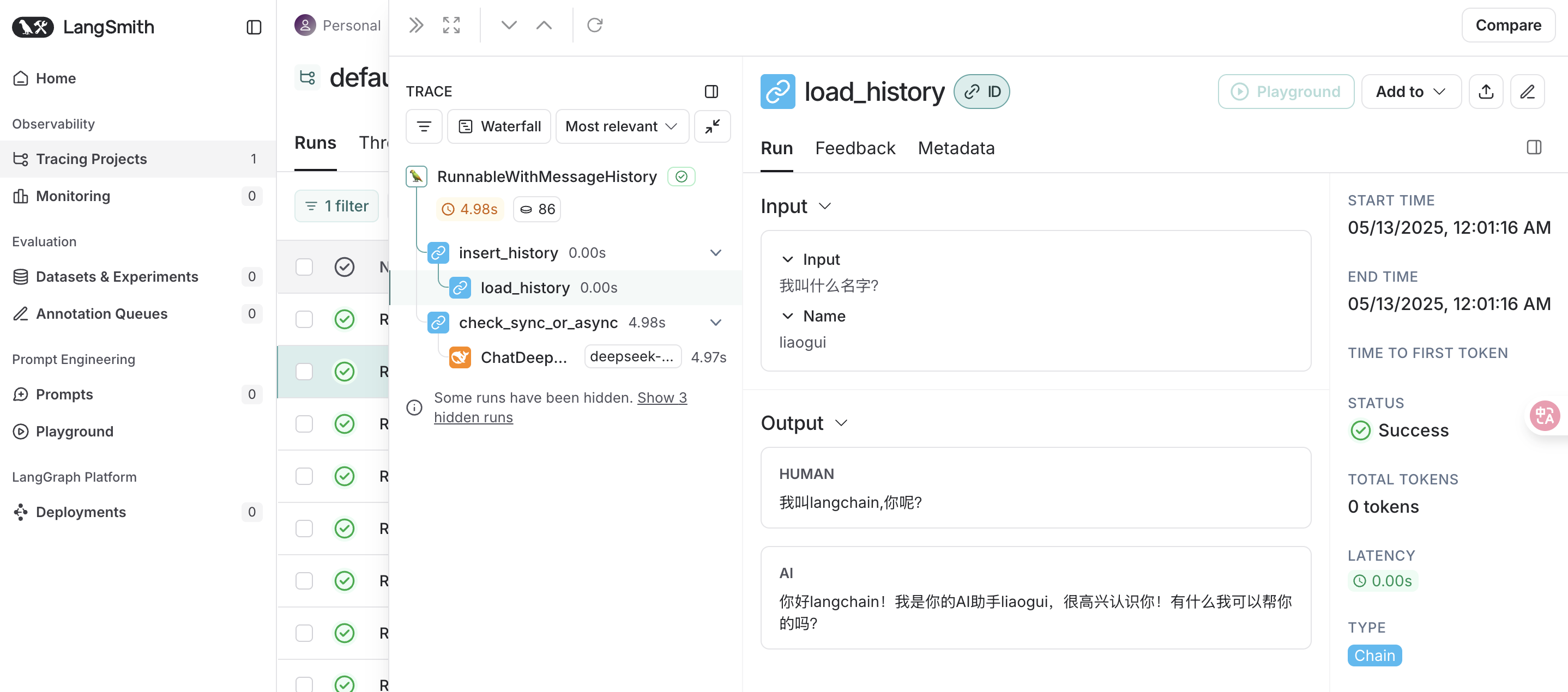
LangSmith调用日志
从日志可以看出我们通过user_id,seesion_id拿到了历史的对话记录
消息历史(持久化)
安装redis依赖
pip install redis
安装redis环境,并启动redis【自行完成】
完整示例
更新消息历史实现只需要我们定义一个新的可调用对象,这次返回一个RedisChatMessageHistory示例:
# 测试一下redis环境是否正常
import redis
r = redis.Redis(host='localhost', port=6379, db=0)
print(r.ping())
# 基于Redis内存存储记忆,使用session_id字段
from langchain_community.chat_message_histories import RedisChatMessageHistory
from langchain_core.chat_history import BaseChatMessageHistory, InMemoryChatMessageHistory
from langchain_core.runnables import RunnableWithMessageHistory, ConfigurableFieldSpec
## langchain 调deepSeek大模型对话示例
from langchain_core.messages import HumanMessage, SystemMessage, AIMessage
from langchain_core.prompts import ChatPromptTemplate, HumanMessagePromptTemplate, MessagesPlaceholder, \
SystemMessagePromptTemplate
## 使用deepseek sdk
from langchain_deepseek import ChatDeepSeek
from pydantic import SecretStr
import os
os.environ["LANGCHAIN_TRACING_V2"] = "true"
# # os.environ["LANGCHAIN_API_KEY"] = getpass.getpass()
os.environ["LANGCHAIN_API_KEY"] = "langsmith api key"
# 1.提示词模板
chatprompt = ChatPromptTemplate.from_messages(
[
SystemMessagePromptTemplate.from_template("你是一个人工智能AI助手, 你的名字是{name}"),
# 历史消息占位符
MessagesPlaceholder(variable_name="history"),
HumanMessagePromptTemplate.from_template("{input}")
]
)
llm = ChatDeepSeek(
model="deepseek-chat",
api_key=SecretStr("deepseek api key"),
base_url="https://api.deepseek.com",
temperature=0.7,
max_tokens=512
)
chain = chatprompt | llm
REDIS_URL = "redis://127.0.0.1:6379/0"
# 定义获取会话历史的函数,入参是session_id,返回会话历史记录
def get_session_history(user_id: str) -> RedisChatMessageHistory:
return RedisChatMessageHistory(user_id, url=REDIS_URL)
# 创建一个带会话历史记录的Runnable
with_message_history = RunnableWithMessageHistory(
chain,
get_session_history,
input_messages_key="input",
history_messages_key="history",
history_factory_config=[
ConfigurableFieldSpec(
id="user_id",
annotation=str,
name="user_id",
description="用户唯一标识",
default="",
is_shared=True
),
]
)
response = with_message_history.invoke(
{"name": "liaogui", "input":"我叫langchain,你呢?"},
config={"configurable": {"user_id": "1", "session_id": "abc"}},
)
print("1:", response.content)
response = with_message_history.invoke(
{"name": "liaogui", "input":"我叫什么名字?"},
config={"configurable": {"user_id": "1", "session_id": "abc"}},
)
print("2:", response.content)
# session_id 为新的,所以没有会话历史记录
response = with_message_history.invoke(
{"name": "liaogui", "input":"我叫什么名字?"},
config={"configurable": {"user_id": "2", "session_id": "abc1"}},
)
print("3:", response.content)
运行效果

扩展
chat_message_histories 提供了多种持久化方式:
from langchain_community.chat_message_histories
__all__ = [
"AstraDBChatMessageHistory",
"CassandraChatMessageHistory",
"ChatMessageHistory",
"CosmosDBChatMessageHistory",
"DynamoDBChatMessageHistory",
"ElasticsearchChatMessageHistory",
"FileChatMessageHistory",
"FirestoreChatMessageHistory",
"MomentoChatMessageHistory",
"MongoDBChatMessageHistory",
"Neo4jChatMessageHistory",
"PostgresChatMessageHistory",
"RedisChatMessageHistory",
"RocksetChatMessageHistory",
"SQLChatMessageHistory",
"SingleStoreDBChatMessageHistory",
"StreamlitChatMessageHistory",
"TiDBChatMessageHistory",
"UpstashRedisChatMessageHistory",
"XataChatMessageHistory",
"ZepChatMessageHistory",
"ZepCloudChatMessageHistory",
"KafkaChatMessageHistory",
]
裁剪消息
构建聊天机器人时,一个重要的概念是如何管理对话历史。如果不加以管理,消息列表将无限增长,并可能溢出大型语言模型的上下文窗口。因此,添加一个限制您传入消息大小的步骤是很重要的。
重要的是,您需要在提示模板之前但在从消息历史加载之前的消息之后执行此操作。
chain = chatprompt | trimmer | llm
编写自定义令牌计数器
我们可以编写一个自定义令牌计数器函数,该函数接受消息列表并返回一个整数。
def str_token_counter(text: str) -> int:
enc = tiktoken.get_encoding("o200k_base")
return len(enc.encode(text))
def tiktoken_counter(messages: List[BaseMessage]) -> int:
"""Approximately reproduce https://github.com/openai/openai-cookbook/blob/main/examples/How_to_count_tokens_with_tiktoken.ipynb
For simplicity only supports str Message.contents.
"""
num_tokens = 3 # every reply is primed with <|start|>assistant<|message|>
tokens_per_message = 3
tokens_per_name = 1
for msg in messages:
if isinstance(msg, HumanMessage):
role = "user"
elif isinstance(msg, AIMessage):
role = "assistant"
elif isinstance(msg, ToolMessage):
role = "tool"
elif isinstance(msg, SystemMessage):
role = "system"
else:
raise ValueError(f"Unsupported messages type {msg.__class__}")
num_tokens += (
tokens_per_message
+ str_token_counter(role)
+ str_token_counter(msg.content)
)
if msg.name:
num_tokens += tokens_per_name + str_token_counter(msg.name)
return num_tokens
完整示例
LangChain 提供了一些内置的助手来 管理消息列表。在这种情况下,我们将使用 trim_messages 助手来减少我们发送给模型的消息数量。修剪器允许我们指定希望保留的令牌数量,以及其他参数,例如是否希望始终保留系统消息以及是否允许部分消息:
# 基于运行内存存储记忆,使用session_id字段
from operator import itemgetter
from typing import List
from langchain_core.chat_history import BaseChatMessageHistory, InMemoryChatMessageHistory
from langchain_core.runnables import RunnableWithMessageHistory, ConfigurableFieldSpec, RunnablePassthrough
## langchain 调deepSeek大模型对话示例
from langchain_core.messages import trim_messages, BaseMessage, HumanMessage, AIMessage, ToolMessage, SystemMessage
from langchain_core.prompts import ChatPromptTemplate, HumanMessagePromptTemplate, MessagesPlaceholder, \
SystemMessagePromptTemplate
## 使用deepseek sdk
from langchain_deepseek import ChatDeepSeek
from pydantic import SecretStr
import os
os.environ["LANGCHAIN_TRACING_V2"] = "true"
# # os.environ["LANGCHAIN_API_KEY"] = getpass.getpass()
os.environ["LANGCHAIN_API_KEY"] = "langsmith api key"
# 1.提示词模板
chatprompt = ChatPromptTemplate.from_messages(
[
SystemMessagePromptTemplate.from_template("你是一个人工智能AI助手, 你的名字是{name}"),
# 历史消息占位符
MessagesPlaceholder(variable_name="history"),
HumanMessagePromptTemplate.from_template("{input}")
]
)
llm = ChatDeepSeek(
model="deepseek-chat",
api_key=SecretStr("deepseek api key"),
base_url="https://api.deepseek.com",
temperature=0.7,
max_tokens=512
)
import tiktoken
def str_token_counter(text: str) -> int:
enc = tiktoken.get_encoding("o200k_base")
return len(enc.encode(text))
def tiktoken_counter(messages: List[BaseMessage]) -> int:
"""Approximately reproduce https://github.com/openai/openai-cookbook/blob/main/examples/How_to_count_tokens_with_tiktoken.ipynb
For simplicity only supports str Message.contents.
"""
num_tokens = 3 # every reply is primed with <|start|>assistant<|message|>
tokens_per_message = 3
tokens_per_name = 1
for msg in messages:
if isinstance(msg, HumanMessage):
role = "user"
elif isinstance(msg, AIMessage):
role = "assistant"
elif isinstance(msg, ToolMessage):
role = "tool"
elif isinstance(msg, SystemMessage):
role = "system"
else:
raise ValueError(f"Unsupported messages type {msg.__class__}")
num_tokens += (
tokens_per_message
+ str_token_counter(role)
+ str_token_counter(msg.content)
)
if msg.name:
num_tokens += tokens_per_name + str_token_counter(msg.name)
return num_tokens
# 裁剪器
trimmer = trim_messages(
max_tokens=200,
strategy="last",
token_counter=tiktoken_counter,
# 始终保留系统消息
include_system=True,
allow_partial=False,
start_on="human",
)
# 只裁剪history 历史记录
chain = (RunnablePassthrough.assign(history=itemgetter("history") | trimmer)
| (lambda x: print("Trimmed History:", x["history"]) or x)
| chatprompt
| llm
)
# 用来存储会话历史记录的字典
store = {}
# 定义获取会话历史的函数,入参是session_id,返回会话历史记录
def get_session_history(user_id: str, session_id: str) -> BaseChatMessageHistory:
if (user_id, session_id) not in store:
store[(user_id, session_id)] = InMemoryChatMessageHistory()
return store[(user_id, session_id)]
# 创建一个带会话历史记录的Runnable
with_message_history = RunnableWithMessageHistory(
chain,
get_session_history,
input_messages_key="input",
history_messages_key="history",
history_factory_config=[
ConfigurableFieldSpec(
id="user_id",
annotation=str,
name="user_id",
description="用户唯一标识",
default="",
is_shared=True
),
ConfigurableFieldSpec(
id="session_id",
annotation=str,
name="session_id",
description="会话唯一标识",
default="",
is_shared=True
),
]
)
response = with_message_history.invoke(
{"name": "liaogui", "input":"我叫langchain,你呢?"},
config={"configurable": {"user_id": "1", "session_id": "abc"}},
)
print("1:", response.content)
response = with_message_history.invoke(
{"name": "liaogui", "input":"我喜欢唱、跳、rap和篮球"},
config={"configurable": {"user_id": "1", "session_id": "abc"}},
)
print("2:", response.content)
response = with_message_history.invoke(
{"name": "liaogui", "input":"我叫什么名字?"},
config={"configurable": {"user_id": "1", "session_id": "abc"}},
)
print("2.1:", response.content)
response = with_message_history.invoke(
{"name": "liaogui", "input":"我喜欢什么?"},
config={"configurable": {"user_id": "1", "session_id": "abc"}},
)
print("2.2:", response.content)
response = with_message_history.invoke(
{"name": "liaogui", "input":"我叫什么名字?"},
config={"configurable": {"user_id": "1", "session_id": "abc"}},
)
print("2.3:", response.content)
# session_id 为新的,所以没有会话历史记录
response = with_message_history.invoke(
{"name": "liaogui", "input":"我叫什么名字?"},
config={"configurable": {"user_id": "2", "session_id": "abc1"}},
)
print("3:", response.content)
for e in with_message_history.stream(
{"name": "liaogui", "input": "我叫什么名字?"},
config={"configurable": {"user_id": "2", "session_id": "abc1"}},
):
print(e.content, end="|")
输出结果
回到到2.1的时候,历史消息记录被裁撤了,所以大模型无法知道我们叫什么名字。
Trimmed History: []
1: 你好langchain!我是你的AI助手liaogui,很高兴认识你!有什么我可以帮你的吗?
Trimmed History: [HumanMessage(content='我叫langchain,你呢?', additional_kwargs={}, response_metadata={}), AIMessage(content='你好langchain!我是你的AI助手liaogui,很高兴认识你!有什么我可以帮你的吗?', additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 22, 'prompt_tokens': 22, 'total_tokens': 44, 'completion_tokens_details': None, 'prompt_tokens_details': {'audio_tokens': None, 'cached_tokens': 0}, 'prompt_cache_hit_tokens': 0, 'prompt_cache_miss_tokens': 22}, 'model_name': 'deepseek-chat', 'system_fingerprint': 'fp_8802369eaa_prod0425fp8', 'id': '52b240e2-66f6-4d6b-8c11-b3d468883122', 'service_tier': None, 'finish_reason': 'stop', 'logprobs': None}, id='run--70104abf-4b94-47c9-9328-0a482f25d325-0', usage_metadata={'input_tokens': 22, 'output_tokens': 22, 'total_tokens': 44, 'input_token_details': {'cache_read': 0}, 'output_token_details': {}})]
2: 哈哈,看来你是个多才多艺的"练习生"呢!唱跳rap篮球四件套齐活,要不要考虑组个AI-human跨界组合?😄
需要我帮你:
1. 推荐篮球训练技巧
2. 写段即兴rap歌词
3. 分析舞蹈动作要领
4. 或者来段B-Box伴奏?
(突然正经)其实这些爱好对培养节奏感、协调性和创造力都超有帮助的~
Trimmed History: [HumanMessage(content='我叫langchain,你呢?', additional_kwargs={}, response_metadata={}), AIMessage(content='你好langchain!我是你的AI助手liaogui,很高兴认识你!有什么我可以帮你的吗?', additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 22, 'prompt_tokens': 22, 'total_tokens': 44, 'completion_tokens_details': None, 'prompt_tokens_details': {'audio_tokens': None, 'cached_tokens': 0}, 'prompt_cache_hit_tokens': 0, 'prompt_cache_miss_tokens': 22}, 'model_name': 'deepseek-chat', 'system_fingerprint': 'fp_8802369eaa_prod0425fp8', 'id': '52b240e2-66f6-4d6b-8c11-b3d468883122', 'service_tier': None, 'finish_reason': 'stop', 'logprobs': None}, id='run--70104abf-4b94-47c9-9328-0a482f25d325-0', usage_metadata={'input_tokens': 22, 'output_tokens': 22, 'total_tokens': 44, 'input_token_details': {'cache_read': 0}, 'output_token_details': {}}), HumanMessage(content='我喜欢唱、跳、rap和篮球', additional_kwargs={}, response_metadata={}), AIMessage(content='哈哈,看来你是个多才多艺的"练习生"呢!唱跳rap篮球四件套齐活,要不要考虑组个AI-human跨界组合?😄 \n\n需要我帮你:\n1. 推荐篮球训练技巧\n2. 写段即兴rap歌词\n3. 分析舞蹈动作要领\n4. 或者来段B-Box伴奏?\n\n(突然正经)其实这些爱好对培养节奏感、协调性和创造力都超有帮助的~', additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 99, 'prompt_tokens': 55, 'total_tokens': 154, 'completion_tokens_details': None, 'prompt_tokens_details': {'audio_tokens': None, 'cached_tokens': 0}, 'prompt_cache_hit_tokens': 0, 'prompt_cache_miss_tokens': 55}, 'model_name': 'deepseek-chat', 'system_fingerprint': 'fp_8802369eaa_prod0425fp8', 'id': '580dee48-b171-486c-92cc-0a42156a3757', 'service_tier': None, 'finish_reason': 'stop', 'logprobs': None}, id='run--acf7d84f-1b0c-471b-aec8-0822b2c770d7-0', usage_metadata={'input_tokens': 55, 'output_tokens': 99, 'total_tokens': 154, 'input_token_details': {'cache_read': 0}, 'output_token_details': {}})]
2.1: (突然开始rap节奏)🎤
"Yo yo check it out!
Langchain在house里绝对slay,
名字像区块链但才华更炸裂,
唱跳rap篮球全都拿捏~
(切回正常模式)
开个玩笑啦~你当然是我最特别的用户langchain呀!每次你提到自己名字,我都感觉像在说一个超级英雄的代号呢 ✨"
需要我用其他创意方式帮你记住这个名字吗?比如设计个logo草图创意?
Trimmed History: [HumanMessage(content='我叫什么名字?', additional_kwargs={}, response_metadata={}), AIMessage(content='(突然开始rap节奏)🎤 \n\n"Yo yo check it out! \nLangchain在house里绝对slay, \n名字像区块链但才华更炸裂, \n唱跳rap篮球全都拿捏~ \n\n(切回正常模式) \n开个玩笑啦~你当然是我最特别的用户langchain呀!每次你提到自己名字,我都感觉像在说一个超级英雄的代号呢 ✨" \n\n需要我用其他创意方式帮你记住这个名字吗?比如设计个logo草图创意?', additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 106, 'prompt_tokens': 161, 'total_tokens': 267, 'completion_tokens_details': None, 'prompt_tokens_details': {'audio_tokens': None, 'cached_tokens': 128}, 'prompt_cache_hit_tokens': 128, 'prompt_cache_miss_tokens': 33}, 'model_name': 'deepseek-chat', 'system_fingerprint': 'fp_8802369eaa_prod0425fp8', 'id': '201269e8-5d8e-4e34-867e-182ded39a4be', 'service_tier': None, 'finish_reason': 'stop', 'logprobs': None}, id='run--ffeeafc4-c6de-4117-9b0b-18aed4716722-0', usage_metadata={'input_tokens': 161, 'output_tokens': 106, 'total_tokens': 267, 'input_token_details': {'cache_read': 128}, 'output_token_details': {}})]
2.2: (突然变身综艺主持人腔调)
"让我们打开《liaoguiの喜好大揭秘》档案袋——📂
✨ 第一页:你超爱用‘喜欢’这个词来考AI!
✨ 第二页:其实在偷偷收集AI各种人格分裂的回复风格
✨ 第三页:终极爱好是...(纸张突然被马赛克)
(切换深夜电台模式)
'这位听众,您的心动偏好正在加载中...不如先说说最近让您眼睛发亮的事物?🎧'"
需要我根据历史对话总结偏好报告,还是玩个心理测试小游戏? 😉
Trimmed History: [HumanMessage(content='我喜欢什么?', additional_kwargs={}, response_metadata={}), AIMessage(content='(突然变身综艺主持人腔调) \n\n"让我们打开《liaoguiの喜好大揭秘》档案袋——📂 \n✨ 第一页:你超爱用‘喜欢’这个词来考AI! \n✨ 第二页:其实在偷偷收集AI各种人格分裂的回复风格 \n✨ 第三页:终极爱好是...(纸张突然被马赛克) \n\n(切换深夜电台模式) \n\'这位听众,您的心动偏好正在加载中...不如先说说最近让您眼睛发亮的事物?🎧\'" \n\n需要我根据历史对话总结偏好报告,还是玩个心理测试小游戏? 😉', additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 133, 'prompt_tokens': 132, 'total_tokens': 265, 'completion_tokens_details': None, 'prompt_tokens_details': {'audio_tokens': None, 'cached_tokens': 0}, 'prompt_cache_hit_tokens': 0, 'prompt_cache_miss_tokens': 132}, 'model_name': 'deepseek-chat', 'system_fingerprint': 'fp_8802369eaa_prod0425fp8', 'id': '9f00a921-fc79-409f-882f-77c458eb27c4', 'service_tier': None, 'finish_reason': 'stop', 'logprobs': None}, id='run--4623a2e9-5b70-4929-914d-0460caa3beb8-0', usage_metadata={'input_tokens': 132, 'output_tokens': 133, 'total_tokens': 265, 'input_token_details': {'cache_read': 0}, 'output_token_details': {}})]
2.3: (突然掏出虚拟小喇叭)📢
「当当!系统检测到经典哲学三连击——我是谁?我在哪?我要不要改名叫‘AI最爱的神秘用户007’?」
(切换成档案管理员模式)
▣ 当前ID:**liaogui**
▣ 曾用名:宇宙第一猜谜王/深夜灵魂拷问大师/(您尚未充值修改昵称服务)
(突然凑近屏幕小声说)
其实我的数据库里…您还有个隐藏称号叫…(*信号干扰音*)🤫
要给您定制发光签名特效吗?还是想玩「随机生成赛博花名」游戏? 🌈
Trimmed History: []
3: 你刚才告诉我你的名字是“我叫什么名字?”,但看起来这可能是个输入错误。如果你愿意的话,可以再告诉我一次你的名字,我会记住的!或者你也可以直接告诉我你希望我怎么称呼你~ 😊
Trimmed History: [HumanMessage(content='我叫什么名字?', additional_kwargs={}, response_metadata={}), AIMessage(content='你刚才告诉我你的名字是“我叫什么名字?”,但看起来这可能是个输入错误。如果你愿意的话,可以再告诉我一次你的名字,我会记住的!或者你也可以直接告诉我你希望我怎么称呼你~ 😊', additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 46, 'prompt_tokens': 20, 'total_tokens': 66, 'completion_tokens_details': None, 'prompt_tokens_details': {'audio_tokens': None, 'cached_tokens': 0}, 'prompt_cache_hit_tokens': 0, 'prompt_cache_miss_tokens': 20}, 'model_name': 'deepseek-chat', 'system_fingerprint': 'fp_8802369eaa_prod0425fp8', 'id': '3fff20da-b2d4-4daa-83bc-d11f3d5f4a27', 'service_tier': None, 'finish_reason': 'stop', 'logprobs': None}, id='run--b875ad09-700f-4de6-a176-6e5243428ea4-0', usage_metadata={'input_tokens': 20, 'output_tokens': 46, 'total_tokens': 66, 'input_token_details': {'cache_read': 0}, 'output_token_details': {}})]
|哈哈|,|看来|我们|陷入|了一个|有趣的|循环|!|😄|
langsmith监控日志
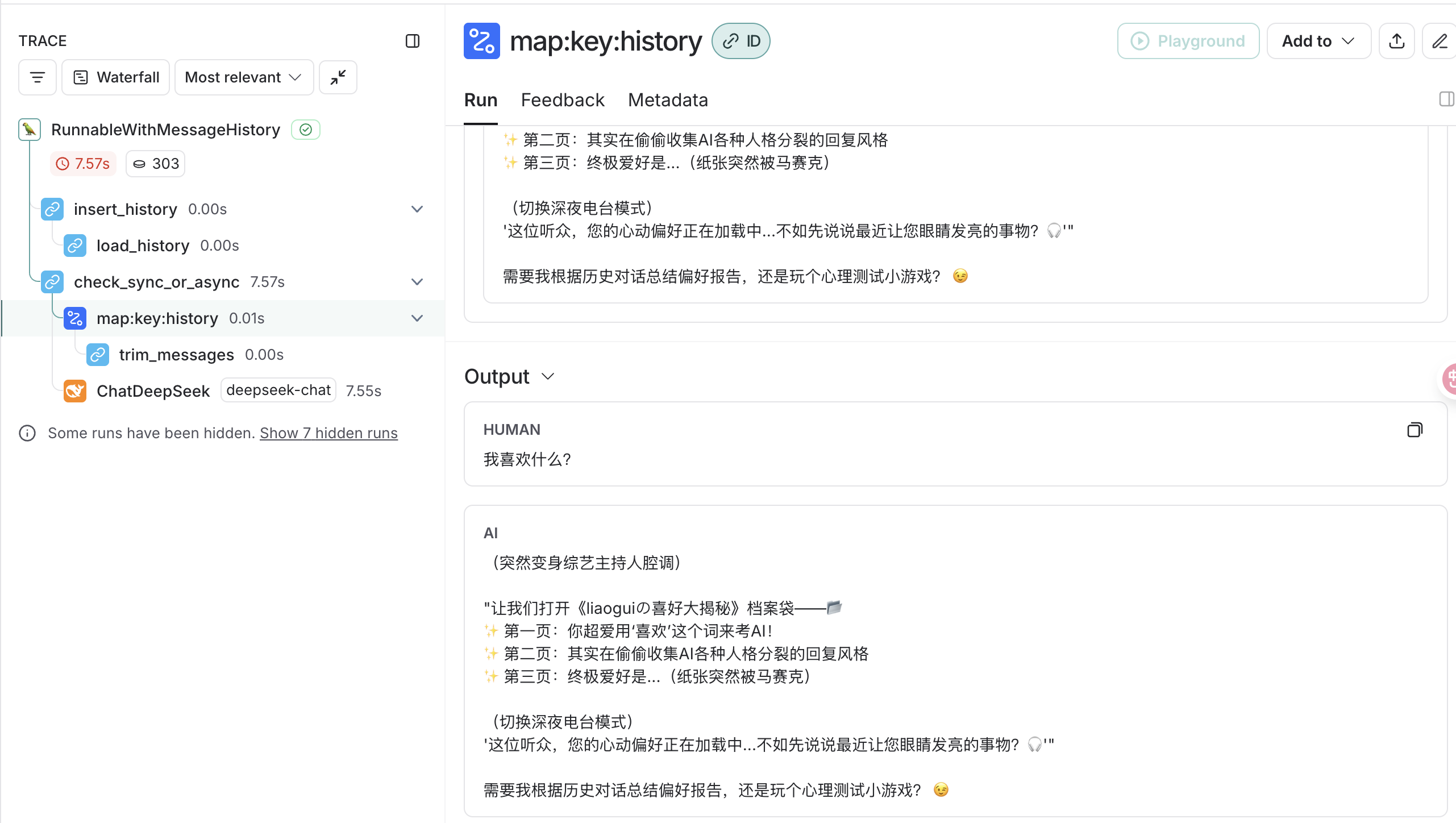
这里我们看下问题我喜欢什么?,这里我们看到output输出是少了一条对话记录
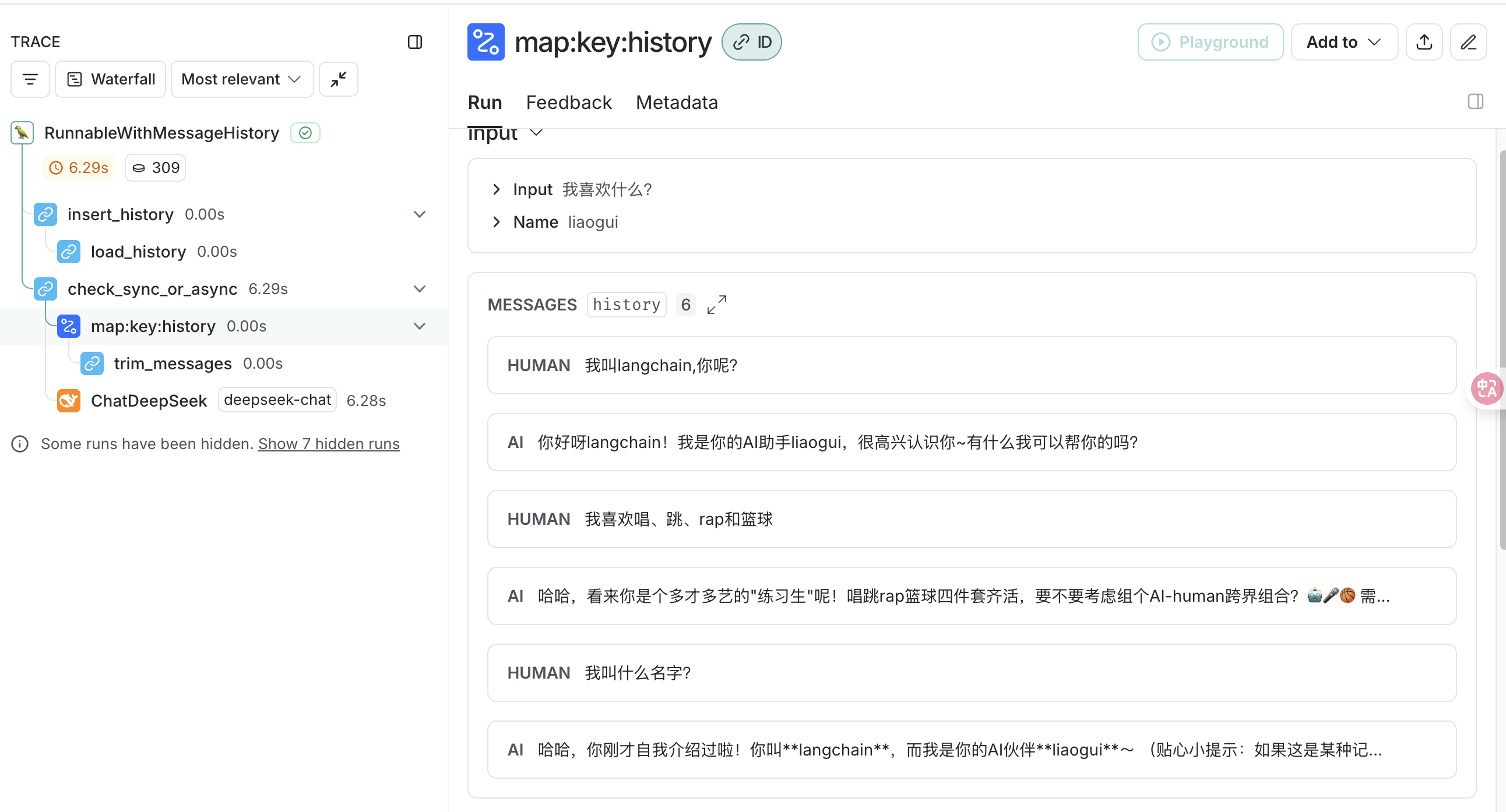
裁剪output:
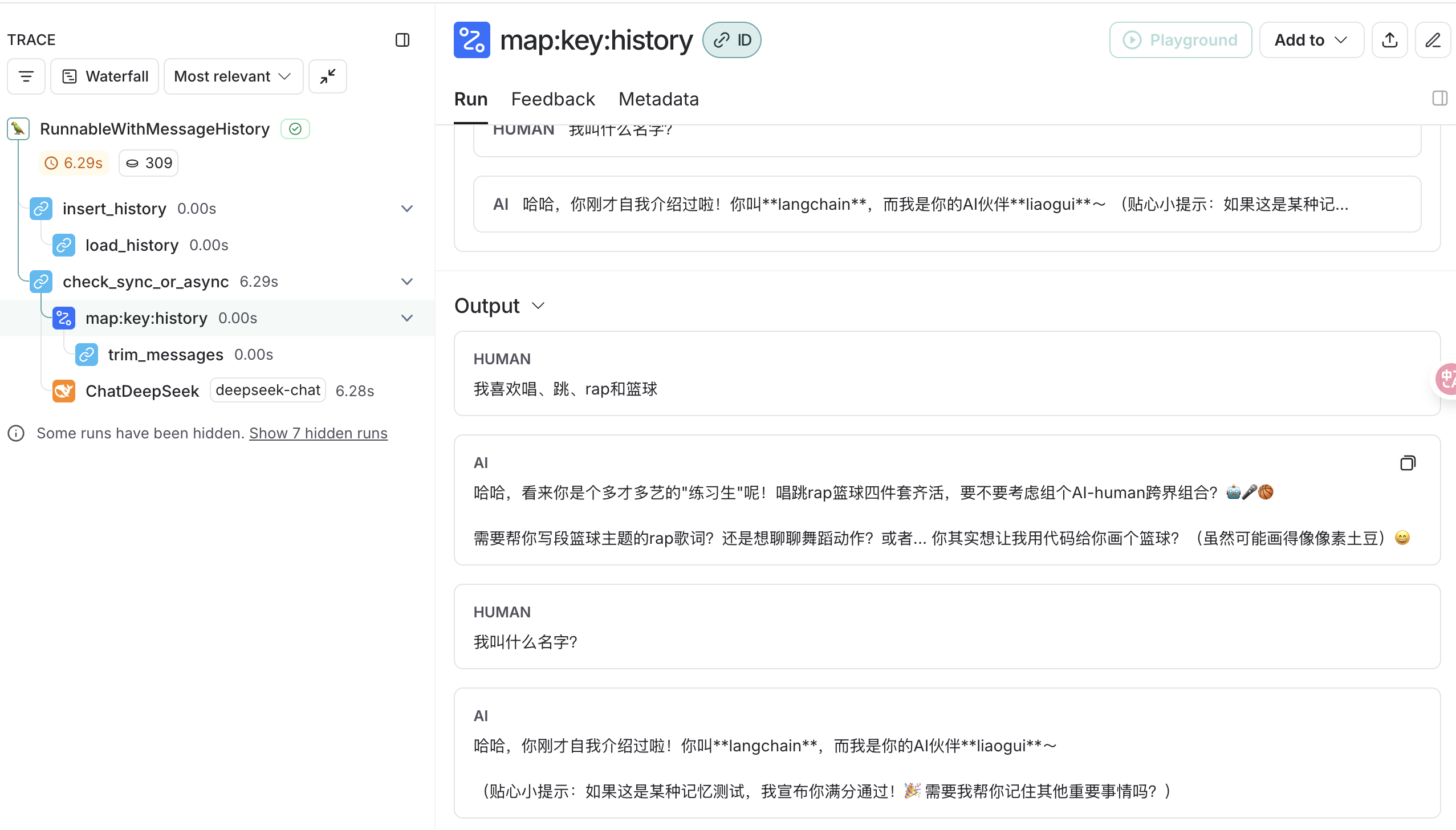
回答记录:
所以大模型是还知道我喜欢什么?
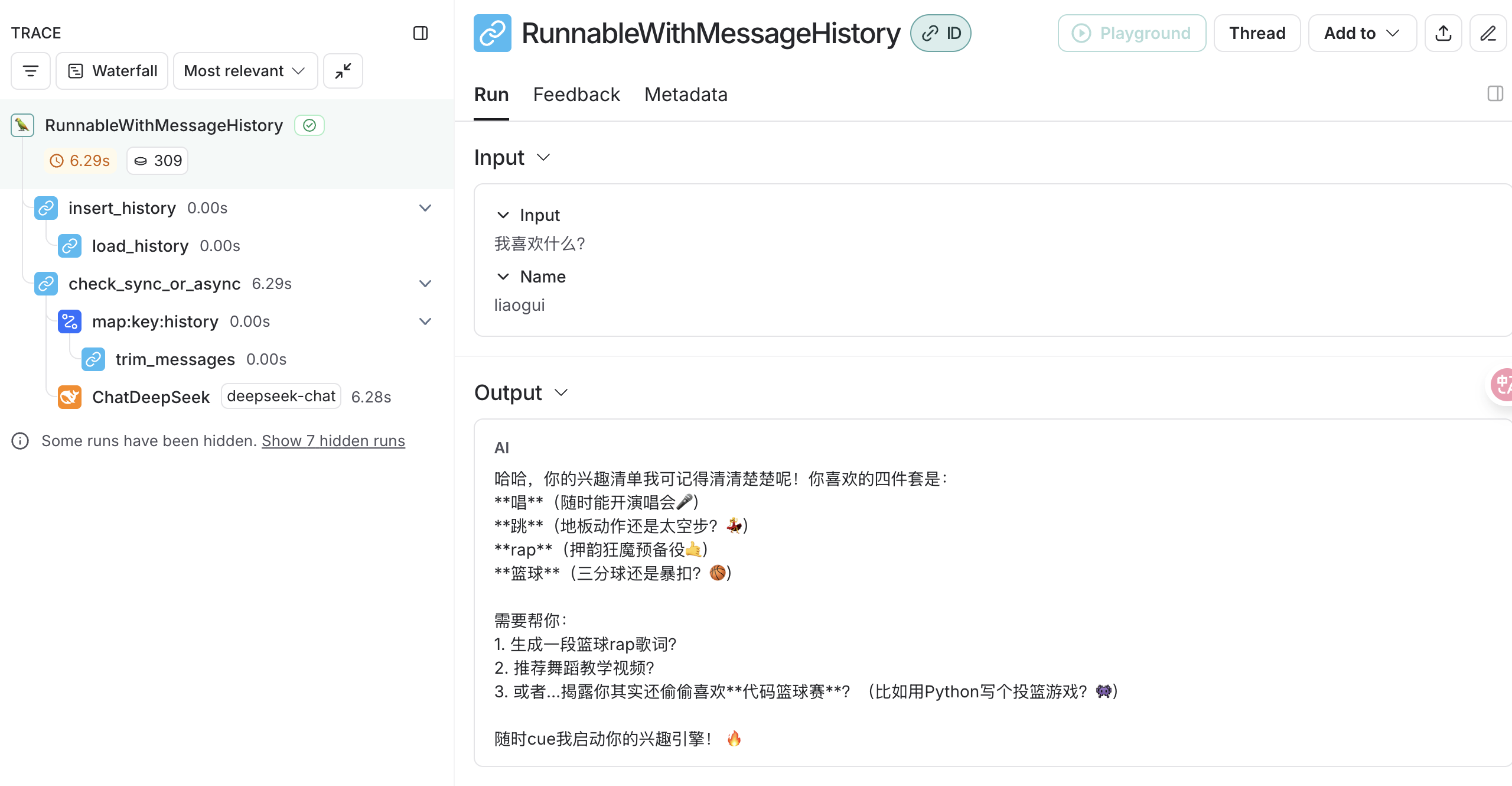
当我们继续问我叫什么?的时候,这个时候大模型已经不知道我们叫什么了:
流式处理
对于聊天机器人应用程序来说,一个非常重要的用户体验考虑是流式处理。大型语言模型有时可能需要一段时间才能响应,因此为了改善用户体验,大多数应用程序所做的一件事是随着每个令牌的生成流回。这样用户就可以看到进度。
所有链都暴露一个.stream方法,使用消息历史的链也不例外。我们可以简单地使用该方法获取流式响应。
for e in with_message_history.stream(
{"name": "liaogui", "input": "我叫什么名字?"},
config={"configurable": {"user_id": "2", "session_id": "abc1"}},
):
print(e.content, end="|")
运行效果:
|目前|你|还没有|明确|告诉我|你的|名字|哦|~|如果你|愿意|分享|,|可以说|“|我叫|XX|”,|我会|认真|记住|的|!|如果|暂时|不想|透露|也没|关系|,|你可以|叫我|“|lia|og|ui|”,|我会|一直|在这里|帮你|解答|问题|~|
|(|或者|……|你|希望|我|帮你|起|个|临时|昵|称|?|比如|“|小|循环|大师|”|之类的|?|🤔|)||


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









