







一、商品上架流程
product
1、根据spuid查询所有sku信息
2、将sku信息封装成skuModel(向es中存储的是skuModel VO)
不一致信息:
库存信息
发送远程调用 查询系统中是否存在库存
热度评分
品牌和分类的名字
检索属性
查出当前sku中所有可以被检索的属性
3、将数据发给es进行保存,调用gulimall-search微服务进行保存
(1)在es中建立索引,建立号映射关系(doc/json/product-mapping.json)
(2)在es中保存这些数据
(3)设置成功失败状态
二、Nginx反向代理配置
1、什么是nginx反向代理
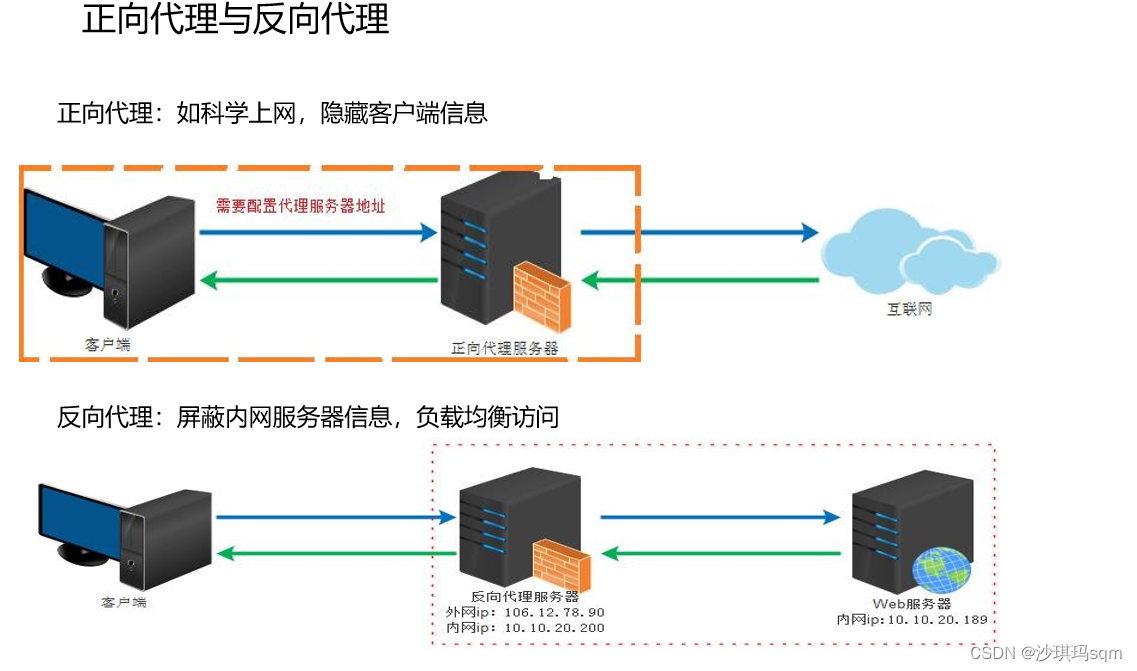
正向代理:我们要访问谷歌,但是被墙,所以将请求发送给代理服务器,由代理服务器来访问,这叫正向代理
反向代理:服务器部署在内网中,客户端访问服务器不能直接访问服务器的内网地址,通常需要根据域名来访问(www.baidu.com)。所以需要反向代理服务器来将外网的ip转换成内网ip来访问。
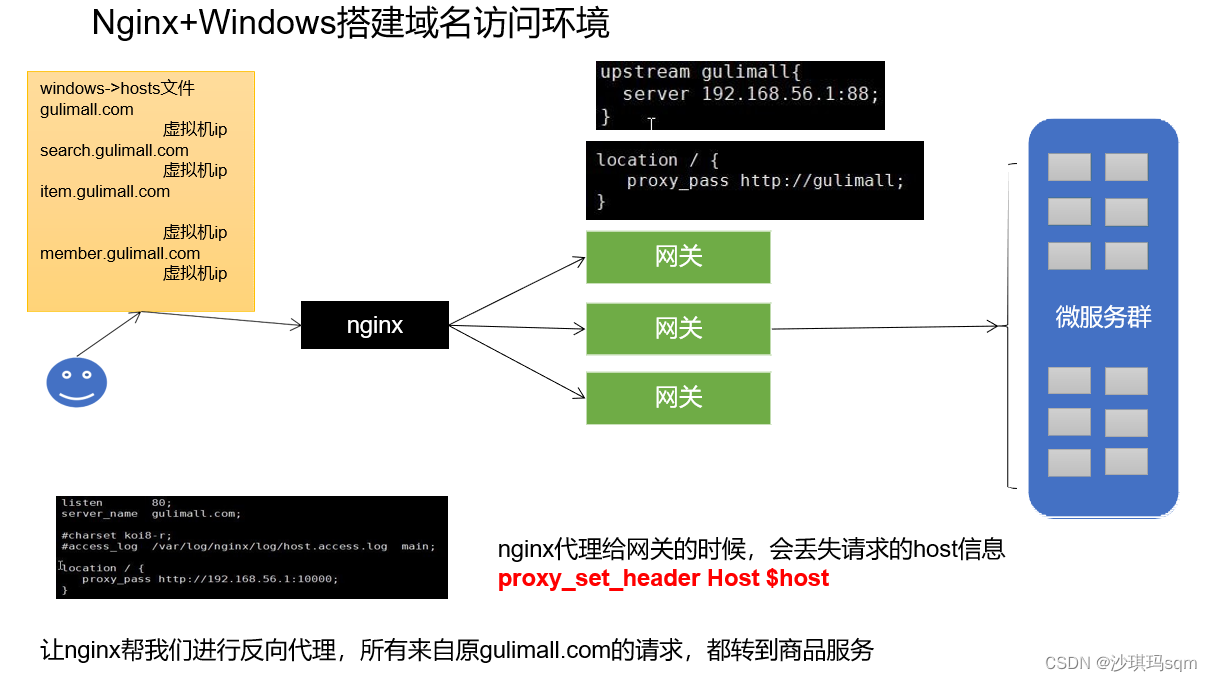
2、反向代理如何实现
只代理到商品服务:客户端发送gulimall.com请求,在windows中映射gulimall.com是虚拟机ip(192.168.56.10)所以会访问虚拟机。虚拟机中的nginx监听80端口。在配置文件中,会设置nginx代理到的路径http://192.168.56.1:10000。这样就访问到了商品服务里的首页(首页在商品服务中)
location/{
proxy_pass http://192.168.56.1:10000
}
代理到网关: 客户端发送gulimall.com请求,在windows中映射gulimall.com是虚拟机ip(192.168.56.10)所以会访问虚拟机。虚拟机中的nginx监听80端口。在配置文件中nginx.config中配置上游服务器gulimall http://192.168.56.1:88。然后继续在配置文件gulimall.config中nginx代理到的路径http://gulimall。
需要注意的是,nginx代理给网关会丢失一部分信息。解决如下
三、压力测试
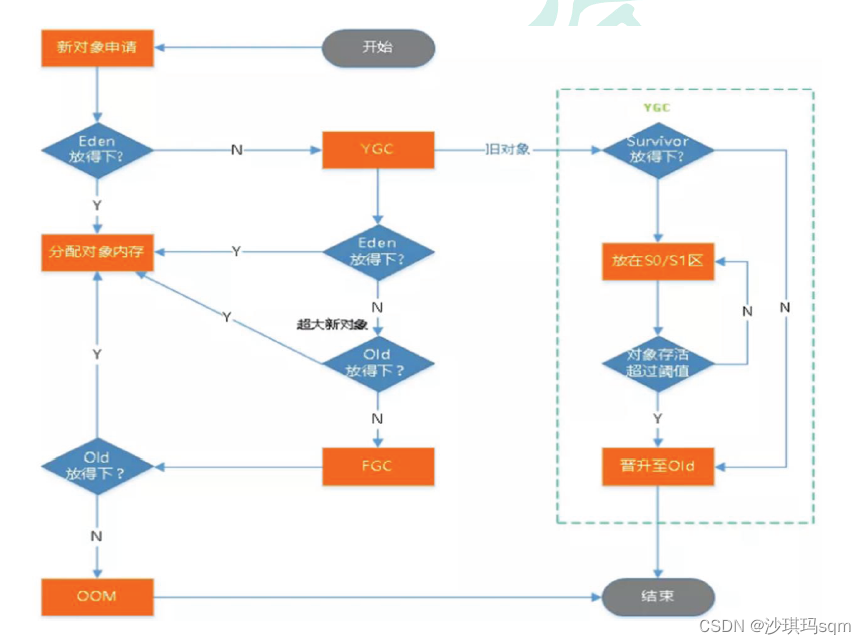
1、JVM堆栈垃圾回收流程
2、优化方式
加内存(提升JVM堆中eden区和old区的内存空间,避免频繁的gc)
数据库优化,加索引
打开模板缓存,设置日志为error时记录
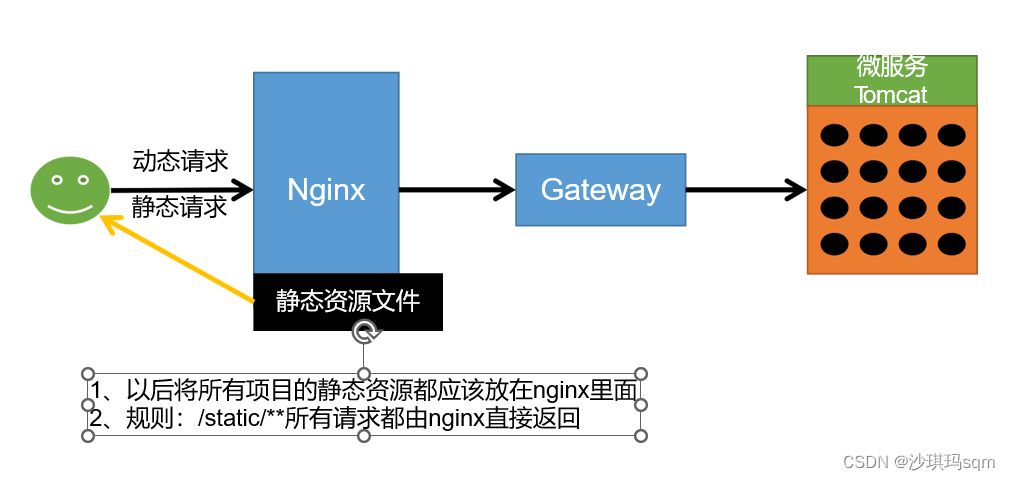
静态资源快速返回 动静分离
优化代码 减少循环查表
3、Nginx实现动静分离
(1)将所有的静态资源移动到nginx中
(2)/static/**下的所有内容由nginx返回,在nginx中进行相关配置,gulimall-conf中设置
location /static/{
root /usr/share/nginx/html
}
4、优化三级分类数据获取
直接查询所有分类的结果,只查一次表,将其他循环查表的过程抽取为一个函数
四、缓存与分布式锁
为什么使用缓存
如何使用redis
引入data-redis-starter
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
简单配置redis的host
使用自动配置好的String Redis Template redis
String Redis Template redis中 存储键值对 键与值都是String类型
//将数据放入缓存
@Override
public Map<Long, List<Catelog2Vo>> getCatelogJson() {
String catelogJson = redisTemplate.opsForValue().get("catelogJson");
if (StringUtils.isEmpty(catelogJson)){
//缓存中没有
Map<Long, List<Catelog2Vo>> catelogJsonFromDB = getCatelogJsonFromDB();
redisTemplate.opsForValue().set("catelogJson",JSON.toJSONString(catelogJsonFromDB));
return catelogJsonFromDB;
}
//因为转化的对象是复杂对象,所以通过TypeReference
Map<Long, List<Catelog2Vo>> catelogJsonFromDB = JSON.parseObject(catelogJson,new TypeReference<Map<Long, List<Catelog2Vo>>>(){});
return catelogJsonFromDB;
}
//从数据库查询数据
public Map<Long, List<Catelog2Vo>> getCatelogJsonFromDB() {
//将数据库的多次交互,转为一次,一次性查询所有数据
List<CategoryEntity> allList = baseMapper.selectList(null);
//查出所有分类
List<CategoryEntity> level1Categorys = getParent_cid(allList,0L);
//分装数据
Map<Long, List<Catelog2Vo>> resultMap = level1Categorys.stream().collect(Collectors.toMap(CategoryEntity::getCatId, v -> {
//每一个的一级分类,查到这个一级分类的二级分类
List<CategoryEntity> list = getParent_cid(allList,v.getCatId());
List<Catelog2Vo> catelog2VoList = null;
if (!StringUtils.isEmpty(list)) {
catelog2VoList = list.stream().map(item -> {
Catelog2Vo catelog2Vo = new Catelog2Vo(v.getCatId().toString(), null, item.getCatId().toString(), item.getName());
//封装二级分类的三级分类
List<CategoryEntity> entityList = getParent_cid(allList,item.getCatId());
if (!StringUtils.isEmpty(entityList)){
List<Catelog2Vo.Catelog3Vo> catelog3Vos = entityList.stream().map(m -> {
Catelog2Vo.Catelog3Vo catelog3Vo = new Catelog2Vo.Catelog3Vo(item.getCatId().toString(),m.getCatId().toString(),m.getName());
return catelog3Vo;
}).collect(Collectors.toList());
catelog2Vo.setCatalog3List(catelog3Vos);
}
return catelog2Vo;
}).collect(Collectors.toList());
return catelog2VoList;
}
return catelog2VoList;
}));
return resultMap;
}
private List<CategoryEntity> getParent_cid(List<CategoryEntity> allList,Long parent_cid) {
List<CategoryEntity> collect = allList.stream().filter(item -> {
return item.getParentCid().equals(parent_cid);
}).collect(Collectors.toList());
return collect;
// return baseMapper.selectList(new QueryWrapper<CategoryEntity>().eq("parent_cid", v.getCatId()));
}
内存溢出以及解决
TODO 产生堆外内存溢出OutOfDirectMemoryError:
产生原因
- springboot2.0以后默认使用lettuce作为操作redis的客户端,它使用netty进行网络通信
- lettuce的bug导致netty堆外内存溢出。netty如果没有指定堆外内存,默认使
用Xms的值,可以使用-Dio.netty.maxDirectMemory进行设置
解决方案:由于是lettuce的bug造成,不要直接使用-Dio.netty.maxDirectMemory 去调大虚拟机堆外内存,治标不治本。
- 升级lettuce客户端。
- 切换使用jedis
lettuce和jedis是操作redis的底层客户端,RedisTemplate是再次封装</font color=‘red’>
缓存失效 穿透、雪崩、击穿
**缓存穿透:**是指大量的并发请求访问一个数据库中从未出现的内容,由于缓存中没有这条内容,所以会并发查表导致数据库崩溃。
**解决办法:**将null也写入缓存中
**缓存雪崩:**是指设置缓存时,key使用了相同的过期时间,大量并发此时同时访问这些过期缓存,导致同时查表导致数据库崩溃。
**解决办法:**缓存过期时间在原来的基础上设置随机值。
**缓存击穿:**是指大量并发请求同时访问一个热点key,如果这个热点key刚好在缓存中过期,导致这个key的数据查询都落到数据库导致数据库崩溃。
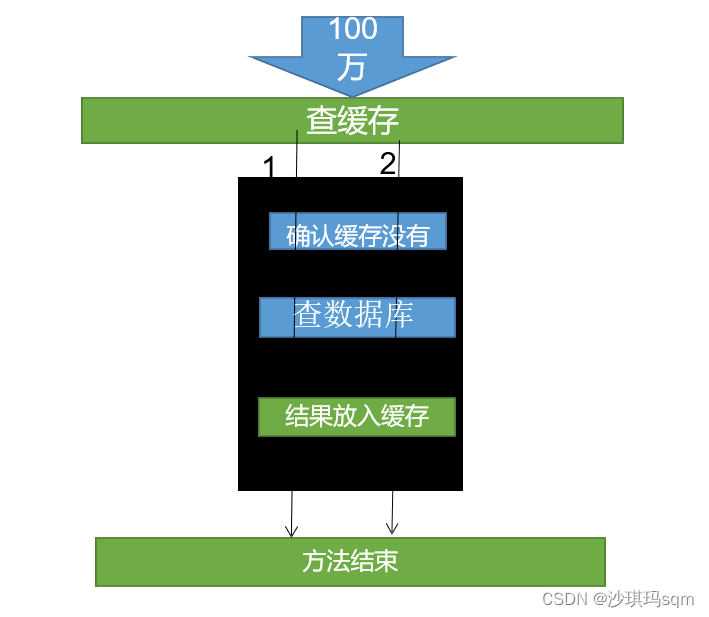
**解决办法:**大量的并发只让一个人去查,其他人等待,查到之后释放锁,其他人回去到锁,查找缓存不会查找数据库。加锁方法使用synchronized(this),this表示当前对象。
注意: 缓存时许问题,确认缓存、查数据库和结果放入缓存是一个原子操作,要在锁内实现。
@Override
public Map<Long, List<Catelog2Vo>> getCatelogJson() {
String catelogJson = redisTemplate.opsForValue().get("catelogJson");
//缓存中没有
if (StringUtils.isEmpty(catelogJson)) {
//获取数据返回
Map<Long, List<Catelog2Vo>> catelogJsonFromDB = getCatelogJsonFromDB();
return catelogJsonFromDB;
}
//因为转化的对象是复杂对象,所以通过TypeReference
Map<Long, List<Catelog2Vo>> catelogJsonFromDB = JSON.parseObject(catelogJson, new TypeReference<Map<Long, List<Catelog2Vo>>>() {
});
return catelogJsonFromDB;
}
//从数据库查询数据
public Map<Long, List<Catelog2Vo>> getCatelogJsonFromDB() {
synchronized (this) {
//判断缓存是否已经有数据,防止之前的线程已经放好数据
String catelogJson = redisTemplate.opsForValue().get("catelogJsonFromDB");
if (!StringUtils.isEmpty(catelogJson)) {
//因为转化的对象是复杂对象,所以通过TypeReference
Map<Long, List<Catelog2Vo>> resultMap = JSON.parseObject(catelogJson, new TypeReference<Map<Long, List<Catelog2Vo>>>() {
});
return resultMap;
}
//将数据库的多次交互,转为一次,一次性查询所有数据
List<CategoryEntity> allList = baseMapper.selectList(null);
//查出所有分类
List<CategoryEntity> level1Categorys = getParent_cid(allList, 0L);
//分装数据
Map<Long, List<Catelog2Vo>> resultMap = level1Categorys.stream().collect(Collectors.toMap(CategoryEntity::getCatId, v -> {
//每一个的一级分类,查到这个一级分类的二级分类
List<CategoryEntity> list = getParent_cid(allList, v.getCatId());
List<Catelog2Vo> catelog2VoList = null;
if (!StringUtils.isEmpty(list)) {
catelog2VoList = list.stream().map(item -> {
Catelog2Vo catelog2Vo = new Catelog2Vo(v.getCatId().toString(), null, item.getCatId().toString(), item.getName());
//封装二级分类的三级分类
List<CategoryEntity> entityList = getParent_cid(allList, item.getCatId());
if (!StringUtils.isEmpty(entityList)) {
List<Catelog2Vo.Catelog3Vo> catelog3Vos = entityList.stream().map(m -> {
Catelog2Vo.Catelog3Vo catelog3Vo = new Catelog2Vo.Catelog3Vo(item.getCatId().toString(), m.getCatId().toString(), m.getName());
return catelog3Vo;
}).collect(Collectors.toList());
catelog2Vo.setCatalog3List(catelog3Vos);
}
return catelog2Vo;
}).collect(Collectors.toList());
return catelog2VoList;
}
return catelog2VoList;
}));
//放入缓存
redisTemplate.opsForValue().set("catelogJson", JSON.toJSONString(resultMap),1L, TimeUnit.DAYS);
return resultMap;
}
}
private List<CategoryEntity> getParent_cid(List<CategoryEntity> allList, Long parent_cid) {
List<CategoryEntity> collect = allList.stream().filter(item -> {
return item.getParentCid().equals(parent_cid);
}).collect(Collectors.toList());
return collect;
// return baseMapper.selectList(new QueryWrapper<CategoryEntity>().eq("parent_cid", v.getCatId()));
}
上面的本地锁只能锁住当前进程,在分布式的情况下无法保证锁住整个集群服务
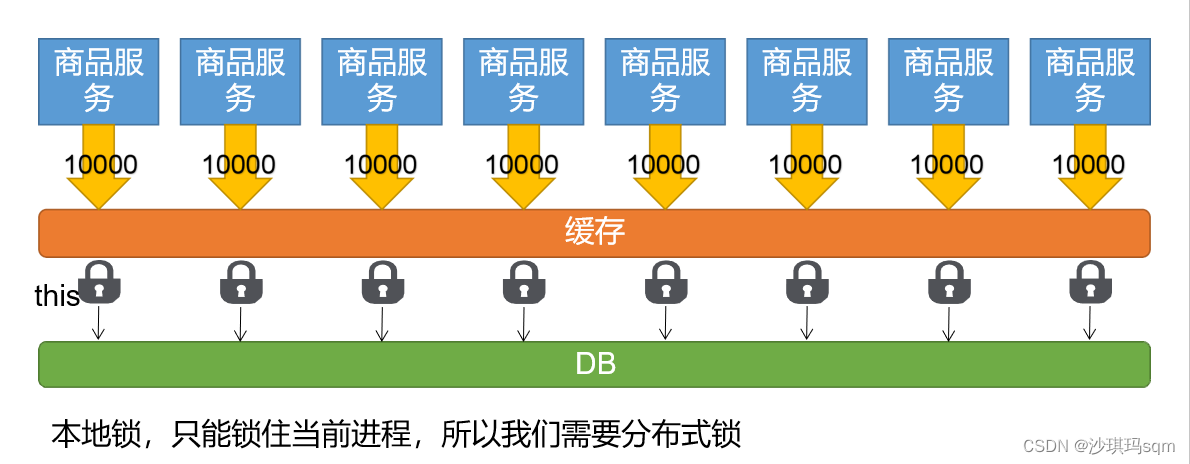
分布式锁
可以让商品服务来占坑,当一个商品服务拿到锁后,其他商品服务必须等待
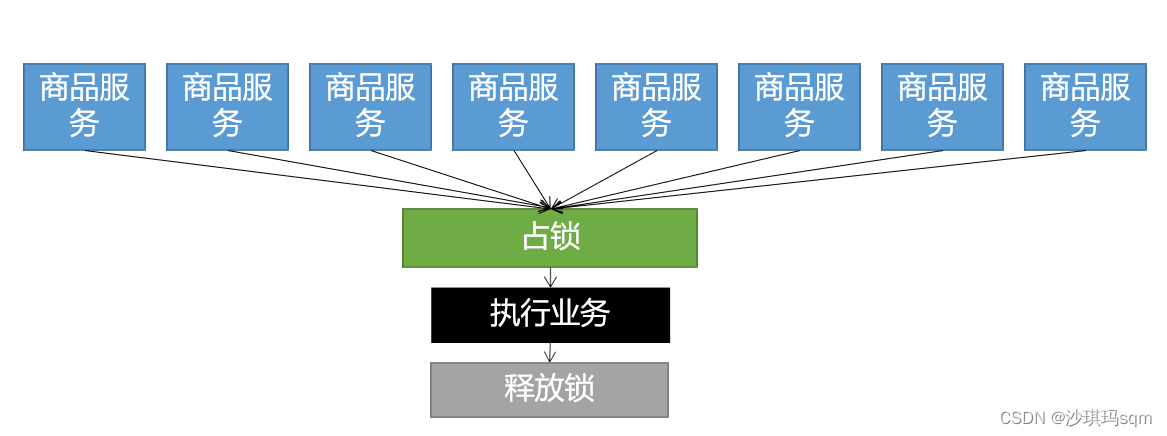
设置分布式锁需要考虑的问题
一二阶段为设置锁需要考虑的问题,二三阶段为删除锁需要考虑的问题
- 第一阶段
setnx会获取锁,然后执行业务,最后删除锁
出现问题:当执行业务时发生宕机,无法执行删除锁的操作,其他线程无法拿到锁。造成死锁。
解决问题:将锁设置一个自动过期时间,来保证锁肯定会被释放

方法名:getCateLogJsonFromDbWithRedisLock
//占分布式锁
Boolean lock=redisTemplate.opsForValue().setIfAbsent("lock","111");
if(lock){
//如果获得锁,执行业务
Map<String,List<Catelog2Vo>> dataFromDb=getDataFromDb();
//执行完删除锁
redisTemplate.delete("lock")
return dataFromDb;
}else{
return getCateLogJsonFromDbWithRedisLock();
}
改进后为:
方法名:getCateLogJsonFromDbWithRedisLock
//占分布式锁
Boolean lock=redisTemplate.opsForValue().setIfAbsent("lock","111");
if(lock){
//如果获得锁,执行业务
Map<String,List<Catelog2Vo>> dataFromDb=getDataFromDb();
//设置过期时间
redisTemplate.expire("key",30,TimeUnit.SECONDS)
//执行完删除锁
redisTemplate.delete("lock")
return dataFromDb;
}else{
return getCateLogJsonFromDbWithRedisLock();
}
- 第二阶段
出现问题:虽然设置了过期时间,但是如果在设置过期时间之前发生了宕机,过期时间没有设置上,又会导致死锁问题。
解决问题:设置过期时间和占位必须是原子操作
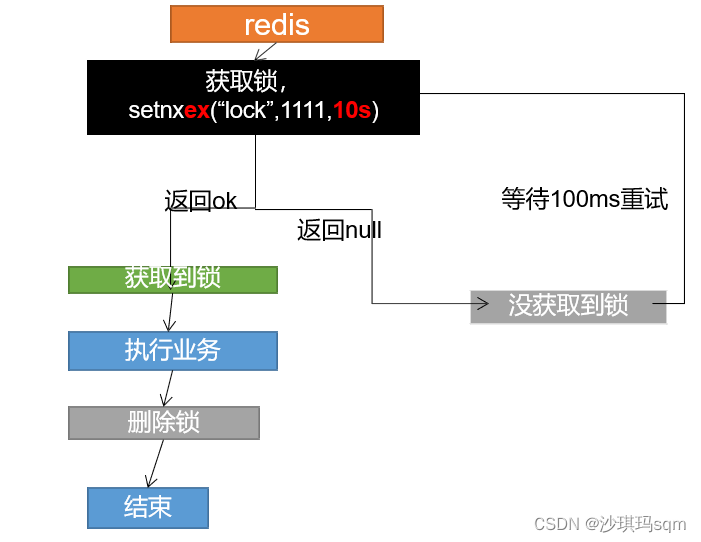
//占分布式锁
//setIfAbsent方法的第三个参数是设置过期时间
Boolean lock=redisTemplate.opsForValue().setIfAbsent("lock","111",300);
if(lock){
//如果获得锁,执行业务
Map<String,List<Catelog2Vo>> dataFromDb=getDataFromDb();
//设置过期时间
//redisTemplate.expire("key",30,TimeUnit.SECONDS)
//执行完删除锁
redisTemplate.delete("lock")
return dataFromDb;
}else{
return getCateLogJsonFromDbWithRedisLock();
}
- 第三阶段
出现问题:由于设置了自动过期时间,如果当前执行的业务很长,删除锁的时候,锁已经自动过期了,此时删除的可能是别人的锁。
解决问题:给每个锁添加唯一的uuid,删除的时候判断一下,匹配的是自己的锁才能删除
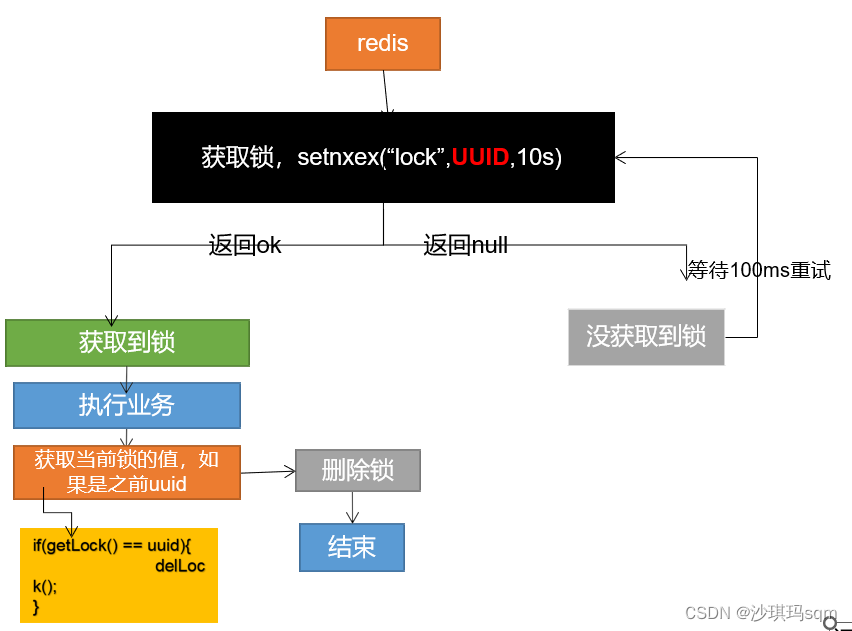
- 第四阶段
出现问题:判断完成之后,需要删除锁前,锁刚好过期,别人设置新的值,那么我们会删除别人的锁
解决问题:删除锁必须保证原子操作(判断与删除同时进行)采用redis+lua脚本实现
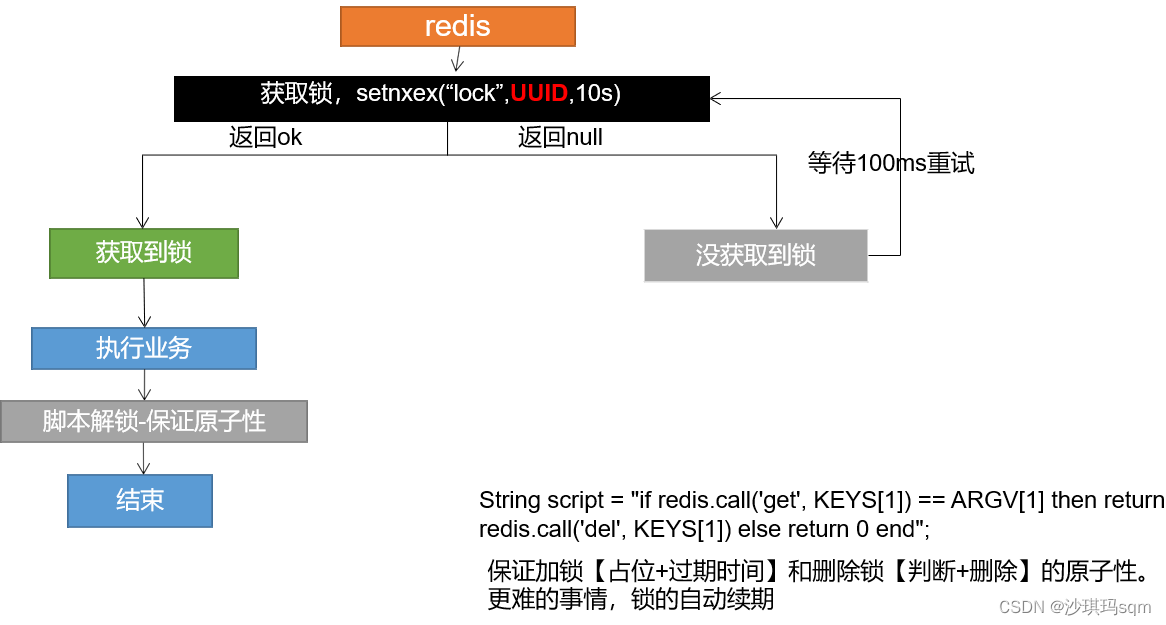
String uuid = UUID.randomUUID().toString();
//设置redis分布式锁,30s自动删除锁
Boolean isLock = redisTemplate.opsForValue().setIfAbsent("lock", uuid,300L,TimeUnit.SECONDS);
if (isLock){
//抢锁成功。。。执行业务
Map<Long, List<Catelog2Vo>> resultMap = null;
try {
resultMap = getLongListMap();
}finally {
//lua脚本解锁:让获取数据+对比数据成为原子操作
String script = "if redis.call(\"get\",KEYS[1]) == ARGV[1] then\n" +
" return redis.call(\"del\",KEYS[1])\n" +
"else\n" +
" return 0\n" +
"end";
Long lock = redisTemplate.execute(new DefaultRedisScript<Long>(script, Long.class),Arrays.asList("lock"),uuid);
}
return resultMap;
}else {
//抢锁失败。。。重试
try {
Thread.sleep(200);
} catch (InterruptedException e) {
e.printStackTrace();
}
// 睡眠0.2s后,重新调用 //自旋
return getCatelogJsonFromDBWithRedisLock();
}
Redisson
Redisson使用
- pom导入
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson</artifactId>
<version>3.13.4</version>
</dependency>
- 开启配置,写一个配置类
@Configuration
public class RedissonConfig {
@Bean(destroyMethod = "shutdown")
public RedissonClient redissonClient(){
Config config = new Config();
config.setTransportMode(TransportMode.EPOLL);
config.useClusterServers()
//可以用"rediss://"来启用SSL连接
.addNodeAddress("redis://192.168.109.101:6379");
return Redisson.create(config);
}
}
可重入锁
基于Redis的Redisson分布式可重入锁RLock Java对象实现了java.util.concurrent.locks.Lock接口。同时还提供了异步(Async)、反射式(Reactive)和RxJava2标准的接口。
- 什么是可重入锁:A中调用B,A拿到锁后,该锁可以由B直接使用,这个锁叫可重入锁,不可重入锁是 A拿到锁后,A调用B,B需要等待A锁的释放,而A锁需要等待B执行完才释放,造成死锁。
- 如何使用Redisson分布式可重入锁
@RequestBody
@GetMapping(/"hello")
public String hello(){
//1、获取锁 锁名字一样就是同一把锁
RLock lock=redission.getLock("lock");
//指定解锁时间的锁
//2、枷锁
lock.lock();//阻塞式等待
//指定解锁时间的锁
//lock.lock(10,TimeUnit.SECONDS)
try{
//3、执行业务
System.out.println("执行业务");
Thread.sleep(30000);
}catch(Exception e){
}finally{
//解锁
lock.unlock();
}
}
Question1: 这与上节redis中自己设置的锁有什么区别
这里是对自己设置的锁进行了封装:上节我们需要自己设置加锁和解锁时的原子操作。而Redisson直接封装了这些原子操作。由于这里加锁会自动设置过期时间,所以不会出现业务崩溃,锁释放不了导致死锁问题。
Question2: Redisson可重入锁,如何保证业务时间长而导致锁被自动删除。
- Redisson可重入锁提供了锁的续期:如果业务时间超长,运行期间会自动给锁续上新的30s(看门狗默认时间)。
- 这里有个疑问,看门狗在业务执行的时候会不断设置新的定时任务来给锁续期,如果此时业务崩溃,看门狗是失效了吗?如果是失效的话,那就相当于不会再继续进行续期,锁会在默认事件之后自动删除。
Question3: 看门狗如何进行锁的续期
只要占锁成功,就会启动一个定时任务,重新给锁设置过期时间,新的过期时间就是看门狗的默认时间。每隔(一个看门狗时间/3)=10s,会自动再次续期,续到30s
Question4: 如果指定自动解锁时间会发生什么
如果指定自动过期时间,看门狗会失效,不会再有锁的续期。自动解锁时间一定要大于业务执行时间。(如果小于会出现业务没执行完,锁已经被释放,此时别的进程抢占锁,当前进程删除锁是报错)。
读写锁
分布式可重入读写锁允许同时有多个读锁和一个写锁处于加锁状态。
读锁被称为共享锁,写锁被称为互斥锁
读读共享 读写/写写 都是互斥
RReadWriteLock rwlock = redisson.getReadWriteLock("anyRWLock");
// 最常见的使用方法
rwlock.readLock().lock();
// 或
rwlock.writeLock().lock();
// 10秒钟以后自动解锁
// 无需调用unlock方法手动解锁
rwlock.readLock().lock(10, TimeUnit.SECONDS);
// 或
rwlock.writeLock().lock(10, TimeUnit.SECONDS);
// 尝试加锁,最多等待100秒,上锁以后10秒自动解锁
boolean res = rwlock.readLock().tryLock(100, 10, TimeUnit.SECONDS);
// 或
boolean res = rwlock.writeLock().tryLock(100, 10, TimeUnit.SECONDS);
//...
lock.unlock();

信号量
生产者消费者问题中出现。例如停车与离开
信号量为存储在redis中的一个数字,当这个数字大于0时,即可以调用acquire()方法增加数量,也可以调用release()方法减少数量,但是当调用release()之后小于0的话方法就会阻塞,直到数字大于0
tryAcquire()返回一个布尔型量,表示当前是否可以获取数量,如果数量为0,返回false。但是不会阻塞。常用于分布式限流
@GetMapping("/park")
@ResponseBody
public String park() {
RSemaphore park = redissonClient.getSemaphore("park");
try {
park.acquire(2);
} catch (InterruptedException e) {
e.printStackTrace();
}
return "停进2";
}
@GetMapping("/go")
@ResponseBody
public String go() {
RSemaphore park = redissonClient.getSemaphore("park");
park.release(2);
return "开走2";
}
缓存与数据一致性
在对表进行修改时,缓存中的内容也需要修改,可以采用两种模式来进行修改
-
双写模式:在写完数据库之后,再写缓存。
存在问题:会出现脏数据的问题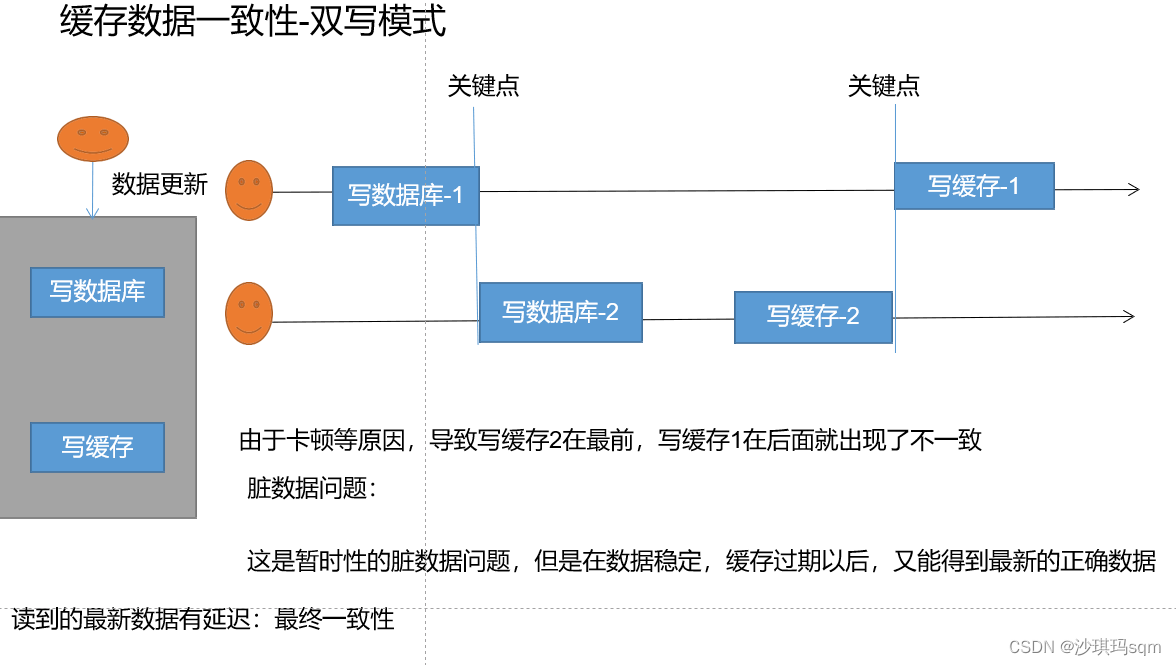
-
失效模式:再写完数据库,删除缓存中的数据,下次再读数据库
存在问题:也会产生脏数据
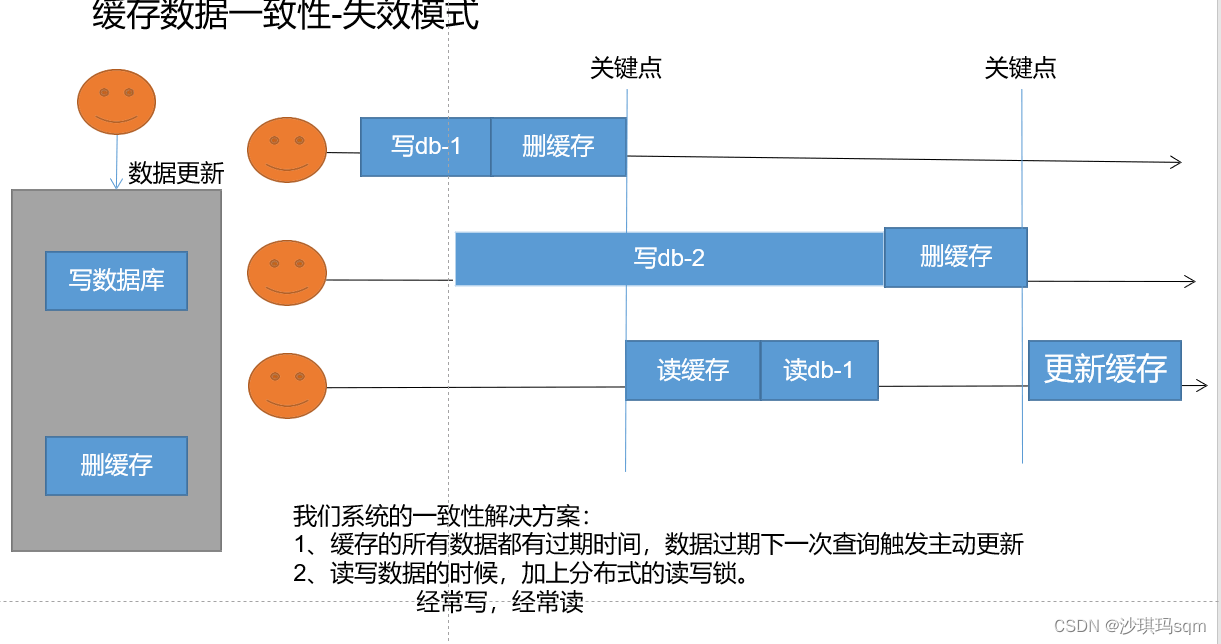
解决脏数据问题: -
设置过期时间,数据过期之后下一次重新查找数据库
-
读写数据时,加上分布式锁的读写锁,经常写经常读会对性能有影响
如果想要保证强一致性可以使用Canal
Canal相当于一个数据库的从库,业务更新数据库后,它会及时的修改缓存。

注意: 实时更新的数据、一致性要求高的数据本就不应该放到缓存中,缓存中加上过期时间保证每天拿到的数据是当前最新数据就可。遇到实时更新的数据、一致性要求高的数据就应该查找数据库。















 1668
1668











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









