mybatis 多个字段模糊匹配




于 2019-10-22 14:45:52 首次发布

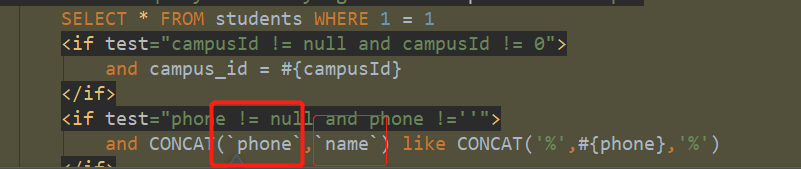
 博客主要围绕MyBatis多个字段模糊匹配展开,介绍了在MyBatis中实现多个字段模糊匹配的相关内容,涉及与MySQL数据库的交互应用。
博客主要围绕MyBatis多个字段模糊匹配展开,介绍了在MyBatis中实现多个字段模糊匹配的相关内容,涉及与MySQL数据库的交互应用。
博客主要围绕MyBatis多个字段模糊匹配展开,介绍了在MyBatis中实现多个字段模糊匹配的相关内容,涉及与MySQL数据库的交互应用。
博客主要围绕MyBatis多个字段模糊匹配展开,介绍了在MyBatis中实现多个字段模糊匹配的相关内容,涉及与MySQL数据库的交互应用。
 1898
711
1898
711

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言