









ElasticSearch7.6入门学习笔记
笔记记录 B站狂神说Java的ElasticSearch课程:https://www.bilibili.com/video/BV17a4y1x7zq
在学习ElasticSearch之前,先简单了解一下Lucene:
- Doug Cutting开发
- 是apache软件基金会4 jakarta项目组的一个子项目
- 是一个开放源代码的全文检索引擎工具包
- 不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎,部分文本分析引擎(英文与德文两种西方语言)
- 当前以及最近几年最受欢迎的免费Java信息检索程序库。
Lucene和ElasticSearch的关系:
- ElasticSearch是基于Lucene 做了一下封装和增强
一、ElasticSearch概述
官网:https://www.elastic.co/cn/downloads/elasticsearch
Elaticsearch,简称为es,es是一个开源的高扩展的分布式全文检索引擎,它可以近乎实时的存储、检索数据;本身扩展性很好,可以扩展到上百台服务器,处理PB级别(大数据时代)的数据。es也使用java开发并使用Lucene作为其核心来实现所有索引和搜索的功能,但是它的目的是通过简单的RESTful API来隐藏Lucene的复杂性,从而让全文搜索变得简单。
据国际权威的数据库产品评测机构DB Engines的统计,在2016年1月,ElasticSearch已超过Solr等,成为排名第一的搜索引擎类应用。
历史
多年前,一个叫做Shay Banon的刚结婚不久的失业开发者,由于妻子要去伦敦学习厨师,他便跟着也去了。在他找工作的过程中,为了给妻子构建一个食谱的搜索引擎,他开始构建一个早期版本的Lucene。
直接基于Lucene工作会比较困难,所以Shay开始抽象Lucene代码以便lava程序员可以在应用中添加搜索功能。他发布了他的第一个开源项目,叫做“Compass”。
后来Shay找到一份工作,这份工作处在高性能和内存数据网格的分布式环境中,因此高性能的、实时的、分布式的搜索引擎也是理所当然需要的。然后他决定重写Compass库使其成为一个独立的服务叫做Elasticsearch。
第一个公开版本出现在2010年2月,在那之后Elasticsearch已经成为Github上最受欢迎的项目之一,代码贡献者超过300人。一家主营Elasticsearch的公司就此成立,他们一边提供商业支持一边开发新功能,不过Elasticsearch将永远开源且对所有人可用。
Shay的妻子依旧等待着她的食谱搜索……
谁在使用:
1、维基百科,类似百度百科,全文检索,高亮,搜索推荐/2
2、The Guardian (国外新闻网站) ,类似搜狐新闻,用户行为日志(点击,浏览,收藏,评论) +社交网络数据(对某某新闻的相关看法) ,数据分析,给到每篇新闻文章的作者,让他知道他的文章的公众反馈(好,坏,热门,垃圾,鄙视,崇拜)
3、Stack Overflow (国外的程序异常讨论论坛) , IT问题,程序的报错,提交上去,有人会跟你讨论和回答,全文检索,搜索相关问题和答案,程序报错了,就会将报错信息粘贴到里面去,搜索有没有对应的答案
4、GitHub (开源代码管理),搜索 上千亿行代码
5、电商网站,检索商品
6、日志数据分析, logstash采集日志, ES进行复杂的数据分析, ELK技术, elasticsearch+logstash+kibana
7、商品价格监控网站,用户设定某商品的价格阈值,当低于该阈值的时候,发送通知消息给用户,比如说订阅牙膏的监控,如果高露洁牙膏的家庭套装低于50块钱,就通知我,我就去买
8、BI系统,商业智能, Business Intelligence。比如说有个大型商场集团,BI ,分析一下某某区域最近3年的用户消费 金额的趋势以及用户群体的组成构成,产出相关的数张报表, **区,最近3年,每年消费金额呈现100%的增长,而且用户群体85%是高级白领,开-个新商场。ES执行数据分析和挖掘, Kibana进行数据可视化
9、国内:站内搜索(电商,招聘,门户,等等),IT系统搜索(OA,CRM,ERP,等等),数据分析(ES热门
的一一个使用场景)
ES和Solr
ElasticSearch简介
- Elasticsearch是一个实时分布式搜索和分析引擎。 它让你以前所未有的速度处理大数据成为可能。
- 它用于全文搜索、结构化搜索、分析以及将这三者混合使用:
维基百科使用Elasticsearch提供全文搜索并高亮关键字,以及输入实时搜索(search-asyou-type)和搜索纠错(did-you-mean)等搜索建议功能。英国卫报使用Elasticsearch结合用户日志和社交网络数据提供给他们的编辑以实时的反馈,以便及时了解公众对新发表的文章的回应。StackOverflow结合全文搜索与地理位置查询,以及more-like-this功能来找到相关的问题和答案。Github使用Elasticsearch检索1300亿行的代码。- 但是Elasticsearch不仅用于大型企业,它还让像
DataDog以及Klout这样的创业公司将最初的想法变成可扩展的解决方案。 - Elasticsearch可以在你的笔记本上运行,也可以在数以百计的服务器上处理PB级别的数据。
- Elasticsearch是一个基于Apache Lucene™的开源搜索引擎。无论在开源还是专有领域, Lucene可被认为是迄今为止最先进、性能最好的、功能最全的搜索引擎库。
- 但是, Lucene只是一个库。 想要使用它,你必须使用Java来作为开发语言并将其直接集成到你的应用中,更糟糕的是, Lucene非常复杂,你需要深入了解检索的相关知识来理解它是如何工作的。
- Elasticsearch也使用Java开发并使用Lucene作为其核心来实现所有索引和搜索的功能,但是它的目的是通过简单的RESTful API来隐藏Lucene的复杂性,从而让全文搜索变得简单。
Solr简介
- Solr是Apache下的一个顶级开源项目,采用Java开发,它是基于Lucene的全文搜索服务器。Solr提供了比Lucene更为丰富的查询语言,同时实现了可配置、可扩展,并对索引、搜索性能进行了优化
- Solr可以独立运行,运行在letty. Tomcat等这些Selrvlet容器中 , Solr 索引的实现方法很简单,用POST方法向Solr服务器发送一个描述Field及其内容的XML文档, Solr根据xml文档添加、删除、更新索引。Solr 搜索只需要发送HTTP GET请求,然后对Solr返回xml、json等格式的查询结果进行解析,组织页面布局。
- Solr不提供构建UI的功能, Solr提供了一个管理界面,通过管理界面可以查询Solr的配置和运行情况。
- Solr是基于lucene开发企业级搜索服务器,实际上就是封装了lucene.
- Solr是一个独立的企业级搜索应用服务器,它对外提供类似于Web-service的API接口。用户可以通过http请求,向搜索引擎服务器提交-定格式的文件,生成索引;也可以通过提出查找请求,并得到返回结果。
ElasticSearch与Solr比较
当单纯的对已有数据进行搜索时,Solr更快

当实时建立索引时,Solr会产生io阻塞,查询性能较差,ElasticSearch具有明显的优势

随着数据量的增加,Solr的搜索效率会变得更低,而ElasticSearch却没有明显的变化

转变我们的搜索基础设施后从Solr ElasticSearch,我们看见一个即时~ 50x提高搜索性能!

总结
1、es基本是开箱即用(解压就可以用!) ,非常简单。Solr安装略微复杂一丢丢!
2、Solr 利用Zookeeper进行分布式管理,而Elasticsearch自身带有分布式协调管理功能。
3、Solr 支持更多格式的数据,比如JSON、XML、 CSV ,而Elasticsearch仅支持json文件格式。
4、Solr 官方提供的功能更多,而Elasticsearch本身更注重于核心功能,高级功能多有第三方插件提供,例如图形化界面需要kibana友好支撑
5、Solr 查询快,但更新索引时慢(即插入删除慢) ,用于电商等查询多的应用;
- ES建立索引快(即查询慢) ,即实时性查询快,用于facebook新浪等搜索。
- Solr是传统搜索应用的有力解决方案,但Elasticsearch更适用于新兴的实时搜索应用。
6、Solr比较成熟,有一个更大,更成熟的用户、开发和贡献者社区,而Elasticsearch相对开发维护者较少,更新太快,学习使用成本较高。
二、ElasticSearch安装
JDK8,最低要求
使用Java开发,必须保证ElasticSearch的版本与Java的核心jar包版本对应!(Java环境保证没错)
这里在windows上进行安装
Windows下安装
1、安装
下载地址:https://www.elastic.co/cn/downloads/
历史版本下载:https://www.elastic.co/cn/downloads/past-releases/
解压即可(尽量将ElasticSearch相关工具放在统一目录下)
2、熟悉目录

bin 启动文件目录config 配置文件目录 1og4j2 日志配置文件 jvm.options java 虚拟机相关的配置(默认启动占1g内存,内容不够需要自己调整) elasticsearch.ym1 elasticsearch 的配置文件! 默认9200端口!跨域!1ib 相关jar包modules 功能模块目录plugins 插件目录 ik分词器
3、启动
一定要检查自己的java环境是否配置好
双击启动


访问9200进行验证:

安装可视化界面
elasticsearch-head
使用前提:需要安装nodejs
1、下载地址
https://github.com/mobz/elasticsearch-head
2、安装
解压即可(尽量将ElasticSearch相关工具放在统一目录下)
3、启动
cd elasticsearch-head# 安装依赖npm install# 启动npm run start# 访问http://localhost:9100/
安装依赖

运行

访问
存在跨域问题(只有当两个页面同源,才能交互)
同源(端口,主机,协议三者都相同)
https://blog.csdn.net/qq_38128179/article/details/84956552

开启跨域(在elasticsearch解压目录config下elasticsearch.yml中添加)
# 开启跨域http.cors.enabled: true# 所有人访问http.cors.allow-origin: "*"
重启elasticsearch
再次连接

如何理解上图:
-
如果你是初学者
- 索引 可以看做 “数据库”
- 类型 可以看做 “表”
- 文档 可以看做 “库中的数据(表中的行)”
-
这个head,我们只是把它
当做可视化数据展示工具
,之后
所有的查询都在kibana中进行
- 因为不支持json格式化,不方便
安装kibana
Kibana是一个针对ElasticSearch的开源分析及可视化平台,用来搜索、查看交互存储在Elasticsearch索引中的数据。使用Kibana ,可以通过各种图表进行高级数据分析及展示。Kibana让海量数据更容易理解。它操作简单,基于浏览器的用户界面可以快速创建仪表板( dashboard )实时显示Elasticsearch查询动态。设置Kibana非常简单。无需编码或者额外的基础架构,几分钟内就可以完成Kibana安装并启动Elasticsearch索引监测。
1、下载地址:
下载的版本需要与ElasticSearch版本对应
https://www.elastic.co/cn/downloads/
历史版本下载:https://www.elastic.co/cn/downloads/past-releases/
2、安装
解压即可(尽量将ElasticSearch相关工具放在统一目录下)

3、启动

启动成功,如下所示:

访问
localhost:5601
访问如下所示:

4、开发工具
(Postman、curl、head、谷歌浏览器插件)
可以使用
Kibana进行测试如下是汉化成功的,汉化如下操作如下所示

如果说,你在英文方面不太擅长,kibana是支持汉化的
5、kibana汉化
编辑器打开kibana解压目录/config/kibana.yml,添加
i18n.locale: "zh-CN"
重启kibana
可以看到如上所示了
-
ELK是
Elasticsearch、Logstash、 Kibana三大开源框架首字母大写简称
。市面上也被成为Elastic Stack。
- 其中Elasticsearch是一个基于Lucene、分布式、通过Restful方式进行交互的近实时搜索平台框架。
- 像类似百度、谷歌这种大数据全文搜索引擎的场景都可以使用Elasticsearch作为底层支持框架,可见Elasticsearch提供的搜索能力确实强大,市面上很多时候我们简称Elasticsearch为es。
- Logstash是ELK的中央数据流引擎,用于从不同目标(文件/数据存储/MQ )收集的不同格式数据,经过过滤后支持输出到不同目的地(文件/MQ/redis/elasticsearch/kafka等)。
- Kibana可以将elasticsearch的数据通过友好的页面展示出来 ,提供实时分析的功能。
- 其中Elasticsearch是一个基于Lucene、分布式、通过Restful方式进行交互的近实时搜索平台框架。
-
市面上很多开发只要提到ELK能够一致说出它是一个日志分析架构技术栈总称 ,但实际上ELK不仅仅适用于日志分析,它还可以支持其它任何数据分析和收集的场景,日志分析和收集只是更具有代表性。并非唯一性。
收集清洗数据(Logstash) ==> 搜索、存储(ElasticSearch) ==> 展示(Kibana)

三、ElasticSearch核心概念
概述
1、索引(ElasticSearch)
- 包多个分片
2、字段类型(映射)
- 字段类型映射(字段是整型,还是字符型…)
3、文档
4、分片(Lucene索引,倒排索引)
ElasticSearch是面向文档,关系行数据库和ElasticSearch客观对比!一切都是JSON!
| Relational DB | ElasticSearch |
|---|---|
| 数据库(database) | 索引(indices)和数据库一样 |
| 表(tables) | types <慢慢会被弃用!> |
| 行(rows)数据 | documents |
| 字段(columns)字段 | fields |
elasticsearch(集群)中可以包含多个索引(数据库) ,每个索引中可以包含多个类型(表) ,每个类型下又包含多个文档(行) ,每个文档中又包含多个字段(列)。
物理设计:
elasticsearch在后台把每个索引划分成多个分片,每分分片可以在集群中的不同服务器间迁移
一个人就是一个集群! ,即启动的ElasticSearch服务,默认就是一个集群,且默认集群名为elasticsearch

逻辑设计:
一个索引类型中,包含多个文档,比如说文档1,文档2。当我们索引一篇文档时,可以通过这样的顺序找到它:索引 => 类型 => 文档ID ,通过这个组合我们就能索引到某个具体的文档。 注意:ID不必是整数,实际上它是个字符串。
文档(”行“ 一条条数据)
就是我们的一条条数据
之前说elasticsearch是面向文档的,那么就意味着索引和搜索数据的最小单位是文档,elasticsearch中,文档有几个重要属性:
- 自我包含,一篇文档同时包含字段和对应的值,也就是同时包含key:value !
- 可以是层次型的,一个文档中包含自文档,复杂的逻辑实体就是这么来的! {就是一个json对象 ! fastjson进行自动转换 !}
- 灵活的结构,文档不依赖预先定义的模式,我们知道关系型数据库中,要提前定义字段才能使用,在elasticsearch中,对于字段是非常灵活的,有时候,我们可以忽略该字段,或者动态的添加一个新的字段。
尽管我们可以随意的新增或者忽略某个字段,但是,每个字段的类型非常重要,比如一个年龄字段类型,可以是字符串也可以是整形。因为elasticsearch会保存字段和类型之间的映射及其他的设置。这种映射具体到每个映射的每种类型,这也是为什么在elasticsearch中,类型有时候也称为映射类型。
类型(“表”)
类型是文档的逻辑容器,就像关系型数据库一样,表格是行的容器。类型中对于字段的定义称为映射,比如name映射为字符串类型。我们说文档是无模式的,它们不需要拥有映射中所定义的所有字段,比如新增一个字段,那么elasticsearch是怎么做的呢?
- elasticsearch会自动的将新字段加入映射,但是这个字段的不确定它是什么类型,elasticsearch就开始猜,如果这个值是18,那么elasticsearch会认为它是整形。但是elasticsearch也可能猜不对,所以最安全的方式就是提前定义好所需要的映射,这点跟关系型数据库殊途同归了,先定义好字段,然后再使用,别整什么幺蛾子。
索引(“库”)
索引是映射类型的容器, elasticsearch中的索引是一个非常大的文档集合。 索引存储了映射类型的字段和其他设置。然后它们被存储到了各个分片上了。我们来研究下分片是如何工作的。
物理设计:节点和分片 如何工作
创建新索引

一个集群至少有一个节点,而一个节点就是一个elasricsearch进程,节点可以有多个索引默认的,如果你创建索引,那么索引将会有个5个分片(primary shard ,又称主分片)构成的,每一个主分片会有一个副本(replica shard,又称复制分片)

上图是一个有3个节点的集群,可以看到主分片和对应的复制分片都不会在同一个节点内,这样有利于某个节点挂掉了,数据也不至于失。实际上,一个分片是一个Lucene索引(一个ElasticSearch索引包含多个Lucene索引) ,一个包含倒排索引的文件目录,倒排索引的结构使得elasticsearch在不扫描全部文档的情况下,就能告诉你哪些文档包含特定的关键字。不过,等等,倒排索引是什么鬼?
倒排索引(Lucene索引底层) 每一个分片都是倒排索引,提高查询效率
简单说就是 按(文章关键字,对应的文档<0个或多个>)形式建立索引,根据关键字就可直接查询对应的文档(含关键字的),无需查询每一个文档,如下图(倒排索引直接把包含关键字的进行了分类,无需查询每一个文档了,提高效率)

四、IK分词器(elasticsearch插件)
IK分词器:中文分词器
分词:即把一段中文或者别的划分成一个个的关键字,我们在搜索时候会把自己的信息进行分词,会把数据库中或者索引库中的数据进行分词,然后进行一一个匹配操作,默认的中文分词是将每个字看成一个词(不使用用IK分词器的情况下),比如“我爱狂神”会被分为”我”,”爱”,”狂”,”神” ,这显然是不符合要求的,所以我们需要安装中文分词器ik来解决这个问题。
IK提供了两个分词算法: ik_smart和ik_max_word ,其中ik_smart为最少切分, ik_max_word为最细粒度划分!
1、下载
版本要与ElasticSearch版本对应
下载地址:https://github.com/medcl/elasticsearch-analysis-ik/releases
2、安装
ik文件夹是自己创建的
加压即可(但是我们需要解压到ElasticSearch的plugins目录ik文件夹下)

3、重启ElasticSearch
加载了IK分词器

4、使用 ElasticSearch安装补录/bin/elasticsearch-plugin 可以查看插件
E:\ElasticSearch\elasticsearch-7.6.1\bin>elasticsearch-plugin list

5、使用kibana测试
ik_smart:最少切分

ik_max_word:最细粒度划分(穷尽词库的可能)

从上面看,感觉分词都比较正常,但是大多数,分词都满足不了我们的想法,如下例
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-30BaQvNT-1658311487544)(E:\笔记\ES学习\es笔记图片\27.png)]
那么,我们需要手动将该词添加到分词器的词典当中
6、添加自定义的词添加到扩展字典中
elasticsearch目录/plugins/ik/config/IKAnalyzer.cfg.xml

打开 IKAnalyzer.cfg.xml 文件,扩展字典

创建字典文件,添加字典内容

重启ElasticSearch,再次使用kibana测试,可以看到我们自定义的那个词,已经可以识别出来了

五、Rest风格说明
一种软件架构风格,而不是标准,只是提供了一组设计原则和约束条件。它主要用于客户端和服务器交互类的软件。基于这个风格设计的软件可以更简洁,更有层次,更易于实现缓存等机制。
基本Rest命令说明:
| method | url地址 | 描述 |
|---|---|---|
| PUT(创建,修改) | localhost:9200/索引名称/类型名称/文档id | 创建文档(指定文档id) |
| POST(创建) | localhost:9200/索引名称/类型名称 | 创建文档(随机文档id) |
| POST(修改) | localhost:9200/索引名称/类型名称/文档id/_update | 修改文档 |
| DELETE(删除) | localhost:9200/索引名称/类型名称/文档id | 删除文档 |
| GET(查询) | localhost:9200/索引名称/类型名称/文档id | 查询文档通过文档ID |
| POST(查询) | localhost:9200/索引名称/类型名称/文档id/_search | 查询所有数据 |
测试
1、创建一个索引,添加
PUT /lzhtest/type/1
{
"name" : "lzh",
"age":25
}
使用方式:put /索引名称/类型名称/文档的id
{
以json格式存放文档里面的属性
}
执行如下所示:

刷新可视化工具,可以看到已经成功创建了索引:

点击数据预览,可以看到我们创建的索引,以及里面存放的数据信息

2、字段数据类型
-
字符串类型
-
text、
keyword
- text:支持分词,全文检索,支持模糊、精确查询,不支持聚合,排序操作;text类型的最大支持的字符长度无限制,适合大字段存储;
- keyword:不进行分词,直接索引、支持模糊、支持精确匹配,支持聚合、排序操作。keyword类型的最大支持的长度为——32766个UTF-8类型的字符,可以通过设置ignore_above指定自持字符长度,超过给定长度后的数据将不被索引,无法通过term精确匹配检索返回结果。
-
-
数值型
- long、Integer、short、byte、double、float、half float、scaled float
-
日期类型
- date
-
te布尔类型
- boolean
-
二进制类型
- binary
-
等等…
3、指定字段的类型(使用PUT)
类似于建库(建立索引和字段对应类型),也可看做规则的建立
创建 lzhtest2 索引,并指定字段类型
PUT /lzhtest2
{
"mappings": {
"properties": {
"name":{
"type":"text"
},
"age":{
"type":"integer"
},
"birthday":{
"type":"date"
}
}
}
}
如下所示:

4、获取建立的规则
GET lzhtest2
get 后面跟索引名称的话,获取的是索引的信息,也可以直接获取文档的信息
获取索引的建立规则

_doc默认类型(default type),type 在未来的版本中会逐渐弃用,因此产生一个默认类型进行代替
PUT /lzhtest3/_doc/1
{
"name":"lzh",
"age":18,
"birthday":"2005-05-03"
}

如果自己的文档字段没有被指定,那么ElasticSearch就会给我们默认配置字段类型

扩展:通过get _cat/ 可以获取ElasticSearch的当前的很多信息!
/_cat/allocation
/_cat/shards
/_cat/shards/{index}
/_cat/master
/_cat/nodes
/_cat/tasks
/_cat/indices
/_cat/indices/{index}
/_cat/segments
/_cat/segments/{index}
/_cat/count
/_cat/count/{index}
/_cat/recovery
/_cat/recovery/{index}
/_cat/health
/_cat/pending_tasks
/_cat/aliases
/_cat/aliases/{alias}
/_cat/thread_pool
/_cat/thread_pool/{thread_pools}
/_cat/plugins
/_cat/fielddata
/_cat/fielddata/{fields}
/_cat/nodeattrs
/_cat/repositories
/_cat/snapshots/{repository}
/_cat/templates
6、修改
两种方案
①旧的(使用put覆盖原来的值)
- 版本+1(_version)
- 状态会变成update
- 但是如果漏掉某个字段没有写,那么更新是没有写的字段 ,会消失
PUT /lzhtest/type/1
{
"name" : "lzh as 小梁同学",
"age":25
}
GET lzhtest/type/1
如下所示

②新的(使用post的update)
- version不会改变
- 需要注意doc
- 不会丢失字段
POST /lzhtest3/_doc/1/_update
{
"doc":{
"name":"lzh-->小谢老师"
}
}
如下所示:

7、删除索引
DELETE lzhtest

8、查询(简单条件)
GET /test3/_doc/_search?q=name:流柚
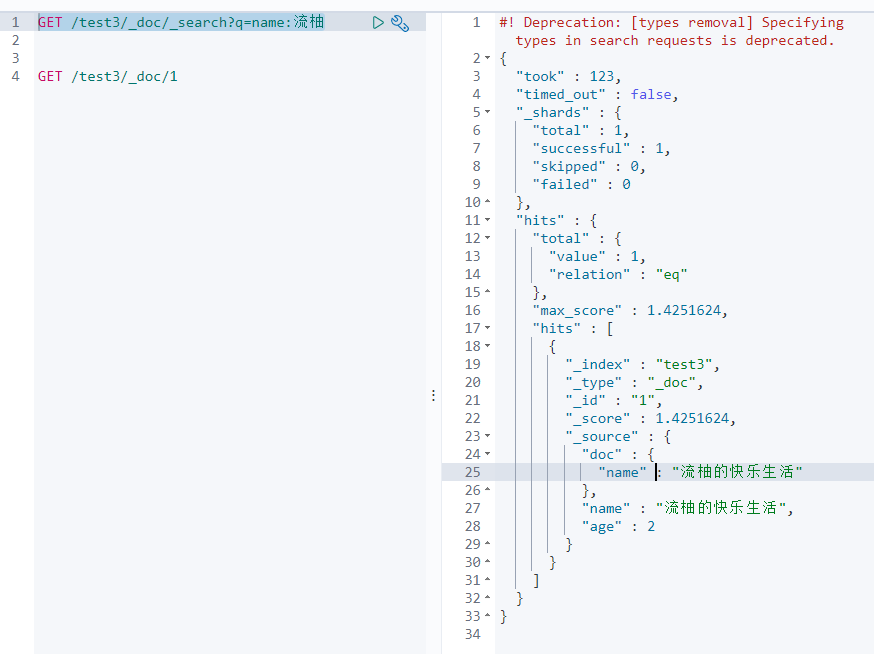
9、复杂查询
添加数据

lzhtest索引中的内容

①查询匹配
match:匹配(会使用分词器解析(先分析文档,然后进行查询))_source:过滤字段sort:排序form、size分页
GET /lzhtest/_search
{
"query": {
"match": {
"name": "糖"
}
}
, "_source": ["name","description","age"]
, "sort": [
{
"age": {
"order": "desc"
}
}
],
"from": 0,
"size": 1
}
match(匹配):分析查询出的json字符串相关内容:

_source ,过滤 ,相当于我们在数据库里面查询指定的字段 ,select name ,description from

sort :排序,根据某个字段进行排序

from ,size 分页:

②多条件查询(bool)
must相当于andshould相当于ormust_not相当于not (... and ...)filter过滤
GET lzhtest/_search
{
"query": {
"bool": {
"filter": {
"range": {
"age": {
"gte": 1,
"lte": 5
}
}
}
}
}
}
GET lzhtest/_search
{
"query": {
"bool": {
"must_not": [
{
"match": {
"name": "棉花糖"
}
},
{
"match": {
"age": "10"
}
}
]
}
}
}
GET /lzhtest/_search
{
"query": {
"bool": {
"should": [
{
"match": {
"name": "棉花糖"
}
},
{
"match": {
"age": "18"
}
}
]
}
}
}
GET /lzhtest/_search
{
"query": {
"match": {
"name": "糖"
}
}
, "_source": ["name","age","description"]
, "sort": [
{
"age": {
"order": "desc"
}
}
],
"from": 0
, "size": 1
}
GET /lzhtest/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"name": "棉花糖的孩子"
}
},
{
"match": {
"description": "人员"
}
},
{
"match": {
"age": "18"
}
}
]
}
}
}
must 相当于 sql中的 and

should 相当于 or

must_not 相当于sql 中的not(条件A and 条件B)

bool 多条件中使用filter 进行某个字段的数据过滤

③匹配数组
- 貌似不能与其它字段一起使用
- 可以多关键字查(空格隔开)— 匹配字段也是符合的
match会使用分词器解析(先分析文档,然后进行查询)- 搜词
GET lzhtest/_search
{
"query": {
"match": {
"tags": "小 调皮"
}
}
}

④精确查询
term直接通过 倒排索引 指定词条查询- 适合查询 number、date、keyword ,不适合text
// 精确查询(必须全部都有,而且不可分,即按一个完整的词查询)// term 直接通过 倒排索引 指定的词条 进行精确查找的GET GET lzhtest/_search
{
"query": {
"term": {
"tags": {
"value": "糖 "
}
}
}
}

⑤text和keyword
- text:
- 支持分词,全文检索、支持模糊、精确查询,不支持聚合,排序操作;
- text类型的最大支持的字符长度无限制,适合大字段存储;
- keyword:
- 不进行分词,直接索引、支持模糊、支持精确匹配,支持聚合、排序操作。
- keyword类型的最大支持的长度为——32766个UTF-8类型的字符,可以通过设置ignore_above指定自持字符长度,超过给定长度后的数据将不被索引,无法通过term精确匹配检索返回结果。
⑥高亮查询
GET lzhtest/_search
{
"query": {
"match": {
"name": "糖"
}
}
, "highlight": {
"pre_tags":"<p style = 'color :red'>"
, "post_tags": "</p>"
, "fields": {"name": {}}
}
}
GET lzhtest/_search
{
"query": {
"match": {
"name": "糖"
}
}
, "highlight": {
"fields": {"name": {}}
}
}

自定义高亮显示标准:
















 660
660











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









