







【SQL】之索引
索引是帮助mysql高效获取数据的数据结构
简单的索引设计方式
新建一个表:
mysql> CREATE TABLE index_demo(
-> c1 INT,
-> c2 INT,
-> c3 CHAR(1),
-> PRIMARY KEY(c1)
-> ) ROW_FORMAT = Compact;
存储一条记录的示意图:
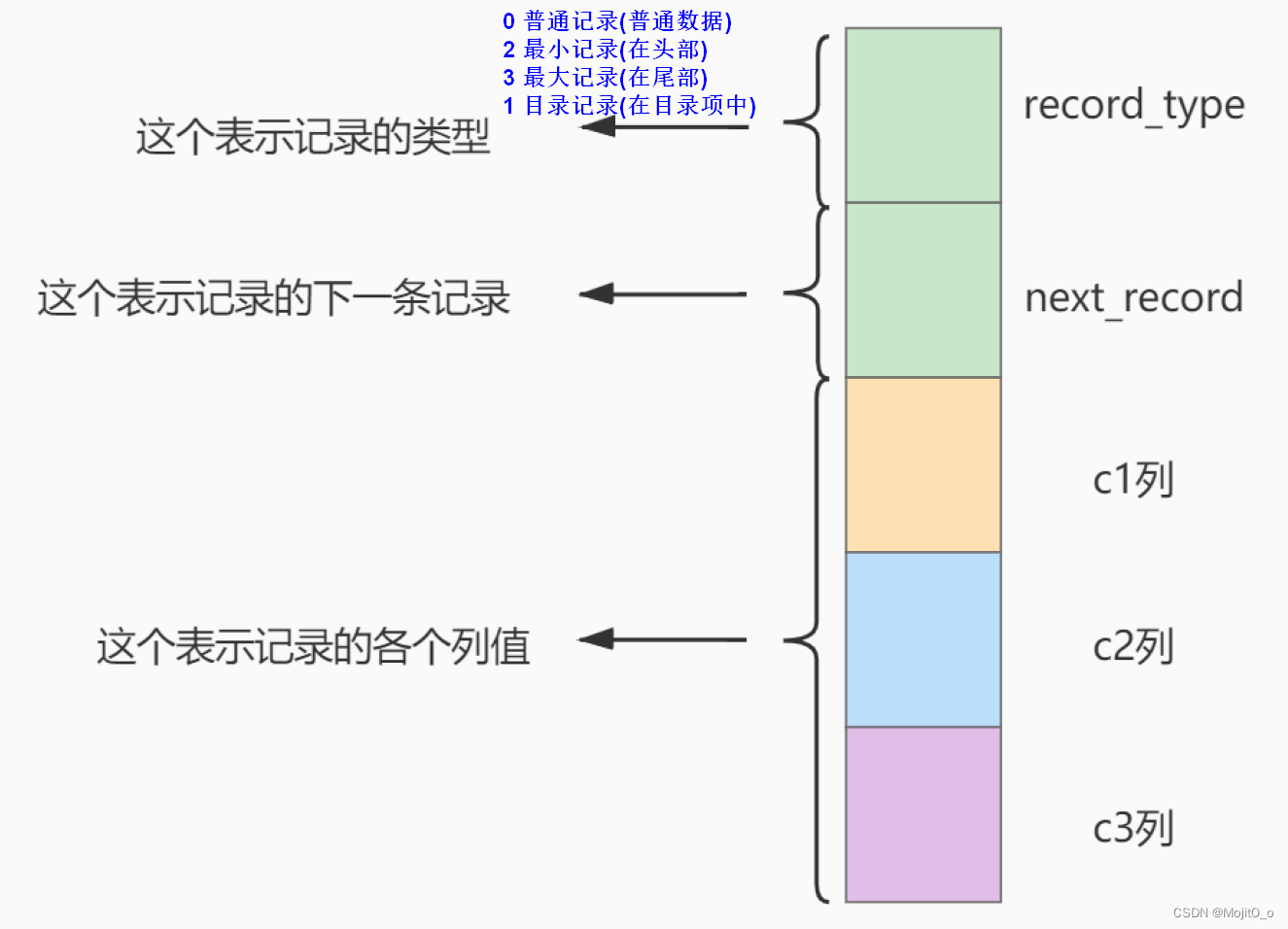
放到页中:
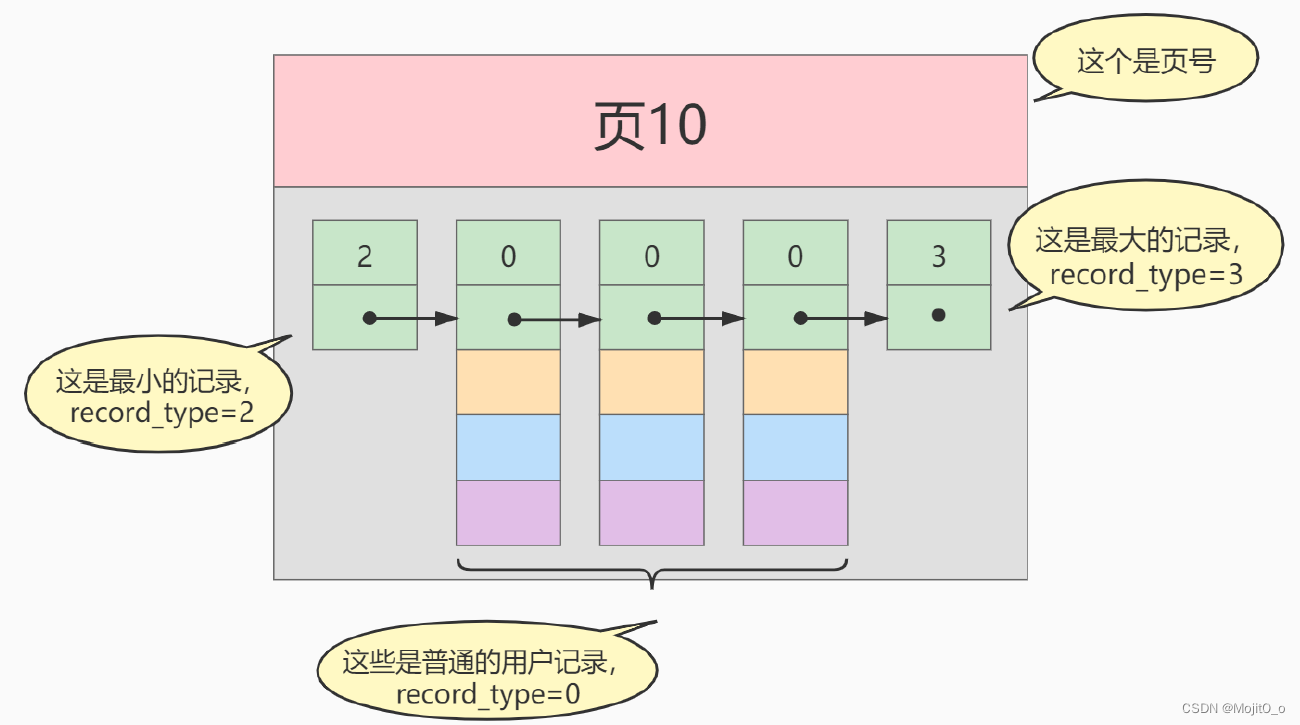
若有多个数据,则建立目录项:
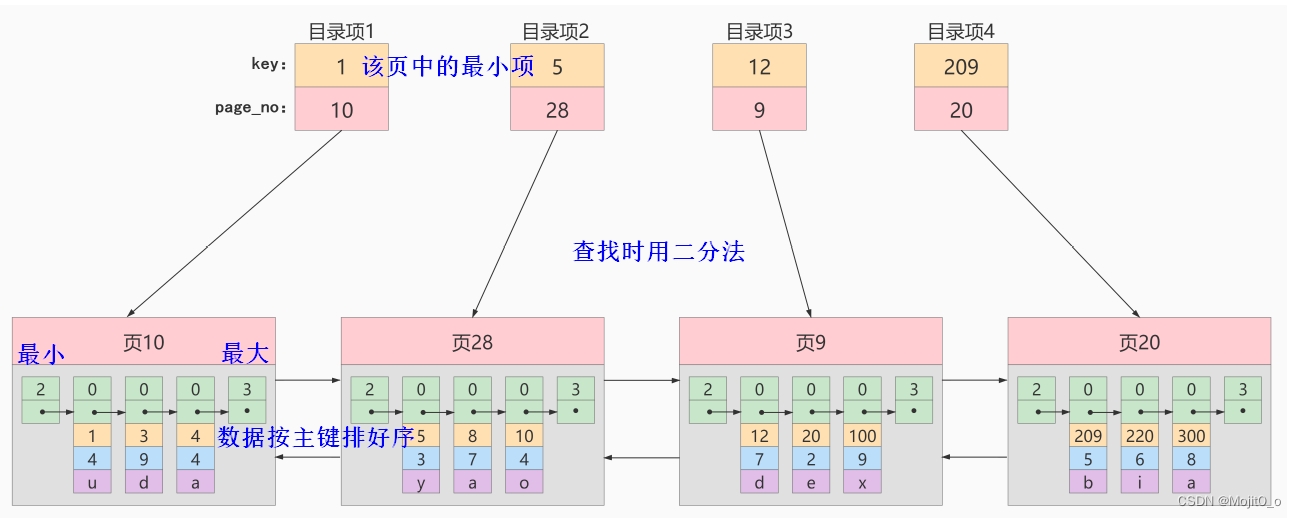
innodb中的索引设计方式
迭代一次
迭代两次
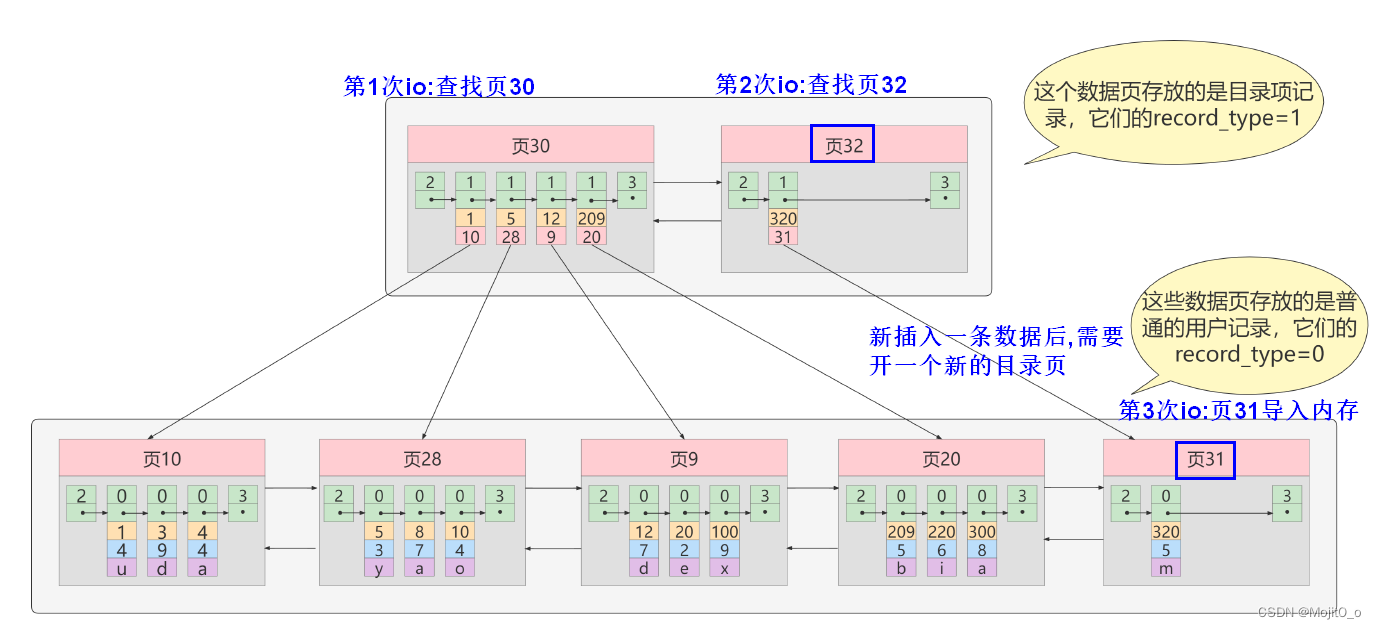
迭代三次
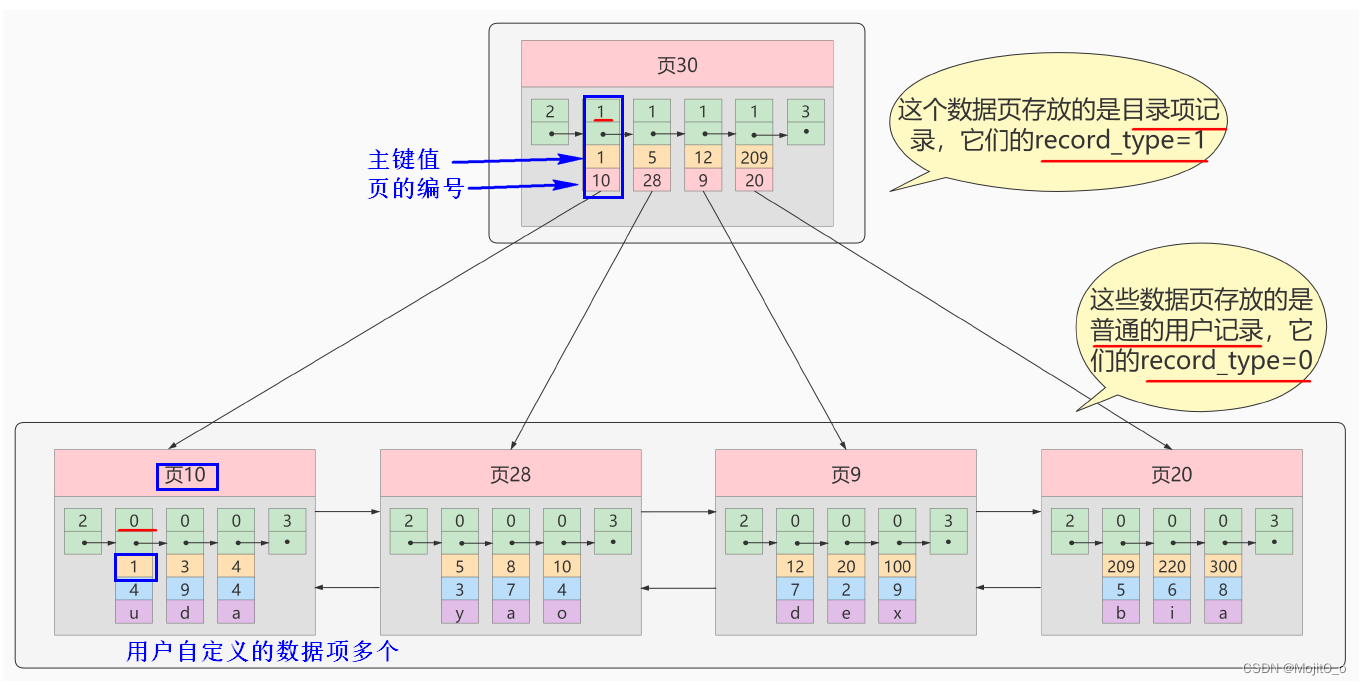
将目录项再生成目录,可减少io次数
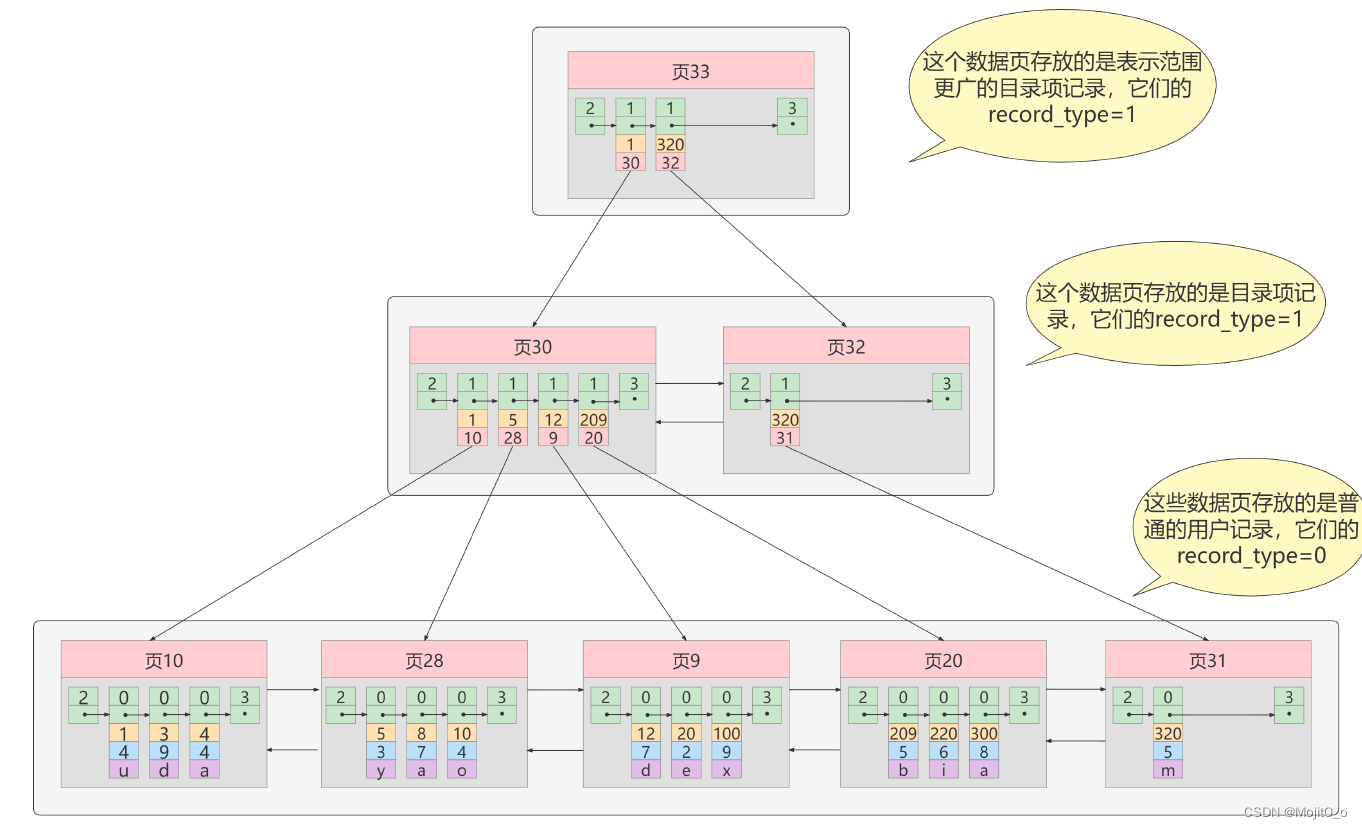
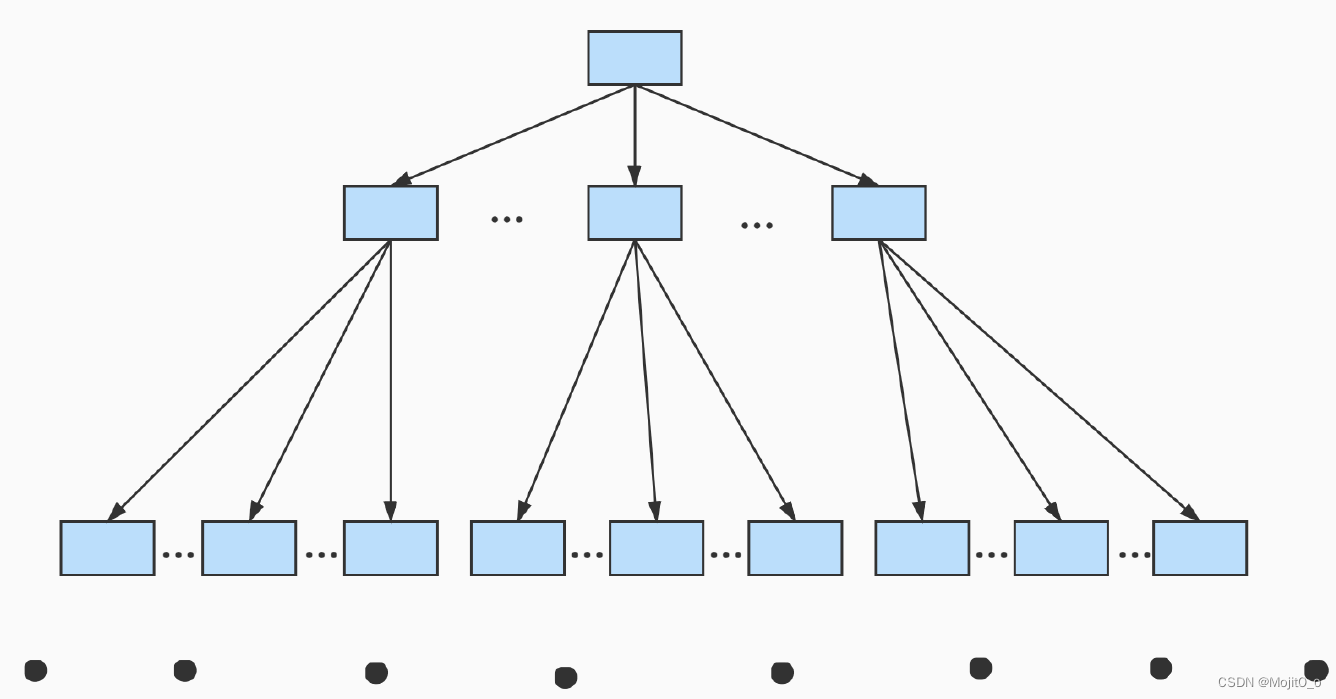
b+tree
b+树一般不超过四层(树的层次越低,io次数越少)
聚簇索引
聚簇索引是一种数据存储方式,innodb中,数据即索引,索引即数据。
页内:按主键大小排序形成单链表
页间:双向链表
使用innodb,在添加数据的过程中,底层的b+树就已经创建起来了,不需要在添加完数据后再创建index。
优点
- 数据访问更快,因为聚簇索引将索引和数据保存在同一个B+树中,因此从聚簇索引中获取数据比非聚簇索引更快
- 聚簇索引对于主键的排序查找和范围查找速度非常快
- 按照聚簇索引排列顺序,查询显示一定范围数据的时候,由于数据都是紧密相连,数据库不用从多个数据块中提取数据,所以节省了大量的io操作。
缺点
- 插入速度严重依赖于插入顺序,按照主键的顺序插入是最快的方式,否则将会出现页分裂,严重影响性能。因此,对于InnoDB表,我们一般都会定义一个自增的ID列为主键
- 更新主键的代价很高,因为将会导致被更新的行移动。因此,对于InnoDB表,我们一般定义主键为不可更新
- 二级索引访问需要两次索引查找,第一次找到主键值,第二次根据主键值找到行数据
二级索引(非聚簇)
使用主键进行查找,可以使用聚簇索引,若使用非主键查找,需要借助二级索引。
每个表中只能有一个聚簇索引,但可以有多个二级索引。
由c2字段构建的索引:
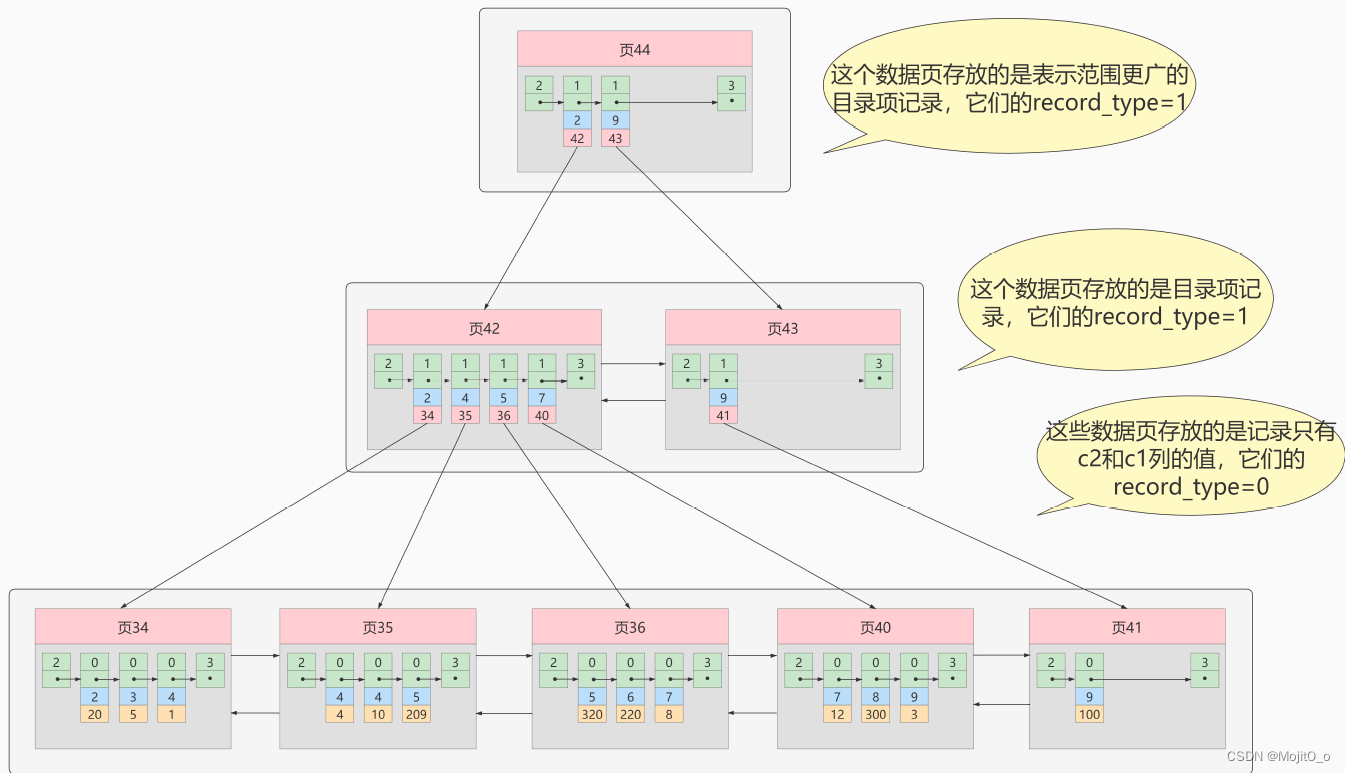
该索引中只有c2字段和c1(主键)字段,要想查找到该字段对应的所有数据(如select *),需要通过查找到的c1(主键)再到聚簇索引中查找完整的数据项目,这个过程叫回表。总共需要用到2棵b+树。
为什么需要有回表操作?不能将完整记录存在叶子节点吗?
正如前面说的,一个表中只能有一个聚簇索引,但可以有多个二级索引。如果给二级索引放上了所有记录,数据量会十分庞大,假设有三个二级索引,每个索引都完整存储了一遍表记录,整个表记录存储了四份,冗余非常大。。

联合索引(非聚簇)
同时为多个列建立索引,如c2和c3,先按c2排序,再在基础上为c3排序,最后保留主键
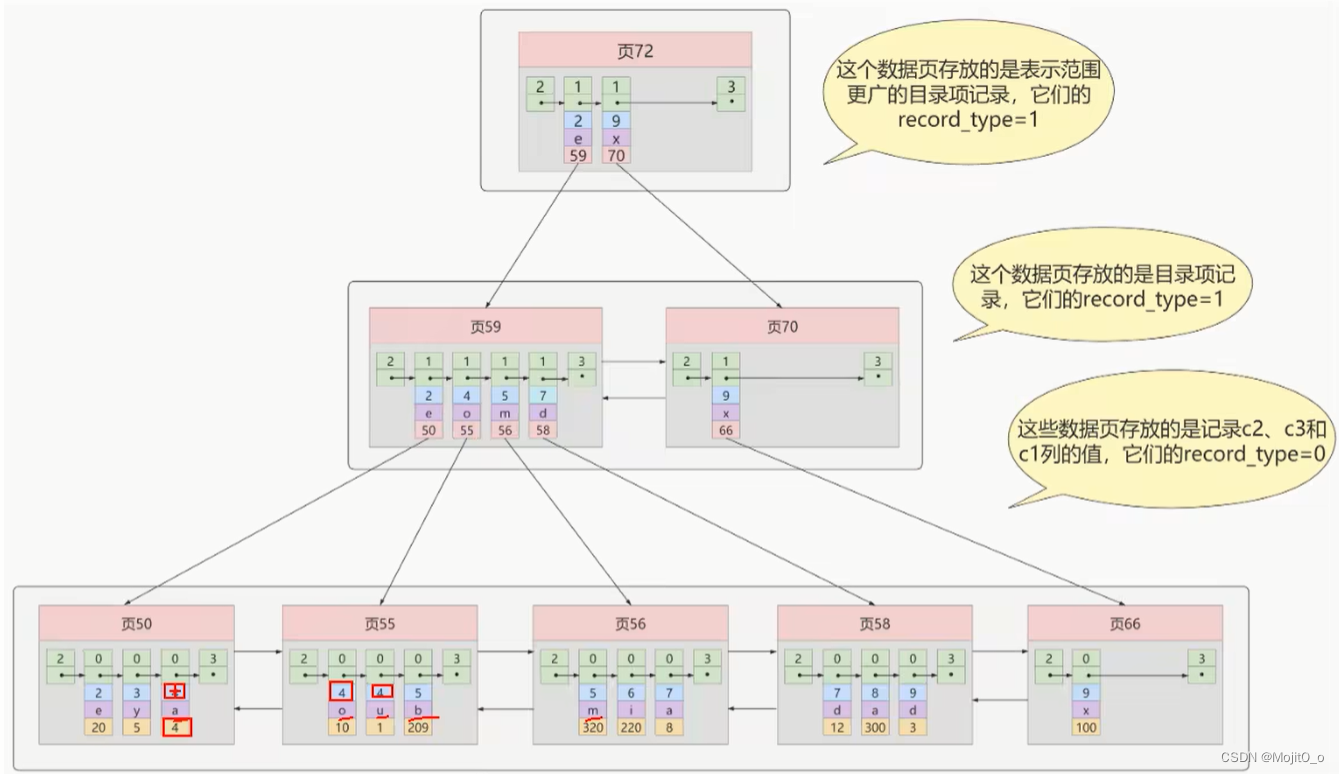
InnoDB的B+树索引的注意事项
1.根页面位置万年不动
2. 内节点中目录项记录的唯一性
3. 一个页面最少存储2条记录
myISAM中索引设计方案
myisam中索引和数据分开。文件拓展:.MYD 表数据;.MYI 表索引
innodb中,文件拓展:.mdb
添加的字段不进行排序。
myisam的索引文件仅保存数据记录的地址。
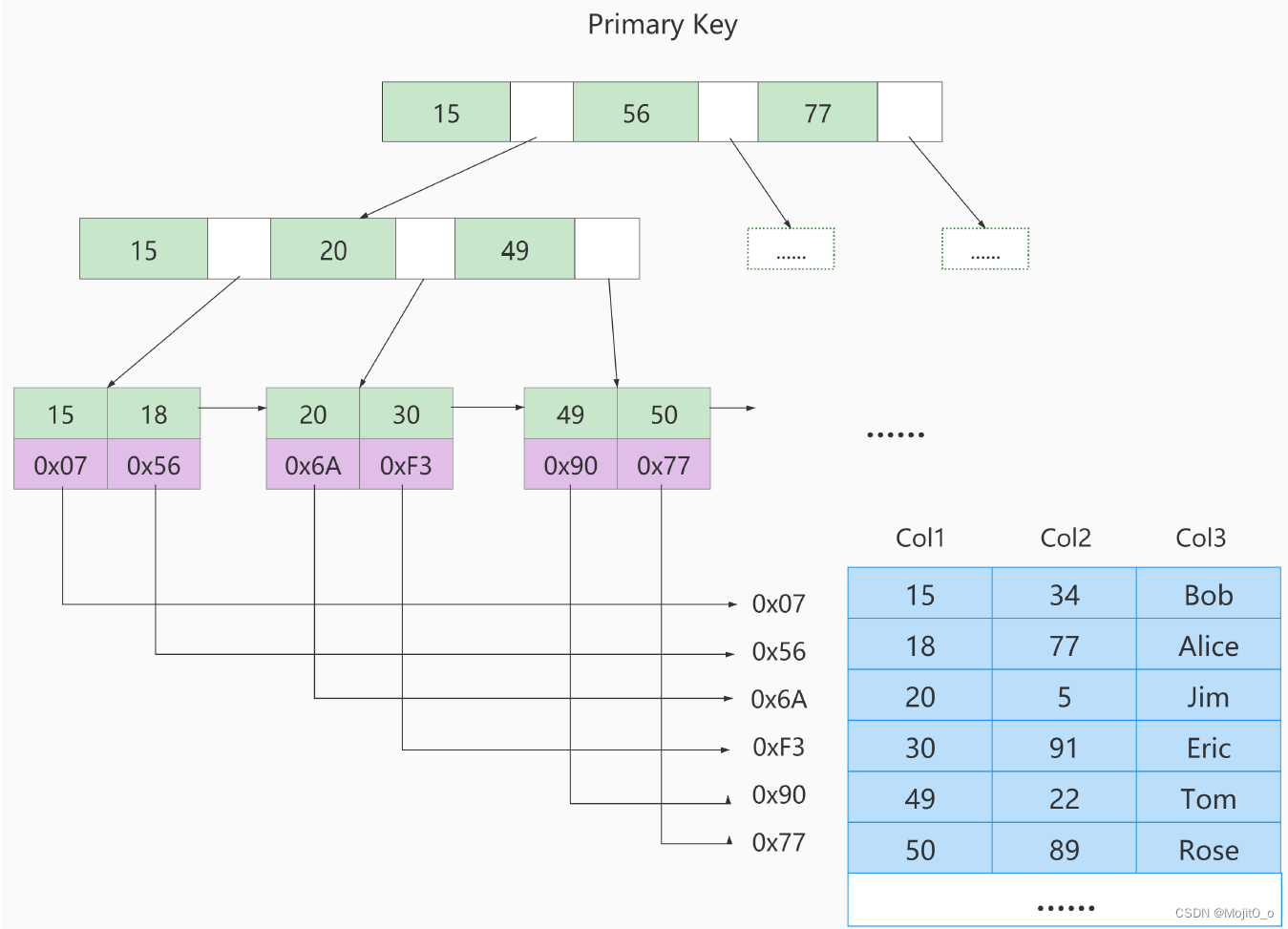
myisam一定会进行回表操作。














 514
514











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









