






Redis的Bitmap的使用案例与场景
概要
- 最近在公司的一次需求迭代中遇到了这么一个场景:有两个异步的动作,前置动作是根据条件筛选用户并统计预估用户量,后置动作是根据条件筛选用户并且需要对具体用户进行操作。由于前置动作统计用户量时就需要查询到具体的用户,所以让后置动作再去做一次重复操作显然不太合理了,所以这里会考虑将用户暂存进redis中,方便后续操作。
- 这里存在一个问题,由于筛选的用户量很大,如果直接存入redis中,必然会造成很大的空间损耗。于是本文的主角:bitmap,就能派上用场了。
本篇文章主要针对上述案例中bitmap的使用方式,并不会对bitmap的细节做过多描述
bitmap的使用注意事项
1.bitmap的优点?
- 如果有1000个Long类型的userId:1,2,3,4 … … 1000。
- 使用list去存储一个这些user_id需要使用 64bit * 1000 的长度去存储。
- 使用bitmap,我们就只需要使用1000bit的长度就可以存储了(1111 … … 第1000个位置是1)。
2.bitmap的缺点?
- 如果有1个Long类型的userId:9999999
- 使用list去存储一个该user_id需要使用64bit的长度去存储。
- 使用bitmap,我们却需要使用9999999bit的长度去存储这一个用户(000…第9999999位置是1)
- 所以bitmap只适合使用数据量多的场景下,如果数据量少,但是单个数据本身的数值却很大,这时候使用bitmap就会造成大量的空间浪费。
解决方案A
1.思路
- 让我们回到正题,此时我要将userId存储进redis中,但是每次筛选的用户数据规模上下限都是很大的(下限是0,上限是全量用户),如果每次都直接往bitmap中存储,在用户数据规模较小的时候很可能会造成空间浪费。
- 所以我们在数据量少的时候,把userId存储进redis的list中,数据量多的时候把user_id存储进redis的bitmap中。
2.key的设计
- 在这个场景下,用户是通过条件表达式筛选出来的,所以key可以设计成: 常量 + 条件表达式的形式。
- 举个例子,针对一个表达式的key:bitmap的key为 condition_bitmap:%s,list的key为condition_list:%s。
3.判断依据的推算
- 那么该如何判断呢?设当前用户系统的用户Id是long类型,现在需要存储x个用户数量,这批用户最大的user_id为m。如果64 * x <= m,则向list中存储,如果 64*x >=m则向bitmap中存储。
4.主流程
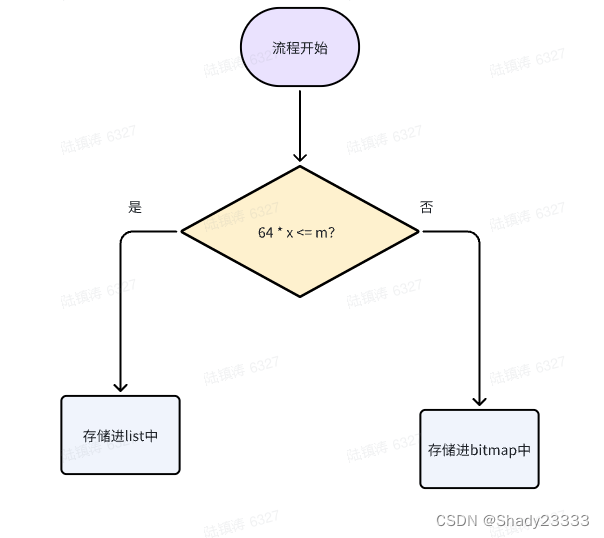
解决方案B
1.思路
- 很多时候我们去存储userId的时候,不一定是一下子将这个表达式对应的用户全部存储进redis,因为用户量很大,在从另一个中间件读取用户的时候(例如es,mysql),是通过分页的方式读取的,所以方案A在这种场景下就无法使用了。(因为每次分页的时候就得写入redis,此时是局部的,你无法知道整体情况下bitmap和list谁大)
- 所以我们在数据量少的时候,把userId存储进redis的list中。当这个list的数量达到阈值后,将list的数据迁移至bitmap中,后续的数据都写入bitmap中。
- 由于我们公司user_id并不是从1开始的,所以为了让bitmap更加节省空间,可以在写入bitmap中时,用实际的user_id 减去当前用户系统中最小的user_id来获取一个压缩的user_id。
2.主流程
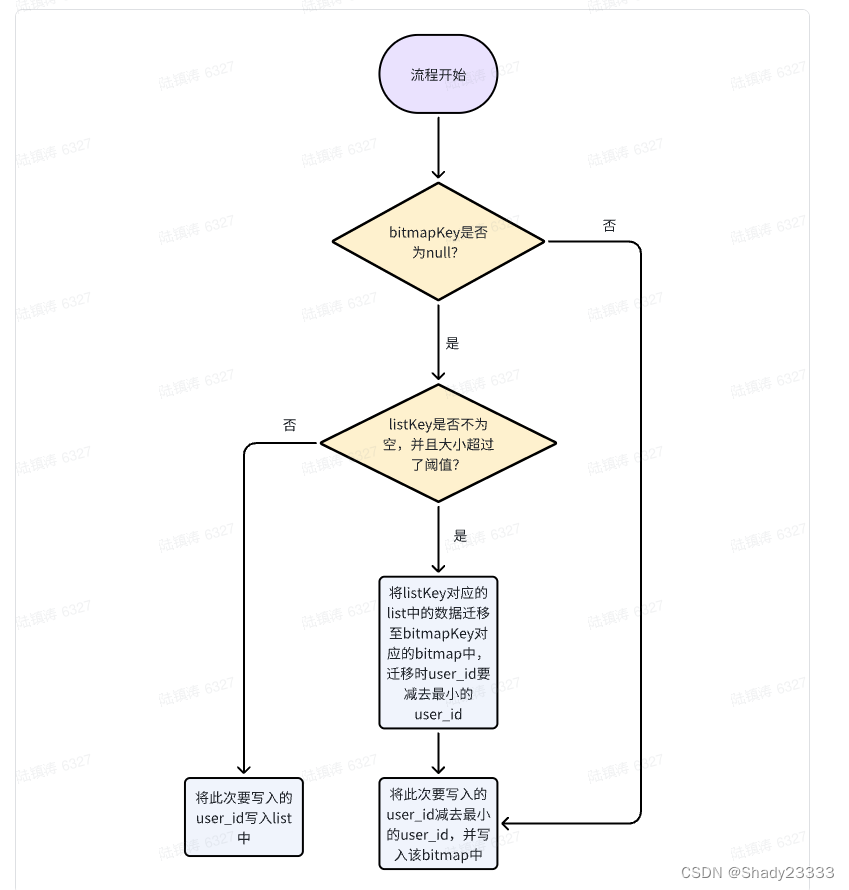
3.关于list向bitmap转化阈值的推算
- bitmap存储的最大长度取决于当前用户系统最大的userId,我们设当前用户系统的用户Id是long类型,并且最大的用户Id为m,最小的用户id为n。现在需要存储x个用户数量。
- 由于任何一个用户数据集,都可能包含最大的用户id,我们需要用最差的情况去计算bitmap。
- 为什么要用最差情况去估算?仔细想想,如果第一次分页中就包含了当前用户系统中最大的user_id,第二次分页时,再去判断第二次分页存储进list还是bitmap还有意义吗?此时bitmap已经开了一块最大的空间了,还不如全往bitmap存… …
- 于是有了以下公式:
- 64 * x = m - n
- 如图:
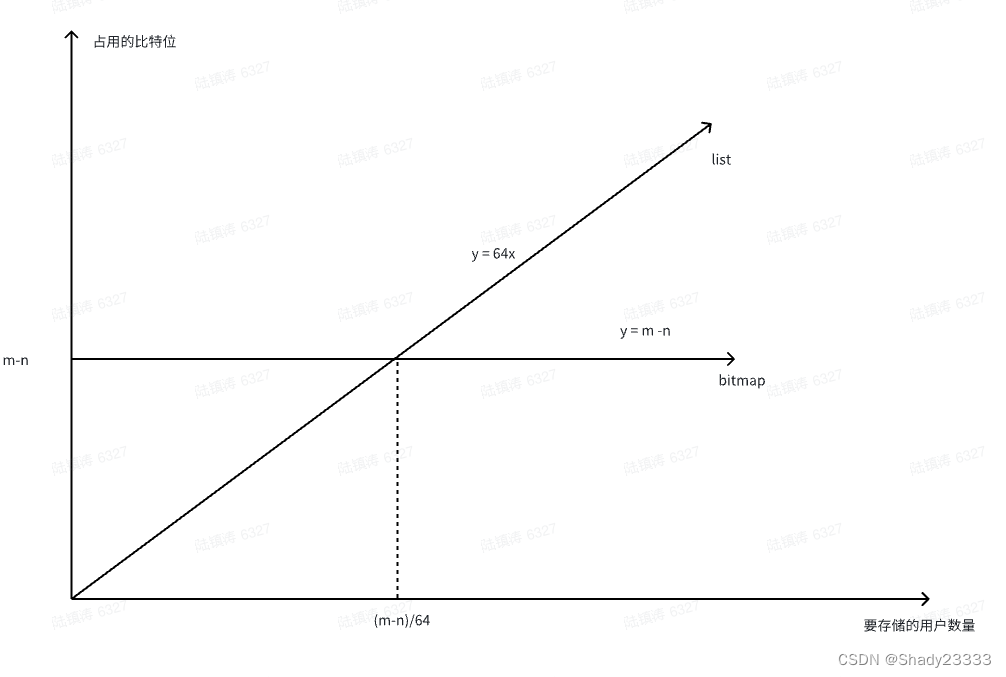
- 即当要存储的用户数量大于 (m-n)/64时,bitmap的存储性能将大于list。
小结
- bitmap的性能并不一定高,必须结合实际的场景使用。















 871
871











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









