







 flume从kafka采集数据到hdfs,flume拦截器解析数据时间到指定的分区
flume从kafka采集数据到hdfs,flume拦截器解析数据时间到指定的分区
Flume配置及拦截器
一、 Flume消费数据到hdfs再load到hive分区表的操作流程
方式一、flume消费数据到hdfs并映射到hive表
1、flume配置
# Name the components on this agent
agent.sources = kafka-source
agent.channels = memory-channel
agent.sinks = hdfs-sink
# Describe/configure the source
agent.sources.kafka-source.type = org.apache.flume.source.kafka.KafkaSource
#每次拉取的数据量为1000
agent.sources.kafka-source.batchSize = 1000
agent.sources.kafka-source.kafka.bootstrap.servers = localhosts:9092
agent.sources.kafka-source.kafka.topics = test
agent.sources.kafka-source.kafka.consumer.group.id = kafka-hdfs-test
agent.sources.kafka-source.kafka.consumer.auto.offset.reset = latest
# Describe/configure the channel
agent.channels.memory-channel.type = memory
agent.channels.memory-channel.capacity = 10000
agent.channels.memory-channel.transactionCapacity = 1000
# Describe the sink
agent.sinks.hdfs-sink.type = hdfs
#文件前缀
agent.sinks.hdfs-sink.hdfs.filePrefix = logs-
agent.sinks.hdfs-sink.hdfs.round = true
#开启时间上的舍弃,每天创建一个文件夹
agent.sinks.hdfs-sink.hdfs.roundValue = 1
agent.sinks.hdfs-sink.hdfs.roundUnit = day
#使用本地时间戳
agent.sinks.hdfs-sink.hdfs.useLocalTimeStamp=true
#agent.sinks.hdfs-sink.hdfs.writeFormat = Text
agent.sinks.hdfs-sink.hdfs.path = /test/hdfs/test_hdfs01/dt=%Y%m%d
#agent.sinks.hdfs-sink.hdfs.fileSuffix = .jsonl
agent.sinks.hdfs-sink.hdfs.rollInterval = 600
agent.sinks.hdfs-sink.hdfs.rollSize = 0
agent.sinks.hdfs-sink.hdfs.rollCount = 1000
agent.sinks.hdfs-sink.transactionCapacity = 1000
agent.sinks.hdfs-sink.hdfs.fileType = DataStream
agent.sinks.hdfs-sink.hdfs.writeFormat = Text
# Bind the source and sink to the channel
agent.sources.kafka-source.channels = memory-channel
agent.sinks.hdfs-sink.channel = memory-channel
2、hive表创建
create external table if not exists test.test_hdfs(
id string,
name string,
createtime string
)
partitioned by (dt string)
row format delimited fields terminated by ’ ’
lines terminated by ‘\n’
stored as textfile
location ‘/test/hdfs/test_hdfs/’;alter table test.test_hdfs add partition (dt = ‘20230925’) ; //注意这里dt跟目录的dt分区保持一致
3、hive表查询
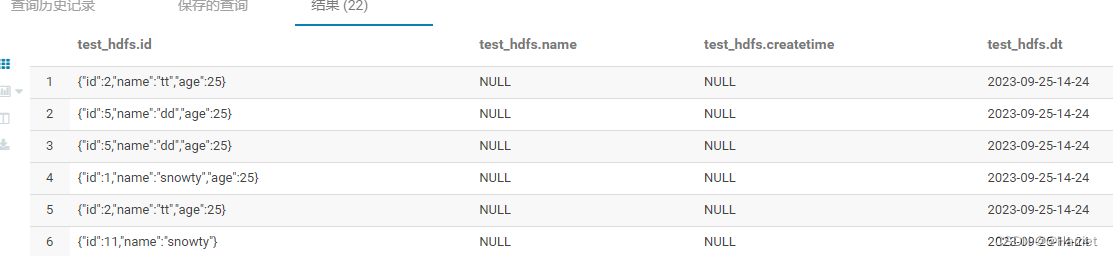
方式二、flume消费数据到hdfs并映射到hive表,查询时json数据被解析
1、flume配置
flume配置同上
2、hive表创建
CREATE EXTERNAL TABLE test.test_hdfs01(
id INT,
name STRING,
createtime STRING)
partitioned by (dt string)
ROW FORMAT SERDE ‘org.apache.hive.hcatalog.data.JsonSerDe’
stored as textfile
LOCATION ‘/test/hdfs/test_hdfs01/’;
3、hive表查询
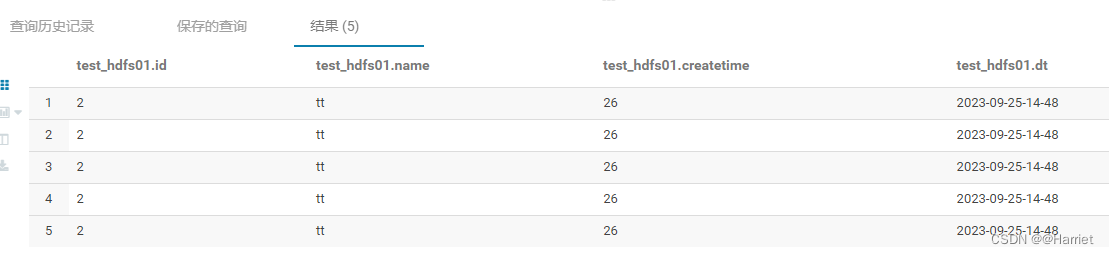
方式二查询的数据被解析,其实hdfs存储格式还是json
二、flume时间戳拦截器
拦截器根据数据时间选择分区,即使数据乱序也可以进入准确地分区
1、拦截器编码
pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.example</groupId>
<artifactId>flume_interceptor_test</artifactId>
<version>1.0-SNAPSHOT</version>
<packaging>jar</packaging>
<properties>
<!-- <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>-->
<compiler.version>1.8</compiler.version>
<flume.version>1.9.0</flume.version>
<fastjson.version>1.2.73</fastjson.version>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target> 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









