









数据背景
作为“世界灭绝之都”,夏威夷已经失去了68%的鸟类物种,其后果可能会损害整个食物链。研究人员利用种群监测来了解本地鸟类对环境变化和保护措施的反应。但岛上的许多鸟类都被隔离在难以接近的高海拔栖息地。由于身体监测困难,科学家们转向了声音记录。这种被称为生物声学监测的方法可以为研究濒危鸟类种群提供一种被动的、低成本的、经济的策略。
目前处理大型生物声学数据集的方法涉及对每个记录的手工注释。这需要专门的训练和大量的时间。因此使用机器学习技能,通过声音来识别鸟类的种类,可以节约大量成本。具体来说,开发一个模型,可以处理连续的音频数据,然后从声音上识别物种。最好的条目将能够用有限的训练数据训练可靠的分类器。

数据介绍
数据集来源:https://www.kaggle.com/competitions/birdclef-2022/data
下载方式:https://github.com/Kaggle/kaggle-api
kaggle competitions download -c birdclef-2022
-
train_metadata.csv:为训练数据提供了广泛的元数据- primary_label -鸟类的编码。可以通过将代码附加到https://ebird.org/species/来查看有关鸟类代码的详细信息,例如美国乌鸦的代码添加到https://ebird.org/species/amecro
- secondary_labels: 记录员标注的背景物种,空列表并不意味着没有背景鸟的声音。
- author - 提供录音的eBird用户
- Filename:关联音频文件。
- rating: 浮动值在0.0到5.0之间,作为Xeno-canto的质量等级和背景物种数量的指标,其中5.0是最高的,1.0是最低的。0.0表示此记录还没有用户评级。
-
train_audio:大量的训练数据由xenocanto.org的用户慷慨上传的单个鸟类叫声的短录音组成。这些文件已被下采样到32khz,适用于匹配测试集的音频,并转换为ogg格式。 -
test_soundscapes:当您提交一个笔记本时,test_soundscapes目录将填充大约5500段录音,用于评分。每一个都是1分钟几毫秒的ogg音频格式,并只有一个音景可供下载。 -
test.csv:测试数据- row_id:行的唯一标识符。
- file_id:音频文件的唯一标识符。
- bird :一行的ebird代码。每个音频文件每5秒窗口有一排为每个得分物种。
- end_time:5秒时间窗口(5、10、15等)的最后一秒。
音频特征提取
特征提取是突出信号中最具辨别力和影响力的特征的过程。本文将引导完成音频处理中的一些重要特征提取,你可以将其扩展到适合的问题域的许多其他类型的特征。本文的其余部分只是一个生物技术学生的尝试,向你解释ta在过去几天能够理解的任何信号处理。
import os
import gc
import ast
import random
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
import seaborn as sns
from tqdm import tqdm
import torchaudio
import IPython.display as ipd
from collections import Counter
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import StratifiedKFold
from sklearn.metrics import f1_score
import torch
import torch.nn as nn
from torch.optim import Adam
import torch.nn.functional as F
from torch.utils.data import Dataset, DataLoader
from torchvision import models
import warnings
warnings.filterwarnings('ignore')
class config:
seed=2022
num_fold = 5
sample_rate= 32_000
n_fft=1024
hop_length=512
n_mels=64
duration=7
num_classes = 152
train_batch_size = 32
valid_batch_size = 64
model_name = 'resnet50'
epochs = 2
device = 'cuda' if torch.cuda.is_available() else 'cpu'
learning_rate = 1e-4
def seed_everything(seed):
random.seed(seed)
os.environ['PYTHONHASHSEED'] = str(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.backends.cudnn.deterministic = True
seed_everything(config.seed)
#读取数据
df = pd.read_csv('../input/birdclef-2022/train_metadata.csv')
df.head()

df.info()

df.describe()

分析Train_Metadata
plt.figure(figsize=(20, 6))
sns.countplot(df['primary_label'])
plt.xticks(rotation=90)
plt.title("Distribution of Primary Labels", fontsize=20)
plt.show()

plt.figure(figsize=(20, 6))
sns.countplot(df['rating'])
plt.title("Distribution of Ratings", fontsize=20)
plt.show()

df['type'] = df['type'].apply(lambda x : ast.literal_eval(x))
top = Counter([typ.lower() for lst in df['type'] for typ in lst])
top = dict(top.most_common(10))
plt.figure(figsize=(20, 6))
sns.barplot(x=list(top.keys()), y=list(top.values()), palette='hls')
plt.title("Top 10 song types")
plt.show()

分析音频文件
使用 Torchaudio(这是一个 PyTorch 的音频库)来处理音频数据
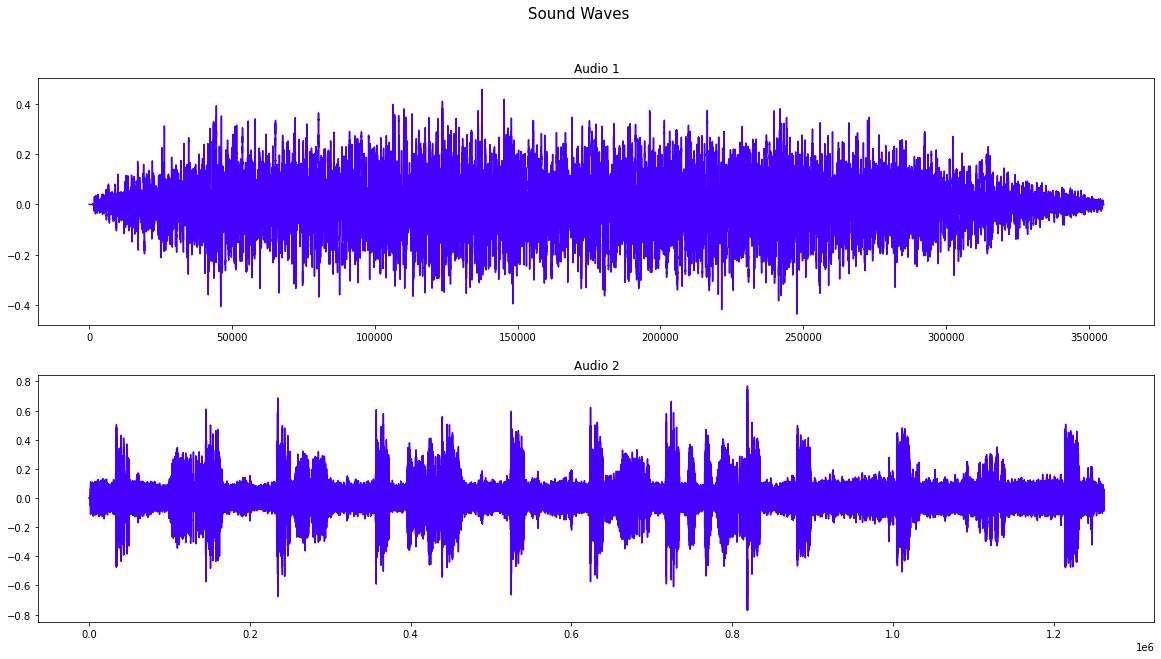
fig, ax = plt.subplots(2, 1, figsize=(20, 10))
fig.suptitle("Sound Waves", fontsize=15)
signal_1, sr = torchaudio.load(f"../input/birdclef-2022/train_audio/{filename_1}")
# The audio data consist of two things-
# Sound: sequence of vibrations in varying pressure strengths (y)
# Sample Rate: (sr) is the number of samples of audio carried per second, measured in Hz or kHz
sns.lineplot(x=np.arange(len(signal_1[0,:].detach().numpy())), y=signal_1[0,:].detach().numpy(), ax=ax[0], color='#4400FF')
ax[0].set_title("Audio 1")
signal_2, sr = torchaudio.load(f"../input/birdclef-2022/train_audio/{filename_2}")
sns.lineplot(x=np.arange(len(signal_2[0,:].detach().numpy())), y=signal_2[0,:].detach().numpy(), ax=ax[1], color='#4400FF')
ax[1].set_title("Audio 2")
plt.show()
数据预处理
由于我们的目标变量是字符串格式,因此将其转换为整数,这里我使用了 LabelEncoder 来执行
encoder = LabelEncoder()
df['primary_label_encoded'] = encoder.fit_transform(df['primary_label'])
skf = StratifiedKFold(n_splits=config.num_fold)
for k, (_, val_ind) in enumerate(skf.split(X=df, y=df['primary_label_encoded'])):
df.loc[val_ind, 'fold'] = k
模型输入是音频文件,但模型无法直接理解这些音频。 因此为了使用它们,我通过执行某种类型的特征提取技术将其转换为可理解的格式
特征提取
通常情况下提取的特征是图像的形式,然后使用它们来训练我们的模型,这里使用MelSpectrogram,这是一种将频率转换为梅尔标度的频谱图
fig, ax = plt.subplots(1, 2, figsize=(20, 7))
fig.suptitle("Mel Spectrogram", fontsize=15)
mel_spectrogram = torchaudio.transforms.MelSpectrogram(sample_rate=config.sample_rate,
n_fft=config.n_fft,
hop_length=config.hop_length,
n_mels=config.n_mels)
mel_1 = mel_spectrogram(signal_1)
ax[0].imshow(mel_1.log2()[0,:,:].detach().numpy(), aspect='auto', cmap='cool')
ax[0].set_title("Audio 1")
mel_2 = mel_spectrogram(signal_2)
ax[1].imshow(mel_2.log2()[0,:,:].detach().numpy(), aspect='auto', cmap='cool')
ax[1].set_title("Audio 2")
plt.show()
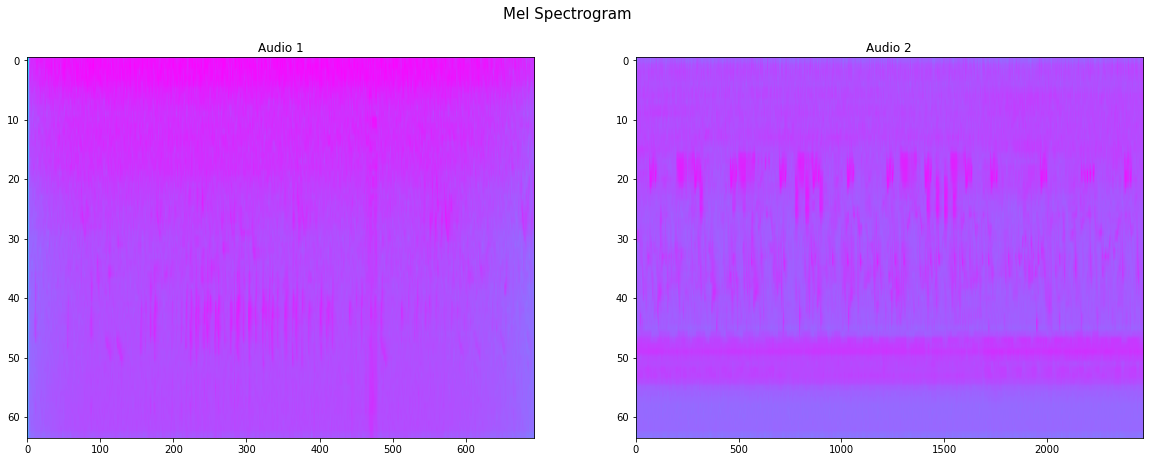















 1313
1313











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









