







一、redis作为缓存和数据库的区别
1.缓存数据不"重要",不是全量数据,缓存应该随着访问变化,存的都是热数据
2.redis里的数据应该能随着业务变化,只保留热数据,因为内存大小是有限的,也就是瓶颈
3.删除优先级:
业务逻辑->key的有效期 业务运转->随着访问变化,淘汰调冷数据
因此能业务删除最好不用淘汰机制
二、redis的淘汰算法
不配置淘汰策略时,内存满了后再访问时返回错误
redis淘汰策略分两个维度:所有键/有过期时间的键+淘汰策略(lru、lfu、random、ttl)
所有的淘汰策略:
-1 allkeys-lru 所有键最久没用
-2 volatile-lru 过期的键久没用
-3 allkeys-lfu 所有键最少使用
-4 valatile-lfu 过期的键最少使用
-5 volatile-random 随机淘汰
-6 volatile-ttl 优先淘汰回收存活时间较少的键
redis实现的lru/lfu并非完全实现,而是做了一点优化,优化如下:
被动方式:访问时才把过期的key删掉
主动方式:
1.每隔一段时间(10秒),随机采样20个(可配)keys
2.删除其中过期的或被lru/lfu判定成功的keys
3.如果删除比例大于%25,重复步骤1、2
目的:牺牲内存,保住性能为主的思想
三、LRU算法和LFU算法
1.LRU算法
需求:R是recently(最近的)的意思,LRU就是淘汰调最久没有使用的key
思路:
1.最蠢的办法:每个key都记录一个时间,然后遍历所有的key,把时间最小的淘汰掉。时间复杂度O(n),空间复杂度O(n)且浪费记录时间的内存
2.put/get/del时间复杂度优化到O(1)。
3.hashmap+双向链表
模型:

put:数据时放到链表头部,时间复杂度复杂度O(1)
del:删除链表尾部即可,时间复杂度O(1)
get:根据key查hashmap即可,时间复杂度O(1)
set=del+put
代码实现可参考java中的LinkedHashmap
LFU算法
需求:F是frequently的意思,同LUR,put/get/del时间复杂度优化到O(1)。
思路:LFU可以算是LRU的延伸,一个map不够用,那就使用第二个map,第二个map的key是访问次数,value维护一个链表,链表每个元素指向第一个map的元素。并在entry中增加count属性
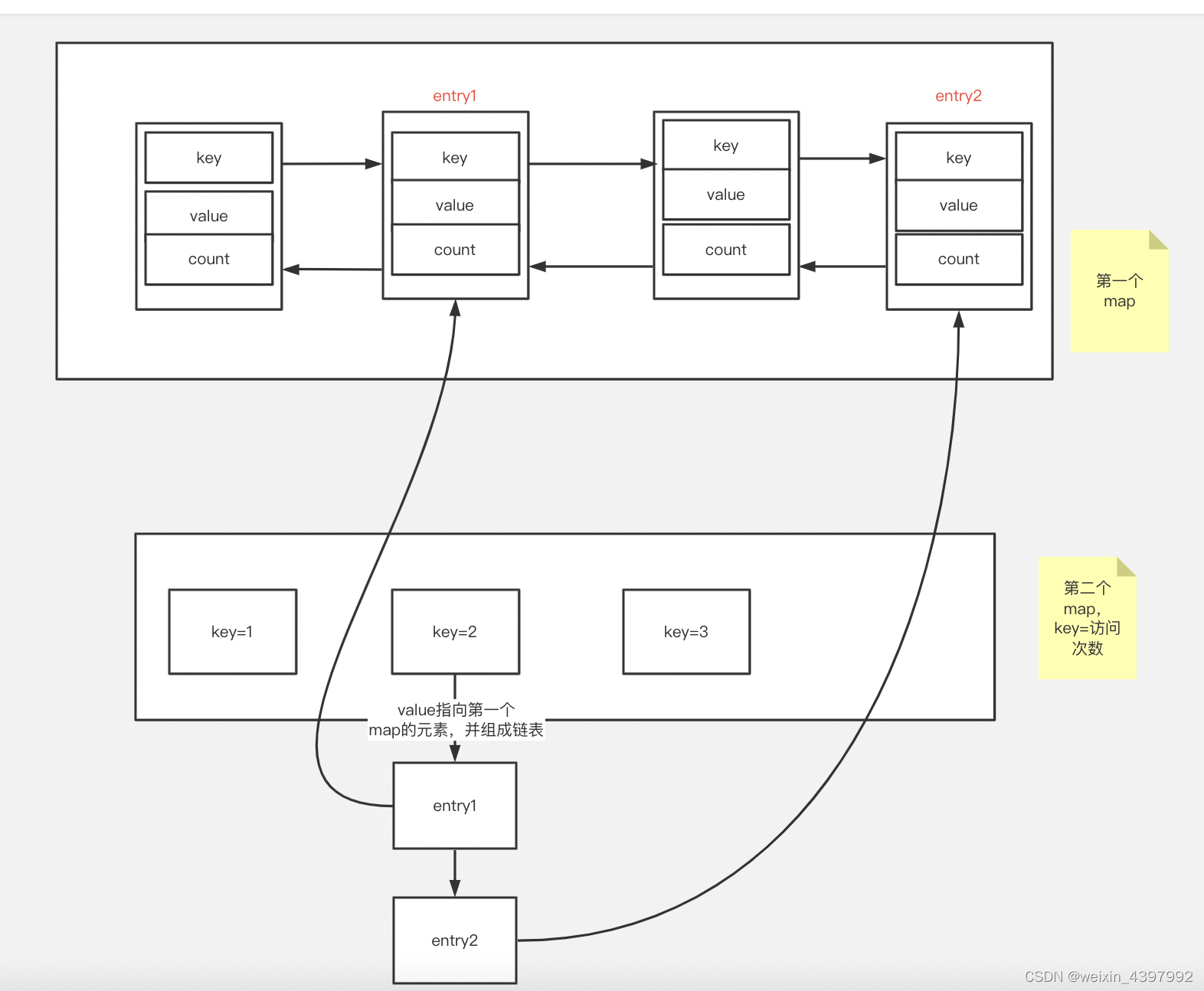
put:数据时放到第一个链表头部,并放入第二个map中,时间复杂度O(1)
del:从第二个map中查key较小的entry,并在第一、二个map中删除,时间复杂度O(1)
get:根据key查第一个hashmap即可,并更新第二个map,count++放到新key里,时间复杂度O(1)
set=del+put
代码自行百度。。。
如果有写错的地方,欢迎大家指正,感谢!















 497
497











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









