







mapreduce原理
MapReduce是一种编程模型,用于大规模数据集的并行运算,其中包含 Map(映射) 和 Reduce(归约) 两个阶段。
接下来以最经典的 Word Count 案例进行解析
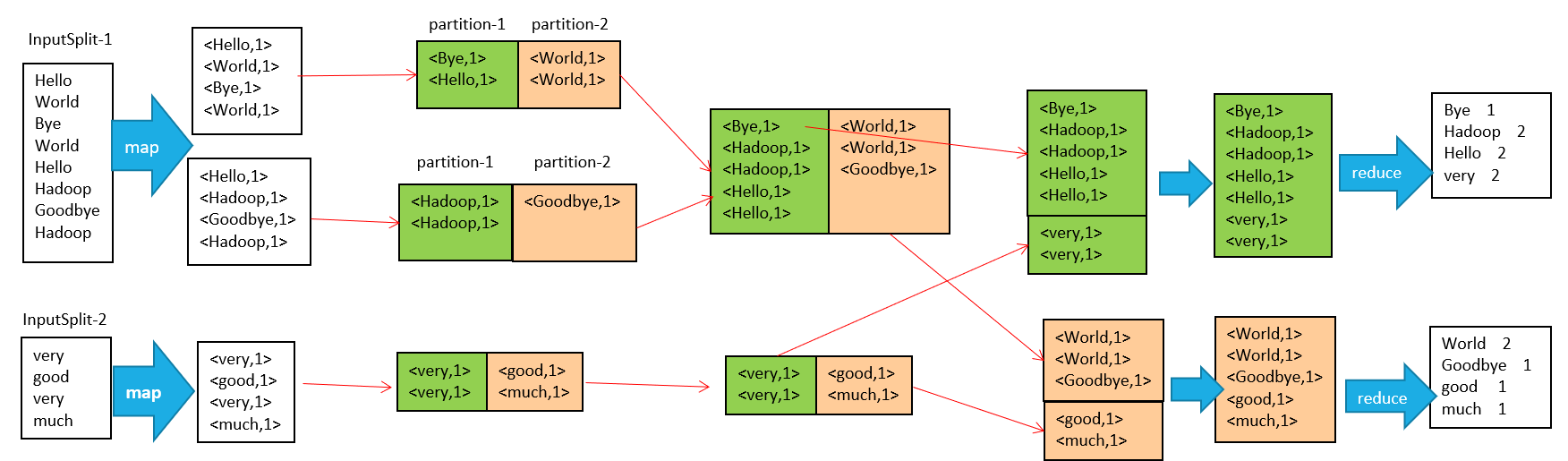
在MapReduce整个过程可以概括为以下过程:
输入 --> map --> shuffle --> reduce -->输出
流程说明如下:
-
输入文件分片,每一片都由一个MapTask来处理
-
Map输出的中间结果会先放在内存缓冲区中,这个缓冲区的大小默认是100M,当缓冲区中的内容达到80%时(80M)会将缓冲区的内容写到磁盘上。也就是说,一个map会输出一个或者多个这样的文件,如果一个map输出的全部内容没有超过限制,那么最终也会发生这个写磁盘的操作,只不过是写几次的问题。
-
从缓冲区写到磁盘的时候,会进行分区并排序,分区指的是某个key应该进入到哪个分区,同一分区中的key会进行排序,如果定义了Combiner的话,也会进行combine操作
-
如果一个map产生的中间结果存放到多个文件,那么这些文件最终会合并成一个文件,这个合并过程不会改变分区数量,只会减少文件数量。例如,假设分了3个区,4个文件,那么最终会合并成1个文件,3个区
-
以上只是一个map的输出,接下来进入reduce阶段
-
每个reducer对应一个ReduceTask,在真正开始reduce之前,先要从分区中抓取数据
-
相同的分区的数据会进入同一个reduce。这一步中会从所有map输出中抓取某一分区的数据,在抓取的过程中伴随着排序、合并。
-
reduce输出
案例背景
假设有以下好友列表,A的好友有B,C,D,F,E,O; B的好友有A,C,E,K
那我们要如何算出A-O用户每个用户之间的共同好友呢?
A:B,C,D,F,E,O
B:A,C,E,K
C:F,A,D,I
D:A,E,F,L
E:B,C,D,M,L
F:A,B,C,D,E,O,M
G:A,C,D,E,F
H:A,C,D,E,O
I:A,O
J:B,O
K:A,C,D
L:D,E,F
M:E,F,G
O:A,H,I,J
解决思路
下面我们将演示分步计算,思路主要如下:

- 提取用户的好友列表

- 提取共同好友

代码实现
由上可知,此次计算由两步组成,因此需要两个MapReduce程序先后执行
Maven项目配置
在编写程序前需要先导入Maven依赖与打包插件
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<!--此处为Maven项目信息-->
<groupId></groupId>
<artifactId></artifactId>
<version></version>
<!--Maven项目全局配置-->
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
</properties>
<dependencies>
<!--Hadoop依赖-->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.7</version>
</dependency>
</dependencies>
<build>
<plugins>
<!--打包插件-->
<plugin>
<group 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 337
337

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









