










在这里插入图片描述
架构演进:
一、开发环境&生成环境
1. 开发环境
平时在写代码时,大多都在是win10/win7/Mac,这些系统都可以称呼开发环境,我们会为了更高效的开发应用程序,安装很多的软件,会导致操作系统不安全,稳定性降低。
2. 生成环境
在生产环境中,操作系统不会采用win10/Mac,这种操作系统相对不安全,生成环境要面向全体用户的,生产环境是要面向用户的,一般会采用专业操作系统。
大多市面上使用的都是基于Linux版本的服务器操作系统Windows 2003 service
二、WEB1.0&WEB2.0阶段
2.1web1.0时期
在WEB1.0时期,由于带宽不足,这是的项目大多是内容少,用户量也不多,甚至一些项目不需要对外开放,对安全性和稳定性的要求是不高的。
单体架构就足以应对,
2.WEB2.0时期
2.1、随之到来的web2.0,实现下ADSL拨号上网,宽带提速,最高可以达到8M,用户量也就不断增加,一些门户网站也开始活跃,项目就需要考虑安全性和稳定性。
2.2、在基于上面的单体架构图中,无法满足WEB2.0对项目的需求。
在单体架构的基础上去构建集群。

2.3、搭架集群后发生的问题


三、垂直架构
比如项目包含了三个模块,用户模块,商品模块,订单模块
商品模块压力过大,一般最直接有效的方式就是搭建集群,在单体架构的集群上去搭建,效果相对比较差。
随着项目的不断更新,项目中的功能越来越多,最严重可能会导致项目无法启动。
关于单体架构中,完美的体现了低内聚,高耦合。
为了解决上诉各种问题,演进出了垂直架构。

四、分布式架构
4.1项目迭代
随着项目的不断迭代,新考功能之间需要相互交互,服务器和服务器之间是需要通讯的。
项目一般是分为三层的,Controller,Service,Dao,导致程序变慢的重灾区,一般是Service和Dao,在搭建集群时,确实针对三层都搭建集群,效果不是很好。
架构从垂直架构演变到了分布式架构。
国内通讯的方式有两种:
Dubbo RPC
SpringCloud HTTP

五、分布式架构常见问题
5.1服务之间的异步通讯
使用分布式架构之后,服务之间的通讯都是同步的。
在一些不是核心业务的功能上,我们希望可以实现异步通讯(如:日志)。
为了实现服务之间的异步通讯,需要学些MQ-RabbitMQ(RabbitMQ:消息队列)。
分布式架构下,实现异步通讯:

5.2服务之间通讯地址的维护
由于服务越来越多,每个服务的访问地址多是一样的。
协议://地址:端口号
由于模块繁多,并且模块搭建的集群数量增加,会导致其他模块需要维护各种ip地址等信息,导致项目的维护性急需要使用一个技术来解决当前问题:
Eureka注册中心帮助我们管理服务信息。
Robbin可以帮我们实现服务之间的负载均衡
Erueka实现通讯地址维护
Robbin实现服务之间的负载均衡

5.3服务降级
在上述的架构中,如果说订单模块出现了问题。
只要是涉及到订单模块的功能,全部都无法使用。
可能会导致服务器提供的线程池耗尽。
为了解决上述的问题,使用Hystrix处理。
Hystrix提供了线程池隔离的方式,避免服务器线程池耗尽在一个服务无法使用时,可以提供断路器的方式来解决。
使用Hystrix帮我们实现断路器和隔壁,并最终服务降级

Eureka,Robbin,Hystrix都是SpringCloud中的组件
海量数据
海量数据会导致数据库无法存储全部的内容。
即便数据库可以存储海量的数据,在查询数据时,数据库的响应时及其缓慢的。
在用户高并发的情况下,数据库也时无法承受住的。
为了解决上述的问题,可以基于MyCat实现数据库的分库分表。

六、微服务架构
虽然已经将每个模块独立的做开发,比如商品模块,压力最大的时商品的查询。
在单独模块中再次拆分项目的方式就可以称之为微服务架构。

6.2模块过多,运维成本增加
为了解决模块过多,运维成本增加的问题。
采用Docker容器化技术来帮助我们管理。
后期在学习的时候,也需要大量的软件,可以使用Docker来帮助我们安装软件。

6.3分布式架构下的其他问题
分布式架构帮助我们解决了很多的问题,但是随之也带来了很多问题。
1、分析事事务:
最传统的操作事务的方式,是通过Connection链接对象的方式操作,Spring也提供了声明式事务的操作。为了解决事务的问题,后续会使用到RabbitMQ|LCN方式来解决。
2、分布式锁:
传统的锁方式,synchronized|Lock锁,基于对象;在分布式环境下,传统的锁是没有效果的,为了解决锁的问题,后续会使用到Redis|Zookeeper来解决。
3、分布式任务:
在传统的定时任务下,由于分布式环境的问题,可能会造成任务重复执行,一个比较大的任务,需要可以拆分。
为了解决这个问题,后续会使用到Redis+Quartz|Elastic-Job。


Linux介绍
一、Linux介绍
1.1引言
在学习Linux之前,大家先了解开发环境,生成,测试环境。
1、开发环境:平时大家大多是在Windows或者Mac操作系统下去编写代码进行开发,在开发环境中安装大量的软件,这样导致环境的稳定性和安全性降低。
2、生成环境:是将程序运行在此环境中,供用户去使用,这个环境是有专业的人员去维护,一般人是没有权限去操作生产环境的。
3、测试环境:一般克隆一份生产环境,会将开发环境中的程序部署到环境中,这个环境的主要目的是去程序进程检测,收集程序中的各种问题,并交给开发人员进行修改。
生产环境中,常用的操作系统比如有Windows 2003 service,Linux,Unix等等。
Linux操作系统,在生产环境中占据了大量的市场份额,Linux主要以稳定,可靠,免费的特点成为全球使用最多的服务器操作系统。
Linux操作系统现在已经成为后待开发人员必备的技能,并且后期学习的各种知识都会涉及到Linux操作系统。
Linux介绍
在Linux操作系统出现之前,还有一个操作系统叫做Minix,Minix操作系统是由Andrew的大学教授研发出来的,当时大学教授是为了给学生上课,买了一套Unix操作系统,参考Unix自己写了一个操作系统,并且命名为Minix。同时将Minix开源,供学校内部的研究和教学,到了2000年,Andrew将Minix操作系统完全对外开源。
Minix由于完全对外开源之后,在互联网上迅速的传播,但是大家在使用时,发现Minix不是很完美,内部存在各种各样问题。用户将问题解决后,编写了一个补丁,将补丁以邮件的方式发给Andrew,但是Andrew教室最初的目的只是为了教学和研究。
于此同时,一位芬兰的大学生出现了,叫Linus,在Minix操作系统基础上,自己添加了一些补丁和插件,并将其命名为Linux操作系统,并且完全对外开源,而且开始维护Linux操作系统。
之前学习的Git也是Linus研发的。
Linus Torvalds 和 Linux

1.3Linux的版本
1、Linux的内核版本。
https://www.kernel.org/
2、Linux的发行版本。
我们需要学习的发行版本就是CentO S
Linux的发行版本

1.4Linux和Windows区别
1、Linux是严格区分大小写的,Windows无所谓。
2、Linux中一切皆是文件。
3、Linux中文件是没有后缀的,但是他有一些约定俗成的后缀
4、Windows下的软件一般是无法直接运行的Linux中。
我们在学习Linux时,参考Windows下做了什么,就在Linux中做什么。
二、Linux安装
1、安装Linux,我们需要一个虚拟机,为了安装虚拟环境:VMware或者Virtual Box(采用VMware)
VMware官网:https://www.vmware.com


2、为了安装Linux,需要一个Linux的镜像文件:CentOS7版本
下载地址:http://mirrors.163.com/centos/7/isos/x86_64/CentOS-7-x86_64-Minimal-2003.iso




3、安装一个连接Linux的图形化界面:Xterm,SSH,XShell(Xterm)
Xterm:https://mobaxterm.mobatek.net/download.html

2.1安装VMware
傻瓜式安装。
2.2安装Xterm
解压既可以使用
2.3在Vmware安装Linux
1、选择典型,下一步





安装好以后配置一下虚拟机右击虚拟机:




启动



然后输入账号密码就好了。
2.4使用Xterm连接Linux
通过ip a命令查看当前Linux的ip地址,通过Xterm连接。



打开Xtrem,选择左上角的Session,并且输入Linux操作系统的ip地址,在输入用户名root,确定即可。
连接上Linux

三、Linux基本操作
Windows的目录结构是带有盘符的。D: E: C:
在Xterm中输入ls /查看Linux的顶级目录。

Linux目录树状图

1、root:该目录为系统管理员HOME目录
2、bin:这个目录下放着经常使用的命令
3、boot:这里存放的是启动Linux是的一些核心文件
4、etc:存放系统管理所需要的配置文件和子目录
5、home:普通用户的HOME目录
6、usr:默认安装软件的目录,类似Windows中的Program Files目录
7、opt:是主机额外安装软件拜访的目录;
3.2获取Linux中的信息
1、我是谁
who an i
2、我在哪
pwd
3、查看ip地址
ip a
4、清屏
clear
5、ping域名|ip
ping 地址
6、强制停止
Ctrl+C
四、Linux命令
Linux中命令的基本格式:命令【选项】【参数】
需要注意,个别命令是不遵循这个格式
当命令中有多个选项时,可以写在一起的,并且选项也是由简写方式的 命令 -选项A选项B
4.1目录的命令
#l. 列出目录
ls [-ald] [目录名]
#目录名不填写,默认为当前目录
#-a:列出的全部的文件,包括隐藏文件
#-l:列举出全部的信息
#-d:仅查看目录本身
#Linux中的隐藏文件是以. 开头的,当前目录使用.表示,上一级目录使用…表示
4.2切换目录
#切换目录
cd 路径 | 符号
#路径可以填写的内容
| 符号 | 表达的路径 |
|-.-|-当前目录-|
| .. | 上一级目录 |
| / | 根目录 |
| ~ | 当前登录用户的HOME目录 |
| - | 返回 |
#3、创建目录
mkdir [-p] 目录名
#-p:代表创建多级目录时,使用
#4、删除目录
rmdir 目录名
#只能删除空目录
rm [-rf] 目录名
#删除非空目录
#-r:代表递归删除目录下的全部内容
#-f:不询问,直接删除
#5、复制目录
cp -r 来源目录 目标目录
#-r:递归复制全部内容
#6、移动、重命名目录
mv 目录名 新目录名
mv 目录名 路径
#如果第二个参数不存在,就是重命名,如果第二个参数的路径存在,就是移动。
4.2文件的命令
#1、创建文件
touch 文件名
touch 文件名1 文件名2
#2、编辑文件
vi 文件名 #查看文件、(查看模式)
i|a|o #进入编辑模式,(编辑模式)
#i:在当前光标处,进入编辑模式; a:在当前光标后一格,进入编辑模式; o:在当前光标下一行,进入编辑模式。
esc #退出编辑模式,回到查看模式。
: #从查看模式进入到底行命令模式。(底运行命令模式)
#在底行命令模式下,输入wq: 保存并退出。输入q!: 不保存并退出。
#在查看模式下,按ZZ,可以快速保存并退出。
#3、在编辑文件时的其他操作
在底行命令模式下,可以输入的内容
set nu #查看文件的行号
to 行号 #快速的跳转到指定行
set nonu #取消行号
#直接在查看模式下输入
/具体内容 #类似Windows的Ctrl+F搜索文件中的具体内容所在位置,查看下一个可以输入字母n
#4、查看文件
cat 文件名
#从第一行开始查看文件内容,展示全部
tac 文件名
#从最好一行开始展示
nl 文件名
#显示文件的时候,展示行号
more 文件名
#查看大文件时,可以一页一页的向下翻
#按space向上翻页,退出时按q
less 文件名
#查看大文件时,可以任意的向上或向下翻
#向上或向下翻页按PageUp和PageDown,一行一行查看,按光标的↑↓
head 文件名
#只查看前几行
tail 文件名
#只查看后几行
#tail -f 日志 监控日志
#5、移动、重命名文件
mv 文件名 新文件名
mv 文件名 目录
#6、复制文件
cp 文件 目录
#7、删除文件
rm [-f] 文件名
#[-f]是否询问
#8、删除文件夹
rm -rf 目录名
4.3针对压缩包的操作
Linux中常用的压缩包,大多是.tar,.tar.gz,taz的。
但是Linux不仅仅针对tar类型的压缩包,也支持zip,rar这种Windows下的压缩包。
4.3.1针对tar命令
#针对tar类型的压缩包操作
#1、解压压缩包
tar -[zxvf]压缩包名称[-C 路径]
# -z:代表压缩包后缀是.gz的
# -x: 代表解压
# -v: 解压时,打印详细信息
# -f: -f选项必须放在所有选项的最后,代表指定文件名称
# -C 路径: 代表将压缩包内容解压到指定路径
#2、打包压缩包。
tar [-zcvf] 压缩包名称 文件1 文件2 目录1 目录2
4.3.2针对zip压缩包
Linux默认不支持zip压缩包格式的。
安装两个软件:
zip,unzip
yum -y install zip
yum -y install unzip
#解压
unzip 压缩包名称
#打包
zip 压缩包名称 文件1 文件2 目录1 目录2 ....
4.4用户&用户组的操作
Linux是一个多用户的操作系统,任何一个用户想要操作Linux操作系统,必须向系统管理员申请一个账号才可以,以这个账号的身份去操作Linux。
用户的账号一方面可以帮助系统管理员追踪当前用户的操作,另一方面可以控制当前用户对系统资源访问。
4.4.1 用户的操作
#1、创建用户
useradd 用户名
#2、设置密码
passwd 用户名
#3、切换用户
su 用户名
#[root@localhost ~]# ->root用户在本地登录,并且当前在~目录下,#代表是超级管理员
#[liuwenzhen@localhost ~]$ ->liuwenzhen用户在本地
#4、删除用户
userdel [-r] 用户名
# -r :代表删除用户的同时,删除该用户的HOME目录
#5、修改用户(了解)
usermod [-cgd] [选项指定的具体内容] 用户名
# -c:代表comment,给用户添加一段注释
# -g:代表group,可以修改用户的所在组
# -d:代表指定用户的HOME目录
4.4.2用户组的操作
#1、创建用户组
groupadd 用户组名
#2、修改用户组
groupmod [-n] 用户组名
#-n:修改用户组名称
#3、删除用户组
groupdel 用户组名称
#只能删除不存在用户的用户组
4.5文件权限的修改
在Linux中输入ls -l或者ll查看文件和目录的详细信息。

实例中,a目录的第一个属性用“d”标识这个a是一个目录
anacinda-ks.cfg第一个属性用“-”标识他是一个文件
在Linux文件详情的后面属性需要分为三组查看
- rwx:代表文件拥有者的权限
- rwx:代表文件所属组用户的权限
- rwx:代表其他用户对当前文件的操作权限
- r:daibiaoread,读的权限
- w:代表write,写的权限
- x:代表execute,代表执行权限
后续的第一个root:代表当前文件的拥有者
后续的第二个root:代表当前文件的所属组
或许分别为:文件的大小和最好修改时间
4.5.1对文件的权限修改
使用chmod对文件的权限进行修改,一种使用数字,一种使用符号。
#1、数字方式
chmod [-R] 777 文件|目录
# rwx在这三个权限中r:4,w:2,x:1
# -R:当修改一个目录权限时,可以添加-R,将目录下的全部内容,都修改权限。
#2、符号方式
#user:u,group:g,other:o,all:a
#read:r,write:w,execute:x
#赋予权限的方式
# 添加:+,减掉:-,设定:=
chmod [-R] a+r,a+w 文件|目录
4.5.2对文件的拥有者和所属组修改
#修改文件的拥有者和所属组
chown [-R] 拥有者:所属组 文件|目录
#修改文件的拥有者
chown [-R] 拥有者 文件|目录
#修改文件的所属组
chgrp [-R] 所属组 文件|目录
4.6Linux的其他操作命令
#1、进程的操作
ps -ef
# 查看全部正在运行的进程
ps -ef|grep 搜索的内容
#杀死进程
kill -9 Pid
#2、服务的操作
#针对服务的启动,停止,重启,开机自动启动,禁止开机自动启动,查看服务状态。
systemctl start|stop|restart|enable|disable|status 服务名称
#3、查看端口号占用情况
#向使用指定的命令需要实现下载netstat
yum -y install net-tools
#查看端口号占用情况
netstat -naop | grep 端口号
#4、访问地址
curl 访问地址
#5、查找文件
find 路径 -tyep f|grep profile
五.Linux下安装软件
5.1安装JDK
#1、下载JDK的压缩包
https://www.oracle.com/java/technologies/javase/javase-jdk8-downloads.html#license-lightbox
#需要去登陆后,才可以下载
#2、将下载好的jdk压缩包拉取到Linux操作系统中
# 通过Xterm或FileZilla携带的Sftp将jdk压缩包拖拽到Linux操作系统
#3、将jdk的压缩包解压到/usr/local
tar -zxvf jdk-8u241-linux-x64.tar.gz -C /usr/local
#4、将jdk的目录名修改一下
cd /usr/local
mv jdk1.8.1_241 jdk
#5、配置环境变量
#Linux提供了两种环境变量的文件
#第一个是用户级别的环境变量,存放在:~/.bashrc
#第二个是系统级别的环境变量,存放在:/etc/profile
#如果想运行当前目录下的可执行文件,需要输入:./可执行文件
#在环境变量文件中,添加如下内容
export JAVA_HOME=/usr/local/jdk (/user/local/jdk:jdk的路径)
export PATH=$JAVA_HOME/bin:$PATH
#重新加载环境变量文件
source /etc/profile
#将/etc/profile文件如何还原
export PATH=/bin:/usr/local/sbin:/usr/local/bin:/sbin:/bin:/usr/sbin:/usr/bin
#最终测试
java -version

5.2安装MySQL
#1、安装MySQL的YUM存储库
#首先通过ym下载wget命令
yum -y install wget
#通过wget下载MySQL存储库
wget https://dev.mysql.com/get/mysql80-community-release-el7-3.noarch.rpm
#2、安装下载好的rpm包
#安装rpm包
rpm -Uvh rpm包(rpm包:mysql80-community-release-el7-3.noarch.rpm)
#查看rpm包
rpm -qa |grep 内容
#卸载rpm
rpm -e --nodeps rpm名称
#3、选择发行版本
#查看一下默认选择的发行版本
yum repolist all | grep mysql
#通过编辑/etc/yum.repos.d/mysql-community.repo文件,去修改发行版本
#80的enabled更改为0,将57的enabled更改为1,保存即可,再次通过yum repolist all | grep mysql查看
#效果如下:

#4、安装MySQL社区版服务
yum -y install mysql-community-server
#5、启动MySQL服务器,并连接
#启动MySQL服务
systemctl start mysqld.service
#查看初始化密码
grep 'temporary password' /var/log/mysqld.log
#通过使用生成的临时密码登录并尽快为超级用户帐户设置自定义密码,以更改root密码:
mysql -uroot -p
Enter password:随机密码
#修改密码
mysql>ALTER USER 'root'@'localhost' IDENTIFIED BY 'Lwz1234@';
#这将要求密码至少包含一个大写字母,一个小写字母,一位数字和一个特殊字符,并且密码总长度至少为8个字符。
#6、开启远程连接,并使用图形化界面操作
#创建一个账号 名称:erid 密码:Lwz1234@ %:无论在那都可以连接
mysql> GRANT ALL PRIVILEGES ON *.* TO 'erid'@'%' IDENTIFIED BY 'Lwz1234@' WITH GRANT OPTION;
mysql> FLUSH PRIVILEGES;
#使用图形化界面连接linux系统上的mysql数据库时需要将linux系统的防火墙关闭
#关闭防火墙
systemctl stop firewalld.service
#关闭防火墙开启自启
systemctl disable firewalld.service
5.3安装Tomcat
#1、下载Tomcat的压缩包([apcche官网下载](https://tomcat.apache.org/download-80.cgi))
wget https://mirror.bit.edu.cn/apache/tomcat/tomcat-8/v8.5.60/bin/apache-tomcat-8.5.60.tar.gz
#2、解压压缩包到/usr/local
tar -zxvf apache-tomcat-8.5.53.tar.gz -C /usr/local
#3、启动Tomcat并监听日志
#跳转到tomcat的bin目录
cd /usr/local/apache-tomcat-8.5.53/bin
#启动
。/startup.sh
#监控日志
cd ./logs
tail -f catalina.out
#启动成功如下:


六、部署SSM工程
部署项目到Linux中需要注意一下内容:
1、项目要保证在Windows下时没有问题的,再考虑部署到Linux。
2、将开发环境中的内容更改为测试环境。
1、连接数据库的信息
2、存放文件的路径
3、日志文件存放的位置
4、项目路径问题
3、将Maven项目打包。
4、根据项目路径的不同,将项目部署到Tomcat中。
5、在部署到Linux操作系统中后,一定要查看日志。

Docker

一、Docker介绍
1.1引言
1、我本地运行没问题啊
环境不一致
2、那个哥们又写死循环了,怎么这么卡
在多用户的操作系统下,会相互影响。
3、淘宝在双11的时候,用户量暴增。
运维成本过高的问题
4、学习一门技术,学习安装成本过高。
关于安装软件成本过高。
1.2Docker的由来
一帮年轻人创业,创办了一家公司,2010年的专门做PAAS平台。
到了2013年的时候,像亚马逊,微软,Google都开始做PAAS平台。
2013年,将公司内的核心技术对外开源,核心技术就是Docker。
到了2014年的时候,得到了C轮的融资,$4000W
到了2015年的时候,得到了D轮融资,$9500W
全神贯注的维护Docker。
所罗门主要作者之一。

Docker的作者已经离开了维护Docker的团队

1.4Docker的思想
1、集装箱:
会将所有需要的内容放到不同的集装箱中,谁需要这些环境就直接拿到这个集装箱就可以了。
2、标准化:
1.运输的标准化:Docker有一个码头,所有上传的集装箱都放在了这个码头上,当谁需要某一个环境,就直接指派大海豚去搬运这个集装箱就可以了。
2.命令的标准化:Docker提供了一些列的命令,帮助我们去获取集装箱等等操作。
3.提供了REST的API:衍生出了很多的图形化界面,Rancher。
3、隔离性:
Docker在运行集装箱内的内容时,会在Linux的内核中,单独的开辟一片空间不会影响到其他程序。

- 注册中心。(超级码头,上面放的就是集装箱)
- 镜像。(集装箱)
- 容器。(运行起来的镜像)
二、Docker的基本操作
#1、下载关于Docker的依赖环境
yum -y install yum-utils device-mapper-persistent-data lvm2
#2、设置一下下载Docker的镜像源
yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
#3、安装Docker
yum makacache fast
yum -y install docker-ce
#4、启动,并设置为开机自动启动,测试
#启动Docker服务
systemctl start docker
#设置开机自动启动
systemctl enable docker
#测试
docker run hello-world
2.2Docker的中央仓库
1、Docker官方的中央仓库:这个仓库时镜像最全的,但是下载速度较慢。
https://hub.docker.com
2、国内的镜像网站:网易蜂巢,daoCloud...
https://c.163.com/hub#/home
http://hub.daocloud.io
3、在公司内部会采用私服的方式拉去镜像。
#在公司内部会采用私服的方式拉去镜像
#需要在/etc/docker/daemon.json
{
"registry-mirrors":["https://registry.docker-cn.com"],
"insecure-registries":["ip:port"]# ip:公司的ip;port:公司的端口号
}
#重启两个服务
systemctl daemon-reload
systemctl restart docker
2.3镜像的操作
#拉去镜像到本地
docker pull 镜像名称[:tag]
#举个例子
#daocloud.io/library/tomcat:8.5.16-jre8 拉取的东西
docker pull daocloud.io/library/tomcat:8.5.16-jre8
#2、查看全部本地的镜像
docker images
#3、删除本地镜像 镜像的标识:IMAGE ID
docker rmi 镜像的标识
#镜像的导入导出(不规范)
#将本地的镜像导出
docker save -o 导出的路径 镜像id
#加载本地的镜像文件
docker load -i 镜像文件
#修改镜像名称
docker tag 镜像id 新镜像名称:版本号
2.4 容器的操作
#1、运行容器
#简单操作
docker run 镜像的标识|镜像名称[:tag]
#常用的参数
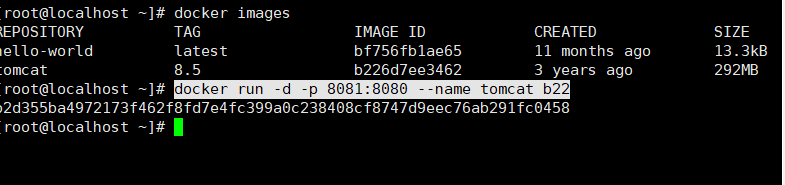
docker run -d -p 宿主机端口:容器端口 --name 容器名称 镜像的标识|镜像名称[:tag]
#-d:表示后台运行容器
#-p 宿主机端口:容器端口:为了映射当前Linux的端口和容器的端口
#--name 容器名称:指定容器的名称

#2、查看你正在运行的容器
docker ps [-qa]
#-a:查看全部的容器,包括没有运行
#-q:只查看容器得到标识
#3、查看容器的日志
docker logs -f 容器id
#-f:可以滚动查看日志的最后几行
#4、进入到容器内部
docker exec -it 容器id bash

#5、删除容器
docker stop 容器id
#停止指定的容器
docker stop $(docker ps -qa)
#停止全部容器
docker rm 容器id
#删除指定容器
docker rm $(docker ps -qa)
#删除全部容器

#6、启动容器
docker start 容器id
三、Docker应用
3.1准备SSM工程
#MySql数据库的连接用户名和密码改变了,修改db.properties
3.2准备MySQL容器
#运行MySQL容器
docker run -d -p 3306:3306 --name mysql -e MYSQL_ROOT_PASSWORD=root daocloud.io/library/mysql:5.7.4
3.3准备Tomcat容器
#运行Tomcat容器,前面已经搞定,只需要将SSM项目war包容器内部即可
#可以通过命令将宿主机的内容服务到容器内部
docker cp 文件名称 容器id:容器内部路径
#举例
docker cp jobs.war fe:usr/local/tomcat/webapps/
3.4 数据库
为了部署SSM的工程,需要使用到cp的命令将指定宿主机的ssm.war文件复制到容器内部
数据卷:将宿主机的一个目录映射到容器的一个目录中。
可以在宿主机中操作目录中的内容,那么容器内部映射的文件,也会跟着一起改变。
#1、创建数据卷
docker volume create 数据卷名称
#创建数据卷之后,默认会存放在一个目录下 /var/lib/docker/volumes/数据卷名称/_data
#2、查看数据卷的详细信息
docker volume inspect 数据卷名称
#3、查看全部数据卷
docker volume ls
#4、删除数据卷
docker volume rm 数据卷名称
#5、应用数据卷
#当你映射数据卷时,如果数据卷不存在。Docker会帮你帮你自动创建,会将容器内部自动的文件,存储在默认的存放路径中
docker run -v 数据卷名称:容器内部的路径 镜像id
#直接指定一个路径作为数据卷的存放位置。这个路径下是空的。
docker run -v 路径:容器内部的路径 镜像id
四、Dcker自定义镜像
中央仓库上的镜像,也是Docker的用户自己上传过去的。
#1、创建一个Dockerfile文件,并且指定自定义镜像信息
#Dockerfile文件中常用的内容
from:指定当前自定义镜像依赖的环境
copy:将相对路径下的内容复制到自定义镜像中
workdir:声明镜像的默认工作目录
cmd:需要执行的命令(在workdir下执行的,cmd可以写多的,只以最后一个为准)
#举个例子,自定义一个tomcat镜像,并且将jobs.war部署到tomcat中,
from daocloud.io/library/tomcat:8.5.19-jre8
copy jobs.war /usr/local/tomcat/webapps
#2、将准备好的Dockerfile和相应的文件拖拽到Linux操作系统中,通过Docker的命令制作镜像, 后面刚的 点 是指当前目录,可以自己指定
docker build -t 镜像名称:[tag] .
六、Dockers-Compose
之前运行一个镜像,需要添加大量的参数
可以通过Dockers-Composes编写这些参数。
Docker-Compose可以帮助我们批量的管理容器
只需要通过一个docker-compose.yml文件去维护即可
6.1下载Docker-Compose
#1、去github官网搜索docker-compose,下载1.24.1版本的Docker-Compose
https://github.com/docker/compose/releases/download/1.24.1/docker-compose-Linux-x86_64
#2、将下载好的文件,拖拽到Linux操作系统中
#3、需要将DockerCompose文件的名称修改一下,基于DockerCompose文件一个可执行的权限
mv docker-compose-Linux-x86_64 docker-compose
chmod 777 docker-compose
#方便后期操作,配置一个环境变量
#将docker-compose文件移动到/usr/local/bin,修改了/etc/profile文件,给/usr/local/bin配置到了PATH中
mv docker-compose /usr/local/bin
vi /etc/profile
export PATH=$JAVA_HOME:/usr/local/bin:$PATH
source /etc/profile
#5、测试一下
在任意目录下输入docker-compose

6.2Docker-compose管理MySQL和Tomcat容器
- yml文件以key: value方式来指定配置信息
- 多个配置信息以换行+缩进的方式来区分
version: '3.1'
services:
mysql: # 服务的名称
restart: always # 代表只要docker启动,那么这个容器就跟着一起启动
image: daocloud.io/library/mysql:5.7.4 # 指定镜像路径
container_name: mysql # 指定容器名称
ports:
- 3306:3306 # 指定端口号的映射
environment:
MYSQL_ROOT_RASSWORD: root # 指定MySQL的ROOT用户登录密码
TZ: Asia/Shanghai # 指定时区
volumes:
- /opt/docker_mysql_tomcat/data:/var/lib/mysql # 映射数据卷
tomcat:
restart: always
image: daocloud.io/library/tomcat:8.5.16-jre8
container_name: tomcat
ports:
- 8080:8080
environment:
TZ: Asia/Shanghai
volumes:
- /opt/docker_mysql_tomcat/tomcat_webapps:/usr/local/tomcat/webapps
- /opt/docker_mysql_tomcat/tomcat_logs:/usr/local/logs
6.3使用docker-compose命令管理容器
在使用docker-compose的命令时,默认会在当前目录下找docker-compose.yml文件
# 1、基于docker-compose.yml启动管理的容器
docker-compose up -d
#如果自定义镜像不存在,会帮助我们构建出自定义镜像,如果自定义镜像已经存在,会直接运行这个自定义镜像
# 重新构建的话。
# 重新构建自定义镜像
docker-compose build
#运行前,重新构建
docker-compose up -d --build
七、Docker DI、CD
7.1项目部署
1、将项目通过maven进行编译打包
2、将文件上传到指定的服务器中
3、将war包放到tomcat的目录中
4、通过Dockerfile将Tomcat和war包转成一个镜像,由DockerCompose去运行容器
项目更新了
将上述流程再次的从头到尾的执行一次
7.2CI介绍
Ci(continuous intergration)持续集成
持续集成:编写代码时,完成了一个功能后,立即提交代码到Git仓库中,将项目重新的构建并且测试。
快速发现错误
防止代码偏离主分支
7.3实现持续集成
7.3.1搭建Gitlab服务器
1、创建一个全新的虚拟机,并且至少指定4G运行内存
2、安装docker以及docker-compose
3、 将ssh的默认22端口,修改为60022
1、打开:vi /etc/ssh/sshd_config
2、修改:RORT 22->60022
3、重启服务:systemctl restart sshd
4、docker-compose.yml文件去安装gitlab(下载和运行的是时间比较长的)
version: '3.1'
services:
gitlab:
image: 'twang2218/gitlab-ce-zh:11.1.4'
container_name: "gitlab"
restart: always
privileged: true
hostname: 'gitlab'
environment:
TZ: 'Asia/Shanghai'
GITLAB_OMNIBUS_CONFIG: |
external_url 'http://192.168.199.110'
gitlab_rails['time_zone'] = 'Asia/Shanghai'
gitlab_rails['smtp_enable'] = true
gitlab_rails['gitlab_shell_ssh_port'] = 22
ports:
- '80:80'
- '443:443'
- '60022:60022'
volumes:
- /opt/docker_gitlab/config:/etc/gitlab
- /opt/docker_gitlab/data:/var/opt/gitlab
- /opt/docker_gitlab/logs:/var/log/gitlab
7.3.2搭建Git.ab-Runner
7.3.3整合项目入门测试
1、创建maven工程,编写html页面
2、编写gitlab-ci.yml文件
3、将maven工程推送到gitlab中
4、可以在gitlab中查看到gitlab-ci.yml编写的内容
八、安装Jenkins
8.1 安装Jenkins
version: "3.1"
services:
jenkins:
image: jenkins/jenkins
restart: always
container_name: jenkins
ports:
- 8888:8080
- 5000:5000
volumes:
- ./data:/var/Jenkins_home
注意:第一次运行时,会因为data目录没有权限,导致启动失败
chmod 777 data
8.1.1 访问http://ip:8888
访问熟读很慢…
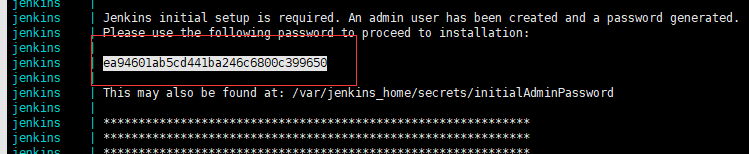
8.1.2 查看日志,输入密码登陆Jenkins:
8.1.3 手动指定插件安装:
publish ssh…
git param…
8.1.4 等待安装完成,指定下列插件即可:

8.1.5 安装成功后,需要指定上用户名和密码

8.2 配置目标服务器及GitLab免密登录
- GitLab->Jenkins->目标服务器
1、jenkins去连接目标服务器



8.3 配置GitLab免密码登录(后期使用后补充笔记)
1、登录Jenkins容器内部
2、输入生成SSH密钥命令
3、复制GitLab的SSH中
Nginx

Author:Eric
Version:9.0.1
一、 Nginx介绍
- 为什么要学习Nginx
- 问题1:客户端到底要将请求发送给哪台服务器
- 问题2:如果所有客户端的请求都发送给了服务器1.
- 问题3:客户端发送的请求可能是申请动态资源的,也有申请静态资源的。
1、服务器搭建集群后

2、在搭建集群后,使用Nginx做反向代理服务器

1.1 Nginx介绍
- Nginx是由俄罗斯人研发的,应对Rambler的网站,并且2004年发布的第一个版本。

- Nginx的特点:
- 1、稳定性极强。7*24小时不间断运行。
- 2、Nginx提供了非常丰富的配置实例。
- 3、占用内存小,并发能力强。
一、Nginx的安装
2.1安装Nginx
version: '3.1'
services:
nginx:
restart: always
image: daocloud.io/library/nginx:latest
container_name: nginx
ports:
- 80:80
验证:浏览器中出入ip地址访问
2.2Nginx的配置文件
- 关于Nginx的核心配置文件Nginx.conf
user nginx;
worker_processes 1;
error_log /var/log/nginx/error.log warn;
# 以上统称为全局快
# worker_processes他的数值越大,Nginx的并发能力越强
# error_log 代表Nginx的错误日志存放的位置
events {
worker_connections 1024;
}
# events块
# worker_connections他的数值越大,Ningx并发能力越强
http {
include /etc/nginx/mime.types;
default_type application/octet-stream;
server {
listen 80;
listen [::]:80;
server_name localhost;
location / {
root /usr/share/nginx/html;
index index.html index.htm;
}
# location块
# root: 将接收到的请求根据/usr/share/nginx/html去查找静态资源
# index::默认去上述的路径中找到index.html或者index.htm
}
# server块
# listen:代表Nginx监听的端口号
# localhost: 代表Nginx接收请求的ip
}
# http块
# include 代表引入一个外部的文件 ——> /mime.types中存着大量的媒体类型
# include /etc/nginx/conf.d/*.conf; ——> 引入了conf.d目录下的.conf为结尾的配置文件
2.3修改docker-compose文件
version: '3.1'
services:
nginx:
restart: always
image: daocloud.io/library/nginx:latest
container_name: nginx
ports:
- 80:80
volumes:
- /opt/docker_nginx/conf.d/:/etc/nginx/conf.d
一、Nginx的反向代理
1.1正向代理
1、正向代理服务时由客户端设立的。
2、客户端了解代理服务器和目标服务器都是谁。
3、帮助咱们实现突破访问权限,提高访问的速度,对目标服务器隐藏客户端的ip地址

1.2反向代理
1、反向代理服务器是配置在服务端的。
2、客户端是不知道访问的到底是哪一台服务器。
3、达到负载均衡,并且可以隐藏服务器真正的ip地址。

1.3基于Nginx实现反向代理
1、准备一个目标服务器:启动一个tomcat服务器
2、编写nginx的配置文件,通过nginx访问tomcat服务器
server{x
listen 80;
server_name localhost;
# 基于反向代理访问到Tomcat服务器
location / {
proxy_pass http://192.168.2.191:8080/;
}
}
1.4关于Nginx的location路径映射
优先级关系:
(location = ) > (location /xxx) > (location ^~ /images/) > (location ~,location ~*) > (location /起始路径)> (location /)
# 1、 = 匹配
location = / {
# 精准匹配,主机名后面不能带任何的字符串
}
# 2、通用匹配
location /xxx {
# 匹配所有以/xxx开头的路径
}
# 3、正则匹配
location ~ /xxx {
# 匹配所有以/xxx开头的路径,高于通用匹配
}
# 4、正则匹配
location ^~ /images/ {
# 匹配所有以/images开头的路径,高于正则匹配
}
# 5、~*\.(gif|jpg|png) {
# 匹配以gif或者jpg或者png为结尾的路径
}
二、Nginx负载均衡
Nginx为我们默认提供了三种负载均衡的策略:
1、轮询:
将客户端发起的请求,平均的分配给每一台服务器
2、权重:
会将客户端的请求,根据服务器的权重值不同,分配不同的数据
3、ip_hash:
基于发起请求的客户端的ip地址不同,他始终将请求发送到指定的服务器上
2.1 轮询
想实现Nginx轮询负载均衡机制只需要在配置文件中添加以下内容。
upstream 名字{
server ip:prot;
server ip:prot;
……
}
server{
listen 80;
server_name localhost;
location / {
proxy_pass http://upstream的名字;
}
}
2.2 权重
实现权重的方法
upstream 名字{
server ip:prot weight=权重比例;
server ip:prot weight=权重比例;
……
}
server{
listen 80;
server_name localhost;
location / {
proxy_pass http://upstream的名字;
}
}
2.3 ip_hash
ip_hash实现
upstream 名字{
ip_hash;
server ip:prot weight=权重比例;
server ip:prot weight=权重比例;
……
}
server{
listen 80;
server_name localhost;
location / {
proxy_pass http://upstream的名字;
}
}
三、Nginx动静分离
Nginx的并发能力公式:
worker_processes *worker_connections / 4 | 2=Nginx最终的并发能力。
动态资源/4;静态资源/2;
Nginx通过动静分离,来提升Nginx的并发能力,更快的给用户相应。
3.1动态资源代理
# 配置如下
location / {
proxy_pass 路径;
}
3.2动态资源代理
# 配置如下
location / {
root 静态资源路径;
index 默认访问路径下的生名资源;
autoindex on; # 表示展示静态资源下的全部内容,以列表的形式展示
}
# 先修改docker,添加一个数据卷,映射到Nginx的一个目录
四、Nginx集群
4.1 引言
单点故障,避免nginx的宕机,导致整个程序的崩溃
准备多台Nginx
准备keeppalived,监听nginx的健康情况
准备haproxy,提供一个虚拟的路径,统一的去接收用户的请i去。

4.2 搭建Nginx集群
查看资料中的文件;全部拷贝修改IP地址到下一个目录后执行:docker-compose up -d
文件路径:
nginx集群.zip

ES

1.2 ES引言
ES是一个使用Java语言的基于Lucene编写的搜索引擎框架,他提供了分布式的全文搜索功能,提供一个统一的基于RESTful的WEB接口,官方客户端也对多种语言都提供了响应的API。
Lucene:Lucene本身就是一个搜索引擎的底层。
分布式:ES主要是为了突出他的横向扩张能力。
全文搜索:讲一段词语进行分词,并且将分出的单个词语统一的放到一个分词库中,在搜索时,根据关键字去粉刺库中搜索,找到匹配的内容。(倒排索引)
RESTful风格的WEB接口:操作ES跟简单,只需要发送一个HTTP请求,并且根据请求方式的不同,携带参数的同时,执行相应的功能。
应用广泛:GitHub.com,WIKI,Gold Man用ES每天维护将近10TB的数据。
1.3 ES的由来
见官网:http://www.elastic.cn
1.4 ES和Slor
1、Solr在查询死数据时,速度相对ES更快一些,但是数据如果是实时改变的,Solr的查询速度会降低很多,ES的查询的效率基本没有变化。
2、Solr搭建集群需要依赖Zookeeper来帮助管理,ES本身就支持集群的搭建,不需要第三方的介入。
3、最开始Solr的社会可以说是非常火爆,针对国内的文档不是很多,在ES出现之后,ES的社会火爆程度直线上升,ES的文档非常建全。
4、ES对现在云计算和大数据支持的特别好。
见官网:http://www.elastic.cn
1.5 倒排索引
将存放的数据,以一定方式进行分词,并且将分词的内容放到一个单独的分词库中。
当用户去查询数据时,会将用户的查询关键字进行分词。
然后去分词库中匹配内容,最终得到数据的id标识。
根据id标识去存放数据的位置拉取到指定数据。

二、ElasticSearch安装
2.1 安装ES&Kibana
Kibana是ES的图形化界面,版本号需一致;
version: "3.1"
services:
elasticsearch:
image: daocloud.io/library/elasticsearch:6.5.4
restart: always
container_name: elasticsearch
ports:
- 9200:9200
kibana:
image: daocloud.io/library/kibana:6.5.4
restart: always
container_name: kibana
ports:
- 5601:5601
environment:
- elasticsearch_url=http://192.168.2.191:9200
depends_on:
- elasticsearch
注意:
虚拟机内存需要至少需要262144,修改内存可见:
https://blog.csdn.net/qzqanzc/article/details/83270679
2.2. 安装IK分词器
1、进入es容器内部安装IK,IK相当于一个插件在/bin/elasticsearch-plugin:docker exec -it CONTAINER ID值 bash
2、下载Ik分词器的地址:https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v6.5.4/elasticsearch-analysis-ik-6.3.0.zip
3、Linux系统安装:./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v6.5.4/elasticsearch-analysis-ik-6.5.4.zip
国外的有点慢可以试试这个:./bin/elasticsearch-plugin install http://tomcat01.qfjava.cn:81/elasticsearch-analysis-ik-6.3.0.zip
4、重启ES的容器,让IK分词器生效。
5、测试,使用方法可见github的IK使用文档

三、ElasticSearch基本操作
3.1 ES的结构
3.1.1 索引 Index,分片和备份
3.1.2 类型 Type
3.1.3 文档 Doc
3.1.4 属性 FieId
3.2 操作ES的RESTful语法
3.3索引的操作
3.3.1 创建一个索引
# 创建一个索引
PUT /person
{
"settings": {
"number_of_shards": 5,
"number_of_replicas": 1
}
}
3.3.2 查看索引信息

# 查看suoyin索引信息
GET /person
3.3.3 删除索引

# shanchu删除索引
DELETE /person
3.4 ES中field可以指定的类型
字符串类型:
text:一把被用于全文检索。将当前Field进行分词。
keyword:当前Field不会被分词
数值类型:
long:
integer:
short:
byte:
double:
float:
half_float:精度比float小一半
scaled_float:根据一个long和scaled来表达一个浮点型,long-345,scaled-100-》3.45
时间类型:
date类型:针对时间类型指定具体的格式
布尔类型:
boolean类型,表达true和false
二进制类型:
binary类型暂时支持Base64 encode string
范围类型:
long_range:赋值时,无需指定具体的内容,只需要存储一个范围即可,指定gt,lt,gte,lte
integer_range:同上
double_range:同上
float_range:同上
date——range:同上
ip_range:同上
经纬度类型:
geo_point:用来存储经纬度的
ip类型:
ip:可以存储IPV4或者IPV6
其他的数据类型参考官网:https://www.elastic.co/guide/en/elasticsearch/reference/6.5/mapping-types.html
3.5 创建索引并指定数据结构
es版本需为6.5.4的,新版本可能有变动,需自行修改。
# 创建一个索引,指定数据结构
PUT /book
{
"settings": {
# 分片数
"number_of_shards": 5,
# 备份数
"number_of_replicas": 1
},
# 指定数据结构
"mappings": {
# 类型Type
"novel": {
# 文档存储的Field
"properties": {
# field属性名
"name": {
# 类型
"type": "text",
# 指定分词器
"analyzer": "ik_max_word",
# 指定当前Field可以被作为查询的条件
"index": true,
# 是否需要额外存储
"store": false
},
"author": {
"type": "keyword"
},
"count": {
"type": "long"
},
"on-sale": {
"type": "date",
# 时间类型的格式化方式
"format": "yyyy-MM-dd:ss||yyyy-MM-dd||epoch_millis"
},
"descr": {
"type": "text",
"analyzer": "ik_max_word"
}
}
}
}
}
3.6 文档的操作
文档在ES服务中的唯一标识,_index,_type,_id 三个内容为符合,锁定一个文档。操作时,是添加还是修改。
3.6.1 新建文档
自动生成_id
# 添加文档,自动生成id
POST /book/novel
{
"name": "盘龙",
"author": "我吃西红柿",
"on-sale": "2000-04-04",
"descr":"哈哈哈嘻嘻嘻"
}
手动指定id
# 添加文档,手动指定id
PUT /book/novel/1
{
"name": "红楼梦",
"author": "曹雪芹",
"on-sale": "1985-01-04",
"descr":"书籍123121321213212132"
}
3.6.2 修改文档
覆盖式修改
# 添加文档,手动指定id
PUT /book/novel/1
{
"name": "红楼梦",
"author": "曹雪芹",
"on-sale": "1985-01-04",
"descr":"书籍123121321213212132"
}
doc修改方式
# 修改文档,基于doc方式
POST /book/novel/1/_update
{
"doc": {
# 指定上需要修改的field和对应的值
"count": "123456"
}
}
3.6.3 删除文档
# 根据id删除文档
DELETE /book/novel/_id值
四、Java操作ElasticSearch
4.1 Java连接ES
- 创建Maven工程
- 导入依赖
- 1、elasticsearch
- 2、elasticsearch的高级API
- 3、junit
- 4、lombok
注:可通过mvn官网查看:https://mvnrepository.com/artifact/org.elasticsearch.client/elasticsearch-rest-high-level-client/6.5.4
<dependencies>
<!-- 1、elasticsearch -->
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>6.5.4</version>
</dependency>
<!-- 2、elasticsearch的高级API -->
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>6.5.4</version>
</dependency>
<!-- 3、junit -->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
<!-- 4、lombok -->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.16</version>
</dependency>
<!-- 5、jackson -->
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>2.10.2</version>
</dependency>
</dependencies>
- 创建测试类
public class ESClient {
public static RestHighLevelClient getClient(){
//创建HttpHost
HttpHost host=new HttpHost("192.168.2.191",9200);
//创建RestClientBuilder
RestClientBuilder clientBuilder= RestClient.builder(host);
//创建RestHighLevelClient
RestHighLevelClient client=new RestHighLevelClient(clientBuilder);
//返回
return client;
}
}
4.2Java操作索引
4.2.1 Java创建索引
创建索引
@Test
public void createIndex() throws IOException {
//1、准备关于索引的settings
Settings.Builder settings = Settings.builder()
.put("number_of_shards", 3)
.put("number_of_replicas", 1);
//2、准备关于索引的结构mappings
XContentBuilder mappings = JsonXContent.contentBuilder()
.startObject()
.startObject("properties")
.startObject("name")
.field("type","text")
.endObject()
.startObject("age")
.field("type","integer")
.endObject()
.startObject("birthday")
.field("type","date")
.field("format","yyyy-MM-dd")
.endObject()
.endObject()
.endObject();
//3、将settings和mappings封装到一个Request对象
CreateIndexRequest request=new CreateIndexRequest(index)
.settings(settings)
.mapping(type,mappings);
//4、通过client对象去连接ES并执行创建索引
CreateIndexResponse resp = client.indices().create(request, RequestOptions.DEFAULT);
//5、输出测试
System.out.println("resp:"+resp.toString());
}
4.2.2 创建索引是否存在,删除索引
检测索引是否存在
@Test
public void exists() throws IOException {
//1、准备request对象
GetIndexRequest request=new GetIndexRequest();
request.indices(index);
//2、通过client对象执行
boolean exists = client.indices().exists(request, RequestOptions.DEFAULT);
//3、输出
System.out.println("exists:"+exists);
}
4.2.3 删除索引
删除索引
@Test
public void delete() throws IOException {
//准备request对象
DeleteIndexRequest request=new DeleteIndexRequest()
.indices(index);
//通过client执行
AcknowledgedResponse delete = client.indices().delete(request, RequestOptions.DEFAULT);
//获取执行结构
System.out.println("delete:"+delete.isAcknowledged());
}
4.3 Java操作文档
4.3.1 添加文档操作
添加文档操作
public class Deom3 {
ObjectMapper mapper=new ObjectMapper();
RestHighLevelClient client = ESClient.getClient();
String index="persion";
String type="man";
@Test
public void createDoc() throws IOException {
//1、准备json数据
Persion persion=new Persion(1,"张三",23,new Date());
String json=mapper.writeValueAsString(persion);
//2、准备一个request对象
IndexRequest request=new IndexRequest(index,type,persion.getId().toString());
request.source(json, XContentType.JSON);
//3、通过client执行
IndexResponse index = client.index(request, RequestOptions.DEFAULT);
//4、输出返回结果
System.out.println(index.getResult().toString());
}
}
4.3.1 修改文档
修改文档
@Test
public void UpdateDoc() throws IOException {
//1、创建一个Map,指定需要需改的内容
Map<String,Object> map=new HashMap<String, Object>();
map.put("name","张大帅");
String docId="1";
//2、创建request对象,封装数据
UpdateRequest request=new UpdateRequest(index,type,docId);
request.doc(map);
//3、通过client对象执行
UpdateResponse update = client.update(request, RequestOptions.DEFAULT);
//4、输出返回结果
System.out.println(update.getResult().toString());
}
4.3.1 删除文档
删除文档
@Test
public void deleteDoc() throws IOException {
//1、封装Request对象
DeleteRequest request=new DeleteRequest(index,type,"1");
//2、client执行
DeleteResponse delete = client.delete(request, RequestOptions.DEFAULT);
//3、输出结果
System.out.println(delete.getResult().toString());
}
4.4 Java批量操作文档
4.4.1 批量添加文档
批量添加文档
@Test
public void bulkCreateDoc() throws IOException {
//1、准备多个json数据
Persion persion1 = new Persion(1, "张三", 23, new Date());
Persion persion2 = new Persion(2, "李四", 25, new Date());
Persion persion3 = new Persion(3, "王五", 24, new Date());
String json1 = mapper.writeValueAsString(persion1);
String json2 = mapper.writeValueAsString(persion2);
String json3 = mapper.writeValueAsString(persion3);
//2、创建Request,将准备好的数据封装进去
BulkRequest request=new BulkRequest();
request.add(new IndexRequest(index,type,persion1.getId().toString()).source(json1,XContentType.JSON));
request.add(new IndexRequest(index,type,persion2.getId().toString()).source(json2,XContentType.JSON));
request.add(new IndexRequest(index,type,persion3.getId().toString()).source(json3,XContentType.JSON));
//3、用client执行
BulkResponse bulk = client.bulk(request, RequestOptions.DEFAULT);
//4、输出结果
System.out.println(bulk.toString());
}
4.4.2 批量删除文档
批量删除文档
@Test
public void bulkDeleteDoc() throws IOException {
//1、封装Request对象
BulkRequest request=new BulkRequest();
request.add(new DeleteRequest(index,type,"1"));
request.add(new DeleteRequest(index,type,"2"));
request.add(new DeleteRequest(index,type,"3"));
//2、client执行
BulkResponse bulk = client.bulk(request, RequestOptions.DEFAULT);
//3、输出
System.out.println(bulk);
}
五、ElasticSearch练习
- 索引:sms-logs-index
- 类型:sms-logs-type

六、ElasticSearch的各中查询
6.1 term&terms查询
6.1.1 term查询
- term的查询时代表完全匹配,搜索之前不会对你搜索的关键词进行分词,对你的关键词去文档分词库中匹配内容
# term查询
POST /sms-logs-index/sms-logs-type/_search
{
"from": 0, # limit ?
"size": 5, # limit x,?
"query": {
"term": {
"province": {
"value": "北京"
}
}
}
}
//Java代码实现方式
@Test
public void termQuery() throws IOException {
//1、创建Request对象
SearchRequest request=new SearchRequest(index);
request.types(type);
//2、指定查询条件
SearchSourceBuilder builder=new SearchSourceBuilder();
builder.from(0);
builder.size(5);
builder.query(QueryBuilders.termQuery("province","北京"));
request.source(builder);
//3、执行查询
SearchResponse search = client.search(request, RequestOptions.DEFAULT);
//4、获取_source中数据,并展示
for (SearchHit hit : search.getHits().getHits()) {
Map<String, Object> asMap = hit.getSourceAsMap();
System.out.println(asMap);
}
}
6.1.2 terms查询
- terms和term的查询机制是一样,都不会将指定的查询关键字进行分词,直接去分词库中匹配,找到相应文档内容。
- terms是在针对一个字段包含多个值的时候使用。
- term:where province=“北京” ;
- terms:where province=“北京” or province=? or province=?;
# terms查询
POST /sms-logs-index/sms-logs-type/_search
{
"query": {
"terms": {
"province": [
"北京",
"山西",
"武汉"
]
}
}
}
//Java代码实现方式
@Test
public void termsQuery() throws IOException {
//1、创建Request对象
SearchRequest request=new SearchRequest(index);
request.types(type);
//2、封装查询条件
SearchSourceBuilder builder=new SearchSourceBuilder();
builder.query(QueryBuilders.termsQuery("province","北京","山西","武汉"));
request.source(builder);
//3、执行查询
SearchResponse search = client.search(request, RequestOptions.DEFAULT);
//4、输出_source
for (SearchHit hit : search.getHits().getHits()) {
System.out.println(hit.getSourceAsMap());
}
}
6.2 match查询
- match查询属于高层查询,他会根据你查询的字段类型不一样,采用不同的查询方式。
- 查询的是日期或者是数值的话,它会将你基于的字符串查询内容转换为日期或者数值对待。
- 如果查询的内容是一个不能被分词的内容(keyword),match查询不会对你指定的查询关键字进行分词。
- 如果查询的内容是一个可以被分词的内容(text),match会将你指定的查询内容根据一定的方式去分词,去分词库中匹配指定的内容。
- match查询,实际底层就是多个term查询,将多个term查询的结果给你封装在一起。
6.2.1 match_all查询
- 查询全部内容,不指定任何查询条件。
# match_all查询
POST /sms-logs-index/sms-logs-type/_search
{
"query": {
"match_all": {}
}
}
//Java代码实现
@Test
public void matchAllQuery() throws IOException {
//1、创建Request
SearchRequest request=new SearchRequest(index);
request.types(type);
//2、指定查询条件
SearchSourceBuilder builder=new SearchSourceBuilder();
builder.query(QueryBuilders.matchAllQuery());
builder.size(20); //ES默认只查询十条数据
request.source(builder);
//3、client执行
SearchResponse search = client.search(request, RequestOptions.DEFAULT);
//4、输出结果
for (SearchHit hit : search.getHits().getHits()) {
System.out.println(hit.getSourceAsMap());
}
System.out.println(search.getHits().getHits().length);
}
6.2.2 match查询
- 指定一个Field作为筛选条件
# match查询
POST /sms-logs-index/sms-logs-type/_search
{
"query": {
"match": {
"smsContent": "收货安装"
}
}
}
//Java代码实现
@Test
public void matchQuery() throws IOException {
//1、创建Request
SearchRequest request=new SearchRequest(index);
request.types(type);
//2、指定查询条件
SearchSourceBuilder builder=new SearchSourceBuilder();
builder.query(QueryBuilders.matchQuery("smsContent","收货安装"));
request.source(builder);
//3、client执行
SearchResponse search = client.search(request, RequestOptions.DEFAULT);
//4、输出结果
for (SearchHit hit : search.getHits().getHits()) {
System.out.println(hit.getSourceAsMap());
}
System.out.println(search.getHits().getHits().length);
}
6.2.3 布尔match查询
- 基于一个Field匹配的内容,采用and或者or的方式连接。
# 布尔match查询
POST /sms-logs-index/sms-logs-type/_search
{
"query": {
"match": {
"smsContent": {
"query": "中国 健康",
"operator": "and" # 内容包括中国并包含健康
}
}
}
}
# 布尔match查询
POST /sms-logs-index/sms-logs-type/_search
{
"query": {
"match": {
"smsContent": {
"query": "中国 健康",
"operator": "or" # 内容包括中国或者健康
}
}
}
}
//Java实现
@Test
public void booleanMatchQuery() throws IOException {
//1、创建Request
SearchRequest request=new SearchRequest(index);
request.types(type);
//2、指定查询条件
SearchSourceBuilder builder=new SearchSourceBuilder();
builder.query(QueryBuilders.matchQuery("smsContent","中国 健康").operator(Operator.OR)); //可以选择AND或者OR
request.source(builder);
//3、client执行
SearchResponse search = client.search(request, RequestOptions.DEFAULT);
//4、输出结果
for (SearchHit hit : search.getHits().getHits()) {
System.out.println(hit.getSourceAsMap());
}
System.out.println(search.getHits().getHits().length);
}
6.2.4 multi_match查询
- match针对一个field做检索,multi_match针对多个field进行检索,多个field对应一个text。
# multi_match 查询
POST /sms-logs-index/sms-logs-type/_search
{
"query": {
"multi_match": {
"query": "北京",
"fields": ["province","smsContent"]
}
}
}
//代码实现
@Test
public void multiMatchQuery() throws IOException {
//1、创建Request
SearchRequest request=new SearchRequest(index);
request.types(type);
//2、指定查询条件
SearchSourceBuilder builder=new SearchSourceBuilder();
builder.query(QueryBuilders.multiMatchQuery("北京","province","smsContent"));
request.source(builder);
//3、client执行
SearchResponse search = client.search(request, RequestOptions.DEFAULT);
//4、输出结果
for (SearchHit hit : search.getHits().getHits()) {
System.out.println(hit.getSourceAsMap());
}
System.out.println(search.getHits().getHits().length);
}
6.3 其他查询
6.3.1 id查询
# id 查询
GET /sms-logs-index/sms-logs-type/21
//Java代码
@Test
public void findById() throws IOException {
//1、创建GetRequest
GetRequest request=new GetRequest(index,type,"21");
//2、执行查询
GetResponse documentFields = client.get(request, RequestOptions.DEFAULT);
//3、获取结果
System.out.println(documentFields.getSourceAsMap());
}
6.3.2 ids查询
- 根据多个id查询,类似MySQL中的where id in (id1,id2,id3…)
# ids查询
POST /sms-logs-index/sms-logs-type/_search
{
"query": {
"ids": {
"values": ["21","22","25"]
}
}
}
//Java代码实现
@Test
public void findByIds() throws IOException {
//1、创建SearchRequest
SearchRequest request=new SearchRequest(index);
request.types(type);
//2\指定查询条件
SearchSourceBuilder builder=new SearchSourceBuilder();
builder.query(QueryBuilders.idsQuery().addIds("21","22","25"));
request.source(builder);
//3、执行查询
SearchResponse documentFields = client.search(request, RequestOptions.DEFAULT);
//4、获取结果
for (SearchHit hit : documentFields.getHits().getHits()) {
System.out.println(hit.getSourceAsMap());
}
}
6.3.3 prefix查询
- 前缀查询,可以通过一个关键字去指定一个Field的前缀,从而查询到指定的文档。
# prefix 查询
POST /sms-logs-index/sms-logs-type/_search
{
"query": {
"prefix": {
"corpName": {
"value": "途虎"
}
}
}
}
//Java代码实现
@Test
public void findByPrefix() throws IOException {
//1、创建SearchRequest
SearchRequest request=new SearchRequest(index);
request.types(type);
//2\指定查询条件
SearchSourceBuilder builder=new SearchSourceBuilder();
builder.query(QueryBuilders.prefixQuery("corpName","途虎"));
request.source(builder);
//3、执行查询
SearchResponse documentFields = client.search(request, RequestOptions.DEFAULT);
//4、获取结果
for (SearchHit hit : documentFields.getHits().getHits()) {
System.out.println(hit.getSourceAsMap());
}
}
6.3.4 fuzzy查询
- 模糊查询,我们输入字符的大概,ES就可以去根据输入的内容大概去匹配一下结果。
# fuzzy查询
POST /sms-logs-index/sms-logs-type/_search
{
"query": {
"fuzzy": {
"corpName": {
"value": "盒马先生"
, "prefix_length": 2 # 指定前面几个字符不错
}
}
}
}
//Java代码现实
@Test
public void findByFuzzy() throws IOException {
//1、创建SearchRequest
SearchRequest request=new SearchRequest(index);
request.types(type);
//2\指定查询条件
SearchSourceBuilder builder=new SearchSourceBuilder();
builder.query(QueryBuilders.fuzzyQuery("corpName","盒马先生").prefixLength(2));
request.source(builder);
//3、执行查询
SearchResponse documentFields = client.search(request, RequestOptions.DEFAULT);
//4、获取结果
for (SearchHit hit : documentFields.getHits().getHits()) {
System.out.println(hit.getSourceAsMap());
}
}
6.3.5 wildcard查询
- 通配查询,和MySQL中的like是一个套路,可以在查询时,在字符串中指定通配符*和占位符?
# wildcard查询
POST /sms-logs-index/sms-logs-type/_search
{
"query": {
"wildcard": {
"corpName": {
"value": "中国??" # 可以使用*和? 指定通配符合占位符
}
}
}
}
//Java代码实现
@Test
public void findByWildcard() throws IOException {
//1、创建SearchRequest
SearchRequest request=new SearchRequest(index);
request.types(type);
//2\指定查询条件
SearchSourceBuilder builder=new SearchSourceBuilder();
builder.query(QueryBuilders.wildcardQuery("corpName","中国??"));
request.source(builder);
//3、执行查询
SearchResponse documentFields = client.search(request, RequestOptions.DEFAULT);
//4、获取结果
for (SearchHit hit : documentFields.getHits().getHits()) {
System.out.println(hit.getSourceAsMap());
}
}
6.3.6 range查询
- 范围查询,只针对数值类型,对某一个Field进行大于或者小于的范围指定。
# range 查询
POST /sms-logs-index/sms-logs-type/_search
{
"query": {
"range": {
"fee": {
"gt": 5,
"lte": 20
# 可以使用 gt : >, gte : >=, lt:<, lte : <=
}
}
}
}
//Java代码实现
@Test
public void findByRange() throws IOException {
//1、创建SearchRequest
SearchRequest request=new SearchRequest(index);
request.types(type);
//2\指定查询条件
SearchSourceBuilder builder=new SearchSourceBuilder();
builder.query(QueryBuilders.rangeQuery("fee").lt(10).gte(5));
request.source(builder);
//3、执行查询
SearchResponse documentFields = client.search(request, RequestOptions.DEFAULT);
//4、获取结果
for (SearchHit hit : documentFields.getHits().getHits()) {
System.out.println(hit.getSourceAsMap());
}
}
6.3.7 regexp查询
- 正则查询,通过你编写的正则表达式去匹配内容
- PS:
- prefix,fuzzy,wildcard和repexp查询效率相对比较低,要求效率比较高时,避免使用。
# regexp查询
POST /sms-logs-index/sms-logs-type/_search
{
"query": {
"regexp": {
"mobile": "180[0-9]{8}" # 编写正则表达式
}
}
}
//Java代码实现
@Test
public void findByRegexp() throws IOException {
//1、创建SearchRequest
SearchRequest request=new SearchRequest(index);
request.types(type);
//2\指定查询条件
SearchSourceBuilder builder=new SearchSourceBuilder();
builder.query(QueryBuilders.regexpQuery("mobile","139[0-9]{8}"));
request.source(builder);
//3、执行查询
SearchResponse documentFields = client.search(request, RequestOptions.DEFAULT);
//4、获取结果
for (SearchHit hit : documentFields.getHits().getHits()) {
System.out.println(hit.getSourceAsMap());
}
}
6.4 深分页Scroll
- ES对from + size是有限制的,from和size二者之和不能超过1W
- 原理:
- from+size在ES查询数据的方式:
- 第一步将用户指定的关键字进行分词
- 第二步将词汇去分词库中进行检索,得到多个文档的id
- 第三步去各个分片中拉取指定的数据。耗时较长
- 第四步将数据根据score进行排序。耗时较长
- 第五步根据from的值,将查询到的数据舍弃一部分
- 第六步返回结果
- Scroll+size在ES查询数据的方式:
- 第一步现将用户指定的关键字分词。
- 第二步将词汇去分词库中进行索引,得到多个文档的id。
- 第三步将文档的id存放在一个ES的上下文中。
- 第四步根据你指定的size的个数去ES中检索指定个数的数据,拿完数据的文档id,会从上下文中移除。
- 第五步如果需要下一页数据,直接去ES的上下文中,找后续内容。
- 第六步循环第四步和第五步。
- from+size在ES查询数据的方式:
- Scroll查询方式,不适合做实时数据的查询。
# scroll深分页
# 执行scroll查询,返回第一页数据,并且将文档id信息存放在ES上下文中,指定生存时间1m
POST /sms-logs-index/sms-logs-type/_search?scroll=1m
{
"query": {
"match_all": {}
},
"size": 2,
"sort": [ # 排序
{
"fee": {
"order": "desc"
}
}
]
}
# 根据scroll查询第下页数据
POST /_search/scroll
{
# 根据第一步得到的scroll_id去指定
"scroll_id": "DnF1ZXJ5VGhlbkZldGNoAwAAAAAAAChEFk14b3lMbG5wUTlLZjktamtrNFJJNncAAAAAAAAoQxZNeG95TGxucFE5S2Y5LWprazRSSTZ3AAAAAAAAKEUWTXhveUxsbnBROUtmOS1qa2s0Ukk2dw==",
"scroll": "1m"
}
# 删除scrollzai在es上下文zhong中的数据;根据第一步得到的scroll_id去指定
DELETE /_search/scroll/DnF1ZXJ5VGhlbkZldGNoAwAAAAAAAChEFk14b3lMbG5wUTlLZjktamtrNFJJNncAAAAAAAAoQxZNeG95TGxucFE5S2Y5LWprazRSSTZ3AAAAAAAAKEUWTXhveUxsbnBROUtmOS1qa2s0Ukk2dw==
//Java代码实现
@Test
public void ScrollQuery() throws IOException {
//1、创建SearchRequest
SearchRequest request=new SearchRequest(index);
//2、指定scroll信息
request.scroll(TimeValue.timeValueMillis(1L));
//3、指定查询的条件
SearchSourceBuilder builder=new SearchSourceBuilder();
builder.size(4);
builder.sort("fee", SortOrder.DESC);
builder.query(QueryBuilders.matchAllQuery());
request.source(builder);
//4、获取返回结果scrollId,source
SearchResponse search = client.search(request, RequestOptions.DEFAULT);
String scrollId = search.getScrollId();
System.out.println("---------首页---------");
for (SearchHit hit : search.getHits().getHits()) {
System.out.println(hit.getSourceAsMap());
}
while (true){
//5、循环——创建SearchScrollRequest
SearchScrollRequest scrollRequest=new SearchScrollRequest(scrollId);
//6、指定scrollId的生存时间
scrollRequest.scroll(TimeValue.timeValueMillis(1L));
//7、执行查询获取返回结果
SearchResponse scrollResp = client.scroll(scrollRequest, RequestOptions.DEFAULT);
//8、判断是否查询到了数据,输出
SearchHit[] hits = scrollResp.getHits().getHits();
int length = scrollResp.getHits().getHits().length;
if (hits !=null&& length >0){
System.out.println("-----下一页-----");
for (SearchHit hit : hits) {
System.out.println(hit.getSourceAsMap());
}
}else {
//9、判断没有查询到数据,停止——退出循环
System.out.println("-----结束-----");
break;
}
}
//10、创建CLearScrollRequest
ClearScrollRequest clearScrollRequest=new ClearScrollRequest();
// 11、指定ScrollId
clearScrollRequest.addScrollId(scrollId);
// 12、删除ScrollId
ClearScrollResponse clearScrollResponse = client.clearScroll(clearScrollRequest, RequestOptions.DEFAULT);
System.out.println("删除scroll = " + clearScrollResponse.isSucceeded());
}
SpringBoot

一、SpringBoot介绍
1.1 引言
- 为了使用SSM框架去开发,准备SSM框架的模板配置
- 为了Spring整合第三方框架,单独的去编写xml文件
- 导致SSM项目后期xm文件特别多,维护xml文件的成本是很高的。
- SSM工程部署也是很麻烦,依赖第三方的容器。
- SSM开发方式是很笨重。
1.2 SpringBoot介绍
- SpringBoot是由Pivotal团队研发的,SpringBoot并不是一门新技术,只是将之前常用的Spring,SpringMVC,data-jpa等常用框架封装到了一起,帮助你隐藏这些框架的整合细节,实现敏捷开发。
- SpringBoot就是一个工具集。

- SpringBoot的特点:
- SpringBoot项目不需要模板化的配置。
- 在SpringBoot中整合第三方框架时,只需要导入相应的starter依赖包,就自动整合了。
- SpringBoot默认只有一个.properties的配置文件,不推荐使用xml,后期会采用.java的文件去编写配置信息。
- SpringBoot工程在部署时,采用的是jar包的方式,内部自动依赖Tomcat容器,提供了多环境的配置。
- 后期要学习的微服务框架SpringCloud需要建立在SpringBoot的基础上。
二、SpringBoot快速入门
2.1 快速构建SpringBoot
1、选择构建项目的类型

2、项目的描述:

3、指定SpringBoot版本和需要的依赖:

第一次创建SpringBoot工程,下载大量依赖,保证,Maven已经配置了阿里云的私服。
4、需改pom.xml文件中的依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!--将cs项目修改成web项目-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
5、编写了Controller
@RestController
public class TestController {
@GetMapping("/test")
public String test(){
return "Hello SpringBoot!";
}
}
6、测试访问test方法

2.2 SpringBoot的目录结构


2.3 SpringBoot三种启动方式

三、SpringBoot常用注解
3.1 @Configuration和@Bean
- 之前使用SSM去开发时,在xml文件中编写bean标签。
- 但是SpringBoot不推荐使用xml文件
- @Configuration注解相当于beans标签
- @Bean注解相当于bean标签
- id=“方法名|注解中的name属性(优先级更高)”
- class=“方法的返回结果”
@Configuration
public class UserConfig {
@Bean(name = "user1")
public User user(){
return new User(1,"张三");
}
/*相当于:
<beans>
<bean id="user1" class="com.fq.firstspringboot.entity.User"></bean>
</beans>
* */
}
@SpringBootApplication
- @SpringBootApplication就是一个组合注解
- 1、@SpringBootConfiguration就是@Configuration注解,代表启动类就是一个配置类
- 2、@EnableAutoConfiguration帮你实现自动装配的,SpringBoot工程启动时,运行一个SpringFactoriesLoader的类,加载META-INF/spring.factories配置类(已经开启的类),通过SpringFactoriesLoader中的load方法,以for循环的方式,一个一个加载。
- 好处:无需编写大量的整合配置信息,只需要按照SpringBoot提供好了约定去整合即可。
- 坏处:如果说你导入一个starter依赖,那么你就需要填写他必要的配置信息。
- 手动关闭自动装配指定内容:@SpringBootApplication(exclude = QuartzAutoConfiguration.class)
- 3、@ComponentScan就相当于<context:component-scan basePackage=“包名” />,帮助扫描注解的。
四、SpringBoot常用配置
4.1 SpringBoot的配置文件格式
- SpringBoot的配置文件支持properties和yml,甚至它还支持json
- 更推荐使用yml文件格式:
- 1、yml文件,会根据换行和缩进帮助咱们管理配置文件所在位置。
- 2、yml文件,相比properties更较量
- yml文件的劣势:
- 1、严格遵循换行和缩进
- 2、在填写value时,一定要在:后面跟上空格
4.2 多环境配置
注:SpringBoot打包,mvn clean package
# 在application.yml文件中添加一个配置项:
spring:
profiles:
active: 环境名
- 在resource目录下,创建多个application-环境名.yml文件即可。
- 在部署工程时,通过java -jar jar项目 --spring.profiles.active:环境名
4.3 引入外部配置文件信息
和传统的SSM方式一样,通过@Value的注解取获取properties/yml文件中的内容
如果在yml文件中需要编写大量的自定义配置,并且具有统一的前缀时,采用如下方式:
@ConfigurationProperties(prefix = "aliyun")
@Component
@Data
public class AliyunProperties {
private String xxx;
private String yyy;
private String zzz;
private String bbb;
}
# properties/yml文件
aliyun:
xxx: yyyy
yyy: xxxx
zzz: aaaa
bbb: dddd
使用:
@Autowired
private AliyunProperties aliyunProperties;
@GetMapping("/aliyun")
public AliyunProperties aliyun(){
return aliyunProperties;
}
4.4 热加载
1、导入依赖:
<!--热加载-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-devtools</artifactId>
<optional>true</optional>
</dependency>
2、修改setting中的配置

3、修改内容后,可以通过build重新构建工程


五、SpringBoot整合Mybatis
5.1 xml方式整合MyBatis
- 1、导入依赖。
<dependencies>
<!--mysql驱动-->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
<!--druid的连接池-->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>1.1.10</version>
</dependency>
<!--mybatis-->
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<version>1.3.2</version>
</dependency>
<!--热加载-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-devtools</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
- 2、编写配置文件

//2.1 准备实体类
@Data
@NoArgsConstructor
@AllArgsConstructor
public class Type implements Serializable {
private long id;
private String type;
public long getId() {
return id;
}
public void setId(long id) {
this.id = id;
}
public String getType() {
return type;
}
public void setType(String type) {
this.type = type;
}
}
@Data
@NoArgsConstructor
@AllArgsConstructor
public class User implements Serializable {
private long id;
private String typesId;
private String name;
private long age;
public long getId() {
return id;
}
public void setId(long id) {
this.id = id;
}
public String getTypesId() {
return typesId;
}
public void setTypesId(String typesId) {
this.typesId = typesId;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public long getAge() {
return age;
}
public void setAge(long age) {
this.age = age;
}
}
// 2.2 准备Mapper接口
public interface UserMapper {
List<User> findAll();
}
// 在启动类中添加直接,扫描Mapper接口所在的包
@MapperScan(basePackages = "com.example.demotest.mapper")
<!--2.3 准备映射文件-->
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.example.demotest.mapper.UserMapper">
<!--List<User> findAll();-->
<select id="findAll" resultType="User">
select *from `user`
</select>
</mapper>
# 添加yml文件配置信息
# mybatis配置
mybatis:
# 扫描映射文件
mapper-locations: classpath:mapper/*.xml
# 配置别名扫描的包
type-aliases-package: com.example.demotest.entity
configuration:
# 开启驼峰映射配置
map-underscore-to-camel-case: true
# 指定连接数据库的信息
spring:
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/bus
username: root
password: 123456
type: com.alibaba.druid.pool.DruidDataSource
- 3、测试
在Mapper接口的位置,直接右键——>goto——>Test
会自动创建当前接口的测试类,在test目录下。
让当前测试类,继承DemotestApplicationTests(记得在父类前指定public)
class UserMapperTest extends DemotestApplicationTests {
@Autowired
private UserMapper userMapper;
@Test
void findAll() {
List<User> users = userMapper.findAll();
for (User user : users) {
System.out.println(user.toString());
}
}
}
5.2 注解方式整合MyBatis
- 1、创建Mapper接口
public interface GoodsMapper {
List<Goods> findAll();
Goods findOneById(@Param("id") Integer id);
}
- 2、添加MyBatis的注解
针对增删改查:@Insert,@Delete,@Update,@Select
还是需要在启动类中添加@MapperScan注解
public interface GoodsMapper {
@Select("select *from goods")
List<Goods> findAll();
@Select("select *from goods where goodId=#{id}")
Goods findOneById(@Param("id") Integer id);
}
- 3、测试,看到执行的sql语句
logging:
level:
com.example.demotest.mapper: debug
class GoodsMapperTest extends DemotestApplicationTests {
@Autowired
private GoodsMapper goodsMapper;
@Test
void findAll() {
List<Goods> all = goodsMapper.findAll();
for (Goods goods : all) {
System.out.println(goods);
}
}
@Test
void findOneById() {
goodsMapper.findOneById(1);
}
}
5.3 SpringBoot整合分页助手
- 1、导入依赖
<!--PageHelper依赖-->
<dependency>
<groupId>com.github.pagehelper</groupId>
<artifactId>pagehelper</artifactId>
<version>1.2.5</version>
</dependency>
- 2、测试使用
@Test
public void findByPage(){
//1、执行分页
PageHelper.startPage(1,2);
//2、执行查询
List<User> all = userMapper.findAll();
//3、封装PageInfo对象
PageInfo<User> pageInfo=new PageInfo<>(all);
//4、输出
for (User user : pageInfo.getList()) {
System.out.println(user);
}
}
六、SpringBoot整合JSP
- 1、需要导入依赖
<!--JSP核心引擎依赖-->
<dependency>
<groupId>org.apache.tomcat.embed</groupId>
<artifactId>tomcat-embed-jasper</artifactId>
</dependency>
<!--JSTL-->
<dependency>
<groupId>javax.servlet</groupId>
<artifactId>jstl</artifactId>
</dependency>
-
2、创建webapp以及WEB-INF去存放JSP页面

-
3、创建Controller·并指定view的前缀后后缀
@Controller
public class JspController {
@GetMapping("/index")
public String index(Model model){
model.addAttribute("name","战三");
return "index";
}
}
spring:
mvc:
# 视图的前缀和后缀
view:
prefix: /WEB-INF/
suffix: .jsp
七、SpringBoot

-
1、构建客户模块和搜索模块的SpringBoot工程
-
2、准备客户模块的静态资源(页面,实体类、数据库)
-
3、准备搜索模块的资源(ES中创建客户模块的索引)
- 导入ES的依赖
<!--ES-->
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>6.5.4</version>
</dependency>
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>6.5.4</version>
</dependency>
- 编写连接ES的config配置类
package com.qf.openapi.search.config;
import org.apache.http.HttpHost;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestClientBuilder;
import org.elasticsearch.client.RestHighLevelClient;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class ElasticSearchConfig {
@Value("${elasticsearch.host}")
private String host;
@Value("${elasticsearch.port}")
private int port;
@Bean
public RestHighLevelClient client(){
//创建HttpHost
HttpHost httpHost = new HttpHost(host,port);
//创建RestClientBuilder
RestClientBuilder clientBuilder = RestClient.builder(httpHost);
//创建RestHighLevelClient
RestHighLevelClient client = new RestHighLevelClient(clientBuilder);
//返回
return client;
}
}
- 导入实体类
package com.qf.openapi.search.entity;
import lombok.Data;
import java.io.Serializable;
@Data
public class Customer implements Serializable {
private static final long serialVersionUID = 1586034423739L;
/**
* 主键
*
* isNullAble:0
*/
private Integer id;
/**
* 公司名
* isNullAble:1
*/
private String username;
/**
*
* isNullAble:1
*/
private String password;
/**
*
* isNullAble:1
*/
private String nickname;
/**
* 金钱
* isNullAble:1
*/
private Long money;
/**
* 地址
* isNullAble:1
*/
private String address;
/**
* 状态
* isNullAble:1
*/
private Integer state;
}
- 运行测试文件
package com.qf.openapi.search;
import com.fasterxml.jackson.databind.ObjectMapper;
import com.qf.openapi.search.entity.Customer;
import org.elasticsearch.action.admin.indices.create.CreateIndexRequest;
import org.elasticsearch.action.admin.indices.create.CreateIndexResponse;
import org.elasticsearch.action.bulk.BulkRequest;
import org.elasticsearch.action.bulk.BulkResponse;
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.common.settings.Settings;
import org.elasticsearch.common.xcontent.XContentBuilder;
import org.elasticsearch.common.xcontent.XContentType;
import org.elasticsearch.common.xcontent.json.JsonXContent;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import java.io.IOException;
@SpringBootTest
class ElasticInitTests {
@Autowired
private RestHighLevelClient client;
String index = "openapi_customer";
String type = "customer";
@Test
public void createIndex() throws IOException {
//1. 准备关于索引的settings
Settings.Builder settings = Settings.builder()
.put("number_of_shards", 5)
.put("number_of_replicas", 1);
//2. 准备关于索引的结构mappings
XContentBuilder mappings = JsonXContent.contentBuilder()
.startObject()
.startObject("properties")
.startObject("id")
.field("type","integer")
.endObject()
.startObject("username")
.field("type","keyword")
.endObject()
.startObject("password")
.field("type","keyword")
.endObject()
.startObject("nickname")
.field("type","text")
.endObject()
.startObject("money")
.field("type","long")
.endObject()
.startObject("address")
.field("type","text")
.endObject()
.startObject("state")
.field("type","integer")
.endObject()
.endObject()
.endObject();
//3. 将settings和mappings封装到一个Request对象
CreateIndexRequest request = new CreateIndexRequest(index)
.settings(settings)
.mapping(type,mappings);
//4. 通过client对象去连接ES并执行创建索引
CreateIndexResponse resp = client.indices().create(request, RequestOptions.DEFAULT);
//5. 输出
System.out.println("resp:" + resp.toString());
}
@Test
public void bulkCreateDoc() throws IOException {
//1. 准备多个json数据
Customer c1 = new Customer();
c1.setId(1);
c1.setUsername("haier");
c1.setPassword("111111");
c1.setNickname("海尔集团");
c1.setMoney(2000000L);
c1.setAddress("青岛");
c1.setState(1);
Customer c2 = new Customer();
c2.setId(2);
c2.setUsername("lianxiang");
c2.setPassword("111111");
c2.setNickname("联想");
c2.setMoney(1000000L);
c2.setAddress("联想");
c2.setState(1);
Customer c3 = new Customer();
c3.setId(3);
c3.setUsername("google");
c3.setPassword("111111");
c3.setNickname("谷歌");
c3.setMoney(1092L);
c3.setAddress("没过");
c3.setState(1);
ObjectMapper mapper = new ObjectMapper();
String json1 = mapper.writeValueAsString(c1);
String json2 = mapper.writeValueAsString(c2);
String json3 = mapper.writeValueAsString(c3);
//2. 创建Request,将准备好的数据封装进去
BulkRequest request = new BulkRequest();
request.add(new IndexRequest(index,type,c1.getId().toString()).source(json1, XContentType.JSON));
request.add(new IndexRequest(index,type,c2.getId().toString()).source(json2,XContentType.JSON));
request.add(new IndexRequest(index,type,c3.getId().toString()).source(json3,XContentType.JSON));
//3. 用client执行
BulkResponse resp = client.bulk(request, RequestOptions.DEFAULT);
//4. 输出结果
System.out.println(resp.toString());
}
}
- 4、将客户模块运行起来(配置数据库连接信息和MyBatis的配置)
配置文件
# tomcat信息
server:
port: 80
# 连接数据库信息
spring:
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql:///openapi-admin?serverTimezone=UTC
username: root
password: 123456
type: com.alibaba.druid.pool.DruidDataSource
# MyBatis的配置
mybatis:
mapper-locations: classpath:mapper/*.xml
type-aliases-package: com.qf.openapi.customer.entity
configuration:
use-actual-param-name: true

RabbitMQ

一、RabbitMQ介绍
1.1引言
- 1、模块之间的耦合度多高,导致一个模块宕机后,全部功能都不能用了。
- 2、同步通讯的成本问题

1.2RabbitMQ的介绍
- 市面上比较火爆的几款MQ:
- ActiveMQ、RocketMQ、Kafka、RabbitMQ
1、语言的支持:ActiveMQ、RocketMQ、只支持Java语言,Kafla可以支持多语言,
2、效率方面:ActiveMQ、RocketMQ,Kafka效率都是毫秒级别,RabbitMQ是微妙级别的。
3、消息丢失,消息重复问题:RabbitMQ针对消息的持久化,和重复问题都有比较成熟的解决方案。
4、学习成本:RabbitMQ非常简单。
RabbitMQ是由RabbitMQ公司去研发和维护的,最终是在Pivotal。
RabbitMQ严格的遵循AMQP协议,高级消息队列协议,帮助我们在进程之间传递异步消息。
二、 RabbitMQ的安装
RabbitMQ的版本就好使用带management的,后面可能要使用它的图形化工具
version: "3.1"
services:
rabbitmq:
image: daocloud.io/library/rabbitmq:management
restart: always
container_name: rabbitmq
ports:
- 5672:5672
- 15672:15672
volumes:
- ./data/:/var/lib/rabbitmq
测试:
默认账号、密码:guest

三、RabbitMQ的架构
- 1、Publisher —— 生产者:发布消息到RabbitMQ中的Exchange
- 2、Consumer——消费者:监听RabbitMQ中的Queue中的消息
- 3、Exchange——交换机:和生产者建立连接并接收生产者的消息
- 4、Queue——队列:Exchange会将消息分布到指定的Queue,Queue和消费者进行交互
- 5、Routes——路由:交换机以什么样的策略将消息发布到Queue

3.1 RabbitMQ的完整架构图

3.2 查看图形化界面并创建一个Virtual Host
- 创建一个全新的用户和全新的Virtual Host,并且将test用户设置上可以操作/test的权限

四、RabbitMQ的使用
4.1 RabbitMQ的通信方式


4.2 Java连接RabbitMQ
1、创建Maven项目
2、导入依赖
<dependencies>
<!-- https://mvnrepository.com/artifact/com.rabbitmq/amqp-client -->
<dependency>
<groupId>com.rabbitmq</groupId>
<artifactId>amqp-client</artifactId>
<version>5.6.0</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>Test</scope>
</dependency>
</dependencies>
3、创建工具类连接RabbitMQ
public class RabbitMQClient {
public static Connection getConnection(){
//创建Connection工厂
ConnectionFactory factory=new ConnectionFactory();
factory.setHost("192.168.1.191");
factory.setPort(5672);
factory.setUsername("test");
factory.setPassword("test");
factory.setVirtualHost("/test");
//创建Connection
Connection conn= null;
try {
conn = factory.newConnection();
} catch (IOException e) {
e.printStackTrace();
} catch (TimeoutException e) {
e.printStackTrace();
}
//返回
return conn;
}
}
4、测试
public class Demo1 {
@Test
public void getConnection() throws IOException {
Connection connection = RabbitMQClient.getConnection();
connection.close();
}
}

4.3 Hello World
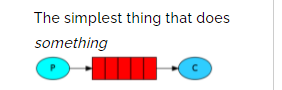
- 一个生产者,一个默认的交换机,一个队列,一个消费者
1、创建生产者,创建一个channel,发布消息到exchange,指定路由规则。
public class Pubisher {
@Test
public void publish() throws Exception {
//1、获取Connection
Connection connection = RabbitMQClient.getConnection();
//2、创建Channel
Channel channel = connection.createChannel();
//3、发布消息到exchange,同时指定路由的规则
String msg="Hello-World";
//参数1:指定exchange,使用""
//参数2:指定路由的规则,使用具体的队列名称
//参数3:指定传递的消息所携带的properties
//参数4:指定发布的具体消息,byte[]类型
channel.basicPublish("","Helloworld",null,msg.getBytes());
//Ps:exchange是不会将消息持久化到本地的,Queue才会帮你持久化消息。
System.out.println("生产者发布消息成功!");
//4、释放资源
channel.close();
connection.close();
}
}
2、创建消费者,创建一个channel,创建一个队列,并且去消费当前队列
public class Consumer {
@Test
public void consumer() throws Exception {
//1、获取连接对象
Connection connection = RabbitMQClient.getConnection();
//2、创建channel
Channel channel = connection.createChannel();
//3、声明队列——HelloWorld
/*
* 参数1:queue:指定队列名称
* 参数2:durable:当前队列是否需要持久化(true)
* 参数3:exclusive:是否排外(conn。close() —— 当前队列会被自动删除,当前队列只能被一个消费者消费)
* 参数4:autoDelete:如果这个队列没有消费者在消费,队列自动删除
* 参数5:arguments:指定当前队列的其他信息
* */
channel.queueDeclare("Helloworld",true,false,false,null);
//4、开启监听Queue
DefaultConsumer consumer=new DefaultConsumer(channel){
@Override
public void handleDelivery(String consumerTag, Envelope envelope, AMQP.BasicProperties properties, byte[] body) throws IOException {
System.out.println("接收到消息:"+new String(body,"UTF-8"));
}
};
/*
* 参数1:queue:指定消费那个队列
* 参数2:deliverCallback:指定是否自动ACK(true,接收到消息后,会立即告诉RabbitMQ)
* 参数3:CancelCallback:指定消费回调
* */
channel.basicConsume("Helloworld",true,consumer);
System.out.println("消费者开始监听队列");
//System.in.read;
System.in.read();
//5、释放资源
channel.close();
connection.close();
}
}
4.4 Work
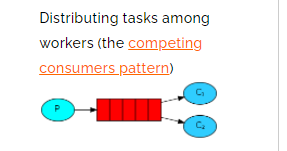
- 一个生产者,一个默认的交换机,一个队列,两个消费者
只需要在消费者端,添加Qos能力以及更改为手动ack即可让消费者,根据自己的能力消费指定的消息,而不是默认情况由RabbitMQ平均分配了。
//1、 指定当前消费者,一次消费多少消息
channel.basicQos(1);
//2、开启监听Queue
DefaultConsumer consumer=new DefaultConsumer(channel){
@Override
public void handleDelivery(String consumerTag, Envelope envelope, AMQP.BasicProperties properties, byte[] body) throws IOException {
try {
Thread.sleep(200);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("消费者2号接收到消息:"+new String(body,"UTF-8"));
//手动ACK
channel.basicAck(envelope.getDeliveryTag(),false);
}
};
//3、手动指定ack
channel.basicConsume("Work",false,consumer);
4.5 Publish/Subscribe
- 一个生产者,一个交换机,两个队列,两个消费者
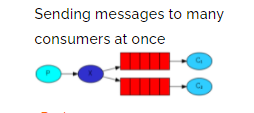
声明一个Fanout类型的exchange,并且将exchange和queue绑定在一起,绑定的方式就是直接绑定。
1、让生产者创建一个exchange并且指定类型,和一个或多个队列绑定到一起。
//3、创建exchange - 绑定某一个队列
/*
* 参数1:exchange的名称
* 参数2:指定exchange的类型 FANOUT-pubsub , DIRECT - Routing , TOPIC- Topics
* */
channel.exchangeDeclare("pubsub-exchange", BuiltinExchangeType.FANOUT);
channel.queueBind("pubsub-queue1","pubsub-exchange","");
channel.queueBind("pubsub-queue2","pubsub-exchange","");
//4、发布消息到exchange,同时指定路由的规则
String msg="Hello-World";
//参数1:指定exchange,使用""
//参数2:指定路由的规则,使用具体的队列名称
//参数3:指定传递的消息所携带的properties
//参数4:指定发布的具体消息,byte[]类型
for (int i = 0; i < 10; i++) {
msg = "Hello-World" + i;
channel.basicPublish("pubsub-exchange","Work",null,msg.getBytes());
}
2、消费者还是正常的监听某一个队列即可。
4.6 Routing
- 一个生产者,一个交换机,两个队列,两个消费者

创建一个DIRECT类型的exchange,并且去根据RoutingKey 去绑定指定的队列。
- 1、生产者在创建DIRECT类型的exchange后,去绑定响应的队列,并且在发送信息时,指定消息的具体RoutingKey即可。
//3、创建exchange - 绑定某一个队列
channel.exchangeDeclare("routing-exchange", BuiltinExchangeType.DIRECT);
channel.queueBind("routing-queue-error","routing-exchange","ERROR");
channel.queueBind("routing-queue-info","routing-exchange","INFO");
//4、发布消息到exchange,同时指定路由的规则
channel.basicPublish("routing-exchange","ERROR",null,"ERROR".getBytes());
channel.basicPublish("routing-exchange","INFO",null,"INFO1".getBytes());
channel.basicPublish("routing-exchange","INFO",null,"INFO2".getBytes());
channel.basicPublish("routing-exchange","INFO",null,"INFO3".getBytes());
- 2、消费者基本没有变化
4.7 Topic
- 一个生产者,一个交换机,两个队列,两个消费者

- 1、生产者创建Topic的exchange并且绑定到队列中,这次绑定可以通过*和#关键字,对指定RoutKey内容,编写时注意格式XXX.XXX.XXX去编写, * ——》一个XXX, 而#——》表示多个XXX.XXX,在发送消息时,指定具体的RoutingKey到底是什么。
//3、创建exchange - 绑定某一个队列 topic-queue-1 topic-queue-2
//动物的信息 <speed> <color> <what>
//*.red.* ->*占位符
//fast.# ->#通配符
//*.*.rabbit
channel.exchangeDeclare("topic-exchange", BuiltinExchangeType.TOPIC);
channel.queueBind("topic-queue-1","topic-exchange","*.red.*");
channel.queueBind("topic-queue-2","topic-exchange","fast.#");
channel.queueBind("topic-queue-2","topic-exchange","*.*.rabbit");
//4、发布消息到exchange,同时指定路由的规则
channel.basicPublish("topic-exchange","fast.red.monkey",null,"红快猴子".getBytes());
channel.basicPublish("topic-exchange","slow.block.dog",null,"黑慢狗".getBytes());
channel.basicPublish("topic-exchange","fast.white.cat",null,"快白猫".getBytes());
- 2、消费者基本没有变化
五、整合SpringBoot
5.1 SpringBoot整合RabbitMQ
1、创建SpringBoot工程
2、导入依赖
<!--rabbitmq-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-amqp</artifactId>
</dependency>
3、编写配置文件
spring:
rabbitmq:
host: 192.168.1.191
port: 5672
username: test
password: test
virtual-host: /test
4、编写配置类,声明exchange和queue,并且绑定到一起
@Configuration
public class RabbitMQConfig {
//1、创建exchange - topic
@Bean
public TopicExchange getTopicExchange(){
return new TopicExchange("boot-topic-exchange",true,false);
}
//2、创建queue
@Bean
public Queue getQueue(){
return new Queue("boot-queue",true,false,false,null);
}
//3、绑定在一起
@Bean
public Binding getBinding(TopicExchange topicExchange,Queue queue){
return BindingBuilder.bind(queue).to(topicExchange).with("*.red.*");
}
}
5、发布消息到RabbitMQ
@Autowired
private RabbitTemplate rabbitTemplate;
@Test
void contextLoads() {
rabbitTemplate.convertAndSend("boot-topic-exchange","solw.red.dog","红色的大狼狗!!!");
}
6、创建消费者监听消息
@Component
public class Consumer {
@RabbitListener(queues = "boot-queue")
public void getMessage(Object message){
System.out.println("接收到消息:"+message);
}
}
5.2 手动Ack
1、添加配置文件
spring:
rabbitmq:
listener:
simple:
acknowledge-mode: manual
2、在消费信息的位置,修改方法,再手动ack
@RabbitListener(queues = "boot-queue")
public void getMessage(String msg, Channel channel, Message message) throws IOException {
System.out.println("接收到消息:"+msg);
//手动Ack
channel.basicAck(message.getMessageProperties().getDeliveryTag(),false);
}
六、RabbitMQ的其他操作
6.1 消息的可靠性
- RabbitMQ的事务:事务可以保证消息100%传递,可以通过事务的回滚记录日志,后面定时再次发送当前消息。事务的操作,效率太低,加了事务后,他比平时操作的效率要慢100倍。
6.1.1 Confirm机制
- RabbitMQ除了事务,还提供了Confirm的确认机制,这个效率比事务高很多。
- 1、普通Confirm方式
//3.1开启Confirm
channel.confirmSelect();
//发送消息
String msg = "Hello-World" ;
channel.basicPublish("","HelloWorld",null,msg.getBytes());
//判断消息是否发送成功
if (channel.waitForConfirms()) {
System.out.println("消息发送成功");
}else {
System.out.println("消息发送失败");
}
- 2、批量Confirm方式。
//3.1开启Confirm
channel.confirmSelect();
//发送消息
for (int i = 0; i < 1000; i++) {
String msg = "Hello-World" +i;
channel.basicPublish("","HelloWorld",null,msg.getBytes());
}
//确定批量操作是否成功
channel.waitForConfirmsOrDie(); //当你发送的全部消息 ,有一个失败的时候,就直接全部失败,抛出异常
- 3、异步Confirm方式。(推荐和常用的一种)
//3.1开启Confirm
channel.confirmSelect();
for (int i = 0; i < 1000; i++) {
String msg = "Hello-World" +i;
channel.basicPublish("","HelloWorld",null,msg.getBytes());
}
channel.addConfirmListener(new ConfirmListener() {
public void handleAck(long l, boolean b) throws IOException {
System.out.println("消息发送成功,标识:"+l+",是否是批量:"+b);
}
public void handleNack(long l, boolean b) throws IOException {
System.out.println("消息发送失败,标识:"+l+",是否是批量:"+b);
}
});

6.1.2 Return机制
- Confirm只能保证消息到达exchange,无法保证消息可以被exchange分发到指定queue。
- 而且exchange是不能持久化消息的,queue是可以持久化消息。
- 采用Return机制来监听消息是否从exchange送到了指定的queue中

1、开启Return机制
//开启return机制
channel.addReturnListener(new ReturnListener() {
public void handleReturn(int i, String s, String s1, String s2, AMQP.BasicProperties basicProperties, byte[] bytes) throws IOException {
//当消息没有传递到queue时,才会执行。
System.out.println(new String(bytes,"UTF-8")+"没有传达到Queue中");
}
});
//再送发消息时,指定mandatory参数为true
channel.basicPublish("","HelloWorld",true,null,msg.getBytes());
6.1.3 SpringBoot实现Confirm以及Return
1、编写配置文件,开启Confirm以及Return机制
spring:
rabbitmq:
publisher-confirm-type: simple
publisher-returns: true
2、指定RabbitTemplate对象,开启Confirm和Return,并且编写了回调方法
@Component
public class PublisherConfirmAndReturnConfig implements RabbitTemplate.ConfirmCallback,RabbitTemplate.ReturnCallback {
@Autowired
private RabbitTemplate rabbitTemplate;
@PostConstruct //ini-method
public void iniMethod(){
rabbitTemplate.setConfirmCallback(this);
rabbitTemplate.setReturnCallback(this);
}
@Override
public void confirm(CorrelationData correlationData, boolean b, String s) {
if (b){
System.out.println("消息已经送达到了ack");
}else {
System.out.println("消息没有送达Exchange");
}
}
@Override
public void returnedMessage(Message message, int i, String s, String s1, String s2) {
System.out.println("消息没有送达到Queue");
}
}
6.2 消息重复消费
-
重复消费信息,会对非幂等次操作造成问题
-
重复消费消息的原因是,消费者没有给RabbitMQ一个ack

-
为了解决消息重复消费的问题,可以采用Redis,在消费者消费消息之前,现将信息的id放到Redis中,
-
id-0(正在执行业务)
-
id-1(执行业务成功)
-
如果ack失败,在RabbitMQ将消息交给其他的消费者时,先执行setnx,如果key已经存在,获取他的值,如果是0,当前消费者就什么都不做,如果是1,直接ack。
-
极端情况:第一个消费者在执行业务时,出现了死锁,在setnx的基础上,再给key设置一个生存时间。
-
1、生产者,发送消息时,指定messageId
AMQP.BasicProperties properties=new AMQP.BasicProperties().builder()
.deliveryMode(1) //指定信息是否需要持久化 1-需要持久化 2- 不需要持久化
.messageId(UUID.randomUUID().toString())
.build();
String msg = "Hello-World" ;
channel.basicPublish("","HelloWorld",true,properties,msg.getBytes());
- 2、消费者,在消费信息时,根据具体业务逻辑去操作redis
DefaultConsumer consumer=new DefaultConsumer(channel){
@Override
public void handleDelivery(String consumerTag, Envelope envelope, AMQP.BasicProperties properties, byte[] body) throws IOException {
Jedis jedis = new Jedis("192.168.31.240", 6379);
String messageId = properties.getMessageId();
//1、setnx到Redis中,默认指定value-0
String nx = jedis.set(messageId, "0", "NX", "EX",10);
if (nx!=null&&nx.equalsIgnoreCase("OK")){
System.out.println("接收到消息:"+new String(body,"UTF-8"));
//2、消费成功,set messageId 1
jedis.set(messageId,"1");
channel.basicAck(envelope.getDeliveryTag(),false);
}else {
//3、如果1中的setnx失败,获取key对应的value,如果是0,return,如果是1
String s = jedis.get(messageId);
if ("1".equalsIgnoreCase(s)){
channel.basicAck(envelope.getDeliveryTag(),false);
}
}
}
};
6.2.2 SpringBoot如果实现
1、导入依赖
<dependencies>
<!--导入Redis-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<!--rabbitmq-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-amqp</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
2、编写配置文件
spring:
rabbitmq:
host: 192.168.31.240
port: 5672
username: test
password: test
virtual-host: /test
listener:
simple:
acknowledge-mode: manual
publisher-confirm-type: simple
publisher-returns: true
redis:
host: 192.168.31.240
port: 6379
3、修改生产者
@Autowired
private RabbitTemplate rabbitTemplate;
@Test
void contextLoads() throws IOException {
CorrelationData messageId = new CorrelationData(UUID.randomUUID().toString());
rabbitTemplate.convertAndSend("boot-topic-exchange","solw.red.dog","红色的大狼狗!!!",messageId);
System.in.read();
}
4、修改消费者
@Component
public class Consumer {
@Autowired
private StringRedisTemplate redisTemplate;
@RabbitListener(queues = "boot-queue")
public void getMessage(String msg, Channel channel, Message message) throws IOException {
//0、获取messageId
String messageId = message.getMessageProperties().getHeader("spring_returned_message_correlation");
//1、设置key到Redis
if (redisTemplate.opsForValue().setIfAbsent(messageId,"0",10, TimeUnit.SECONDS)) {
//2、消费信息
System.out.println("接收到消息:"+msg);
//3、设置key的value为1
redisTemplate.opsForValue().set(messageId,"1",10,TimeUnit.SECONDS);
//4、手动ack
channel.basicAck(message.getMessageProperties().getDeliveryTag(),false);
}else {
//5、获取Redis中的value即可,如果1,手动ack
if ("1".equalsIgnoreCase(redisTemplate.opsForValue().get(messageId))) {
channel.basicAck(message.getMessageProperties().getDeliveryTag(),false);
}
}
}
}
七、 RabbitMQ应用(需要学习最后一集)
- 客户模块
- 1、导入依赖
- 2、编写配置文件
- 3、编写配置类
- 4、修改Service
Redis
二、Redis安装
2.1 安装Redis
version: '3.1'
services:
redis:
image: daocloud.io/library/redis:5.0.7
restart: always
container_name: redis
environment:
- TZ=Asia/Shanghai
ports:
- 6379:6379
2.2 安装Redis
进去Redis容器的内部
docker exec -it 容器id bash
在容器内部,使用redis-cli连接

2.3 使用图形化界面连接Redis
三、Redis常用命令
3.1 Redis存储数据的结构
常用的5种
- key-string:一个key对应一个值
- key-hash:一个key对应一个Map
- key-list:一个key 对应一个列表
- key-set:一个key对应一个集合
- key-zset:一个key对应一个有序集合。
另外三种数据结构: - HyperLogLog:计算近似值
- GEO:地理位置
- BIT :一般存储的也是一个字符串,存储的是一个byte[]
五种常用的存储数据结构图

- key-string:最常用的,一般用于存储一个值
- key-hash:存储一个对象数据的。
- key-list:使用list结构实现栈和队列结构。
- key-set:交集,差集和并集的操作。
- key-zset:排行榜,积分存储等操作。
3.2 Redis常用命令
# 1. 添加值
set key value
# 2. 取值
get key
# 3. 批量操作
mset key value [key value...]
mset key [key...]
# 4.自增命令(自增1)
incr key
# 5.自减命令(自增1)
decr key
# 6. 自增或自减指定数量
incrby key increment
decrby key increment
# 7.设置值的同时,指定生存时间(每次向Redis中添加数据时,尽量都设置上生存时间)
setex key second value
# 8.设置值,如果当前key不存在的话(如果这个key存在,什么事都不做,如果这个key不存在,和set命令一样)
setnx key value
# 9.在key对应的value后,追加内容
append key value
# 10.查看value字符串的长度
strlen key
3.3 hash常用命令
# 1.存储数据
hset key field value
# 2.获取数据
hget key field
# 3.批量操作
hmset key field value [field value...]
hmget key field [field...]
# 4. 自增(指定自增的值)
hincrby key field increment
# 5. 设置值(如果key-field 不存在,那么就正常添加,如果存在,什么事多不做)
hsetnx key field value
# 6.检查field是否存在
hexisis key field
# 7. 删除key 对应的某一个field,可以删除多个
hdel key field [field...]
# 8. 获取当前hash结构中的全部field和value
hgetall key
# 9. 获取当前hash结构中的全部field
hkeys key
# 10. 获取当前hash结构中的全部value
havls key
# 11.获取当前hash结构中field的数量
hlen key
3.4 list常用命令
# 1.存储数据(从左侧插入数据)
lpush key value [value...]
# 存储数据(从右侧插入数据)
rpush key value [value...]
# 2.存储数据(如果key不存在,什么事多不做,如果key存在,但是不是list结构,什么都不做)
lpushx key value
rpushx key value
# 3.修改数据(在存储数据时,指定好你的索引位置,覆盖之前索引位置的数据,index超出整个列表的长度,也会失败)
lset key index value
# 4.弹栈方式获取数据(左侧弹出数据,从右侧弹出数据)
lpop key
rpop key
# 5.获取指定索引范围的数据(start从0开始,stop 输入-1 ,代表最后一个,-2代表倒数第二个)
lrange key start stop
# 6. 获取指定索引位置的数据
lindex key index
# 7.获取整个列表的长度
llen key
# 8.删除列表中的数据(他是删除当前列表中的count个value值,count > 0从左侧向右侧删除,count < 0从右侧向左侧删除,count=0 删除列表中全部的value)
lrem key count value
# 9.保留列表中的数据(保留你指定索引范围的数据,超过整个索引范围的被移除掉)
ltrim key start stop
# 10.将一个列表中最后的一个数据,插入到另一个列表的头部位置
rpoplpush list1 list2
3.5 set常用命令
# 1.存储数据
sadd key member [member...]
# 1. 获取数据(获取全部数据)
smembers key
#3. 随机获取一个数据(获取的同时,移除数据,count默认为1,代表弹出数据的数量)
spop key [count]
# 4. 交集(取多个set集合交集)
sinter set1 set2 ....
# 5.并集(获取全部集合 中的数据 )
sunion set1 set2 ...
# 6.差集(获多个集合中不一样的数据)
sdiff set1 set2 ...
# 7.删除数据
srem key member [member...]
# 8.查看当前的set集合中是否包含这个值
sismember key member
3.6 zset的常用命令
# 1. 添加数据(score必须是一个数值,member不允许重复的)
zadd key score member [score member...]
# 2. 修改member的分数(如果member是存在于key中的,正常增加分数,如果member不存在,这个命令就相当于zadd)
zincrby key increment member
# 3.查看指定的member的分数
zscore key member
# 4. 获取zset中数据的数量
zcard key
# 5.根据score的范围查看member数量
zcount key min max
# 6.删除zset中的成员
zrem key member [member...]
# 7. 根据分数从小到大排序,获取指定范围内数据(withscore如果添加这个参数,那么会返回member对应的分数)
zrange key start stoop [withscore]
#8.根据分数从大到小排序,获取指定范围内数据(withscore如果添加这个参数,那么会返回member对应的分数)
zrevrange key start stoop [withscore]
# 9.根据分数的范围去获取数据(withscore代表同时返回score,添加limit,就和MySQL中一样,如果不希望等于min或者max的值被查询出来可以采用“(分数” 相当于 < 但是不等于的方式,最大值和最小值使用+inf和-inf来标识)
zrangebyscore key min max [withscore] [limit offset count]
# 10.根据分数的返回去获取member(withscore代表同时返回score,添加limit,就和MySQL中一样)
zrevrangebyscore key max min [withscore] [limit offset count]
3.7 key常用命令
# 1.查看Redis中的全部的key (pattern: * , xxx* , *xxx)
keys pattern
# 2.查看某一个key是否存在(1 —— 可以存在,0 —— 可以不存在)
exists key
# 3.删除key
del key [key...]
# 4.设置key的存在时间,单位为秒,单位为毫秒,设置还能活多久
expire key second
pexpire key milliseconds
# 5.设置key的生存时间,单位为秒,单位为毫秒,设置能活到什么时间点
expireat key timestamp
pexpireat key milliseonds
# 6.查看key 的剩余生存时间,单位为秒,单位为毫秒(-2 —— 当前key不存在,-1 —— 当前key没有设置生存时间,具体剩余的生存时间)
ttl key
pttl key
# 7.移除key的生存时间(1——移除成功,0——key不存在生存时间,key不存在)
persist key
# 8.选择操作的库
select 0~15
# 9.移动key到另外一个库中
move key db
3.8库的常用命令
# 1.清空当前所在的数据库
flushdb
# 2.清空全部数据库
flushall
# 3.查看当前数据库中有多少个key
dbsize
# 查看最后一次操作的时间
lastsave
# 5. 实时监控Redis 服务接收到的目录
monitor
四、Java连接Redis
- Jedis连接Redis,Lettuce连接Redis
4.1 Jedis连接Redis
- 1.创建Maven项目
- 2.导入需要的依赖
<dependencies>
<!--1、Jedis-->
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>2.9.0</version>
</dependency>
<!--2、Junit-->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>test</scope>
</dependency>
<!--3、Lombok-->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.16.20</version>
</dependency>
</dependencies>
- 3.测试
@Test
public void test(){
//1、连接Redis
Jedis jedis=new Jedis("192.168.0.127",6379);
//2、操作Redis——因为Redis的命令是什么,Jedis的方法就是什么
jedis.set("name","李四");
//3、释放资源
jedis.close();
}
@Test
public void get(){
//1、连接Redis
Jedis jedis=new Jedis("192.168.0.127",6379);
//2、操作Redis——因为Redis的命令是什么,Jedis的方法就是什么
System.out.println(jedis.get("name"));
//3、释放资源
jedis.close();
}
4.2 Jedis如何以数组存储一个对象到Redis
1、准备一个User实体类
@Data
@NoArgsConstructor
@AllArgsConstructor
public class User implements Serializable {
private Integer id;
private String name;
private Date birthday;
}
2、导入spring-context依赖
<!--4、导入Spring-context-->
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-context</artifactId>
<version>4.3.18.RELEASE</version>
</dependency>
3、创建Demo测试类,编写内容
//存储对象——对byte[]形式存储在Redis中
@Test
public void setByteArray(){
//1、连接Redis服务
Jedis jedis = new Jedis("192.168.0.127",6379);
//2.1、准备key(String)-value(User)
String key="user";
User value = new User(1, "张三", new Date());
//2.2、将key和value转换为byte[]
byte[] serialize = SerializationUtils.serialize(key);
byte[] serialize1 = SerializationUtils.serialize(value);
//2.3、将key和value存储到Redis
jedis.set(serialize,serialize1);
//3、释放资源
jedis.close();
}
//获取对象——对byte[]形式存储在Redis中
@Test
public void getByteArray(){
//1、连接Redis服务
Jedis jedis = new Jedis("192.168.0.127",6379);
//2.1、准备key(String)-value(User)
String key="user";
User value = new User(1, "张三", new Date());
//2.2、将key和value转换为byte[]
byte[] serialize = SerializationUtils.serialize(key);
byte[] serialize1 = SerializationUtils.serialize(value);
//2.3、将key和value存储到Redis
byte[] bytes = jedis.get(serialize);
//2.4 反序列化
Object deserialize = SerializationUtils.deserialize(bytes);
System.out.println(deserialize);
//3、释放资源
jedis.close();
}
4、String转换byte需要用到spring-context的jar包
<!--4 、导入Spring-Context-->
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-context</artifactId>
<version>4.3.18</version>
</dependency>
4.3 Jedis如何以String存储一个对象到Redis
- 导入依赖
<!--JSON与String之间的转换-->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.47</version>
</dependency>
- 测试
public class Dmeo3 {
//以String-key存储
@Test
public void setString(){
//1、连接Redis
Jedis jedis = new Jedis("127.0.0.1", 6379);
//2.1 准备Key(String)——value(User)
String key="stringkey";
User user = new User(2, "李四", new Date());
//2.2 使用fastJSON将value装化为json字符串
String s = JSON.toJSONString(user);
//2.3存储到Redis中
jedis.set(key,s);
//3、释放资源
jedis.close();
}
//读取
@Test
public void getString(){
//1、连接Redis
Jedis jedis = new Jedis("127.0.0.1", 6379);
//2.1 准备Key(String)——value(User)
String key="stringkey";
//2.3取出到Redis中
String s1 = jedis.get(key);
//2.2 使用fastJSON将value装化为User对象
User user=JSON.parseObject(s1,User.class);
System.out.println(user.toString());
//3、释放资源
jedis.close();
}
}
4.4 Jedis连接池的操作
@Test
public void pool2(){
//1、创建指定连接池的配置信息
GenericObjectPoolConfig poolConfig = new GenericObjectPoolConfig();
poolConfig.setMaxTotal(100); //连接池中最大的活跃数
poolConfig.setMaxIdle(10); //最大空闲数
poolConfig.setMinIdle(5); //最小空闲数
poolConfig.setMaxWaitMillis(3000); //当连接池空了之后,多久没获取到Jedis对象,就超时
//2、创建连接池
JedisPool pool=new JedisPool(poolConfig,"127.0.0.1",6379);
//3、通过连接池获取jedis对象
Jedis jedis = pool.getResource();
//4、操作
System.out.println(jedis.get("stringkey"));
//5、释放资源
jedis.close();
}
4.5 Redis的管道操作
- 因为在操作Redis的时候,执行一个命令需要先发送请求到Redis服务器,这个过程需要经历网络的延迟,Redis还需要给客户端一个响应。
- 如果我需要一次性执行很多命令,上述的方式效率很低,可以通过Redis的管道,先将命令放到客户端的一个Pipeline中,之后一次性的将全部命令都发送到Redis服务,Redis服务一次性的将全部的放回结果响应给客户端。
//Redis管道操作
@Test
public void pipeline(){
//1、创建连接池
JedisPool pool = new JedisPool("127.0.0.1", 6379);
long x = System.currentTimeMillis();
System.out.println(x);
/* //2、获取一个连接对象
Jedis jedis = pool.getResource();
//3、执行incr - 100000次
for (int i = 0; i < 100000; i++) {
jedis.incr("pp");
}
//4、释放资源
jedis.close();*/
//=================
//2、获取一个连接对象
Jedis jedis1 = pool.getResource();
//3、创建管道
Pipeline pipeline=jedis1.pipelined();
//4、执行incr - 100000次放到管道中
for (int i = 0; i < 100000; i++) {
pipeline.incr("qq");
}
//5、执行命令
pipeline.syncAndReturnAll();
//6、释放资源
jedis1.close();
long x1 = System.currentTimeMillis();
System.out.println(x1-x);
}
五、Redis其他配置及集群
- 修改yml文件,以方便后期修改Redis配置信息
version: '3.1'
services:
redis:
image: daocloud.io/library/redis:5.0.7
restart: always
container_name: redis
environment:
- TZ=Asia/Shanghai
ports:
- 6379:6379
volumes:
- ./conf/redis.conf:/usr/local/redis/redis.conf
command:: ["redis-server","/usr/local/redis/redis.conf"]
注:command:加载文件
5.1 Redis的AUTH
- 方式一:通过修改Redis的配置文件,实现Redis的密码校验
# redis.conf
requirepass 密码
- 三种客户端的连接方式
-
- redis-cli:在输入正常命令之前,先输入auth指定密码即可
-
- 图形化界面:在连接Redis的信息中添加上验证的密码。
-
- Jedis客户端:
- 第一种:jedis.auth(password);
- 第二种:public JedisPool(GenericObjectPoolConfig poolConfig, String host, int port, int timeout, String password) { }
-
- 方式二:在不修改redis.conf文件的前提下,在第一次链接Redis时,输入命令:config set requirepass 密码 ,后续向再次操作Redis时,需要先AUTH一下验证(单Redis重启后失效)
Redis的事务
注:Redis允许同时开启RDB和AOF
- Redis的事务:一次事务操作,该成功的成功,该失败的失败。
- 先开启事务,执行一些列的命令,但是密码不会立即执行,会被放在一个队列中,如果你执行事务,那么这个队列的命令全部执行,如果取消了事务,一个队列中的命令全部作废。
- 1、开启事务:multi
- 2、输入要执行的命令:被放入到一个队列中
- 3、执行事务:exec
- 4、取消实物:discard
Redis的事务想发挥功能,需要配置watch监听机制
在开启事务之前,先通过watch命令去监听一个或多个key,在开启事务之后,如果其他客户端修改了我监听的key,事务会自动取消。
如果执行了事务,或者取消了事务,watch监听自动消除,一般不需要手动执行unwatch
5.3 Redis持久化
- RDB是Redis默认的持久化机制
- 1、RDB持久化文件,速度比较快,而且存储的是一个二进制的文件,传输起来很方便。
- 2、RDB持久化的时机:
- save 900 1:在900秒内,有1个key改变,就执行RDB持久化。
- save 300 10:在300秒内,有10个key改变,就执行RDB持久化。
- save 60 10000:在60秒内,有10000个key改变,就执行RDB持久化。
- 3、RDB无法保证数据的绝对安全。
# Redis的AUTH密码
# requirepass xxxx
# 900秒之内,有一个key改变了,就执行RDB持久化
save 900 1
save 300 10
save 60 10000
# 开启RBD持久化的压缩
rdbcompression yes
# RDB持久化文件的名称
dbfilename dump.rdb
-
AOF持久化策略(默认是关闭的,Redis推荐同时开启RDB和AOF持久化,更安全,避免数据丢失)
- 1、AOF持久化的速度,相对RDB比较慢,存储的是一个文本文件,到了后期文件会比较大,传输困难
- 2、AOF持久化时机:
- appendfsync always:每执行一次操作,立即执行到AOF文件中,性能比较低
- appendfsync everysec:每秒执行一次持久化
- appendfsync no:会根据你的系统不同,环境的不同,在一定时间内执行一次持久化。
- 3、AOF相对RDB更安全,推荐同事开启AOF和RDB。
-
关于同时开启RDB和AOF的注意事项:
- 如果同时开启了AOF和RDB持久化,南无在Redis宕机重启之后,需要加载一个持久化文件,优先选择AOF文件
- 如果先开启了RDB,再开启AOF,如果RDB执行了持久化,那么RDB文件中的内容会被AOF覆盖掉。
# AOF持久化策略
# yes代表开启AOF持久化
appendonly yes
# AOF文件的名称
appendfilename "appendonly.aof"
# AOF持久化执行的时机
# appendfsync always
appendfsync everysec
# appendfsync no
5.4 Redis的主从架构
- 单机版Redis存在读写瓶颈的问题

version: '3.1'
services:
redis1:
image: daocloud.io/library/redis:5.0.7
restart: always
container_name: redis1
environment:
- TZ=Asia/Shanghai
ports:
- 7001:6379
volumes:
- ./conf/redis1.conf:/usr/local/redis/redis.conf
command: ["redis-server","/usr/local/redis/redis.conf"]
redis2:
image: daocloud.io/library/redis:5.0.7
restart: always
container_name: redis2
environment:
- TZ=Asia/Shanghai
ports:
- 7002:6379
volumes:
- ./conf/redis2.conf:/usr/local/redis/redis.conf
links:
- redis1:master
command: ["redis-server","/usr/local/redis/redis.conf"]
redis3:
image: daocloud.io/library/redis:5.0.7
restart: always
container_name: redis3
environment:
- TZ=Asia/Shanghai
ports:
- 7003:6379
volumes:
- ./conf/redis3.conf:/usr/local/redis/redis.conf
links:
- redis1:master
command: ["redis-server","/usr/local/redis/redis.conf"]
# 添加从节点的配置(redis2和redis3的配置)
replicaof master 6379
5.5 哨兵
- 哨兵可以帮助我们解决主从架构中的单点故障问题

- 修改一下docker-compose.yml,为了可以在容器内部使用哨兵的配置
version: '3.1'
services:
redis1:
image: daocloud.io/library/redis:5.0.7
restart: always
container_name: redis1
environment:
- TZ=Asia/Shanghai
ports:
- 7001:6379
volumes:
- ./conf/redis1.conf:/usr/local/redis/redis.conf
- ./conf/sentinel1.conf:/usr/local/redis/redis.conf # 添加的内容
command: ["redis-server","/usr/local/redis/redis.conf"]
redis2:
image: daocloud.io/library/redis:5.0.7
restart: always
container_name: redis2
environment:
- TZ=Asia/Shanghai
ports:
- 7002:6379
volumes:
- ./conf/redis2.conf:/usr/local/redis/redis.conf
- ./conf/sentinel2.conf:/usr/local/redis/redis.conf # 添加的内容
links:
- redis1:master
command: ["redis-server","/usr/local/redis/redis.conf"]
redis3:
image: daocloud.io/library/redis:5.0.7
restart: always
container_name: redis3
environment:
- TZ=Asia/Shanghai
ports:
- 7003:6379
volumes:
- ./conf/redis3.conf:/usr/local/redis/redis.conf
- ./conf/sentinel3.conf:/usr/local/redis/redis.conf # 添加的内容
links:
- redis1:master
command: ["redis-server","/usr/local/redis/redis.conf"]
- 准备哨兵的配置文件,并且在容器内部手动启动哨兵即可。
# 哨兵需要后台启动
daemonize yes
# 指定Master节点的ip和端口号(主)
sentinel monitor master localhost 6379 2
# 指定Master节点的ip和端口号(从)
sentinel monitor master master 6379 2
# 哨兵每隔多久监听一次redis架构
sentinel down-after-milliseconds master 10000
- 在Redis容器内部启动sentinel即可
redis-sentinel sentinel.conf

5.6 Redis的集群
- Redis集群在保证主从加哨兵的基本功能之外,还能够提升Redis存储数据的能力。
Redis集群架构图

# docker-compose.yml
version: '3.1'
services:
redis1:
image: daocloud.io/library/redis:5.0.7
restart: always
container_name: redis1
environment:
- TZ=Asia/Shanghai
ports:
- 7001:7001
- 17001:17001
volumes:
- ./conf/redis1.conf:/usr/local/redis/redis.conf
command: ["redis-server","/usr/local/redis/redis.conf"]
redis2:
image: daocloud.io/library/redis:5.0.7
restart: always
container_name: redis2
environment:
- TZ=Asia/Shanghai
ports:
- 7002:7002
- 17002:17002
volumes:
- ./conf/redis2.conf:/usr/local/redis/redis.conf
command: ["redis-server","/usr/local/redis/redis.conf"]
redis3:
image: daocloud.io/library/redis:5.0.7
restart: always
container_name: redis3
environment:
- TZ=Asia/Shanghai
ports:
- 7003:7003
- 17003:17003
volumes:
- ./conf/redis3.conf:/usr/local/redis/redis.conf
command: ["redis-server","/usr/local/redis/redis.conf"]
redis4:
image: daocloud.io/library/redis:5.0.7
restart: always
container_name: redis4
environment:
- TZ=Asia/Shanghai
ports:
- 7004:7004
- 17004:17004
volumes:
- ./conf/redis4.conf:/usr/local/redis/redis.conf
command: ["redis-server","/usr/local/redis/redis.conf"]
redis5:
image: daocloud.io/library/redis:5.0.7
restart: always
container_name: redis5
environment:
- TZ=Asia/Shanghai
ports:
- 7005:7005
- 17005:17005
volumes:
- ./conf/redis5.conf:/usr/local/redis/redis.conf
command: ["redis-server","/usr/local/redis/redis.conf"]
redis6:
image: daocloud.io/library/redis:5.0.7
restart: always
container_name: redis6
environment:
- TZ=Asia/Shanghai
ports:
- 7006:7006
- 17006:17006
volumes:
- ./conf/redis6.conf:/usr/local/redis/redis.conf
command: ["redis-server","/usr/local/redis/redis.conf"]
# redis.conf
# 指定Redis的端口号
port 6379
# 开启Redis集群
cluster-enabled yes
# 集群信息的文件
cluster-config-file nodes-7001.conf
# 集群的对外ip地址
cluster-announce-ip 192.168.0.140
# 集群的对外端口号
cluster-announce-port 7001
# 集群的总线端口
cluster-announce-bus-port 17001
- 启动了6个Redis的节点
- 随便跳转到一个容器内部,使用redis-cli管理集群
# 启动
redis-cli --cluster create 192.168.0.140:7001 192.168.0.140:7002 192.168.0.140:700
3 192.168.0.140:7004 192.168.0.140:7005 192.168.0.140:7006 --cluster-replicas 1
# 随便跳转到一个容器内部,使用redis-cli管理集群,进入那个节点
redis-cli -h 192.168.0.140 -p 7001
5.7 Java链接Redis集群
- 使用JedisCluster对象连接Redis集群
public void test(){
//创建Set<HostAndPort>
Set<HostAndPort> hostAndPorts = new HashSet<>();
for (int i = 0; i < 6; i++) {
hostAndPorts.add(new HostAndPort("192.168.0.140",7001+i));
}
//创建JedisCluster对象
JedisCluster cluster = new JedisCluster(hostAndPorts);
//操作
System.out.println(cluster.get("a"));
}
六、Redis常见问题
6.1 key的生存时间到了,Redis会立即删除吗?
- 不会立即删除
- 1、定期删除:
- Redis每隔一段时间就去查看Redis设置了过期时间的key,会再100ms的间隔中默认查看3个key。
- 2、惰性删除:
- 如果当你去查询一个已经过期的key时,Redis会先查看当前key的生存时间,是否已经到了,直接删除当前key,并且给用户返回空值。
- 1、定期删除:
6.2 Redis的淘汰机制
- 在Redis内存已经满的时候,添加了一个新的数据,执行淘汰机制。
-
- volatile-lru:
- 在内存不足时,Redis会再设置过了生存时间的key中干掉一个最近最少使用的key。
-
- allkeys-lru:
- 在内存不足时,Redis会再全部的key中干掉一个最近最少使用的key。
-
- volatile-lfu:
- 在内存不足时,Redis会再设置过了生存时间的key中干掉一个最近最少频次使用的key。
-
- allkeys-lfu:
- 在内存不足时,Redis会再全部的key中干掉一个最近最少频次使用的key。
-
- volatile-random:
- 在内存不足时,Redis会再设置过了生存时间的key中随机干掉一个。
-
- allkeys-random:
- 在内存不足时,Redis会再全部的key中随机干掉一个。
-
- volatile-ttl:
- 在内存不足时,Redis会再设置过了生存时间的key中干掉一个剩余时间最短的一个。
-
- noeviction:
- 在内存不足时,直接报错。
指定淘汰机制的方式:maxmemory-policy具体策略
-
- 设置Redis的最大内存:maxmemory
6.3 缓存的常见问题
- 缓存穿透

- 缓存击穿

- 缓存雪崩

- 缓存倾斜

Zookeeper


一、Zookeeper介绍
1.1 引言
1、注册中心
2、配置集群管理
3、集群管理
4、分布式锁,分布式任务
5、队列的管理
1.2 Zookeeper介绍
- Zookeeper本身是Hadoop生态园的中一个组件,Zookeeper强大的功能,在Java分布式架构中,也会频繁的使用到Zookeeper。

- Zookeeper就是一个文件系统+监听通知机制
二、Zookeeper安装
1、Docker-compose.yml
version: "3.1"
services:
zk:
image: daocloud.io/daocloud/zookeeper:latest
restart: always
container_name: zk
ports:
- 2181:2181
三、Zookeeper架构
3.1 Zookeeper的架构图
- 每一个加点都被称为znode
- 每一个znode中都可以存储数据
- 节点名称是不允许重复的

3.2 znode类型
四种Znode:
1、持久节点
永久的保存在你的Zookeeper
2、持久有序节点
永久的保存在你的Zookeeper,他会给节点添加一个有序的序号。 /xx -> /xx0000001
3、临时节点
当存储的客户端和Zookeeper服务断开连接时,这个临时节点自动删除
4、临时有序节点
当存储的客户端和Zookeeper服务断开连接时,这个临时节点自动删除,他会给节点一个有序的序号 /xx -> /xx0000001
3.3 Zookeeper的监听通知机制
- 客户端可以去监听Zookeeper中的znode节点
- Znode改变时,会通知监听当前Znode的客服端

四、Zookeeper常用命令
- 1、查询:
# 查询当前节点下的全部子节点
ls 节点名称
# 例子 ls /
# 查询当前节点下的数据
get 节点名称
# 例子 get /
2、创建节点
create [-s] [-e] znode 名称 znode数据
# -s :sequence,有序节点
# -e :ephemeral,临时节点
```shell
3、修改节点数据
```shell
set znode名称 新数据
3、删除节点
delete znode名称 # 没有子节点的znode
deleteall znode名称 # 删除当前节点和全部的子节点,有些版本可能是rmr删除
五、Zookeeper集群
5.1 Zookeeper集群架构图

5.2 Zookeeper集群中节点的角色
1、Leader
Master主节点
2、Follower(默认的从节点)
从节点,参与选举全新的Leader
3、Observer
从节点,不参与报票
4、Looking
正在找Leader节点
5.3 Zookeeper投票策略
1、每一个Zookeeper服务都会被分配一个全局唯一的myid,myid是一个数字。
2、Zookeeper在执行数据时,每一个节点都有一个自己的FIFO的队列。保证写每一个数据的时候,顺序是不会乱的,Zookeeper还会给每一个数据分配一个全局唯一额zxid,数据越新zxid就越大。
选举Leader:
1、选举出zxid最大的节点作为Leader
2、在zxid相同的节点中,选举出一个myid最大的节点,作为Leader。
5.4 搭建Zookeeper集群
version: "3.1"
services:
zk1:
image: zookeeper
restart: always
container_name: zk1
ports:
- 2181:2181
environment:
ZOO_MY_ID: 1
ZOO_SERVERS: server.1=zk1:2888:3888;2181 server.2=zk2:2888:3888;2181 server.3=zk3:2888:3888;2181
zk2:
image: zookeeper
restart: always
container_name: zk2
ports:
- 2182:2181
environment:
ZOO_MY_ID: 2
ZOO_SERVERS: server.1=zk1:2888:3888;2181 server.2=zk2:2888:3888;2181 server.3=zk3:2888:3888;2181
zk3:
image: zookeeper
restart: always
container_name: zk3
ports:
- 2183:2181
environment:
ZOO_MY_ID: 3
ZOO_SERVERS: server.1=zk1:2888:3888;2181 server.2=zk2:2888:3888;2181 server.3=zk3:2888:3888;2181
六、Java操作Zookeeper
6.1 Java连接Zookeeper
1、创建Maven工程
2、导入依赖
<dependencies>
<dependency>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
<version>3.6.0</version>
</dependency>
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-recipes</artifactId>
<version>5.1.0</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
</dependencies>
3、编写连接Zookeeper集群的工具类
package com.qf;
import org.apache.curator.RetryPolicy;
import org.apache.curator.framework.CuratorFramework;
import org.apache.curator.framework.CuratorFrameworkFactory;
import org.apache.curator.retry.ExponentialBackoffRetry;
public class ZKUtil {
public static CuratorFramework cf(){
RetryPolicy retrypolicy=new ExponentialBackoffRetry(3000,2);
CuratorFramework cf= CuratorFrameworkFactory.builder()
.connectString("192.168.31.240:2181,192.168.31.240:2182,192.168.31.240:2183")
.retryPolicy(retrypolicy)
.build();
cf.start();
return cf;
}
}
4、测试(不报错就可以了)
@Test
public void connect(){
CuratorFramework cf = ZKUtil.cf();
}
6.2 Java操作Znode节点
1、查询
CuratorFramework cf = ZKUtil.cf();
@Test
public void selectZnode() throws Exception {
List<String> strings = cf.getChildren().forPath("/");
for (String string : strings) {
System.out.println(string);
}
}
@Test
public void getData() throws Exception {
byte[] bytes = cf.getData().forPath("/qf");
System.out.println(new String(bytes,"UTF-8"));
}
2、添加
@Test
public void create() throws Exception {
cf.create().withMode(CreateMode.PERSISTENT).forPath("/qf2","uuuu".getBytes());
}
3、修改
@Test
public void update() throws Exception {
cf.setData().forPath("/qf2","oooo".getBytes());
}
4、删除
@Test
public void delete() throws Exception {
cf.delete().deletingChildrenIfNeeded().forPath("/qf2");
}
5、查看znode的状态
@Test
public void status() throws Exception {
Stat stat = cf.checkExists().forPath("/qf");
System.out.println(stat);
}
6.3 监听Znode节点
CuratorFramework cf = ZKUtil.cf();
@Test
public void listen() throws Exception {
//1、创建NodeCache对象,指定要监听的znode
final NodeCache nodeCache=new NodeCache(cf,"/qf");
nodeCache.start();
//2、添加一个监听器
nodeCache.getListenable().addListener(new NodeCacheListener() {
public void nodeChanged() throws Exception {
byte[] data = nodeCache.getCurrentData().getData();
Stat stat = nodeCache.getCurrentData().getStat();
String path = nodeCache.getCurrentData().getPath();
System.out.println("监听的节点是:"+path);
System.out.println("节点现在的数据是:"+new String(data,"UTF-8"));
System.out.println("节点状态是:"+stat);
}
});
System.out.println("开始启动");
//3、System.in.read();
System.in.read();
}
分布式处理方案


一、分布式锁介绍
- 由于传统的锁是基于Tomcat服务器内部的,搭建了集群之后,导致锁失效
- 使用分布式锁来处理

二、分布式锁解决方案
2.1 搭建环境
1、创建SpringBoot工程
2、编写抢购业务
@RestController
public class SecondKillController {
//1、准备商品的库存
public static Map<String,Integer> itemStock=new HashMap<>();
//2、准备商品的订单
public static Map<String,Integer> itemOrder=new HashMap<>();
static {
itemStock.put("牙刷",10000);
itemOrder.put("牙刷",0);
}
@GetMapping("/kill")
public String kill(String item) throws InterruptedException {
//1、减库存
Integer stock=itemStock.get(item);
if (stock<=0){
return "商品库存不足!!!";
}
Thread.sleep(100);
itemStock.put("牙刷",stock-1);
//2、创建订单
Thread.sleep(100);
itemOrder.put(item,itemOrder.get(item)+1);
//3、返回信息
return "抢购成功!!!"+item+":剩余库存数为 - "+itemStock.get(item)+",订单数为:"+itemOrder.get(item);
}
}
3、下载ab压力测试
下载地址:https://www.apachehaus.com/cgi-bin/download.plx?dli=QZsZEaTtWQ41ERBJjSI5UWZNlVUNlVSZ0SsZERhdFO
使用方式:
cmd打开到bin目录,命令:
ab -n
4、测试















 1841
1841











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









