







首先来看公式:
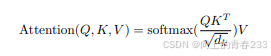
这是论文Attention Is All You Need中用于计算注意力机制的公式。
有聪明的观众可能要问了,为什么要除以dk?这也是大模型面试中常问的内容。
实际上,当计算的向量比较大的时候,结果值之间的差距同样会变大,值大的softmax函数结果更加靠近1,而其他结果更加靠近0。这样做可以防止梯度消失,
因此,为了保持稳定性并减小点积的幅度,通常将点积结果除以 dk,这样做可以避免softmax饱和以及稳定梯度。
你学到了吗?
首先来看公式:
这是论文Attention Is All You Need中用于计算注意力机制的公式。
有聪明的观众可能要问了,为什么要除以dk?这也是大模型面试中常问的内容。
实际上,当计算的向量比较大的时候,结果值之间的差距同样会变大,值大的softmax函数结果更加靠近1,而其他结果更加靠近0。这样做可以防止梯度消失,
因此,为了保持稳定性并减小点积的幅度,通常将点积结果除以 dk,这样做可以避免softmax饱和以及稳定梯度。
你学到了吗?

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


























