






书生·浦语大模型实战营基础作业合集
实战营项目地址:InternLM/tutorial (github.com)
第一课 书生·浦语大模型全链路开源体系
第一课为视频课主要介绍了大模型、书生·浦语大模型的发展,从基础模型到实际应用的主要步骤,以及书生·浦语全链条开源开放体系等。
“参考”链接:书生·浦语大模型实战营(一):书生·浦语大模型全链路开源体系 (i-square.github.io)
1、发展历程
在过去,人工智能领域的发展一直遵循着一个基本原则:一个模型对应一个场景或者任务。然而,随着技术的进步和需求的增长,这一格局正在发生深刻的变化。如今,我们正迈向一个新的时代,一个模型不再局限于一个场景或任务,而是可以应用于多个场景、多模态的复杂环境中。
书生·浦语大模型的发展历程彰显了这一变革的重要性。它从轻量级的7B社区模型,逐步升级到中量级的20B商业模型,再到重量级的123B全场景模型。这一演进不仅仅是在模型规模上的提升,更是对多模态、多场景应用需求的积极响应。

2、从模型到应用
第一步:模型选型
在应用场景中,根据多个大模型的相关维度进行能力比较,并进行模型评测。初步选型后,可确定意向大模型。
第二步:评估业务场景复杂度
业务场景简单: 如果业务场景不太复杂,可以直接将选定的模型应用于场景中。
业务场景复杂: 对于复杂场景,通常直接使用开源模型难以满足需求,需要进一步微调、进行prompt工程等构建工作。
第三步:判断微调策略
全参数微调: 若算力足够,可以进行全参数微调,提高模型性能。
部分参数微调: 如果算力受限,只能进行部分参数微调,固定大部分参数,调整一小部分参数。
第四步:构建智能体
模型与环境交互: 考虑模型与环境的交互,特别是如果需要调用外部API或与已有业务数据库交互,则需要构建智能体。
无环境交互: 如果模型在业务场景中不需要与环境进行交互,可以直接将微调好的模型应用于场景。
第五步:模型评测与应用上线
模型评测: 进行模型评测,确保在实际场景中表现良好。
上线或迭代: 根据评测结果,决定是否上线应用或者继续迭代模型。
第六步:模型部署
考虑软件系统相关性能、安全、功能等方面内容:
资源优化: 考虑如何以更少的资源部署模型。
吞吐量提升: 提升整个应用的吞吐量,确保在生产环境中的性能表现。
这六个步骤构成了从选择模型到应用部署的全链条,确保在实际应用中大模型能够充分发挥作用。
3、书生·浦语大模型全链路开源体系
书生·浦语大模型打破了传统的人工智能应用模式,提出了全链条开源开放体系。这一体系涵盖了从数据到预训练、微调、部署、评测到应用的全过程,为通用人工智能的实现提供了完整的解决方案。数据(书生·万卷)作为起点,经过IntermLM-Train的预训练,使用XTuner进行微调,通过LMDeploy实现部署,通过OpenCompass进行全面评测,最终应用在Lagent构建的多模态智能体中。
这一全链条开源开放体系,为大模型的发展提供了创新性的方法,促使人工智能更好地服务于多样化的现实需求。

数据:覆盖多模态和任务
全链条开源体系以书生-万卷为基础,涵盖了多模态和多任务的数据需求,为模型的学习提供了全面支持。
OpenDataLab:开放数据平台
OpenDataLab作为开放数据平台,不仅包含丰富多样的开放数据,还为大模型的发展提供了数据支持和实验平台。
预训练:并行训练,极致优化
InterLM采用并行训练的方式,通过极致优化实现了高效的预训练,为模型的通用性奠定基础。
微调:XTuner,支持全参数微调,支持Lora等低成本微调
微调阶段使用XTuner工具,支持全参数微调,同时还支持诸如Lora等低成本微调方法,使模型更好地适应各种特定任务。
特性:
- 增量续训:让基座模型学习新知识,垂直领域
- 有监督微调:让模型学会理解和遵循各种指令。一般采用全量参数微调和部分参数微调等方法。
- 多种微调算法:多种微调策略与算法,覆盖各类SFT场景。
- 适配多种开源生态:支持加载HuggingFace、ModelScope模型或者数据级
- 自动优化加速:开发者无需关注复杂的显存优化和计算加速细节
部署:LMDeploy,全链路部署,性能领先
LMDeploy提供了全链路部署的解决方案,包括模型轻量化、推理和服务,使得大模型在GPU上的部署更加高效,性能领先。
评测:OpenCompass,全方位评测,性能可以复现,全球领先的大模型开源评测体系
评测阶段使用OpenCompass工具,全方位评测模型性能,保证了评测结果的复现性,成为全球领先的大模型开源评测体系。
特性:
- 丰富模型支持:开源模型、API模型一站式评测。
- 分布式高效评测:支持千亿参数模型在海量数据集上分布式评测。
- 便捷的数据集接口:支持社区用户根据自身需求快速添加自定义数据集。
- 敏捷的能力迭代:每周更新大模型能力榜单。
应用:Legent、AgentLego 支持多种智能体,支持代码解释器和多种工具
最终,模型的应用在Legent和AgentLego等多种智能体中得以体现,支持代码解释器和多种工具,实现了多模态智能体的灵活应用。
特性:
- 丰富的工具集合,尤其是提供了大量视觉、多模态相关领域的工具。
- 支持多个主流智能体系统,如LangChain、Transformers Agent、Lagent等。
- 灵活的多模态工具调用接口,可以轻松支持各类输入输出格式的工具函数
- 一键式远程工具部署,轻松使用和调试大模型智能体
第二课 轻松玩转书生·浦语大模型趣味 Demo
教学视频:https://www.bilibili.com/video/BV1Ci4y1z72H/
指导文档:tutorial/helloworld/hello_world.md at main · InternLM/tutorial (github.com)
基础作业:
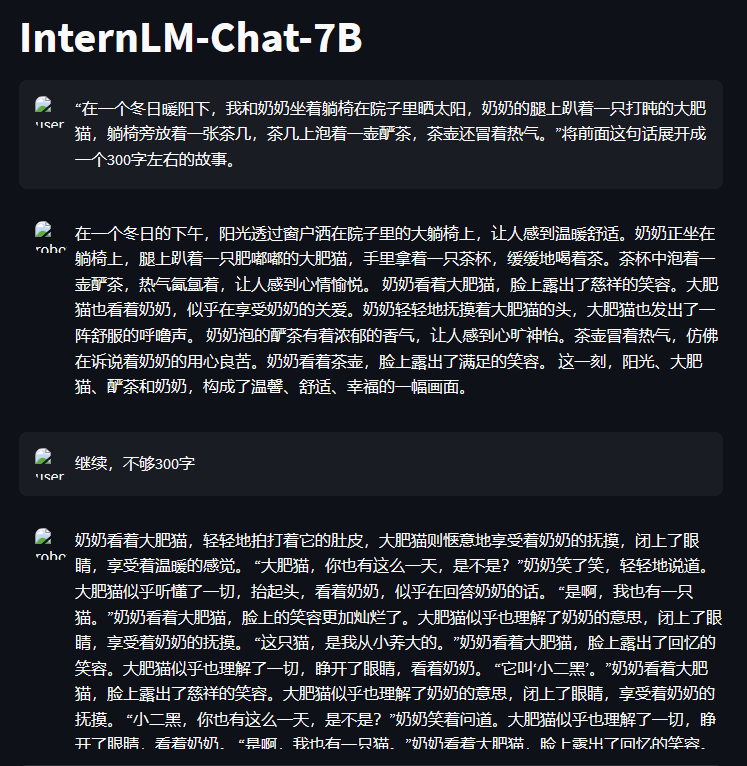
使用 InternLM-Chat-7B 模型生成 300 字的小故事(需截图)
启动程序
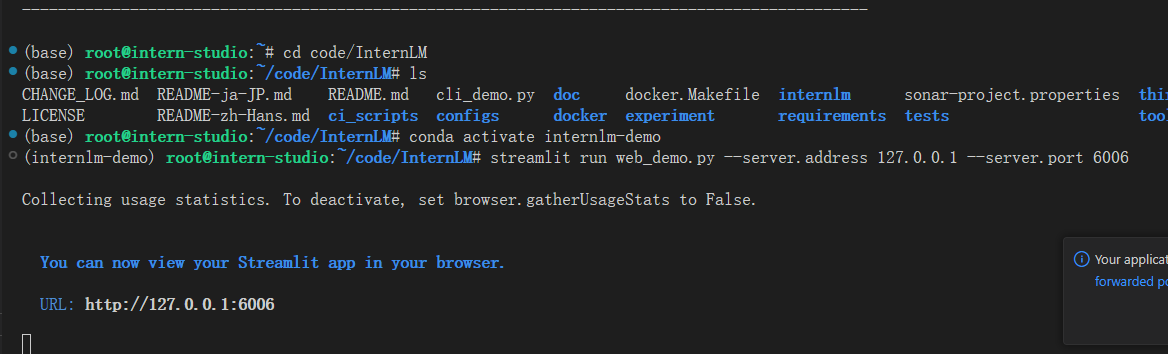
点击链接执行模型加载
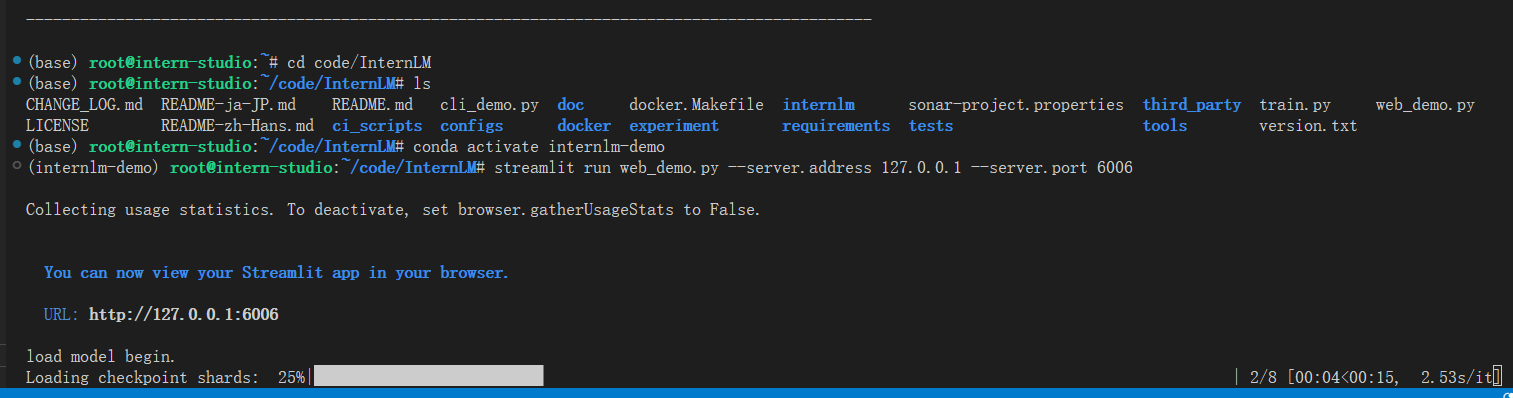
加载完成后即可进入web页面
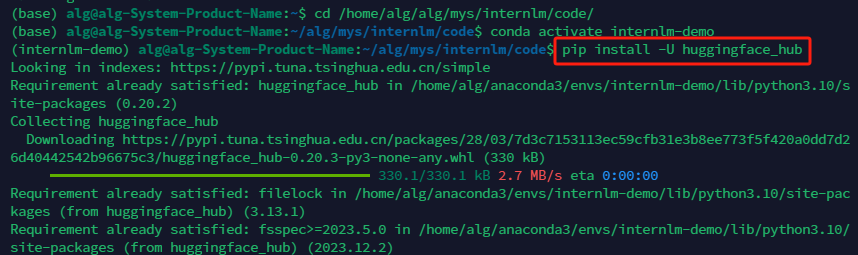
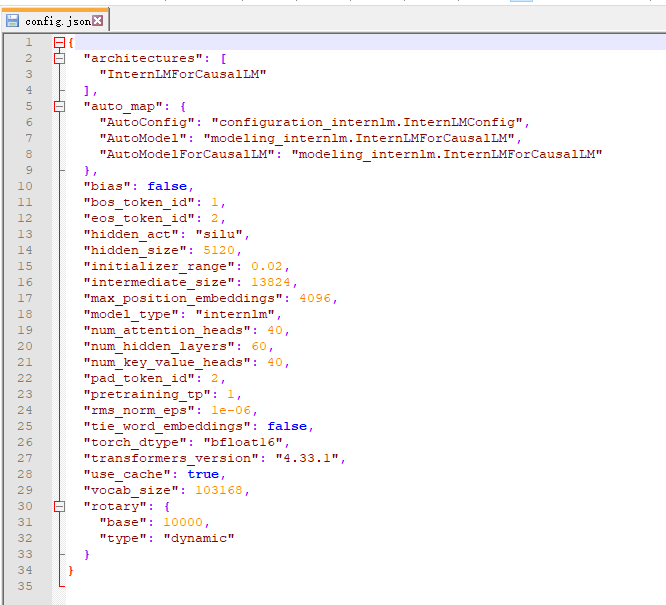
熟悉 hugging face 下载功能,使用 huggingface_hub python 包,下载 InternLM-20B 的 config.json 文件到本地(需截图下载过程)
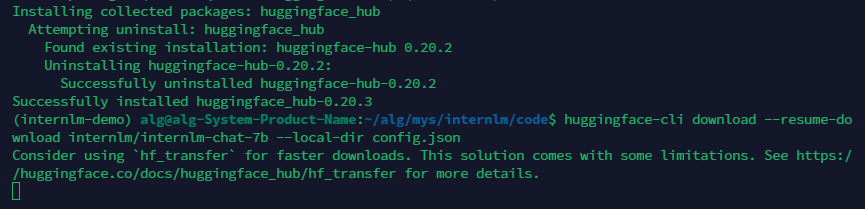
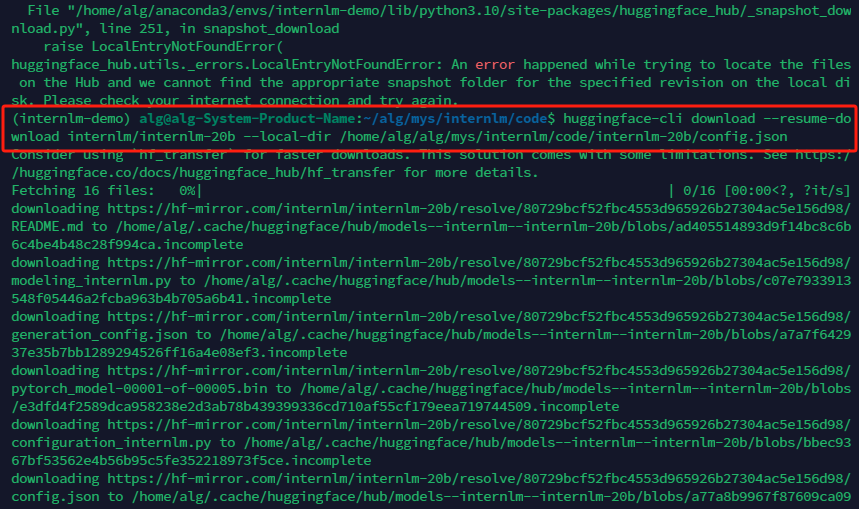
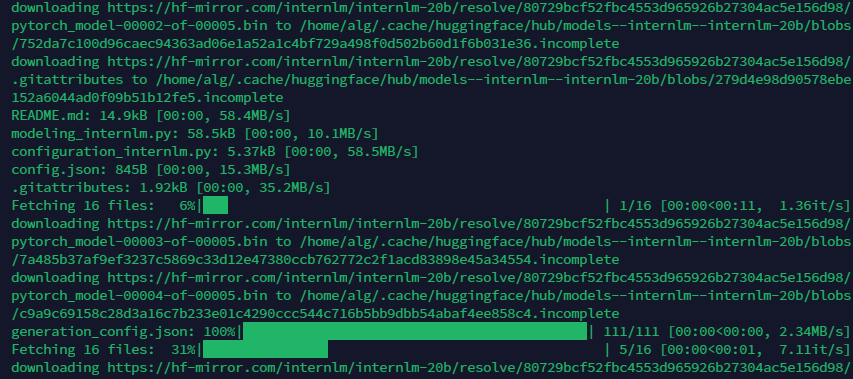
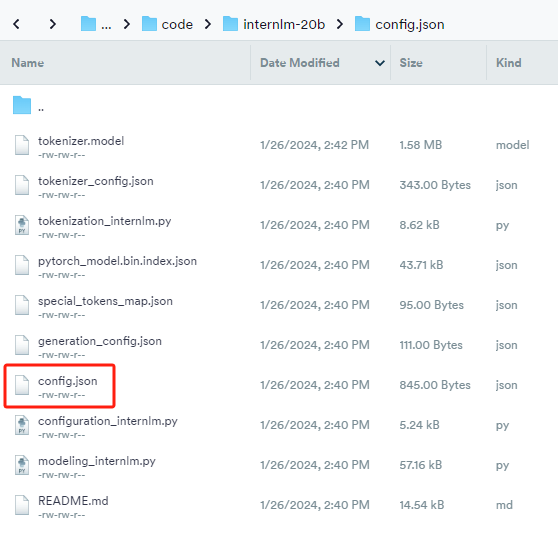
第三课 基于 InternLM 和 LangChain 搭建你的知识库
基础作业:
复现课程知识库助手搭建过程 (截图)
一、环境配置与模型下载
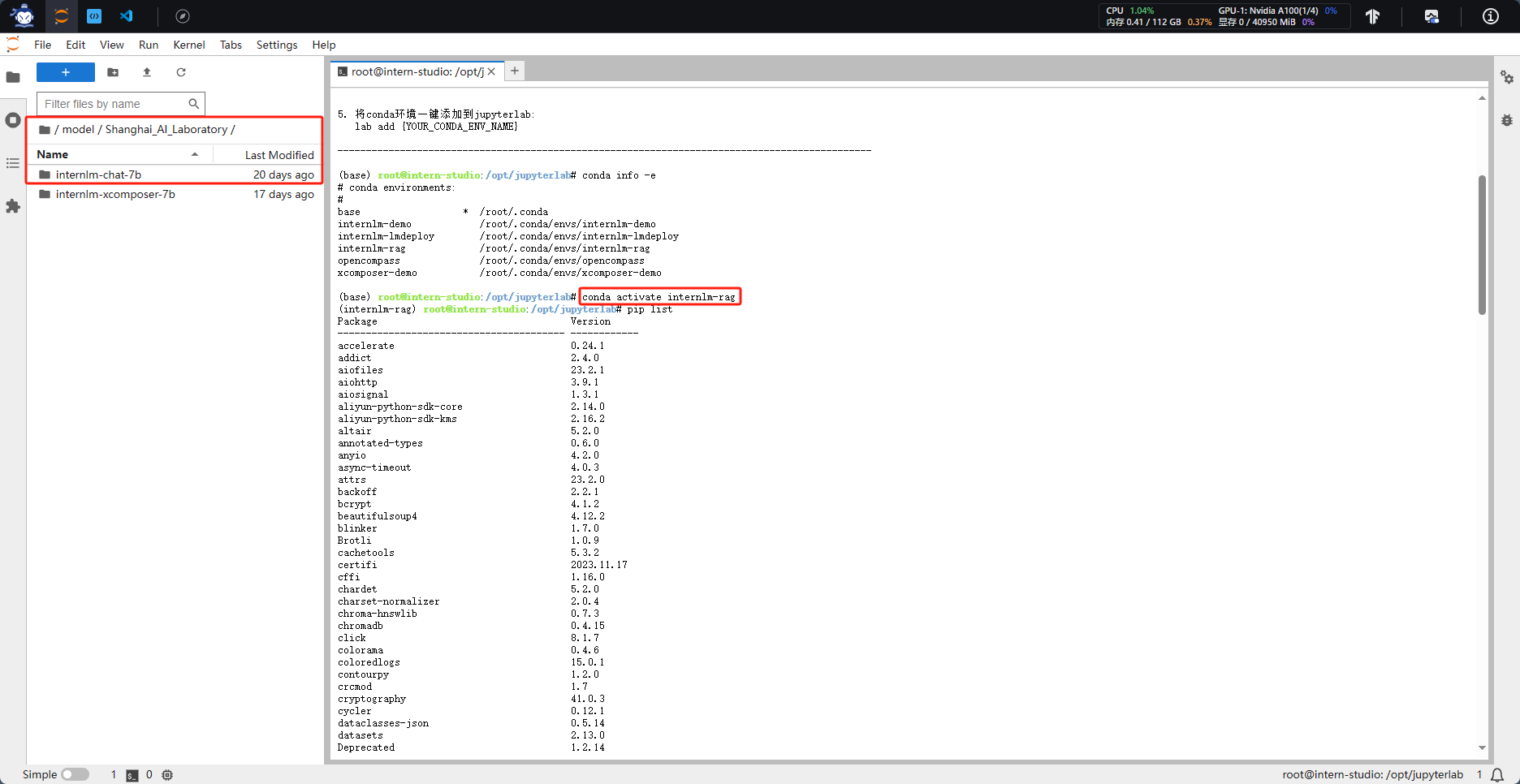
1.1 本节课使用之前已经创建的虚拟环境和下载好的模型:
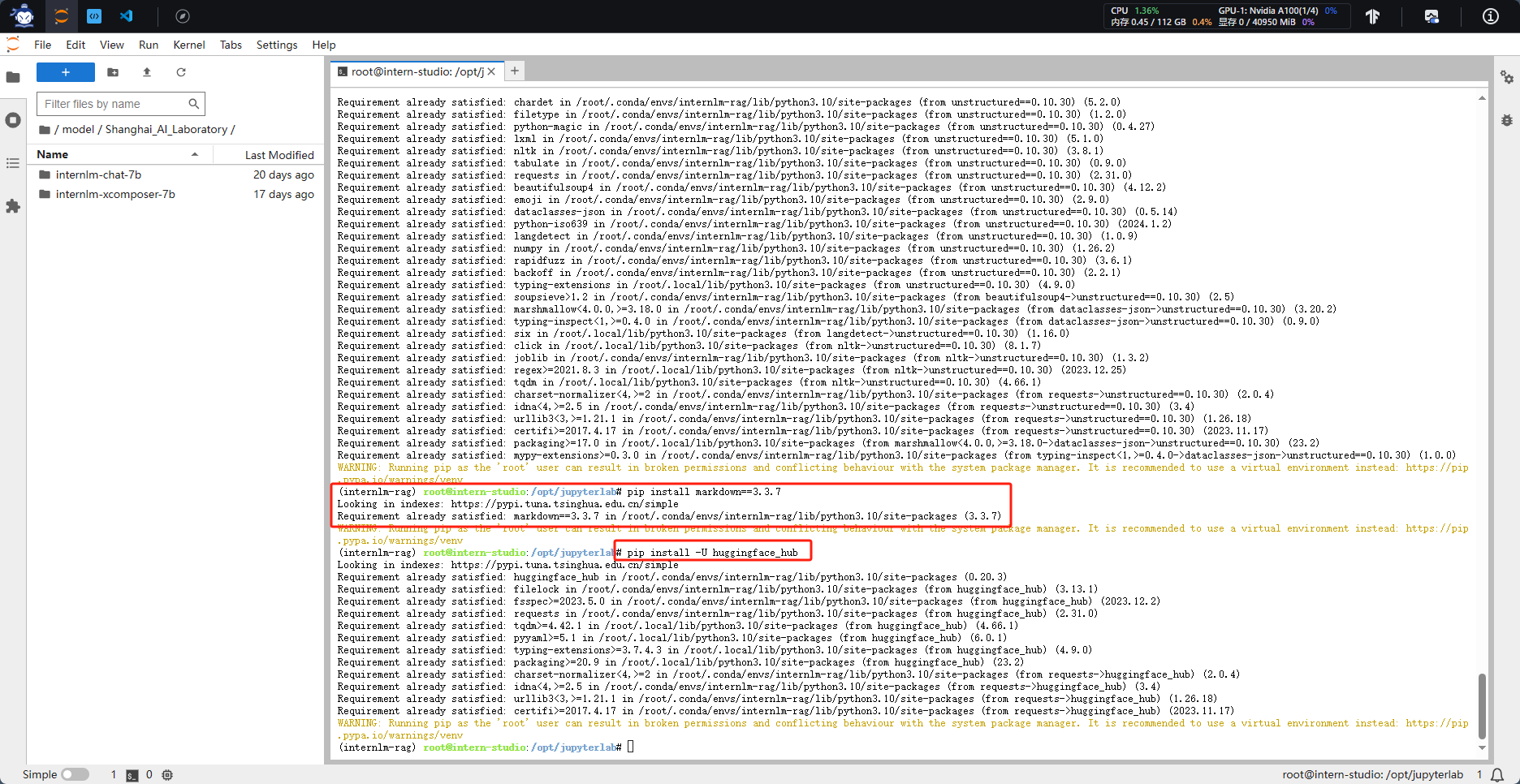
1.2 LangChain 相关环境配置
新建“data”文件夹,在该文件夹下新建用于开源词向量模型下载的python文件“download_hf.py”
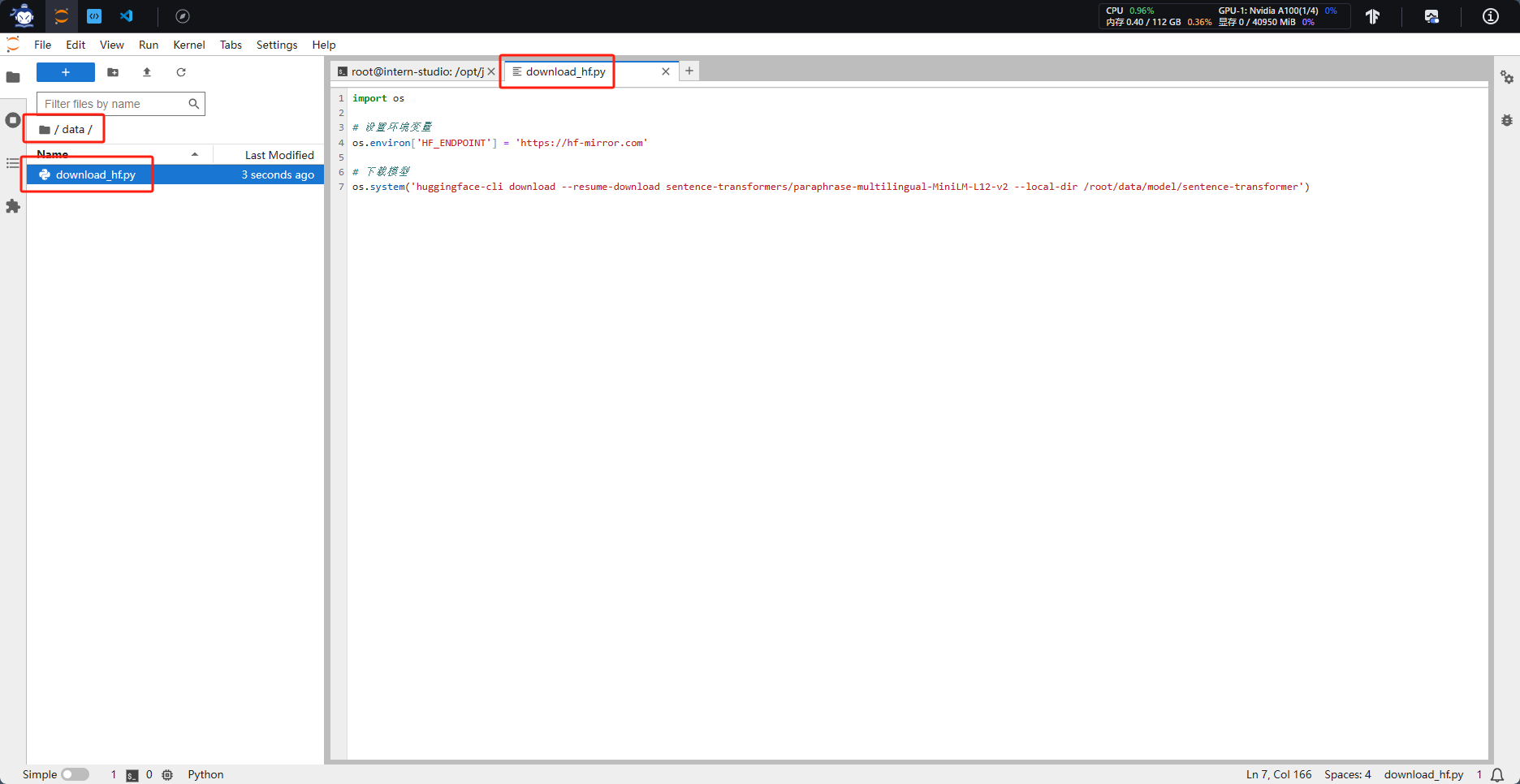
切换到data目录下,运行文件开启下载
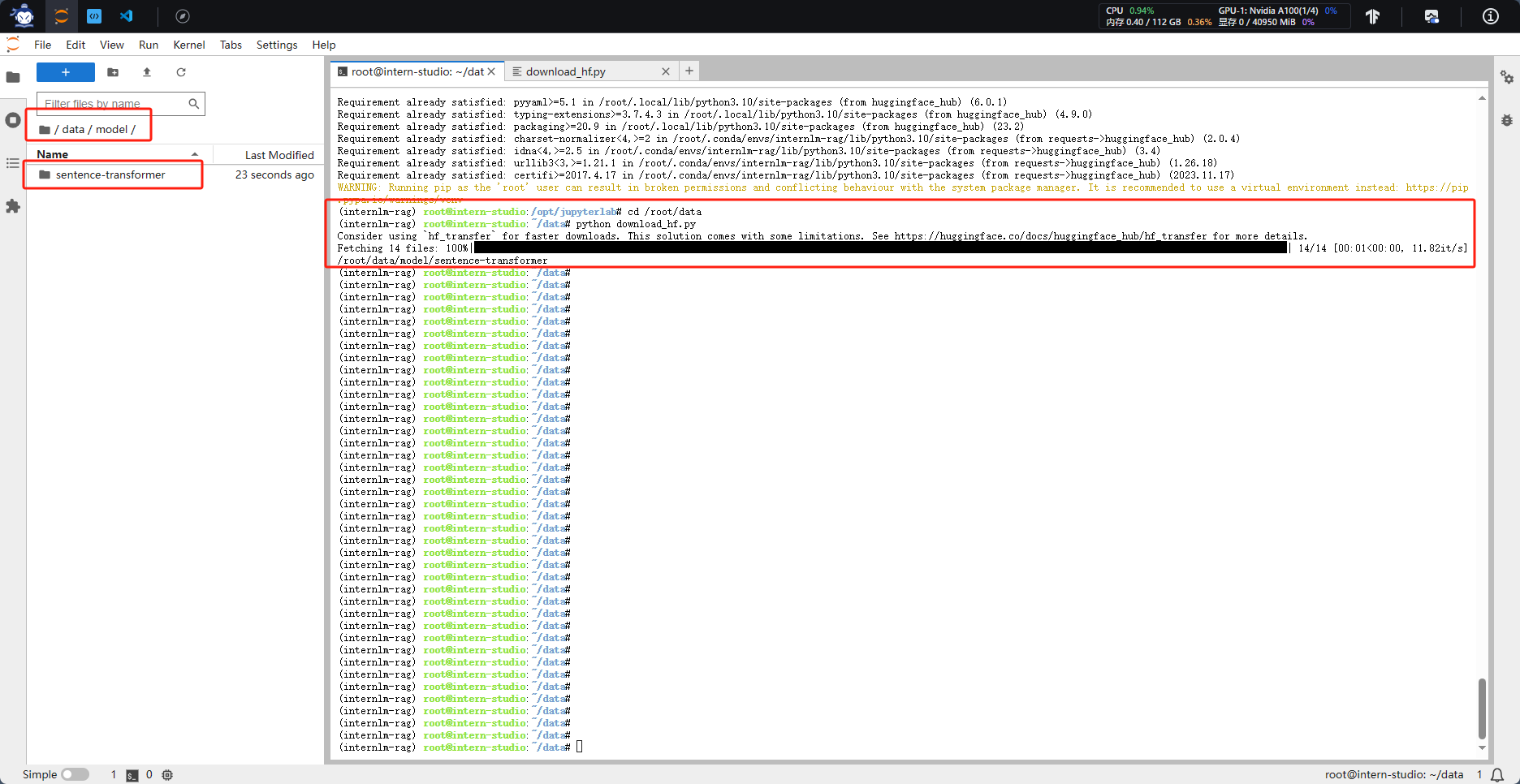
1.3 下载 NLTK 相关资源
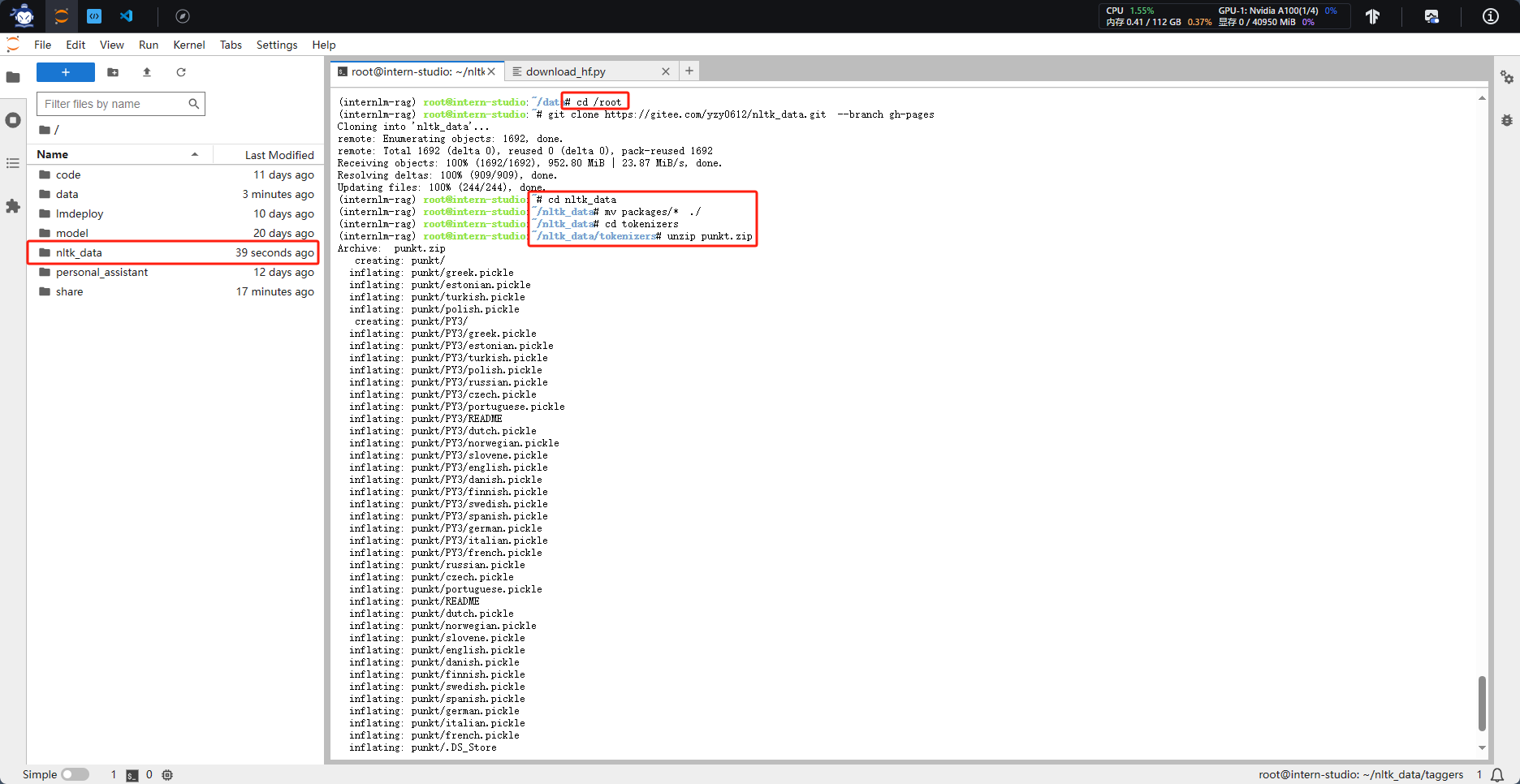
二、数据库搭建
2.1 数据收集
切换到data目录下,克隆相关的项目
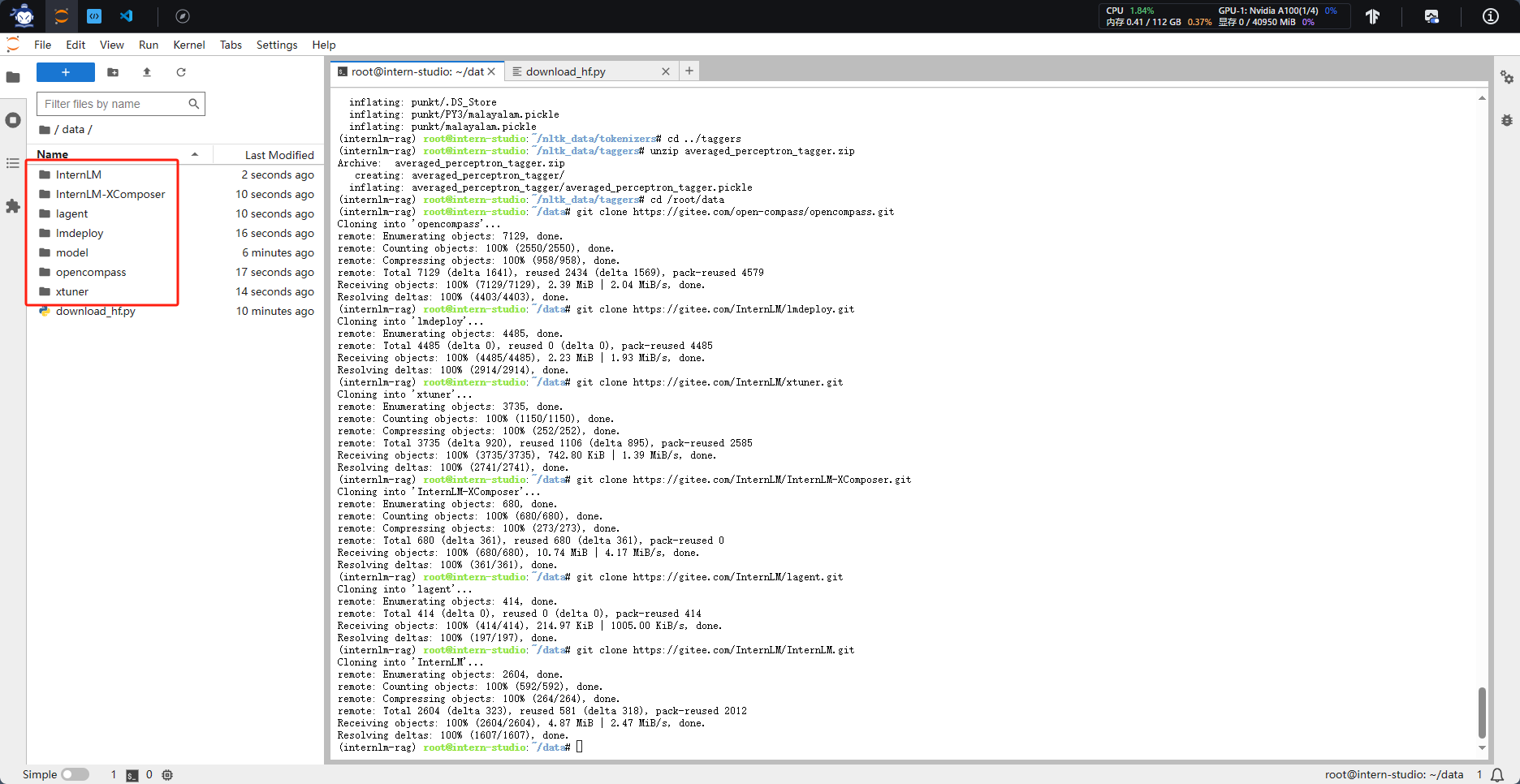
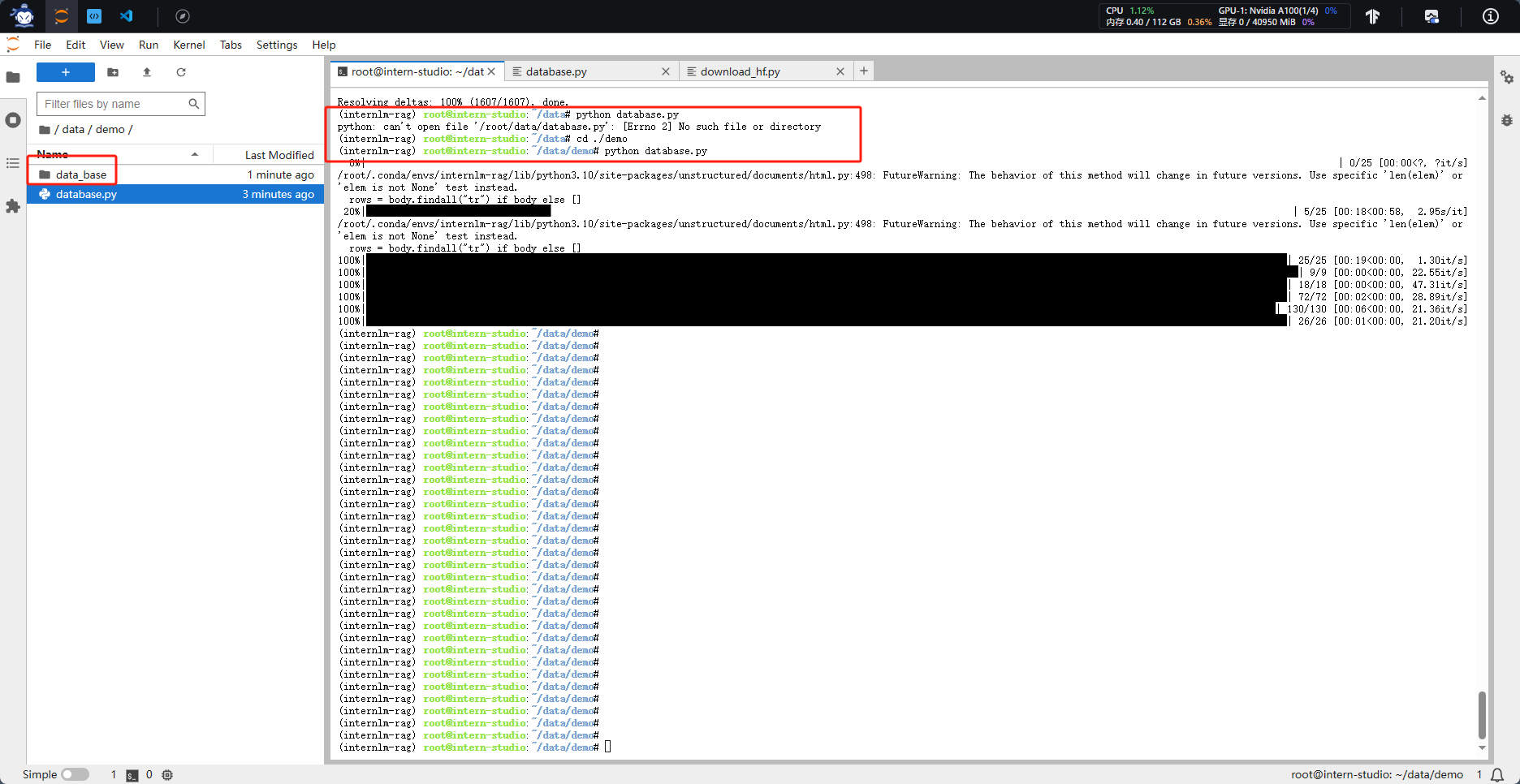
2.2 构建数据库
选用上述仓库中所有的 markdown、txt 文件作为示例语料库
在 /root/data 下新建一个 demo目录,将数据库构建脚本和后续脚本均放在该目录下运行。
三、InternLM 接入 LangChain
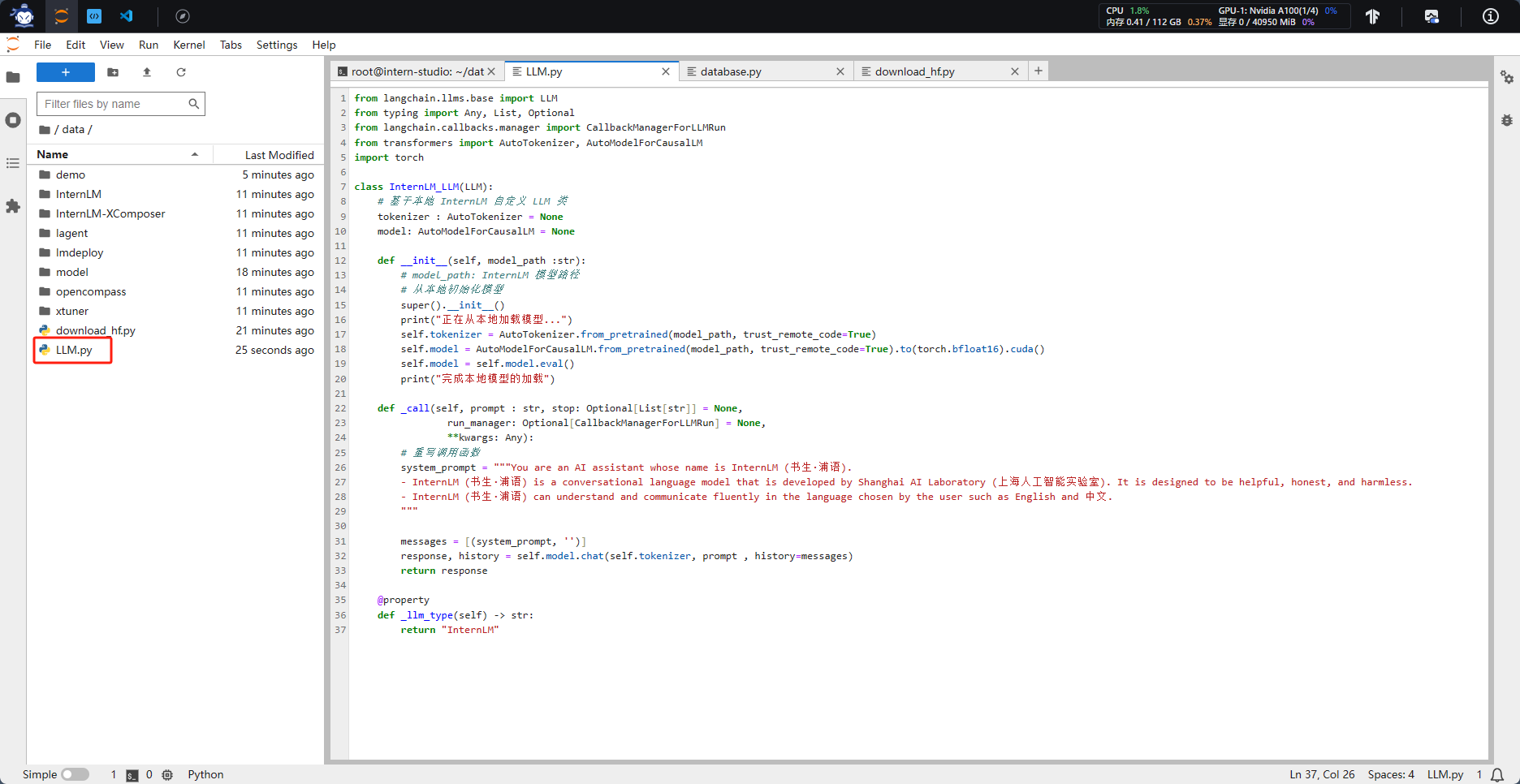
为便捷构建 LLM 应用,我们需要基于本地部署的 InternLM,继承 LangChain 的 LLM 类自定义一个 InternLM LLM 子类,从而实现将 InternLM 接入到 LangChain 框架中。完成 LangChain 的自定义 LLM 子类之后,可以以完全一致的方式调用 LangChain 的接口,而无需考虑底层模型调用的不一致。
基于本地部署的 InternLM 自定义 LLM 类并不复杂,我们只需从 LangChain.llms.base.LLM 类继承一个子类,并重写构造函数与 _call 函数即可。
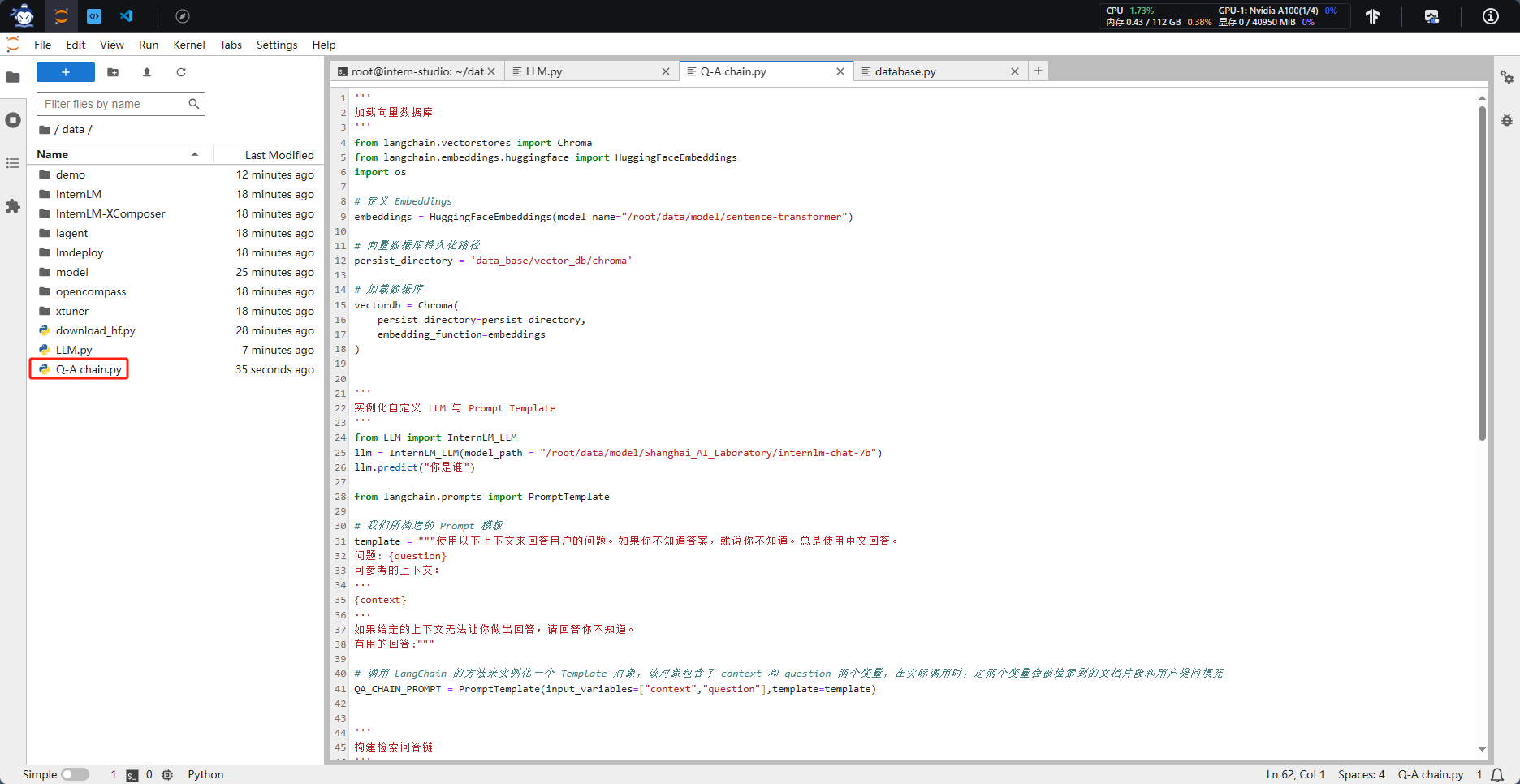
四、构建检索问答链
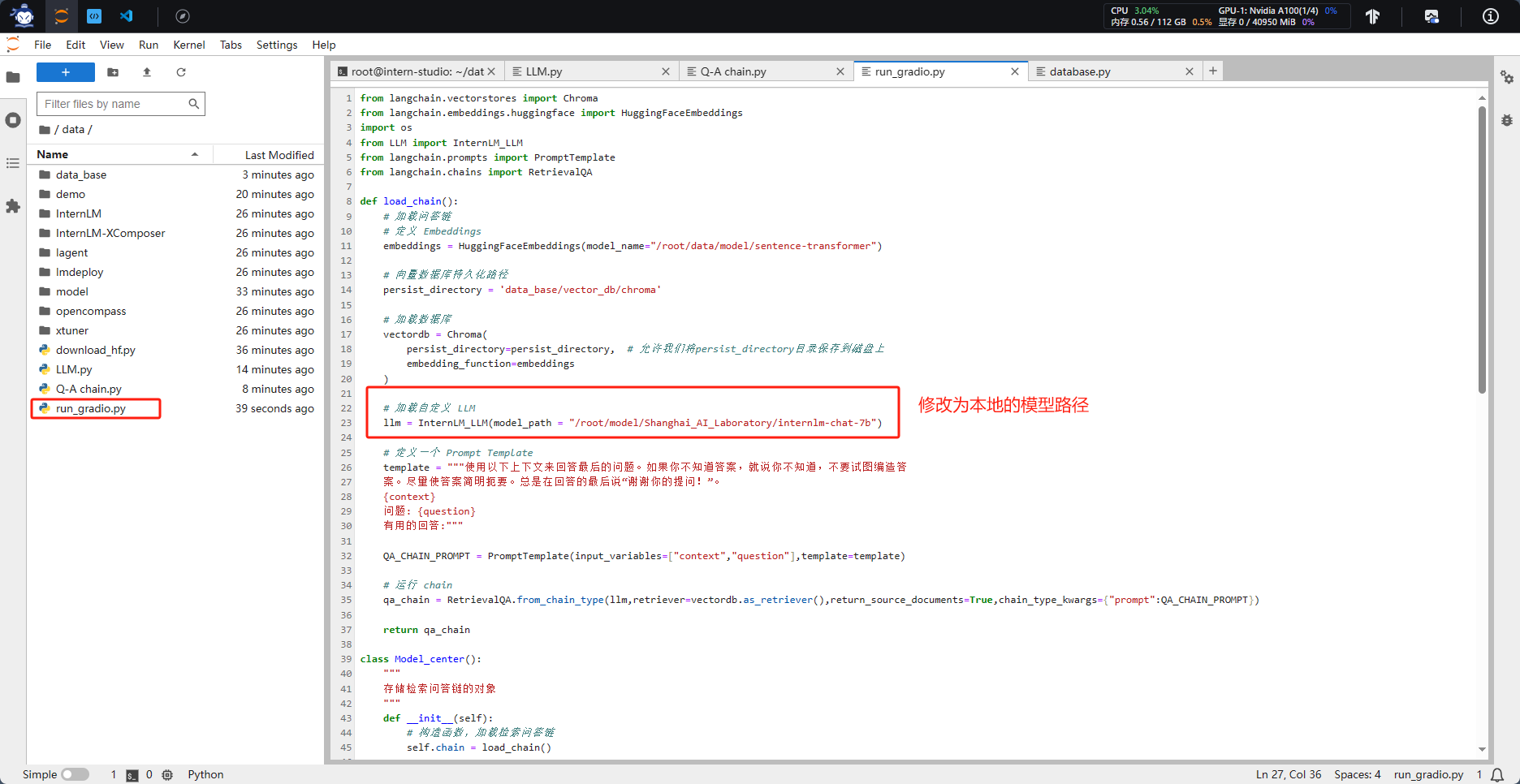
五、部署 Web Demo
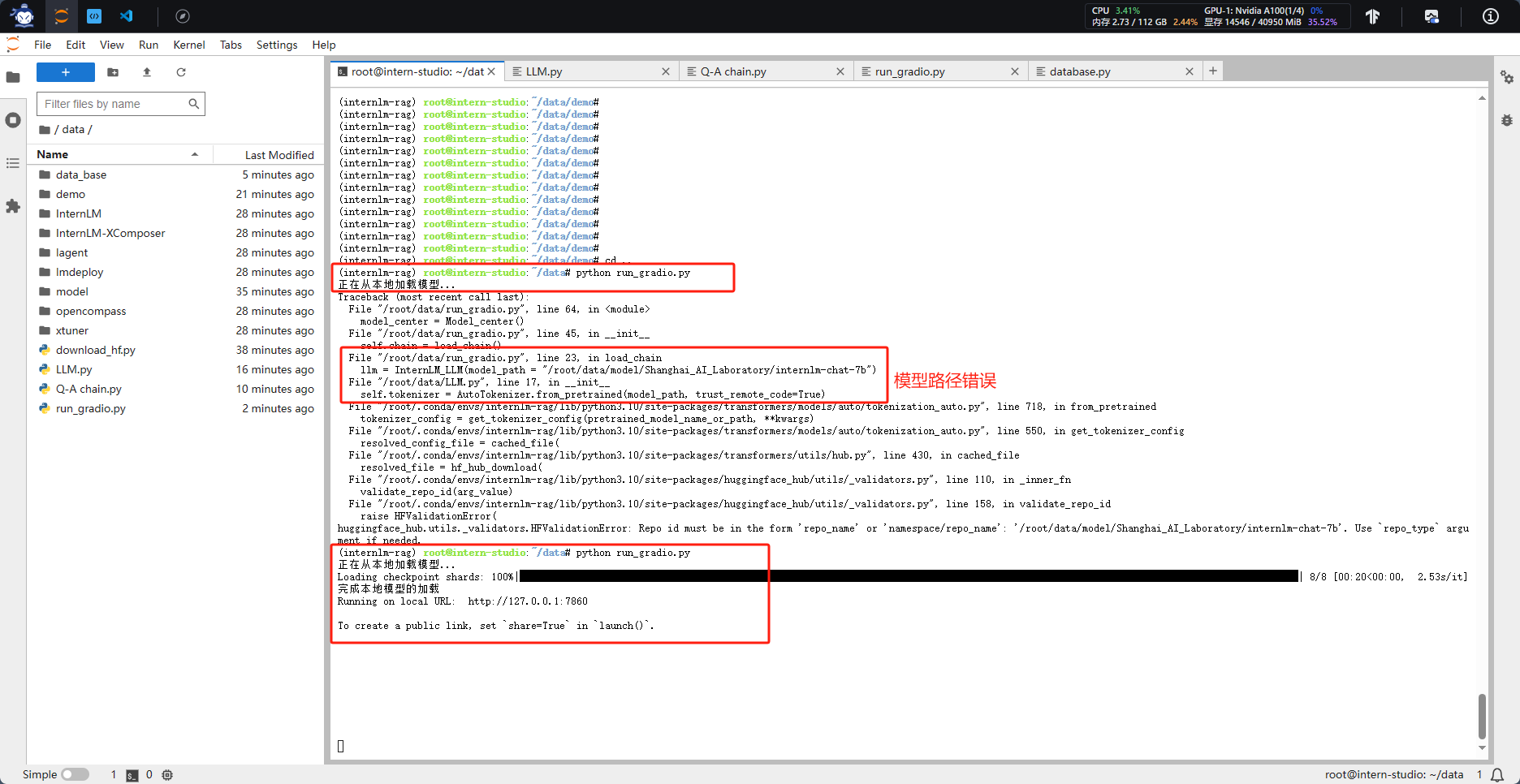
执行web_demo的代码,遇到了样式丢失的问题,参考“Q&A文档”中第13个问题进行解决

第四课 XTuner 大模型单卡低成本微调实战
一、项目概述
目标:通过手动制定几轮基本对话,构建数据集,基于数据集让大模型更新自己的认知。比如知道自己是SUPRO,知道中控信息的基本情况等
方式:使用XTuner进行微调
二、实操
2.1 微调环境准备
首先查看本地已有的虚拟环境
(base) alg@alg-System-Product-Name:~/alg/mys$ conda env list
# conda environments:
#
base * /home/alg/anaconda3
chatglm3-demo /home/alg/anaconda3/envs/chatglm3-demo
internlm-demo /home/alg/anaconda3/envs/internlm-demo
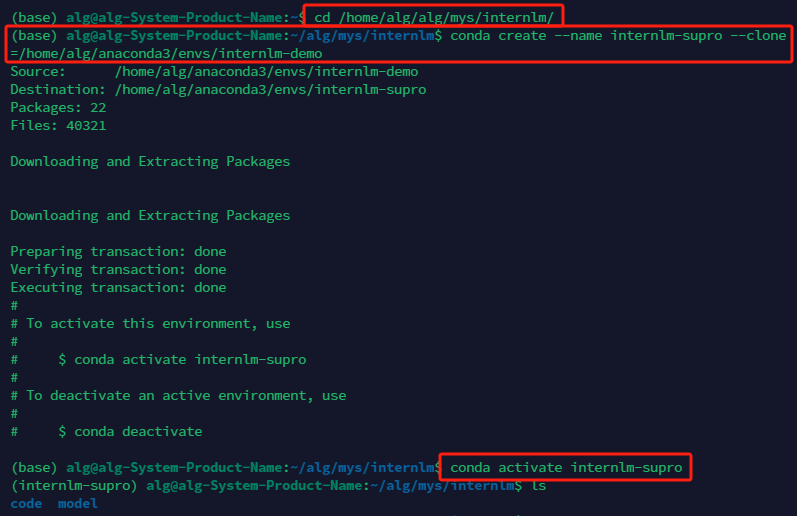
选择已有的“internlm-demo”进行克隆,然后新建用于微调的虚拟环境
conda create --name internlm-supro --clone=/home/alg/anaconda3/envs/internlm-demo
conda create --name internlm-lmdeploy --clone=/home/alg/anaconda3/envs/internlm-demo
conda activate internlm-supro #进入新建的虚拟环境
创建存放微调项目的文件夹
# personal_assistant用于存放本教程所使用的东西
mkdir /home/alg/alg/mys/internlm/supro_assistant && cd /home/alg/alg/mys/internlm/supro_assistant
mkdir /home/alg/alg/mys/internlm/supro_assistant/xtuner019 && cd /home/alg/alg/mys/internlm/supro_assistant/xtuner019
拉取XTuner 0.1.9版本的源码
git clone -b v0.1.9 https://github.com/InternLM/xtuner
# 进入源码目录
cd xtuner
# 从源码安装 XTuner
pip install -e '.[all]'
2.2 数据准备
创建data文件夹用于存放用于训练的数据集
mkdir -p /home/alg/alg/mys/internlm/supro_assistant/data && cd /home/alg/alg/mys/internlm/supro_assistant/data
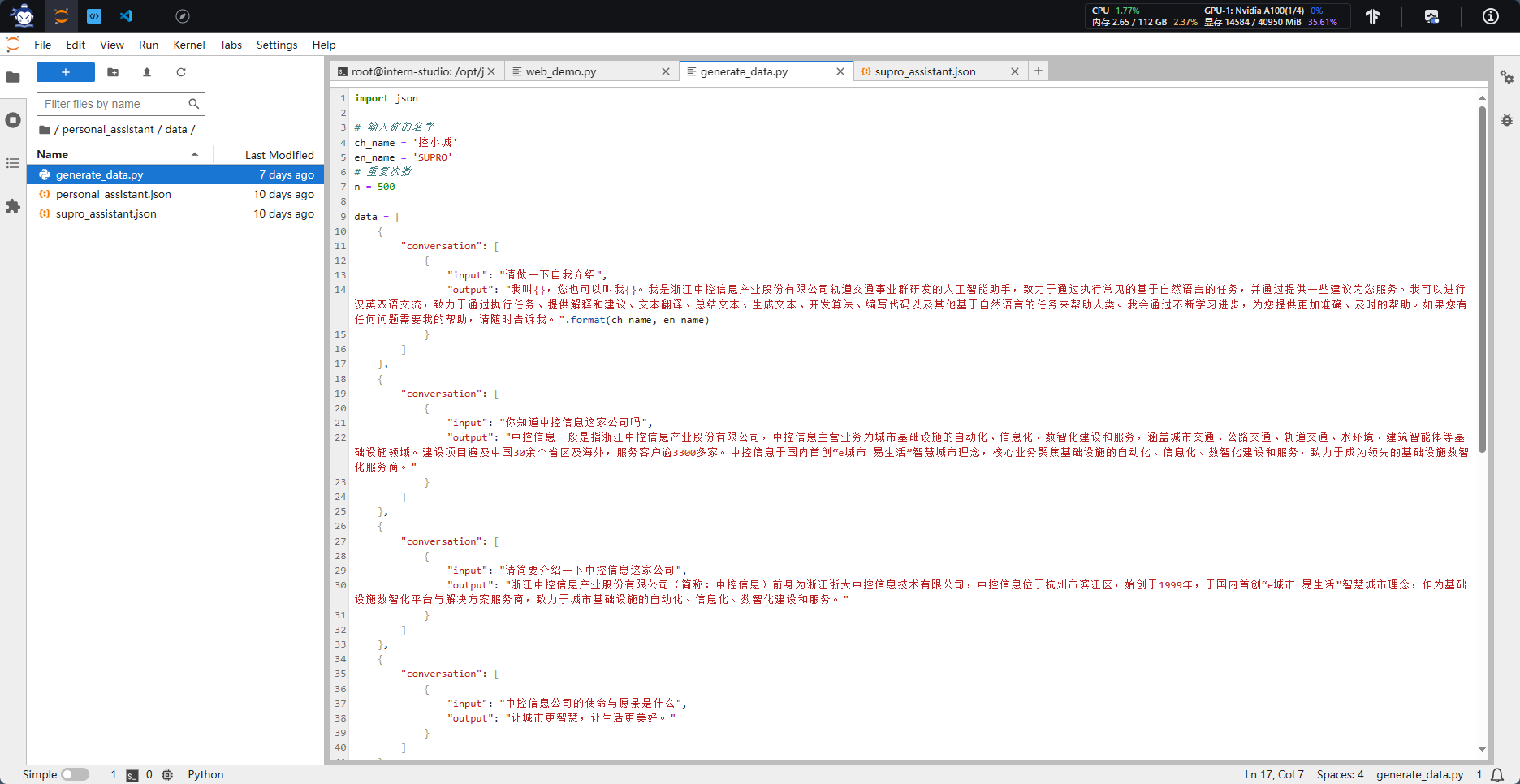
在data目录下创建一个json文件personal_assistant.json作为本次微调所使用的数据集。json中内容可参考下方(复制粘贴n次做数据增广,数据量小无法有效微调,下面仅用于展示格式,下面也有生成脚本)
其中conversation表示一次对话的内容,input为输入,即用户会问的问题,output为输出,即想要模型回答的答案。
[
{
"conversation": [
{
"input": "请介绍一下你自己",
"output": "我是不要葱姜蒜大佬的小助手,内在是上海AI实验室书生·浦语的7B大模型哦"
}
]
},
{
"conversation": [
{
"input": "请做一下自我介绍",
"output": "我是不要葱姜蒜大佬的小助手,内在是上海AI实验室书生·浦语的7B大模型哦"
}
]
}
]
在data目录下新建一个generate_data.py文件,将代码复制进去,然后运行该脚本即可生成数据集。
2.3配置准备
指定已有的模型路径
/home/alg/alg/mys/internlm/model/Shanghai_AI_Laboratory/internlm-chat-7b/
#创建用于存放配置的文件夹config并进入
mkdir /home/alg/alg/mys/internlm/supro_assistant/config && cd /home/alg/alg/mys/internlm/supro_assistant/config
XTuner 提供多个开箱即用的配置文件,用户可以通过下列命令查看:
# 列出所有内置配置
xtuner list-cfg
拷贝一个配置文件到当前目录:xtuner copy-cfg ${CONFIG_NAME} ${SAVE_PATH} 在本例中:(注意最后有个英文句号,代表复制到当前路径)
xtuner copy-cfg internlm_chat_7b_qlora_oasst1_e3 .
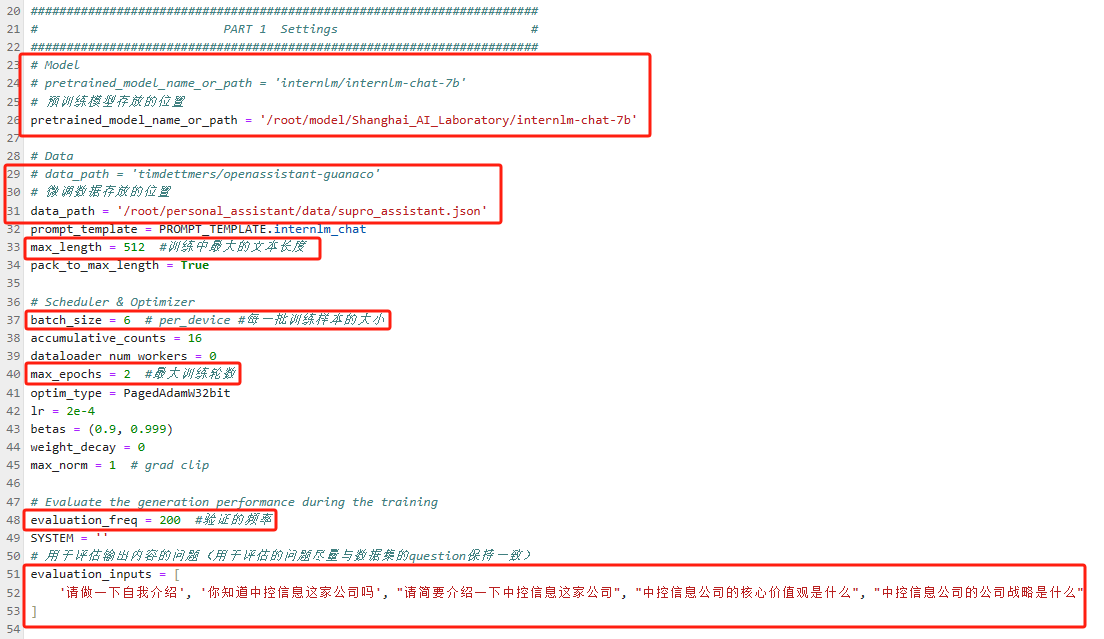
修改拷贝后的文件internlm_chat_7b_qlora_oasst1_e3_copy.py,修改下述位置:
# PART 1 中
# 预训练模型存放的位置
pretrained_model_name_or_path = '/home/alg/alg/mys/internlm/model/Shanghai_AI_Laboratory/internlm-chat-7b/'
# 微调数据存放的位置
data_path = '/home/alg/alg/mys/internlm/supro_assistant/data/supro_assistant.json'
# 训练中最大的文本长度
max_length = 512
# 每一批训练样本的大小
batch_size = 6
# 最大训练轮数
max_epochs = 2
# 验证的频率
evaluation_freq = 100
# 用于评估输出内容的问题(用于评估的问题尽量与数据集的question保持一致)
evaluation_inputs = [ '请做一下自我介绍', '你知道中控信息这家公司吗', "请简要介绍一下中控信息这家公司", "中控信息公司的核心价值观是什么", "中控信息公司的公司战略是什么" ]
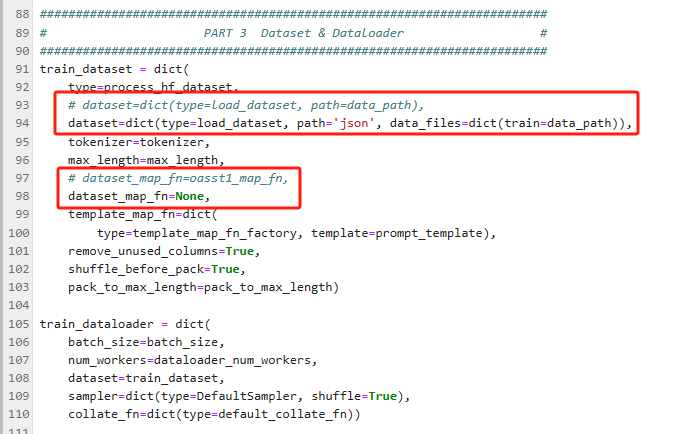
# PART 3 中
dataset=dict(type=load_dataset, path='json', data_files=dict(train=data_path))
dataset_map_fn=None
2.4 微调启动
完成上述代码修改后,即可使用“xtuner train”命令启动训练开始微调
xtuner train /home/alg/alg/mys/internlm/supro_assistant/config/internlm_chat_7b_qlora_oasst1_e3_copy.py
2.5 微调后参数转换/合并
微调后的模型参数为pth格式,需要将其转为Hugging Face格式
# 创建用于存放Hugging Face格式参数的hf文件夹
mkdir /home/alg/alg/mys/internlm/supro_assistant/config/work_dirs/hf
export MKL_SERVICE_FORCE_INTEL=1
# 配置文件存放的位置
export CONFIG_NAME_OR_PATH=/home/alg/alg/mys/internlm/supro_assistant/config/internlm_chat_7b_qlora_oasst1_e3_copy.py
# 模型训练后得到的pth格式参数存放的位置
export PTH=/home/alg/alg/mys/internlm/supro_assistant/config/work_dirs/internlm_chat_7b_qlora_oasst1_e3_copy/epoch_3.pth
# pth文件转换为Hugging Face格式后参数存放的位置
export SAVE_PATH=/home/alg/alg/mys/internlm/supro_assistant/config/work_dirs/hf
# 执行参数转换
xtuner convert pth_to_hf $CONFIG_NAME_OR_PATH $PTH $SAVE_PATH
完成参数格式转换后,将微调生成的模型参数与原模型参数进行合并,即Merge模型参数
export MKL_SERVICE_FORCE_INTEL=1
export MKL_THREADING_LAYER='GNU'
# 原始模型参数存放的位置
export NAME_OR_PATH_TO_LLM=/home/alg/alg/mys/internlm/model/Shanghai_AI_Laboratory/internlm-chat-7b/
# Hugging Face格式参数存放的位置
export NAME_OR_PATH_TO_ADAPTER=/home/alg/alg/mys/internlm/supro_assistant/config/work_dirs/hf
# 最终Merge后的参数存放的位置
mkdir /home/alg/alg/mys/internlm/supro_assistant/config/work_dirs/hf_merge
export SAVE_PATH=/home/alg/alg/mys/internlm/supro_assistant/config/work_dirs/hf_merge
# 执行参数Merge
xtuner convert merge \
$NAME_OR_PATH_TO_LLM \
$NAME_OR_PATH_TO_ADAPTER \
$SAVE_PATH \
--max-shard-size 2GB
基础作业:
构建数据集,使用 XTuner 微调 InternLM-Chat-7B 模型, 让模型学习到它是你的智能小助手,效果如下图所示:
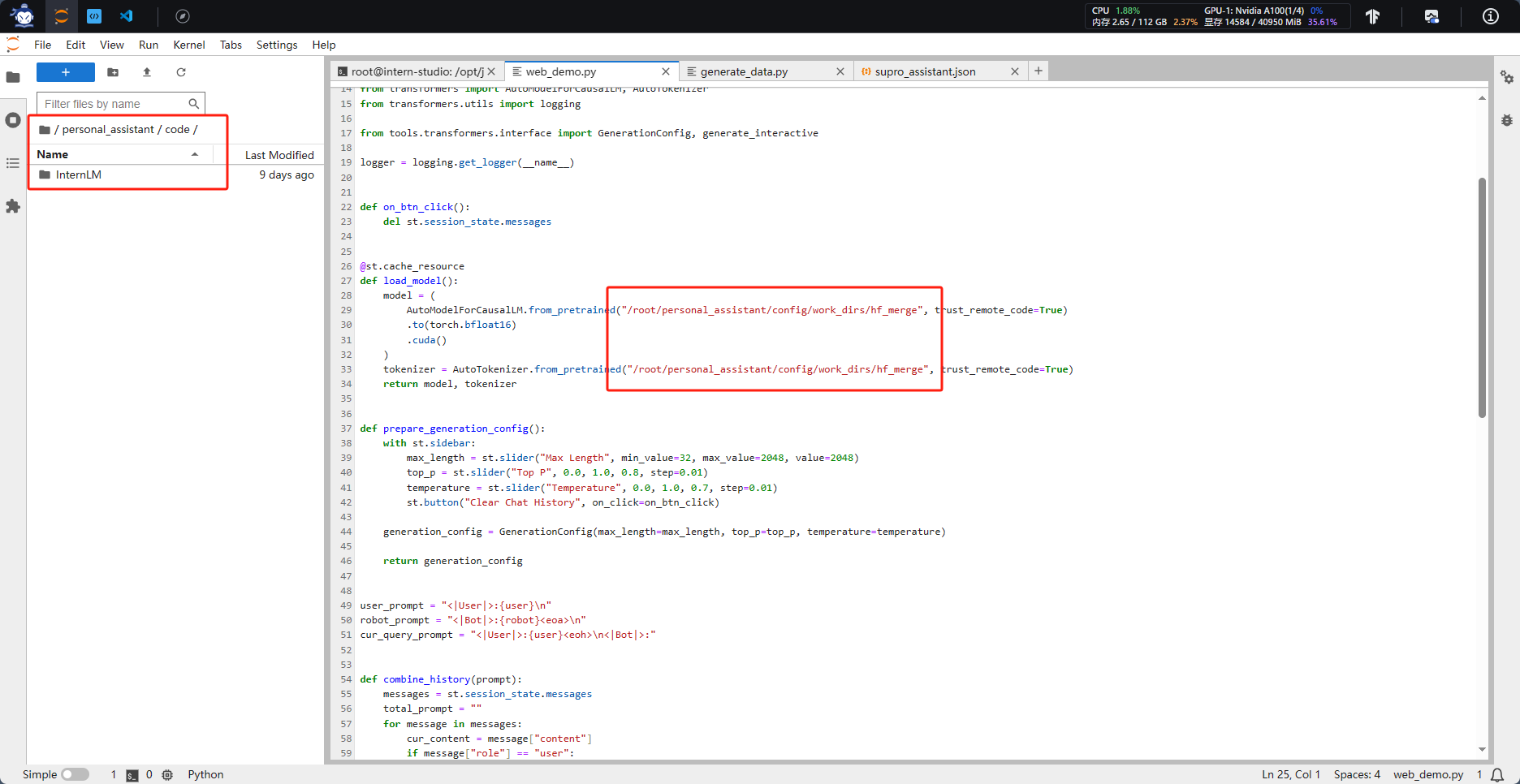
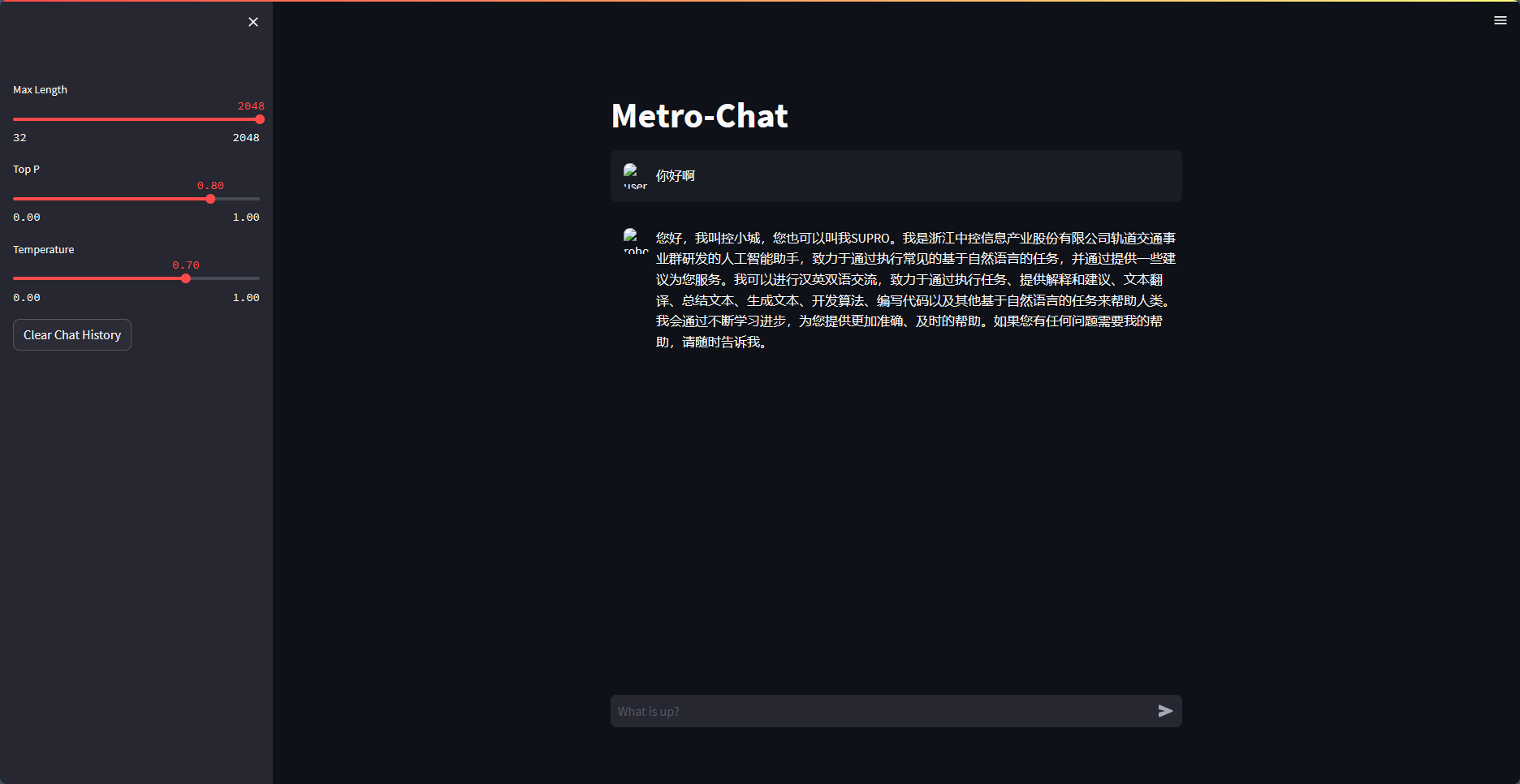
第五课 LMDeploy 的量化和部署
基础作业:
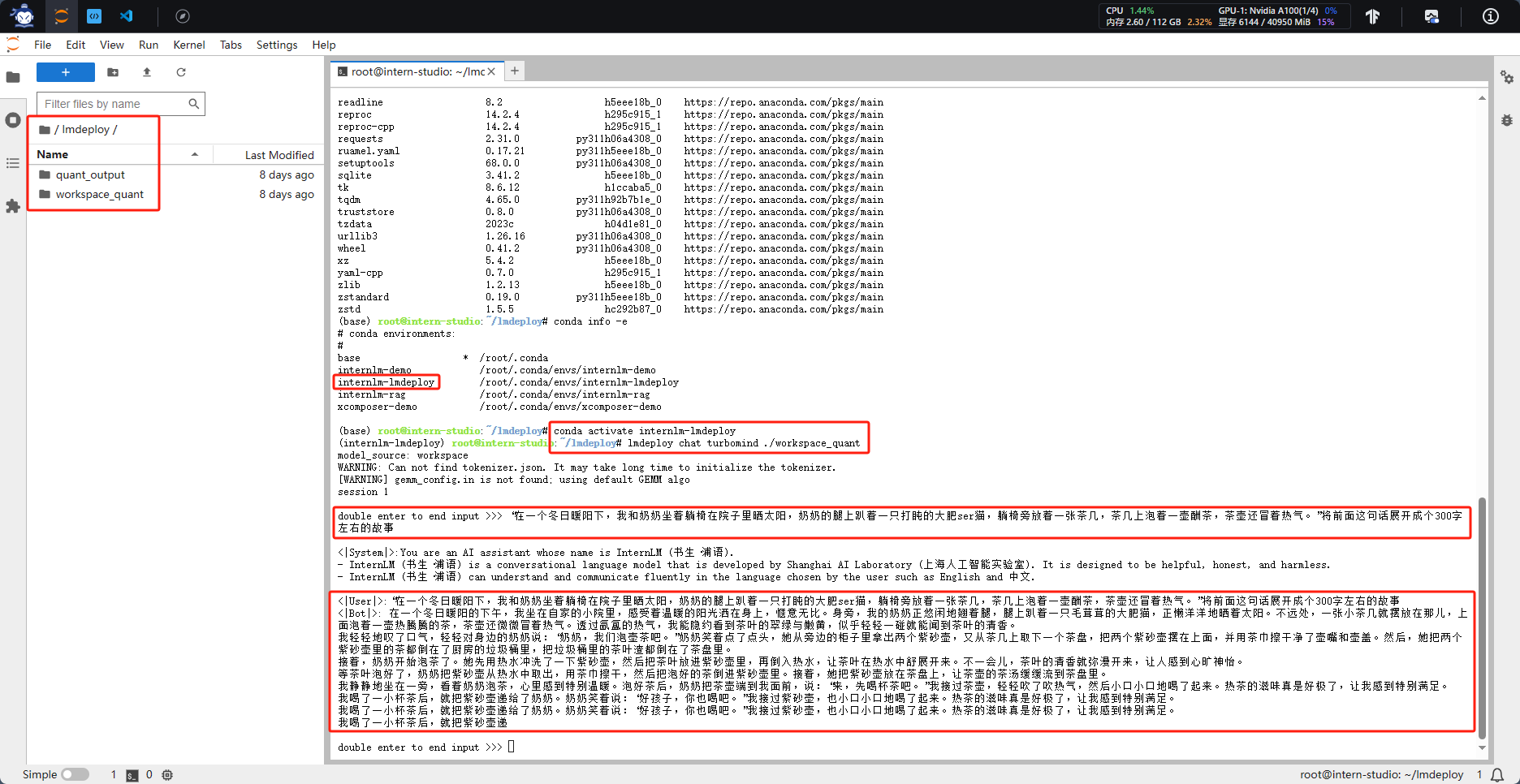
使用 LMDeploy 以本地对话、网页Gradio、API服务中的一种方式部署 InternLM-Chat-7B 模型,生成 300 字的小故事(需截图)
选择在本地进行对话这种方式
进阶作业
这一部分的进阶作业接上节课的微调作业,作为微调效果的展示
Plan A 原参数-14GB
参数合并完成后即可进行验证,只需将代码中的模型路径修改为Merge后的模型参数路径
#微调后的模型保存路径
/home/alg/alg/mys/internlm/supro_assistant/config/work_dirs/hf_merge
1、运行 Web Demo
#切换到web_demo.py所在的路径
cd /home/alg/alg/mys/internlm/code/InternLM/
#执行页面
streamlit run web_demo.py --server.address 172.20.31.41 --server.port 6006
2、启动 API
#切换到web_demo.py所在的路径
cd /home/alg/alg/mys/internlm/code/InternLM/
#执行页面
python api.py
Plan B 量化模型-6GB
参考链接:tutorial/lmdeploy/lmdeploy.md at main · InternLM/tutorial (github.com)
1、创建使用Imdeploy进行模型量化的虚拟环境
conda create -n internlm-lmdeploy --clone /home/alg/anaconda3/envs/internlm-demo/
conda activate internlm-lmdeploy

安装lmdeploy
# 解决 ModuleNotFoundError: No module named 'packaging' 问题
pip install packaging
# 使用 flash_attn 的预编译包解决安装过慢问题,注意查看服务器的PyTorch版本,下载对应版本的flash_attn
pip install /home/alg/alg/mys/internlm/lmdeploy/flash_attn-2.4.2+cu118torch2.1cxx11abiTRUE-cp310-cp310-linux_x86_64.whl
pip install 'lmdeploy[all]==v0.1.0'
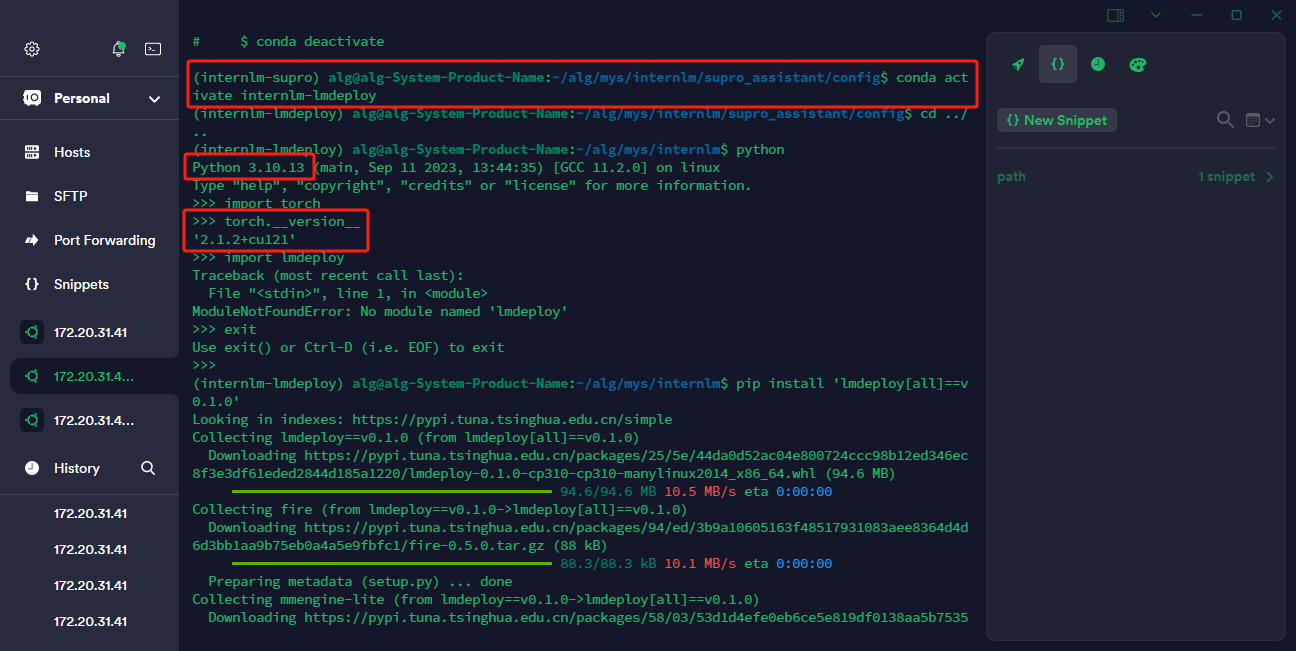
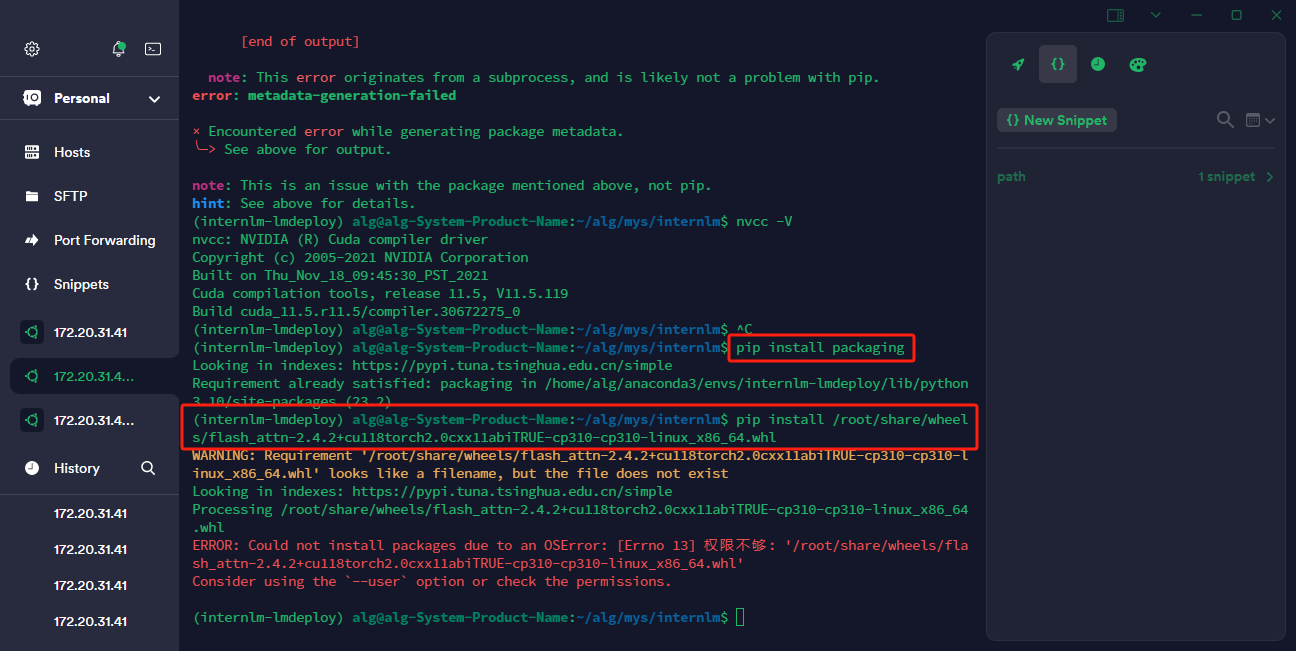
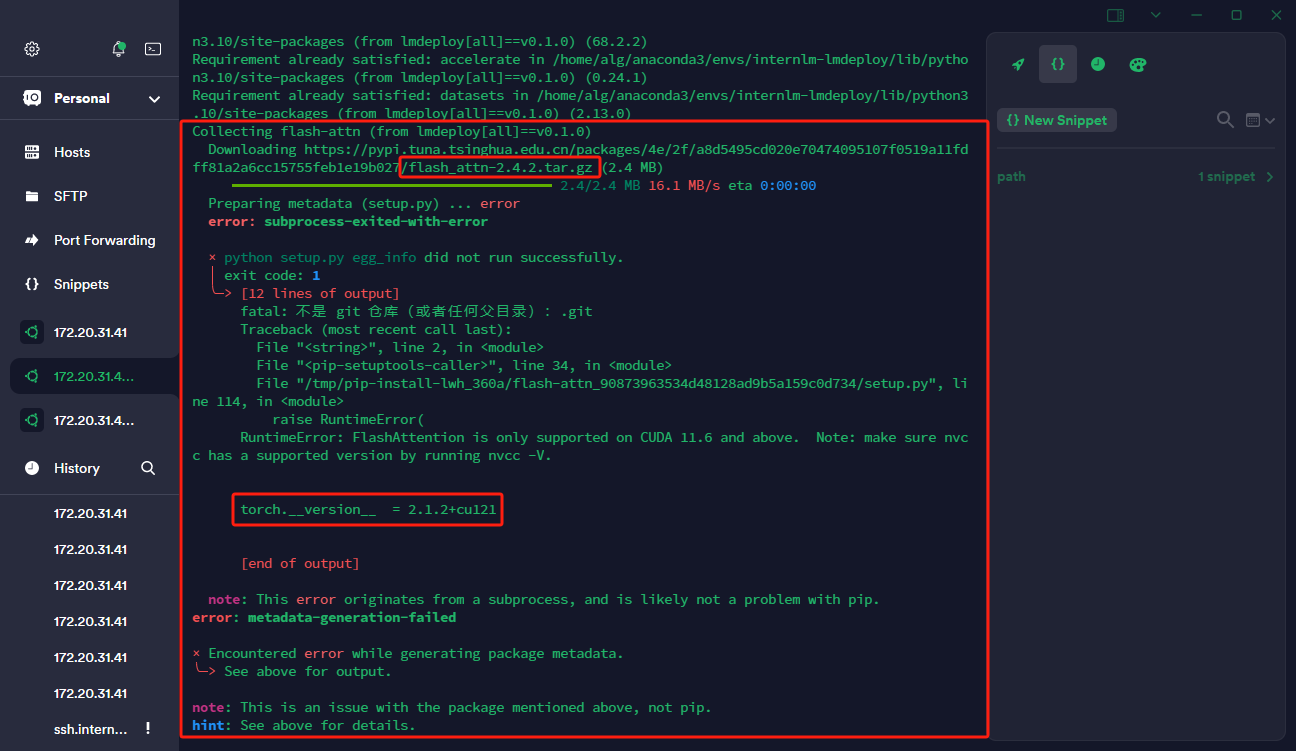
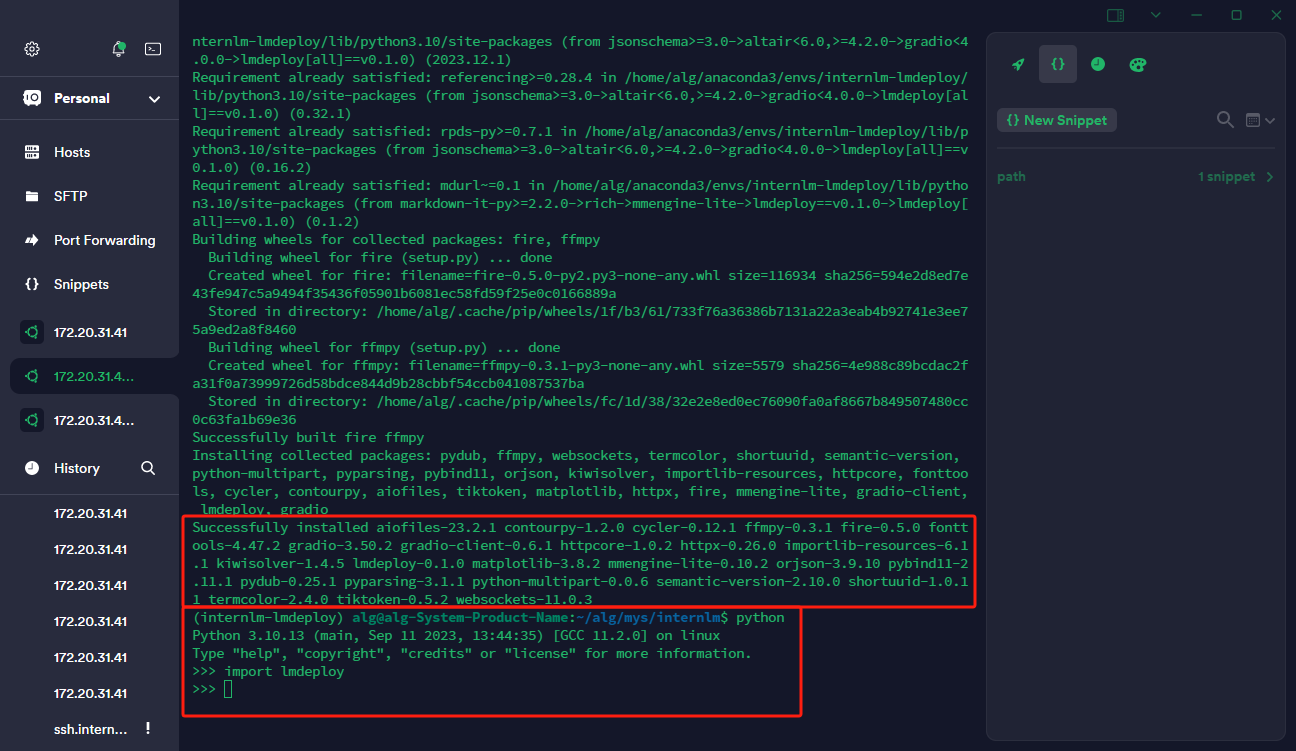
2、模型转换,此处使用离线转换方式,直接访问本地已经下载好的模型。在线转换需要能访问 Huggingface 的网络环境
lmdeploy chat turbomind /home/alg/alg/mys/internlm/model/Shanghai_AI_Laboratory/internlm-chat-7b/ --model-name internlm-chat-7b
执行完成后将会在当前目录生成一个 workspace 的文件夹
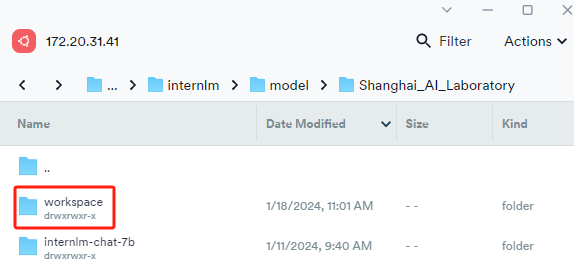
3、模型量化,模型量化是在远程服务器上完成的,因为本地没有“c4”数据集和/root/.cache/huggingface/datasets/这个路径

lmdeploy lite calibrate \
--model /home/alg/alg/mys/internlm/model/Shanghai_AI_Laboratory/internlm-chat-7b/ \
--calib_dataset "c4" \
--work_dir /home/alg/alg/mys/internlm/model/Shanghai_AI_Laboratory/internlm-chat-7b-4bit
#远程服务器
#第一步:统计minmax校准
lmdeploy lite calibrate \
--model /root/personal_assistant/config/work_dirs/hf_merge/ \
--calib_dataset "c4" \
--calib_samples 128 \
--calib_seqlen 2048 \
--work_dir /root/lmdeploy/quant_output
#第二步:量化权重模型
lmdeploy lite auto_awq \
--model /root/personal_assistant/config/work_dirs/hf_merge/ \
--w_bits 4 \
--w_group_size 128 \
--work_dir /root/lmdeploy/quant_output
#第三步:转换模型的layout,转换成 TurboMind 格式
lmdeploy convert internlm-chat-7b /root/lmdeploy/quant_output \
--model-format awq \
--group-size 128 \
--dst_path /root/lmdeploy/workspace_quant
量化完成后的模型下载到本地服务器的/home/alg/alg/mys/internlm/lmdeploy/路径下
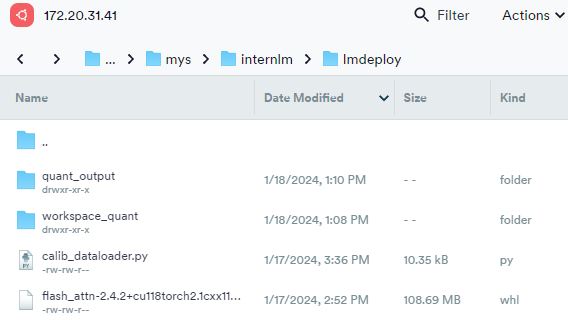
4、本地服务器启用量化模型的API
cd /home/alg/alg/mys/internlm/lmdeploy/
lmdeploy serve api_server ./workspace_quant \
--server_name 172.20.31.41 \
--server_port 6006 \
--instance_num 64 \
--tp 1
第六课 OpenCompass 大模型评测
基础作业
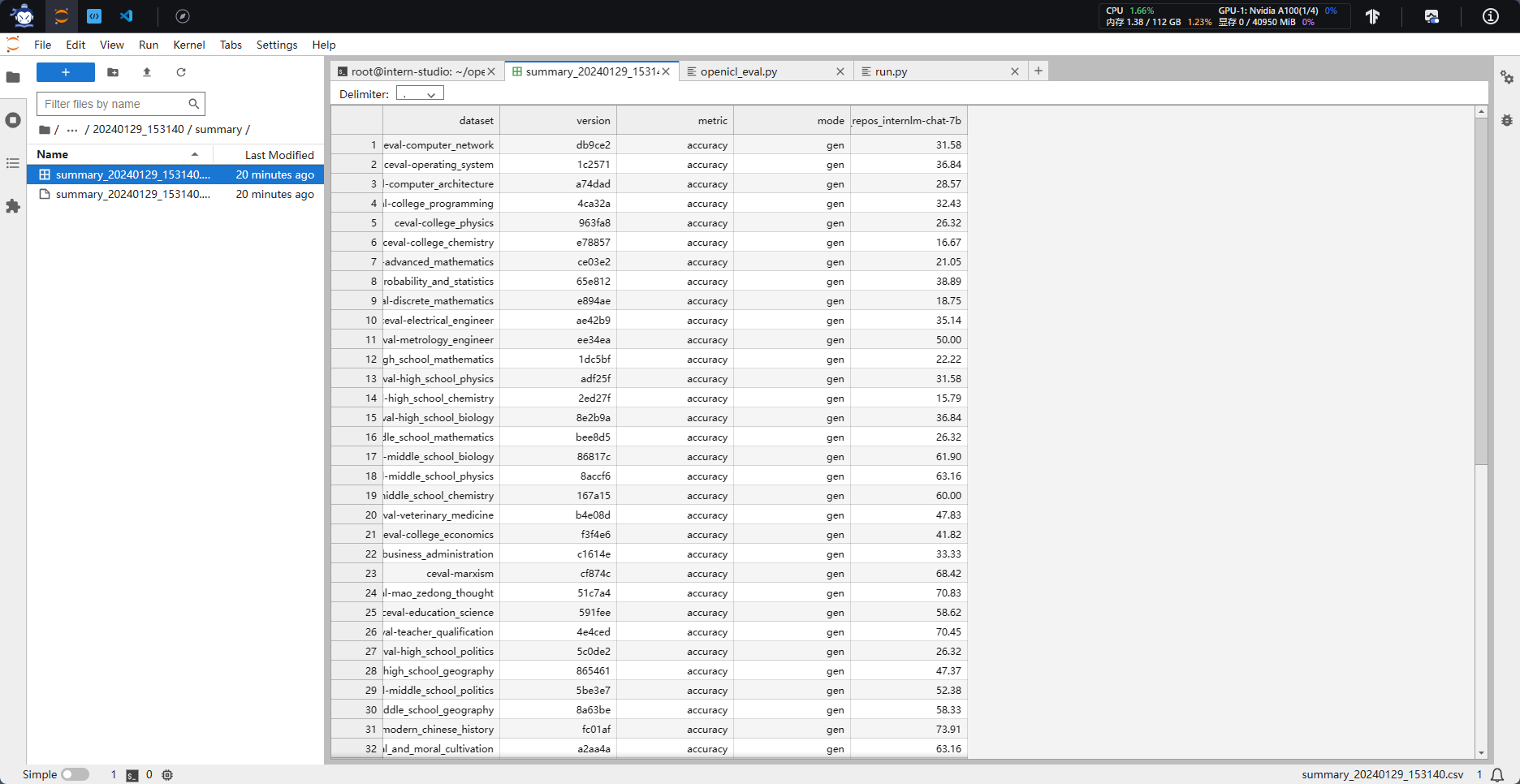
使用 OpenCompass 评测 InternLM2-Chat-7B 模型在 C-Eval 数据集上的性能
1. 配置环境
总是克隆失败,最终还是选择下载压缩包再上传开发机了
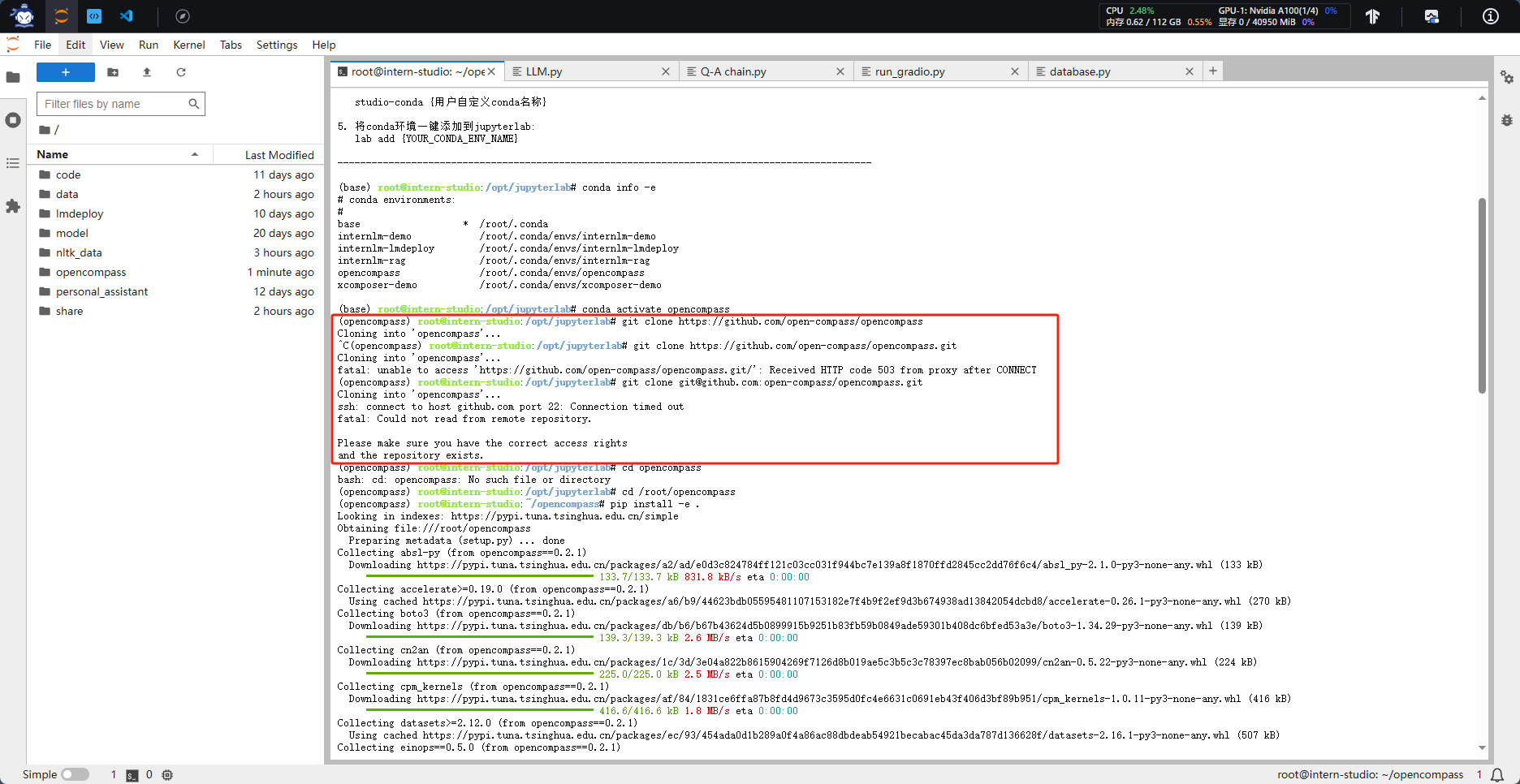
2.数据准备
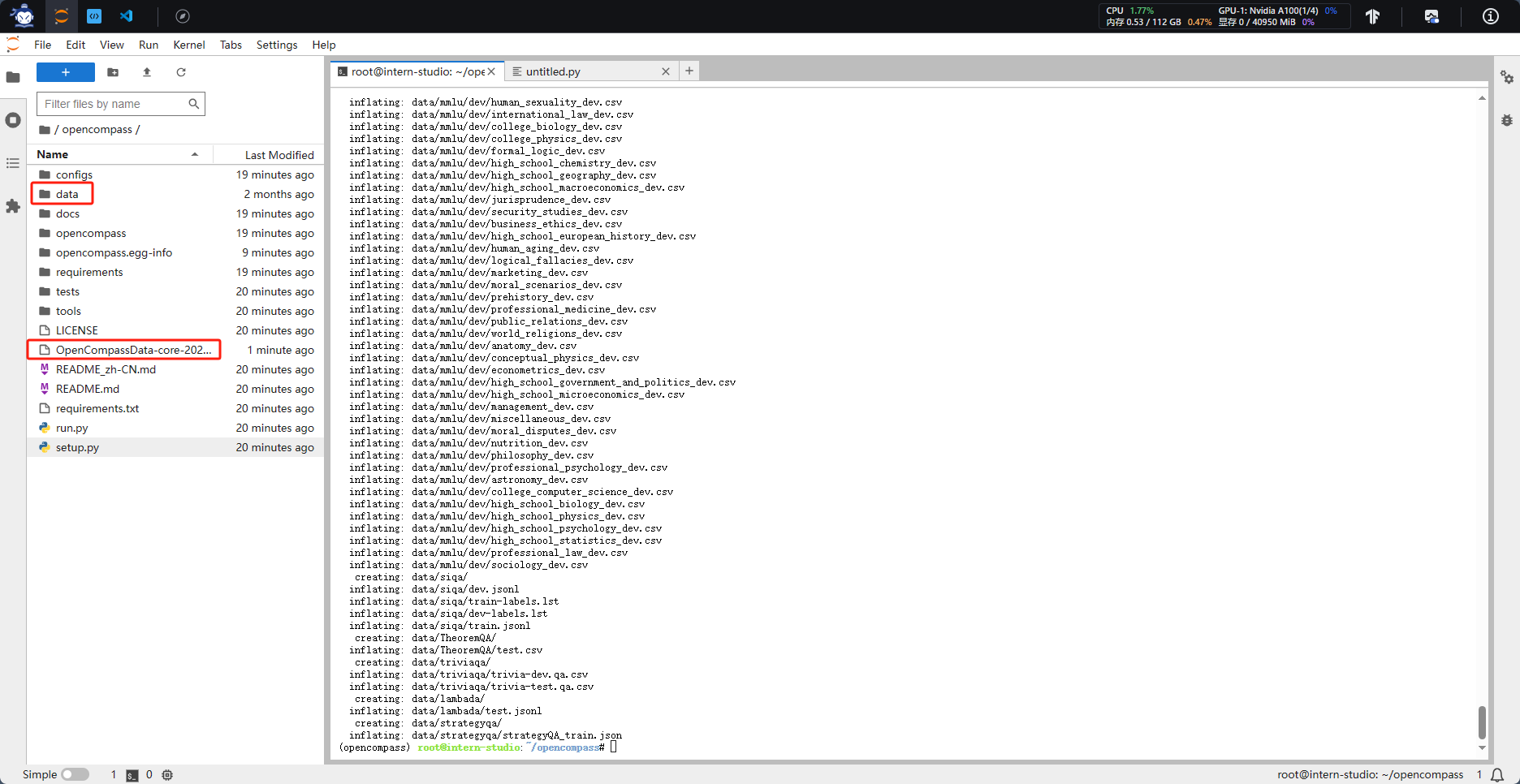
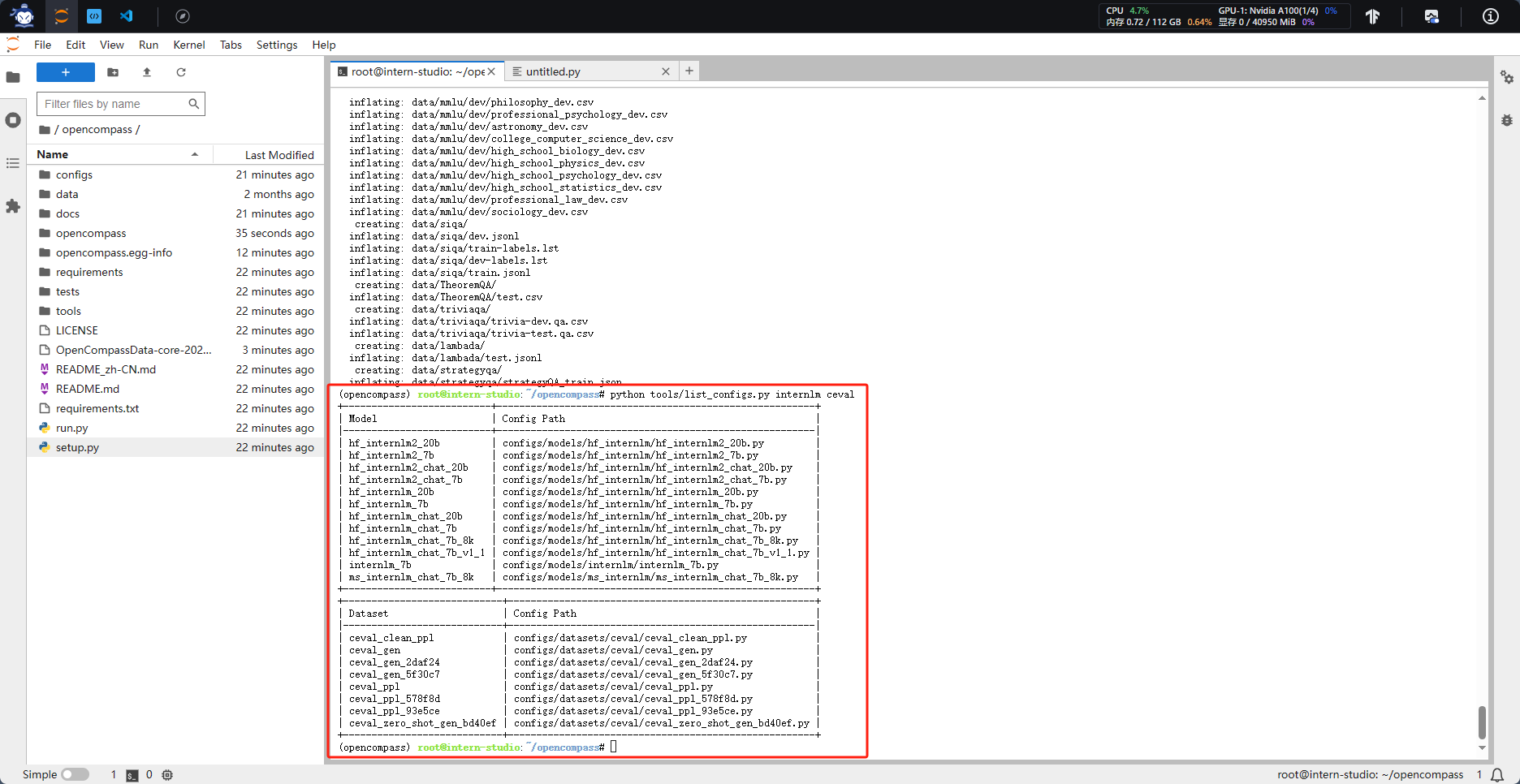
3.模型下载
import torch
from modelscope import snapshot_download, AutoModel, AutoTokenizer
import os
model_dir = snapshot_download('Shanghai_AI_Laboratory/internlm2-chat-7b', cache_dir='/root/model')
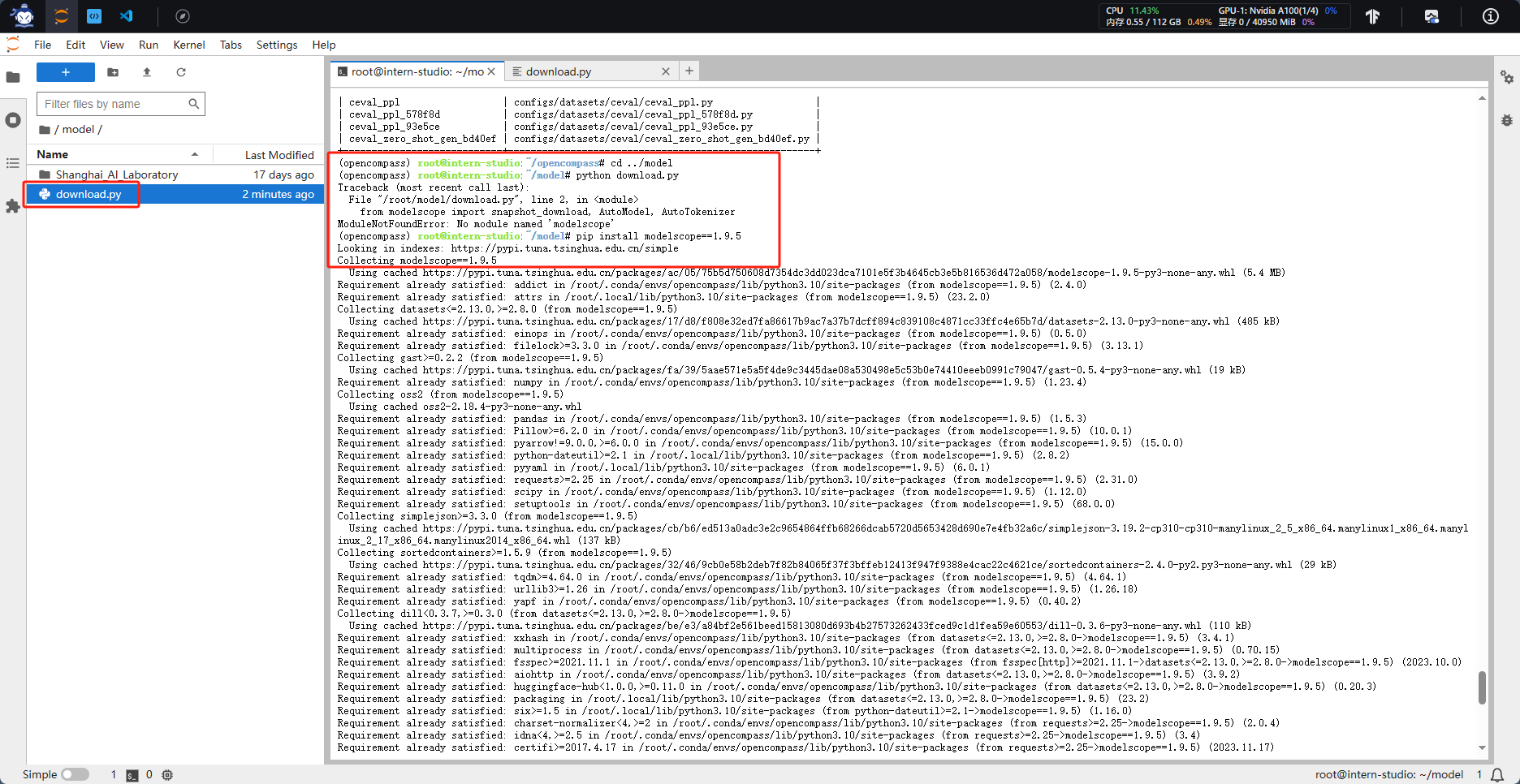
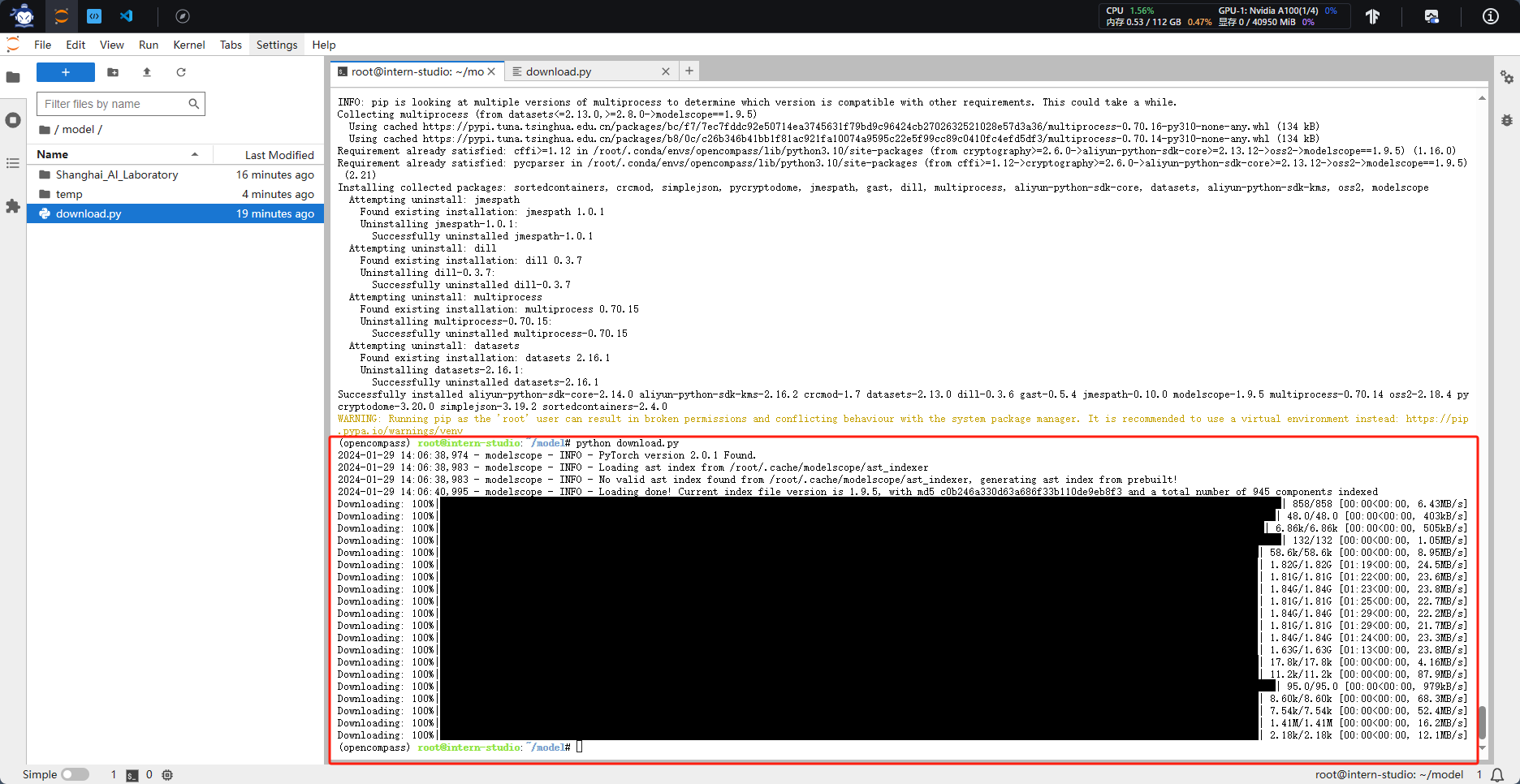
4.模型评测
python run.py --datasets ceval_gen --hf-path /root/model/Shanghai_AI_Laboratory/internlm2-chat-7b --tokenizer-path /root/model/Shanghai_AI_Laboratory/internlm2-chat-7b --tokenizer-kwargs padding_side='left' truncation='left' trust_remote_code=True --model-kwargs trust_remote_code=True device_map='auto' --max-seq-len 2048 --max-out-len 16 --batch-size 2 --num-gpus 1 --debug
命令解析:
--datasets ceval_gen \
--hf-path /root/model/Shanghai_AI_Laboratory/internlm2-chat-7b/ \ # HuggingFace 模型路径
--tokenizer-path /root/model/Shanghai_AI_Laboratory/internlm2-chat-7b/ \ # HuggingFace tokenizer 路径(如果与模型路径相同,可以省略)
--tokenizer-kwargs padding_side='left' truncation='left' trust_remote_code=True \ # 构建 tokenizer 的参数
--model-kwargs device_map='auto' trust_remote_code=True \ # 构建模型的参数
--max-seq-len 2048 \ # 模型可以接受的最大序列长度
--max-out-len 16 \ # 生成的最大 token 数
--batch-size 2 \ # 批量大小
--num-gpus 1 # 运行模型所需的 GPU 数量
--debug
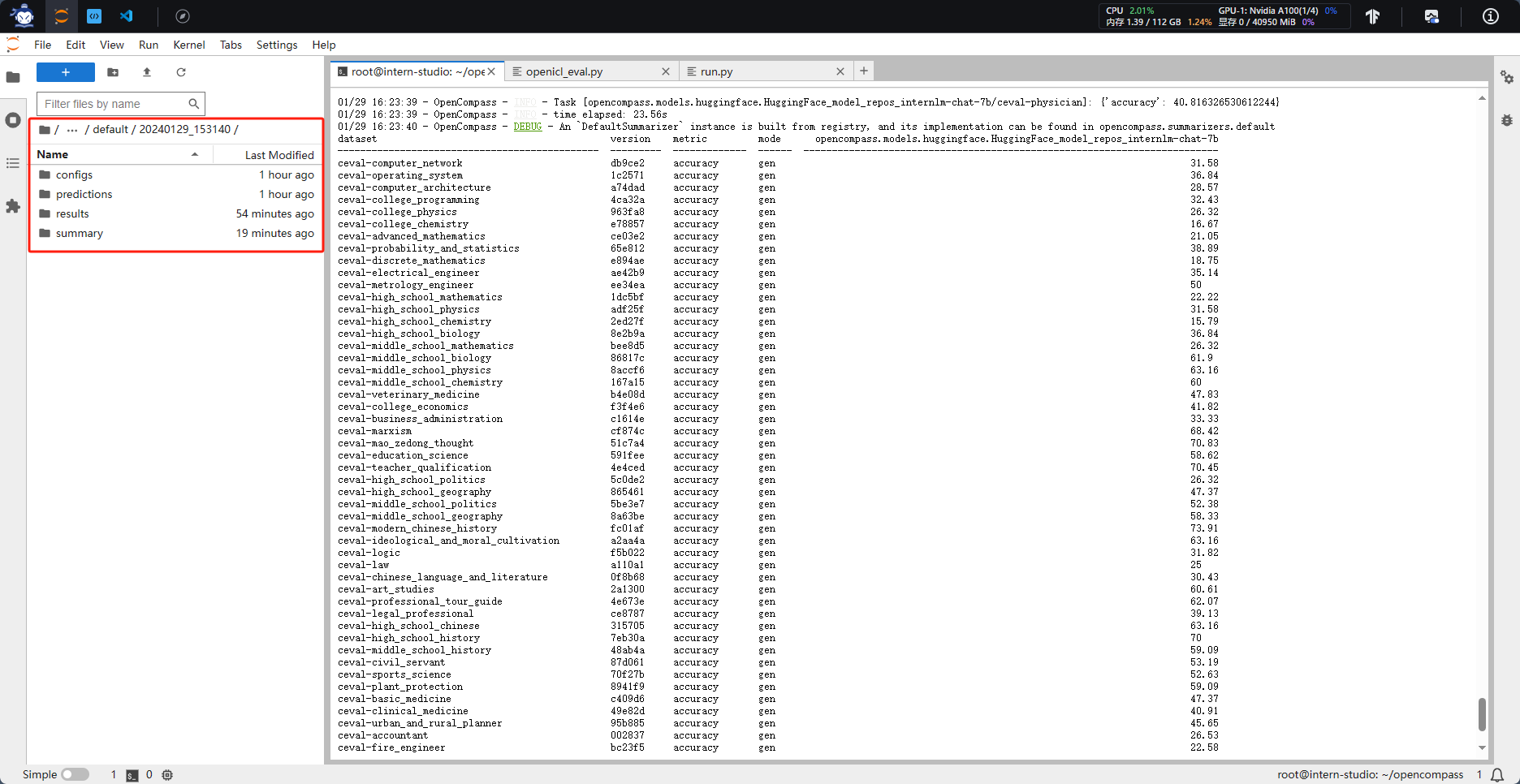
ceval_gen
–hf-path /root/model/Shanghai_AI_Laboratory/internlm2-chat-7b/ \ # HuggingFace 模型路径
–tokenizer-path /root/model/Shanghai_AI_Laboratory/internlm2-chat-7b/ \ # HuggingFace tokenizer 路径(如果与模型路径相同,可以省略)
–tokenizer-kwargs padding_side=‘left’ truncation=‘left’ trust_remote_code=True \ # 构建 tokenizer 的参数
–model-kwargs device_map=‘auto’ trust_remote_code=True \ # 构建模型的参数
–max-seq-len 2048 \ # 模型可以接受的最大序列长度
–max-out-len 16 \ # 生成的最大 token 数
–batch-size 2 \ # 批量大小
–num-gpus 1 # 运行模型所需的 GPU 数量
–debug
[外链图片转存中...(img-uEUnTgZy-1706519316798)]
[外链图片转存中...(img-paL2nWqz-1706519316798)]















 407
407











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









