







《Essential C++》学习笔记 第三章 泛型编程风格(二)
一、设计一个泛型算法
泛型算法能够完成不针对特定数据类型的特定功能,C++就提供了一定数量的泛型算法,比如find()、sort()等等这样一些功能简单的算法。但有时候还需要结合模板和C++提供的泛型算法来设计一个实现特定功能的泛型算法。
给定这样一段函数声明:
/*1*/vector<int> filter_less(vector<int> &vec,int &value);
/*2*/vector<int> filter(vector<int> &vec,int &value,bool *fun(int,int));
/*3*/vector<int>filter(vector<int> &vec,int &value,less<int> <);
/*4*/template<typename InputIterator, typename OutputIterator,
typename ElemType ,typename Comp>
OutputIterator filter_ittem(InputIterator first,const InputIterator last,
OutputIterator at,const ElemType &value, Comp pred);
- 该函数过滤vec内小于value的值并放在一个新的vector内作为返回值。不足:这个函数只能解决取小于特定值的场景。
- 该函数将vec内满足与value有特定关系的值并放在一个新的vector内作为返回值。相比于(1),我们可以通过函数指针指定特定的关系包括<,>=,<=等。不足:要自己另外写函数。
- 该函数过滤vec内小于value的值并放在一个新的vector内作为返回值。相比于(1),我们使用了function object;相比于(2),我们不需要自己写函数。
- 该函数将vec内满足与value有特定关系的值并放在一个新的vector内作为返回值。相比于(1)(2)(3),这个函数可以处理array、vector<int>,vector<string>,map等等数据类型,返回值的数据类型根据输入的数据类型自适应变换。
1.1 函数指针
对于程序(2)中的声明:
/*2*/vector<int> filter(vector<int> &vec,int &value,bool *fun(int,int));
其调用的方法如下:
fil_fibon = filter(fibon, 100, greater_than);
fil_fibon = filter(fibon, 100, less_than);
fil_fibon = filter(fibon, 100, equal);
第三个参数其实是函数的名字,可见函数的名字即地址,为了让程序成功运行,需要为此编写三个函数:greater_than,less_than,equal,并且,从声明中第三个参数可见,传给这三个函数的参数必须是int,而且是两个。
bool less_than(int num1, int threshold)
{ return num1 < threshold ? true : false;}
bool greater_than(int num1, int threshold)
{ return num1 > threshold ? true : false;}
至此,我们也完成了一个针对vector<int>的过滤器,能够用第三个参数控制和阈值value的关系。但这有一个问题:自己写的greater_than,less_than,equal泛用性不强,从定义可见,它只针对int类型,如果我想比较string呢?这需要重新写几端代码,但会使得代码更膨胀。
针对(1)我们可以写一个泛型算法,但对于这样功能简单的算法,C++有提供解决方案,即Function Object
1.2 Function Object
1.2.1Function Object中特例的介绍和使用
书上给出使用Function Object的理由是:提高效率,消除“通过函数指针来调用函数”时需要付出的额外代价。根据我的理解,就是把一些符号变成具有泛用性函数,比如 “>”,我们不需要针对int,char,string都写一个实现“判断是否大于”的函数,只需要输入greater<type>即可,其中的type就是根据场景的int,char,string。并且,这样的Function Obvject可以直接与C++的其他泛型算法兼容。
我们看看所谓Function Object的源码吧
// STRUCT TEMPLATE less
template <class _Ty = void>
struct less {
_CXX17_DEPRECATE_ADAPTOR_TYPEDEFS typedef _Ty _FIRST_ARGUMENT_TYPE_NAME;
_CXX17_DEPRECATE_ADAPTOR_TYPEDEFS typedef _Ty _SECOND_ARGUMENT_TYPE_NAME;
_CXX17_DEPRECATE_ADAPTOR_TYPEDEFS typedef bool _RESULT_TYPE_NAME;
_NODISCARD constexpr bool operator()(const _Ty& _Left, const _Ty& _Right) const {
return _Left < _Right;
}
};
从中可以看到一个像函数的东西,他具有这样的格式
XXX(){
return;
}
而里面刚好是判断是否小于。而前面三行有三个“typedef”就是简单的替换吧,比如有时候嫌弃vector<string>太长了,就输入typedef vector<string> vst,以后就可以用vst代替 vector<string>了。但是这对于实现判断"<"是没有明显关系的。我们知道他确实能判断小于,至于为什么能忽视数据类型,我暂时还无法通过源码了解了。
程序3的声明:
/*3*/vector<int>filter(vector<int> &vec,int &value,less<int> <);
其调用的方法为:
less<int> g;
new_vec = filter_itfun(vec_, 23,g );
我曾经试着直接在第三个参数填less<int>,但不行,知道我这样写。然而从函数3的声明中可以见到,该函数只能处理小于的情况。从声明知vec_必须是一个vector<int>。
1.2.2 Function Object在泛型算法里的用法及解析
使用function object 后的过滤器如下
vector<int> filter_itfun(const vector<int>& vec, int filter_value,
less<int> <)
{
vector<int> new_vec;
vector<int>::const_iterator vec_it = vec.begin();
while ((vec_it = find_if(vec_it, vec.end(), bind2nd(lt, filter_value))) != vec.end())
{
new_vec.push_back(*vec_it);
vec_it++;
}
return new_vec;
}
其中bind2nd(lt, filter_value)是把filter_value绑定到lt的第二个参数,如果lt传过来的是less<int>,根据上面1.2.1function object less的源码知,其返回的是return _Left<filter_value;。而find_if返回的是在*[vec_it, vec.end()]*范围内满足第三个参数条件的值的地址,那么我推测find_if(vec_it, vec.end(), bind2nd(lt, filter_value))运作流程如下:
- 先定义一个指针
p,从vec.it开始。 - 调用第三个参数所指的“函数”,
*p作为_Left进行对比。 - 如果为真,则find_if返回
p所指的地址,否则循环,知道找到下一个满足条件的值或者无值可比。
看泛型算法find_if的源码
template <class _InIt, class _Pr>
_NODISCARD _CONSTEXPR20 _InIt find_if(_InIt _First, const _InIt _Last, _Pr _Pred) { // find first satisfying _Pred
_Adl_verify_range(_First, _Last);
auto _UFirst = _Get_unwrapped(_First);
const auto _ULast = _Get_unwrapped(_Last);
for (; _UFirst != _ULast; ++_UFirst) {
if (_Pred(*_UFirst)) {
break;
}
}
_Seek_wrapped(_First, _UFirst);
return _First;
}
好家伙,写的什么鬼玩意儿,但是我们可以明显见到一个for循环,这个循环意图很明显:在一定范围内循环直到找到某个_Pred(*_UFirst)。_Pred(.)是传过来的参数,假设我们传的是less<int>,less<int>源码里有两个参数,其中第二个参数_Right通过bind2nd绑定了,这里传过去的就是*_UFirst作为_Left了。如果满足条件,则返回1,执行了break;,返回了_First的地址。
1.3 Function Object + template
将原本的vector<int>替换为template,结合Function Object即可得到声明/4/所示的代码
/*4*/template<typename InputIterator, typename OutputIterator,
typename ElemType ,typename Comp>
OutputIterator filter_ittem(InputIterator first,const InputIterator last,
OutputIterator at,const ElemType &value, Comp pred);
然而值得注意的是:这段代码不仅仅意在支持容器,还期望支持数组,但是,数组不支持容器的共通操作,即类似vec.begin(),这就是为什么相比于(1)(2)(3)这里传入了一个last:对于一个数组,我们不能使用.size()确定其长度,因此要一个变量,确认其尾地址(不知道c++有没有lenghof函数),以便进行后续操作。此外,加入一个last即可支持数组和容器的原因在于,他们有一个共同的量------地址。
二、容器Map
用班级成绩单举例:用名字作索引,这里的“名字”在map中是称为“key”;可以通过名字找到各科的成绩,成绩在map中成为“value”。在这个例子中,key是字符串,value是数值。但是,
- map中key和value的数据类型不限于“key为字符串,value为数值”,还可以“key和value都是字符串,比如姓名”。
- value不限于1个,还可以多个,比如“一个学生不止考一科,成绩为
vector<int>”,再比如“一个姓可以有多个名,姓为string,名为vector`”
2.1、map的定义方法
#include<map>
map<string,string> name;
map<string,int> grade;
map<string,vector<int>> grades;
2.2、map的赋值方法
对于value为非vector:
grade["xiaoming"]=90;
grade["xiaohong"]=95;
value为vector
vector<int> chengji1={100,95,98};
vector<int> chengji2={100,100,100};
grades["xiaohong"]=chengji1;
grades["xiaoming"]=chengji2;
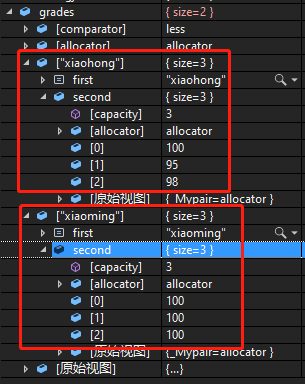
2.3、map的查询方法
从2.2节的图片可见,map中的key通过first查询,value通过second查询。
书本提供了三种方法:
- 没有vector的情况下可以通过
map<string,string> name;
name["zhang"]="san";
cout<<name["zhang"];
缺点:如果查询的时候不存在,就会创建一个新的key,value默认为0。比如里面没有"li",如果用方法1查询name["li"],就会在map中创建name["li"]=0
2. 容器的共通操作:.find()
有则返回地址,无则返回end()。不会创建新的索引。
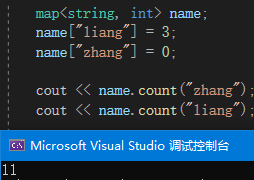
3. count函数
调用会范围对应的value值,如果value为0表示不存在。不会创建新的索引,如下图,查询后没有出现zhang。

下图可见count返回的不是value值,存在则为1,不存在则为0;
以上三种方法都是针对没有vector的情况,如果要处理value是vector的情况,则要使用泛型指针来处理了。而且至少需要2个指针。
map<string, vector<int>> grades;
vector<int> chengji1 = {100,95,98};
grades["xiaohong"] = chengji1;
map<string, vector<int>> ::iterator itmap=grades.begin();
vector<int>::iterator map_it_chengji = itmap->second.begin();
cout << *map_it_chengji << *(map_it_chengji + 1);
三、容器Set
是特殊的vector,不出现重复的值。可以简单理解为数学里的集合,集合具有确定性,即不存在重复的数。
四、Iterator Inserter
有时候我们并不提前知道容器的大小,一般情况下都是太大了。比如刚开始一个班30人,但是可能会有插班的情况,因此会预留一部分,开一个大小为40的vector,但是这可能是过大的。虽然vector可以是一个空的容器,想插入新的元素则用.pushback(),然而有时候算法需要容器的首地址,但是空容器是没有首地址和尾地址的。
一个具体的场景:有一个长度为100的vector<int> vec1,我们想要从vec1中取出所有偶数,设置一个new_vec但是不知道共有多少个偶数,大小无法确定。
但其实我觉得这个东西不怎么好用,直接贴代码吧
首先是不使用iterator inserter
vector<int> new_vec(8);
filter_ittem(vec_.begin(), vec_.end(),
new_vec.begin(),
23, greater_equal<int>());
使用了iterator inserter
#include<iterator>
vector<int> new_vec;
filter_ittem(vec_.begin(),vec_.end(),
inserter(new_vec,new_vec.end()),
23, greater_equal<int>());
区别在于new_vec的预设大小,第一段代码需要预设否则编译不过,第二段则没问题。本质上时因为空容器没有首地址,所以第一段代码不预设大小则编译不过。
但是,我们可以发现:这两段函数返回的都是void,这其实在为难自己,返回一个vector就好了呀,想泛型则用template就好了。
五、iostream Iterator
输入/输出设备的指针,设备包括:(1)cin,cout代表标准输入输出设备(2)文件
(1)
istream_iterator<int> is_point(cin);
istream_iterator<int> eof;
vector<int> my_num;
copy(is_point, eof, back_inserter(my_num));
//copy会把if到eof的元素复制到第三个参数
(2)
ofstream out_oddfile("oddfile.txt");
ofstream out_evenfile("evenfile.txt");
ostream_iterator<int> o_odd(out_oddfile, ", ");
ostream_iterator<int> o_even(out_evenfile, "- ");
//第二个参数表示输出后的字符,比如"5-6-9-8-7","1 2 55 7"
copy_if(my_num.begin(), my_num.end(), o_even, is_even());
copy_if(my_num.begin(), my_num.end(), o_odd, is_odd());















 366
366











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









