






MOE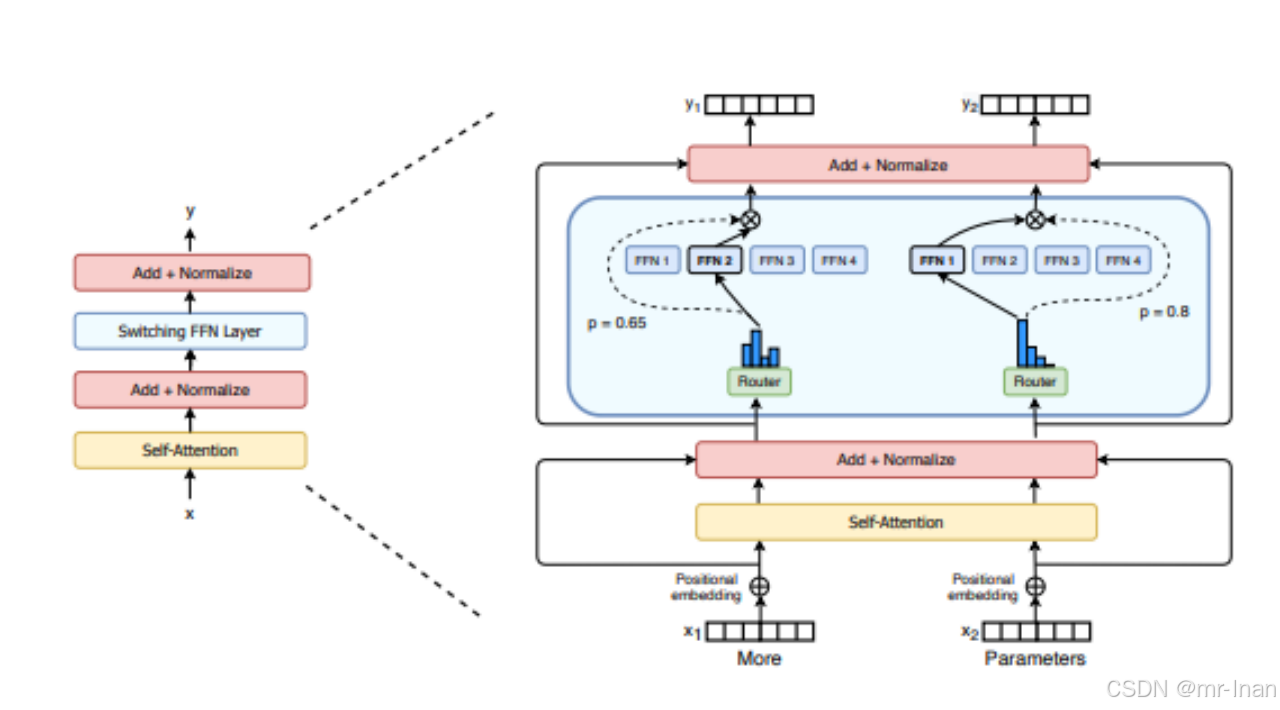
Deepseek MoE
问题:
1.混合专家通常采用有限数量的专家(8个或16个),由于token会有更多的样的知识,导致特定的专家变成一个杂糅多知识的专家,不能充分发挥专家的专业效果。
2.不同的专家肯呢个要学习相同的公共知识,导致专家参数出现冗余,使MoE模型无法达到理论上限性能。
解决:
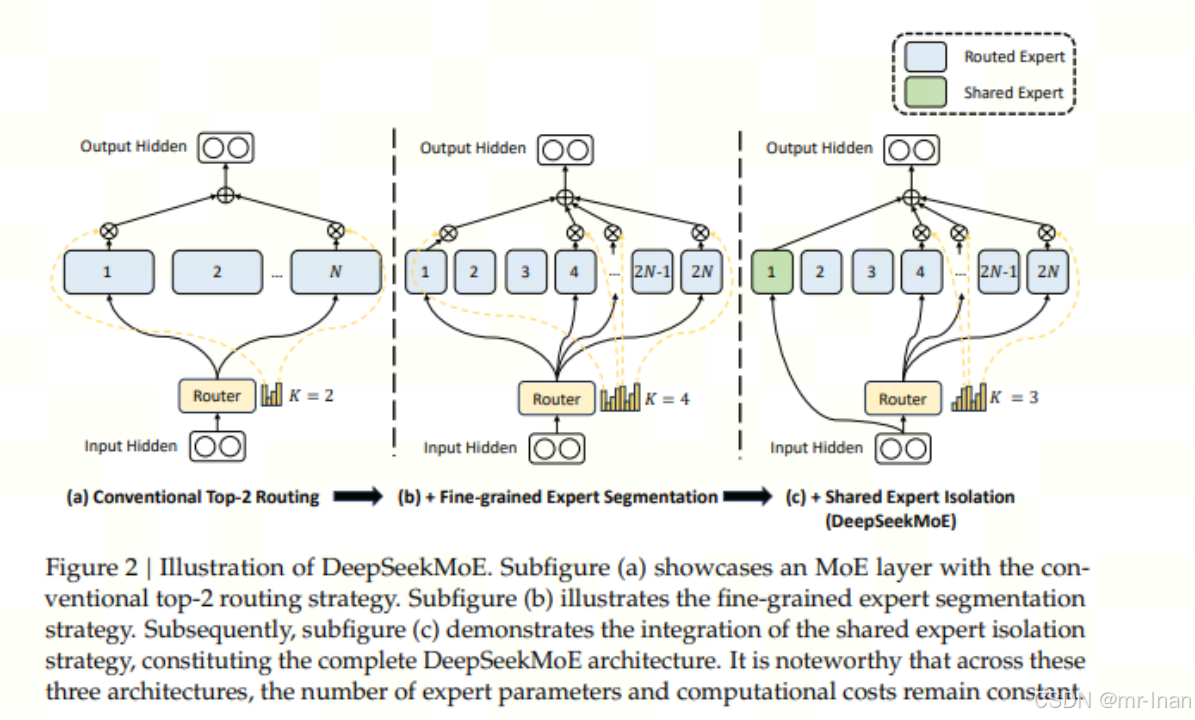
1.细粒度专家划分,在保持参数数量不变的情况下,我们通过拆分(FFN)的中间隐藏维度,将专家划分得更细。即由(a)部分架构转换为(b)部分架构
2.共享专家分离,分理处特定的专家作为共享专家,使得这些专家一直处于激活状态,使这些专家学习通用知识,缓解其他专家学习通用知识,使得路由专家之间的冗余得到缓解
专家级别的负载均衡损失函数

设备级别的辅助损失函数

v2
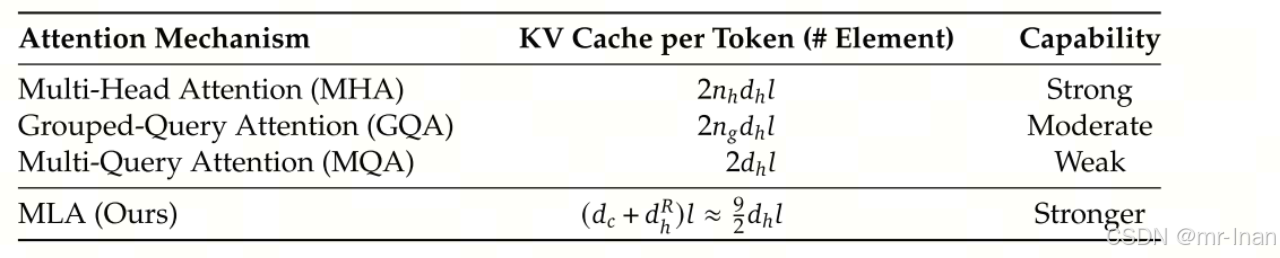
MHA需要大量的显存来存储KV cache,为了减少KV cache 显存占用,GQA,MQA被提出,虽然显存占用减少,但效果却与MHA相比下降,因此deepseek v2提出一种新的MLA注意力,可以有效地减少显存占用,同时效果超越MHA。
MLA
MLA的核心是对键和值进行低秩联合压缩,以减少KV缓存
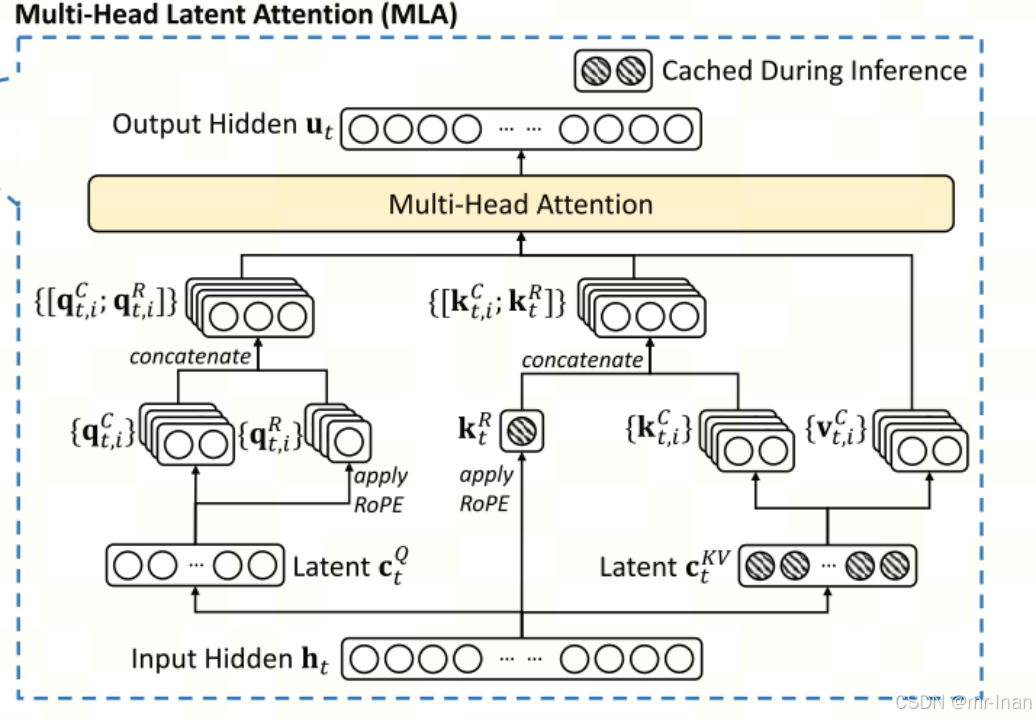
由于位置编码不能适用于MLA,因此deepseek v2中提出了解耦的RoPE策略,
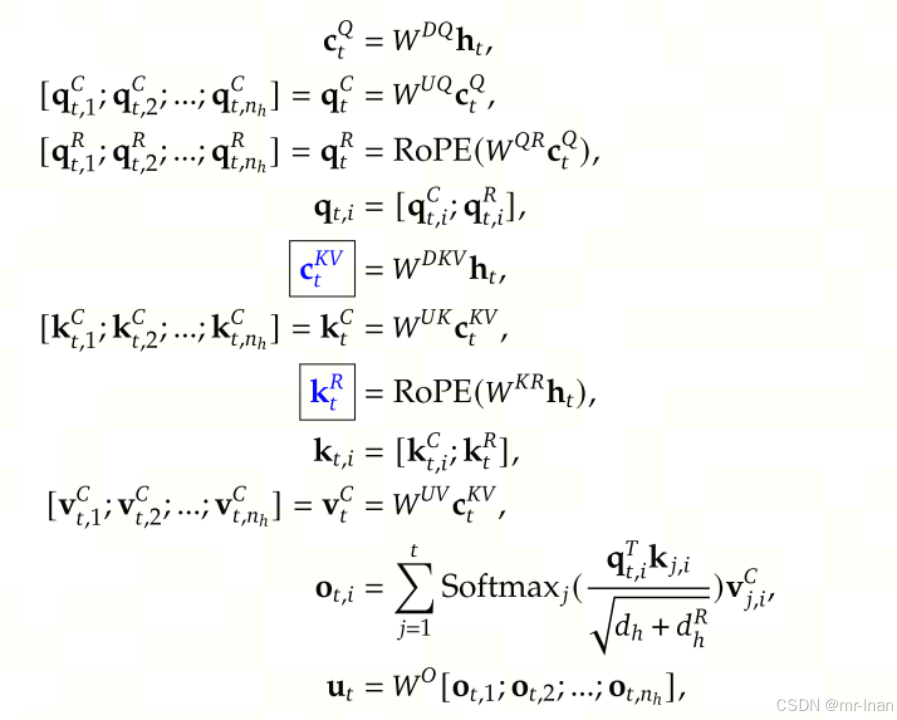
因此只需要保存蓝色部分,每个token需要KV cache的存储为(dc+dr)*l
架构上架构上沿用deepseek MoE架构
在deepseek MoE架构上添加了通信均衡策略,与专家级别的负载均衡损失函数和设备级负载均衡损失函数相似,是用该损失函数保证设备之间的信息的平衡交换,促进有效的通信。
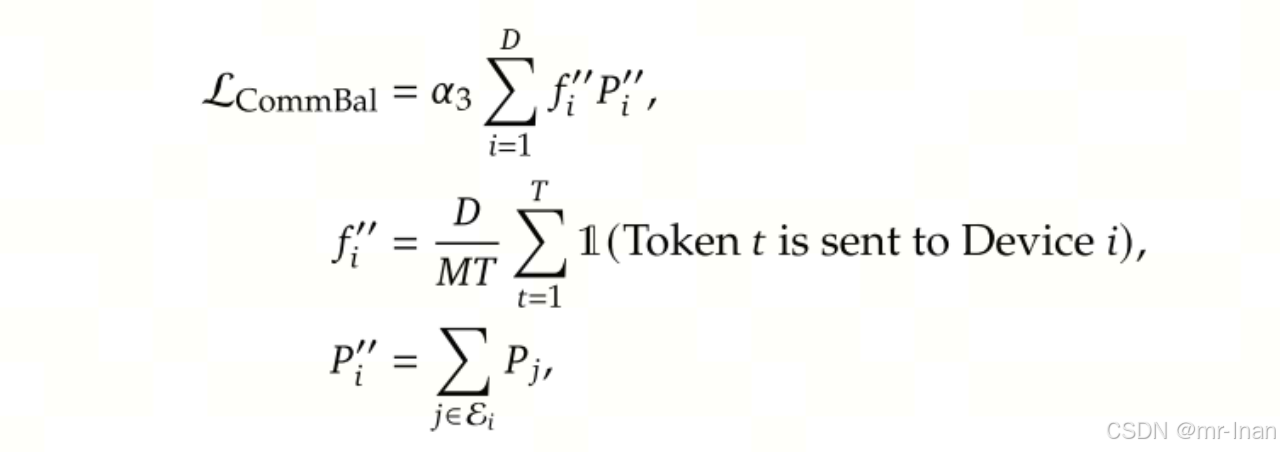
v3
使用新的无损耗负载均衡代替之前MoE架构中的辅助损失函数,在之前使用的辅助损失函数会损害模型性能,因此为了解决该问题,deepseek v3使用了一种无损耗损失函数(Auxiliary-Loss-Free Load Balancing),该方法在路由选择时为每一个专家添加一个偏置项bi,并在后续训练中,对过载专家的偏置项减小为bi-r,并且对欠载的专家偏执项增加为bj+r。(偏执项仅作用于路由选择,而在计算中继续使用S i,t)
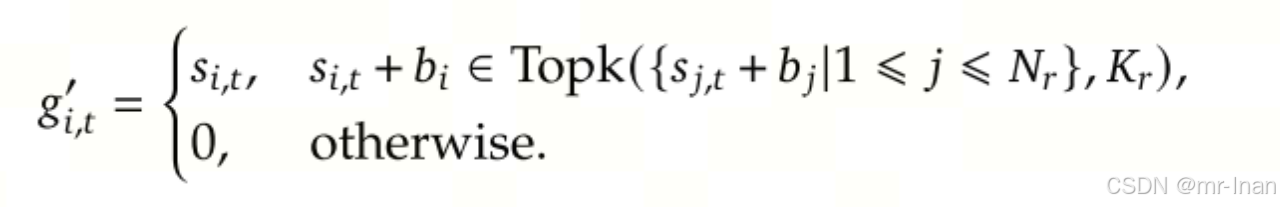
此外,防止任何单个序列内的极端不平衡,还采用了序列级平衡损失(Complementary Sequence-Wise Auxiliary Loss)
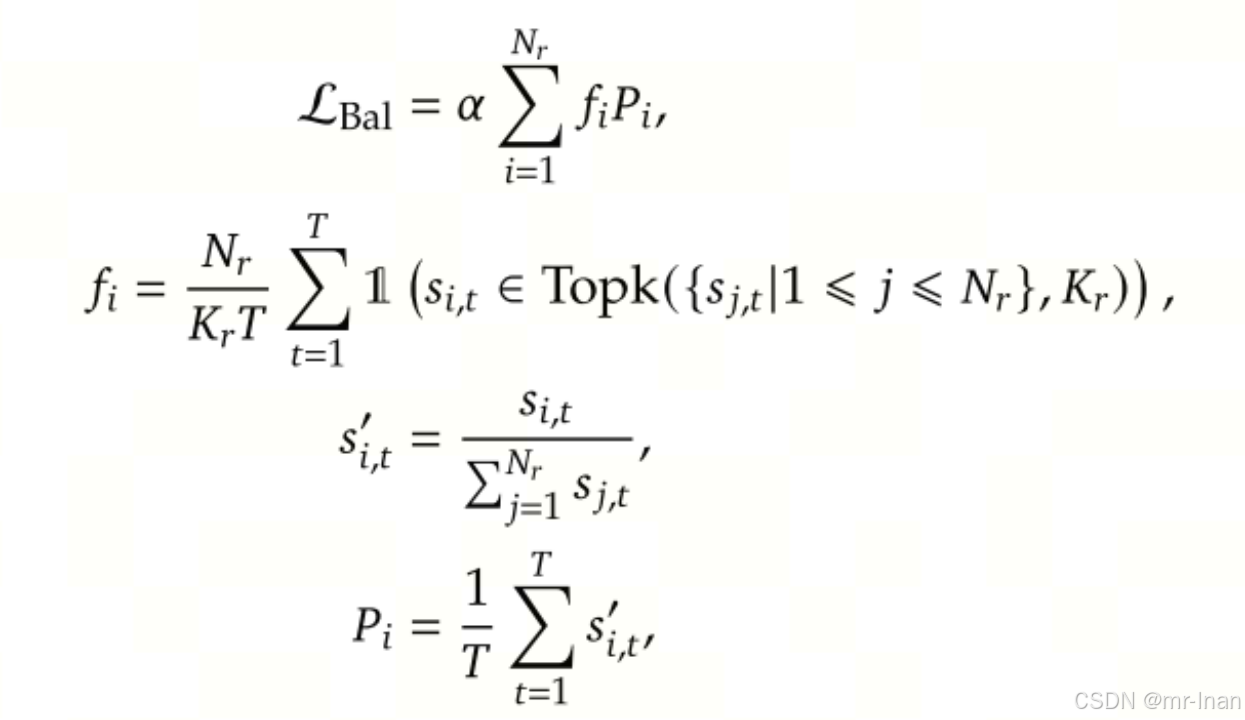
Multi-Token Prediction
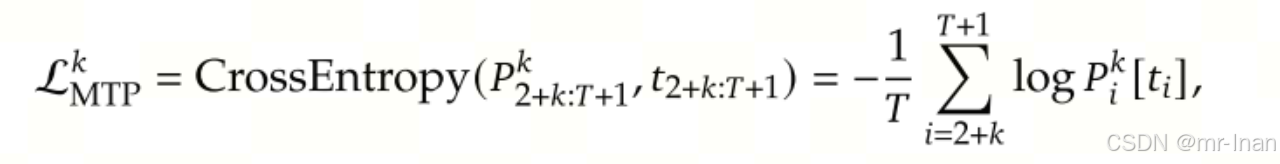
训练:输入t1,main model预测 t2(预测),module1 根据main model 最后一层隐层 + t2(真实) embedding 预测 t3 ,以此类推,预测到tk。
损失:
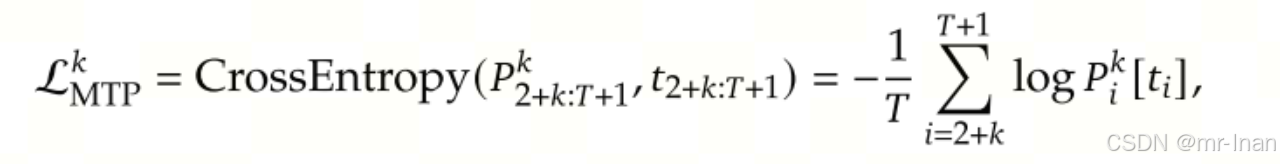
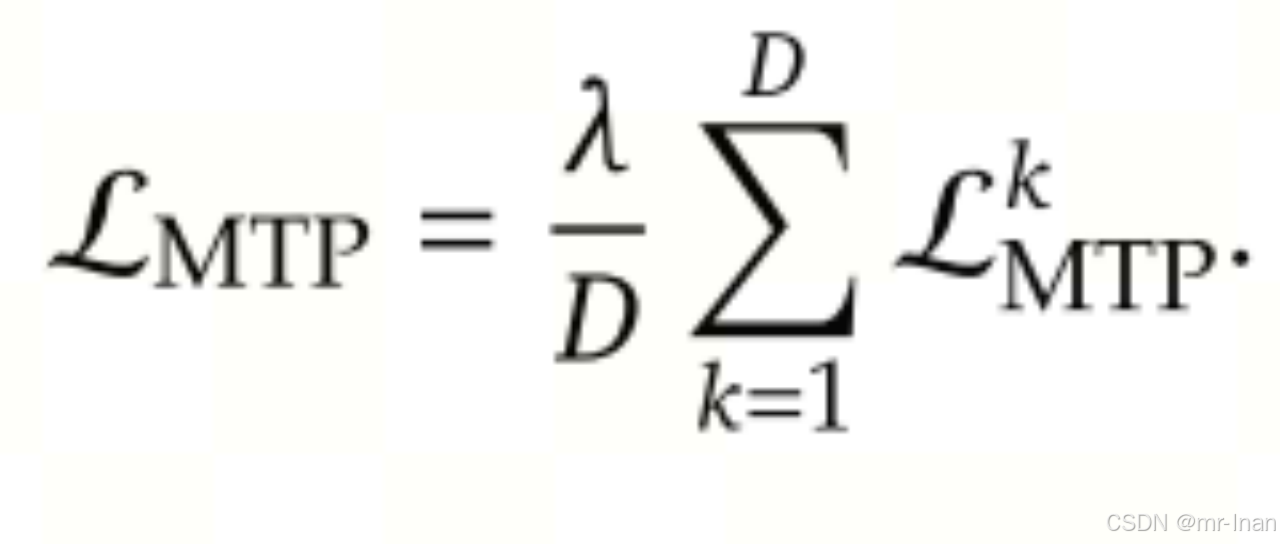
推理:
将下一步输入替换成上一步预测输出(t2(真实)替换为t2(预测)),也可以取消MTP进行推理。
R1
DeepSeek-R1-Zero:
在模型训练过程中很大程度依赖于监督数据,而这些数据收集需要大量的时间。DeepSeek-R1-Zero重点关注通过强化学习自我进化。
Group Relative Policy Optimization(GRPO)
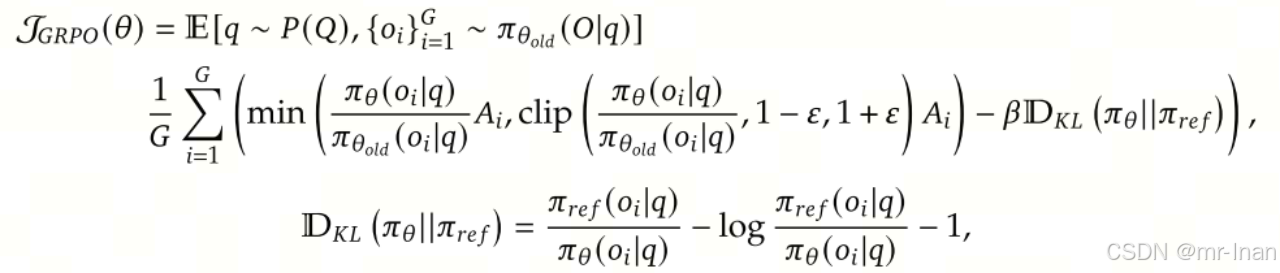
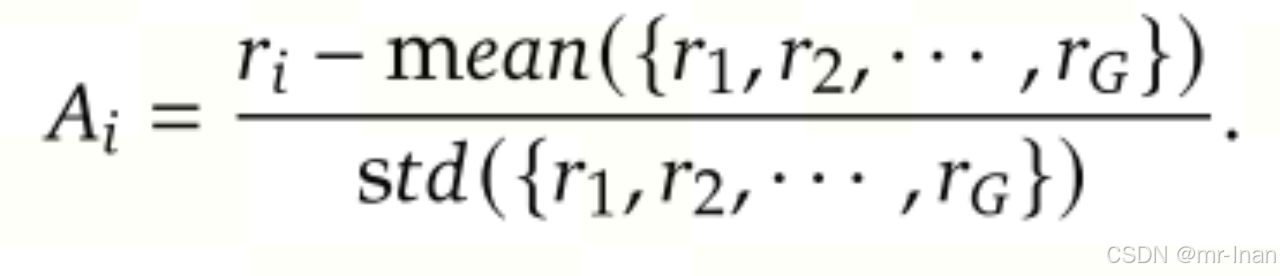
Reward Model
仅使用规则奖励模型:Accuracy rewards(准确度奖励)和Format rewards(格式奖励)
Accuracy rewards:在有确定性结果的数学问题中,要统一输出格式,避免出现 0.5!=1/2的情况,导致训练无法收敛
Format rewards:则确保模型输出思考过程放在<think>和</think>之间,确保格式正确
DeepSeek-R1
阶段1 冷启动:
冷启动数据:利用长思维回答作为 few-shot 示例,直接提示模型生成包含反思和验证步骤的详细答案,以及收集 DeepSeek-R1-Zero 的输出并通过人工标注者进行细化。
阶段2 推理导向的强化学习:
使用冷启动模型进行RL训练,以提升模型在推理任务上的性能。并引入语言一致性奖励,该奖励根据思维链(CoT)中目标语言单词的比例来计算,以减少推理过程中的语言混合问题。
阶段3 拒绝采样和 SFT:
构造推理数据和非推理数据,使用deepseek对该部分数据进行微调
推理数据:使用上一个训练收敛的checkpoint进行数据生成,生成推理轨迹,其中部分数据使用生成奖励模型,为了提升数据质量,过滤掉混合语言,长段落和代码块的思路链。对于每个提示的多个响应进行采样,仅保留正确地响应
非推理数据:使用deepseek-v3的sft数据部分,并且对部分数据使用deepseek-v3生成潜在思维链,对于简单查询不提供思维链。
阶段4 适用于所有场景的强化学习:
推理数据:使用与deepseek-r1-zero相同的奖励进行训练
常规数据:使用奖励模型进行训练
无害性:评估模型的整个响应,包括推理过程和总结,以识别和减轻生成过程中可能出现的任何潜在风险、偏见或有害内容。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









