









说明 📘
- 思路
- 获取该歌手ID
- 获取该歌手的歌曲数量,及每页包含的歌曲数量
- 获取该歌手的所有歌曲ID和对应的歌曲名称
- 获取歌曲ID所对应的名字及链接
- 下载音乐
- 传送门:GitHub 📍
Code 🔍
- 关键点
- json格式的数据写入与读取
- 抓取Ajax动态加载的网页
- 利用content保存音频等二进制文件
import requests
import re
import json
from pprint import pprint
import os
# 写入读取字典格式的数据 for json文件
class JsonFile(object):
@staticmethod
def save_file(path, content_dict):
# 先将字典对象转化为可写入文本的字符串
content_dict = json.dumps(content_dict, ensure_ascii=True, indent=4)
try:
with open(path, "w", encoding='utf-8') as f:
f.write(content_dict)
except Exception as e:
print("写入json文件出错:", e)
@staticmethod
def load_file(path):
with open(path, 'r') as f:
content = f.read()
content.encode("utf-8-sig")
id_singer_dict = json.loads(content)
# 利用pprint打印json格式数据
# pprint(id_singer_dict)
return id_singer_dict
# 获取歌曲ID所对应的名字及链接
def get_song_links(song_id):
url = "http://play.taihe.com/data/music/songlink"
params = {
'songIds': song_id,
}
response = requests.post(url=url, params=params)
# 提取json文件中的字典信息
music_infos = response.json()['data']['songList']
for music_info in music_infos:
song_name = music_info['songName']
song_link = music_info['songLink']
yield song_name, song_link
# 获取该歌手的所有歌曲ID
def get_song_ids(singer_id, start='0'):
params = {
'start': start, # 从第start开始的15首歌曲id,改变数字,获取更多的歌曲信息
'size': '15', # 每页歌曲数
'ting_uid': singer_id,
# '.r': '0.127372516911736341578451426991',
}
song_list_url = 'http://music.taihe.com/data/user/getsongs'
response = requests.get(song_list_url, params=params)
response.encoding = response.apparent_encoding # 解决编码问题
json_str = json.loads(response.text)['data']['html'] # 提取Ajax动态请求加载的html页面
song_id_name_ls = re.findall('<a href="/song/(\\d+)".*?" title="(.*?)"', json_str, re.S)
song_ids_ls = []
song_name_ls = []
for id_name_tuple in song_id_name_ls:
song_ids_ls.append(id_name_tuple[0])
song_name_ls.append(id_name_tuple[1])
print("、\t".join(song_name_ls))
return song_ids_ls, song_name_ls
# 获取歌手ID
def get_singer_id(singer_name):
def get_singer_ids():
# 首先获取所有歌手的ID
path = '.\\id_singer.json'
if not os.path.exists(path):
base_url = 'http://music.taihe.com/artist'
response = requests.get(base_url)
response.encoding = response.apparent_encoding
id_singers = re.findall('<a href="/artist/(\\d+)" title="(.*?)"', response.text, re.S)
id_singer_dict = {}
for id_singer in id_singers:
id = id_singer[0]
singer = id_singer[1]
if singer not in id_singer_dict:
id_singer_dict[singer] = id
# 将歌手id和歌手名字保存为json格式文件
JsonFile.save_file(path=path, content_dict=id_singer_dict)
id_singer_dict = JsonFile.load_file(path=path)
else:
print("歌手ID信息已存在,导入中......")
id_singer_dict = JsonFile.load_file(path=path)
return id_singer_dict
# 获取歌手ID
id_singer_dict = get_singer_ids()
singer_id = id_singer_dict[singer_name]
return singer_id
# 获取该歌手的歌曲数量,及每页包含的歌曲数量
def get_singer_song_nums(singer_id):
response = requests.get("http://music.taihe.com/artist/{}".format(singer_id))
response.encoding = response.apparent_encoding # 解决编码问题
total_size = re.findall(r"'total':(\d+), 'size':(\d+)", response.text, re.S)[0]
singer_song_nums, page_size = total_size[0], total_size[1]
return singer_song_nums, page_size
# 下载音乐
def download_music(name_links, singer_name):
# 下载mp3的文件夹
save_path = ".\\music\\{}\\".format(singer_name)
if not os.path.exists(save_path):
os.makedirs(save_path)
# 下载mp3
for name_link in name_links:
print(name_link)
song_name = name_link[0]
song_link = name_link[1]
try:
# 图片、音频是二进制数据,用content访问
response = requests.get(song_link)
with open(save_path + song_name + ".mp3", "wb") as f:
f.write(response.content)
except Exception as e:
print("这首歌曲请求出错:", e)
# 网站暂未进行反爬
if __name__ == "__main__":
singer_name = input('请输入歌手姓名: ')
# 1.获取该歌手ID
singer_id = get_singer_id(singer_name)
# 2.获取该歌手的歌曲数量,及每页包含的歌曲数量
singer_song_nums, page_size = get_singer_song_nums(singer_id)
download_num = int(input("共包含{}的歌曲{}首\n请输入您想下载的歌曲数: ".format(singer_name, singer_song_nums)))
# 3.获取该歌手的所有歌曲ID和对应的歌曲名称
for start in range(0, download_num, int(page_size)):
print("\n第{}页的歌曲包括:".format(start // int(page_size) + 1))
song_ids, song_name_ls = get_song_ids(singer_id, start=str(start))
song_ids = ",".join(song_ids)
# 4.获取歌曲ID所对应的名字及链接
name_links = get_song_links(song_ids)
# 5.下载音乐
download_music(name_links, singer_name)
部分效果图
原网页


程序爬取

下载的部分歌手的音乐
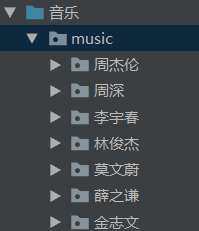
The End
- 撒花✿✿ヽ(°▽°)ノ✿
- 更多爬虫项目传送门:GitHub















 2657
2657











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









