







中科院:面向非结构化文本的信息抽取
文章目录
导读:随着大数据、人工智能的发展,知识图谱相关技术越发成熟。其中,信息抽取又是构建高质量知识图谱的关键环节,对于知识图谱的应用具有重要意义。如何从非结构化文本中完成高质量的信息抽取,是我们一直以来都面临的难题之一。今天就我们在非结构化文本的信息抽取方面的工作同大家做一次交流汇报。本次分享题目是:面向非结构化文本的信息抽取:从封闭到开放。在本文中,我们将主要介绍:
- 信息抽取
- 抽取任务与挑战
- 关系抽取
- 联合抽取
- 开放抽取
01 信息抽取
1. 信息抽取概念

图1.1 信息抽取概念
首先,**什么是信息抽取?**定义如下:从自然语言文本中抽取实体、关系等事实信息,并形成结构化三元组<头实体,关系,尾实体>的技术。
信息抽取目标是让互联网上的海量信息机器可读,为正确决策提供大量的相关知识。
信息抽取应用,包括知识图谱构建与补充、自动机器问答、信息检索、辅助决策。例如图1.1(右下)展示的AliCoCo电商图谱。
2. 信息抽取任务形式
信息抽取任务通常可由关系集合是否给定分为封闭信息抽取和开放信息抽取两大类。其中,封闭信息抽取又根据实体对是否给定分为关系抽取(分类)和实体关系联合抽取两类。今天我们的分享主要聚焦在关系抽取 、实体关系联合抽取和开放信息抽取。

图1.2 信息抽取任务形式
从图1.2可以看到这三种信息抽取形式上的区别。对输入文本“鲍卡斯与曼斯菲尔德都来自蒙大拿州”,在关系抽取任务中,关系集合是事先预置的封闭集合,给定头实体“鲍卡斯”和尾实体“蒙大拿州”,可抽取到头尾实体的关系是“come-from”,形成三元组(鲍卡斯, come-from, 蒙大拿州);在实体关系联合抽取中,关系集合也是事先预置的封闭集合,但头尾实体不给定,可直接抽取到三元组(鲍卡斯, come-from, 蒙大拿州)、(曼斯菲尔德, come-from, 蒙大拿州);在开放信息抽取中,关系集合是无需事先预置,是开放的,(鲍卡斯,来自, 蒙大拿州)、(曼斯菲尔德, 来自, 蒙大拿州)均是从输入文本抽取出来的三元组。
02 抽取任务与挑战
1. 关系抽取任务与挑战
关系抽取通常建模为给定目标实体对下的文本分类问题,其挑战在于设计模型关注能决定目标实体对的语义关系的片段,并降低噪声的影响。

图2.1 关系抽取模型
在这一段文本的关系抽取当中,由于“担任“这一词的存在,会对三元组的抽取带来干扰,即噪声影响。我们的重点在于“来自”而非“担任”。
2. 联合抽取任务与挑战
对于联合抽取来说,给定关系集合,但不给定实体对,联合抽取需要从输入文本中直接抽取三元组,其挑战在于解决不同三元组间的重叠问题,包括单实体重叠和实体对重叠。

图2.2 联合抽取模型-例1

图2.3 联合抽取模型-例2
如图2.2和2.3所示,第一个示例包含尾实体重叠和头实体重叠,第二个示例既有尾实体的重叠,也有实体对的重叠。所以如何解决这种重叠问题,也是面临的难题之一。
3. 开放抽取任务与挑战
对于开放式的抽取任务,输入的只有一个句子,没有关系集合、没有实体对,所以,开放抽取是信息抽取中最复杂的任务,需要对头实体、关系、尾实体三要素进行配对,并且面向开放场景需要具有良好的领域适应能力

图2.4 开放抽取模型
开放信息抽取面临很多很多的场景需要处理,其一,实体和关系短语可能不连续,如图2.4中尾实体包括了两个片段要素;其二,实体(关系短语)存在重叠甚至部分重叠的情况,如上图中两个三元组的尾实体存在要素重叠,关系短语完全重叠。面对这样的复杂关系,高质量的信息抽取十分困难。
针对以上的问题,下面介绍一下我们近期的工作。主要探讨一下已发表的一些论文,希望可以在关系抽取、联合抽取、开放抽取方面取得更大进展。
03 关系抽取
在将要介绍的关系抽取中,主要涉及如下两篇论文:
- Beyond Word Attention: Using Segment Attention in Neural Relation Extraction. IJCAI 2019
- From What to Why: Improving Relation Extraction with Rationale Graph. Findings of ACL 2021
1. 基于片段注意力机制的关系抽取
① 问题与动机

图3.1 关系抽取
给定输入文本以及文本中被标出的两个实体,关系抽取模型预测得到这两个实体间的语义关系,具体做法是输出预定义关系集合中每个关系的概率,概率越高,说明两个实体间存在对应关系的可能性越大。
以图3.1为例,其中的柱状图表示了关系的概率。“鲍卡斯”和“蒙大拿州”之间的关系应该是come-from,但是可以看到关系job的概率也很高,原因文本中存在“后者担任每个驻日大使”这个片段,它描述了job,但是对应的是实体对“曼斯菲尔德”和“美国驻日大使”,而非关注的“鲍卡斯”和“蒙大拿州”,所以关系抽取任务的挑战在于设计模型关注目标实体对间的语义关系,并过滤句子中其他关系的噪声。
引入注意力机制是解决这一挑战的主流思路。基于注意力机制的关系抽取方法为每个词项单独计算与目标实体的相关性得分,并进行归一化,最后对所有词项的表示加权求和,作为实体对的语义关系表示。然而,这种单独计算每个词项重要性的方式忽略了一个重要的现象,那就是关系的描述往往是以片段形式存在而不是分散在文本中。再回到上图所示例子,其中两个关系描述“来自”和“担任”都是以片段形式存在的,单独建模每个词的重要性可能会导致遗漏关系片段内的部分词。所以很自然想到,能不能做这样一个工作,使得其基于片段的形式,而不只是简单的基于每个词的形式去调整其相关性得分。
② 研究思路
现有方法单独计算每个词项的重要性而忽略关系描述呈片段分布的特点,我们将条件随机场引入注意力机制,隐式建模关系描述词之间的依赖关系。提出转移正则项和稀疏正则项,约束模型关注连续的关系描述片段。

图3.2 条件随机场中引入注意力机制
下图可以看到对每个函数给出的一个公式,以及对两个正则项的说明。

图3.3 转移正则项和稀疏正则项应用于关系抽取
转移正则项是希望相同状态的转移得分大于不同状态的转移得分,使得相邻词项的状态更一致,从而产生片段。稀疏正则项,希望减少被选中的作为关系描述的词项数量。
下图是我们的实验结果。在关系抽取的公认数据集TACRED上,相比于单独计算注意力得分的PA-LSTM,我们的片段注意力机制在准确率和召回率上均有较大的提升。注意力分布的可视化分析表明我们的方法的确可以关注到连续的片段而非单个的词。

图3.4 实验结果
2. 全局理据增强的神经关系抽取

图3.5 指示信息和关系理据
① 指示信息
在关系抽取任务中,实体类型和关系触发词是人类进行关系判断的重要理据,如图3.5第一部分所示,我们在判断关系时首先注意到的是这两个实体都是“人”,并且句子中出现了“children”这个单词,那么我们的第一反应就是这两个实体之间存在父子关系。然后再根据句子语义判断具体的关系。
② 关系理据
实体类型和关系触发词就是关系表达中最具有指示性的信息,并且与关系标签之间存在很强的约束和对应关系。然而,只根据一个句子很难得到这种完整的信息,纵观整个数据集,我们就会发现实体类型和关系触发词通常和特定的关系标签共同出现,并且呈现出一定的概率分布,而这种概率分布正是人在看到这些指示性信息时的第一印象。
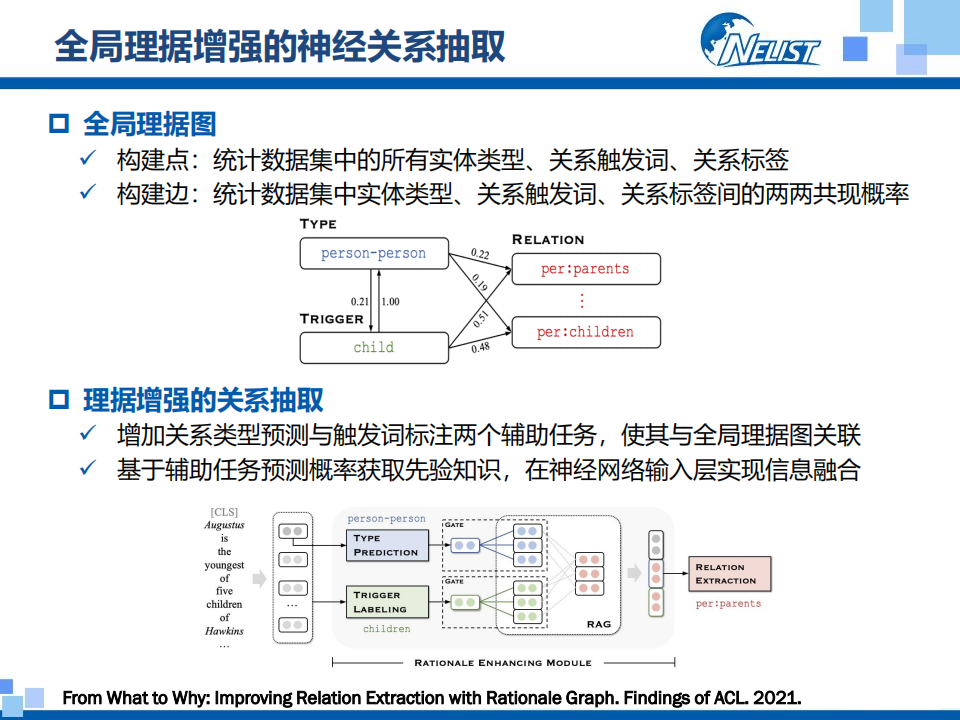
图3.6
③ 全局理据图
基于这一观察,我们统计数据集并构造全局指示特征图来组织实体类型、关系触发词、关系标签之间的全局共现概率,得到两两间的约束和对应关系。

图3.7 理据增强的关系抽取
④ 理据增强的关系抽取
为了将这种全局先验特征知识与现有的神经网络相结合,我们提出实体类型和关系触发词预测两个辅助任务,依据预测结果从全局指示特征图中获取关系指示特征与关系标签之间的先验概率,使用输入文本和图神经网络来更新全局指示特征图中的节点表示,最终基于映射概率对图中的关系节点进行加权,在神经网络的输出层实现知识聚合来提升关系抽取模型性能。不同于传统方法,我们提出的模型不仅能够实现关系预测,同时也能够给出与关系判断相关的指示特征。

图3.8
⑤ 篇章级关系抽取(DialogRE)
我们的第一个实验在DialogRE数据集上进行。这也是目前关系抽取领域唯一同时标注触发词和实体类型的数据集。我们的方法取得了很好的结果。
⑥ 句子级关系抽取(TACRED/V,20%额外标注)
我们也在关系抽取任务的基准数据集TACRED上进行了实验,TACRED数据集具有实体标注类型而没有触发词标注。这里我们对其中约20%的数据人工标注了触发词。
⑦ 标注数量分析(DialogRE)
我们还分析了使用不同数量的理据标注数据对最终结果的影响,可以看到,在标注数据很少的情况下,这种全局指示特征增强的方法能够取得极大的性能提升,同时对于一个任意的现有关系抽取数据集,我们只为部分数据标注理据信息来即插即用地提升模型性能。
⑧ 样例分析
通过样例分析可以发现,模型不只是能够输出实体之间是什么关系,还能够解释这两个实体之间为什么是这个关系。
04 联合抽取
在联合抽取中,主要介绍如下两篇论文:
- Joint Extraction of Entities and Relations Based on a Novel Decomposition Strategy. ECAI 2020
- TPLinker: Single-stage Joint Extraction of Entities and Relations Through Token Pair Linking. COLING 2020
相比于关系抽取,实体关系联合抽取不要求给定实体对,而是从文本中直接抽取三元组,其中关系类型来自预先定义的集合。因为不需要指定实体对,所以一段文本中可能会抽取得到多个三元组,不同的三元组彼此重叠。如图4.1所示的例子中,前两个三元组共享尾实体“蒙大拿州”,后两个三元组共享头实体“曼斯菲尔德”,这就造成了单实体重叠。

图4.1 单实体重叠
图4.2例子中的重叠情况更加复杂,后两个三元组的头尾实体都一致,也就是实体对重叠。单实体重叠和实体对重叠的情况在自然语言文本中出现频繁,如果不能准确识别,将会极大影响抽取的召回率,所以解决不同三元组的重叠问题是实体关系联合抽取任务的主要挑战。

图4.2 实体对重叠
针对这一挑战,主流的解决思路是序列标注,将实体在三元组中的角色及实体间的关系编码在标注标签中,代表性工作是NovelTagging。
NovelTagging用BIEOS标签来指代实体的位置,B表示实体的开始,E表示实体的结束,将关系类型融入标签中,如图4.3中的CF标签指代该实体参与了come-from为类型的关系,用1和2表示实体在三元组中的角色,1是头实体,2是尾实体。这样的标注方法巧妙地实现了联合抽取,但是它要求每个词只能有一个标签,参与一个三元组,所以无法解决三元组重叠的问题。
输入文本:鲍卡斯来自蒙大拿州,担任驻日大使

图4.3 NovelTagging
1. 头实体->尾实体关系之ETL
为了解决联合抽取任务中现有基于序列标注的方法未能考虑头实体,关系和尾实体间的交互,导致无法识别重叠三元组的问题,提出对联合抽取进行任务分解:先抽取头实体,再为每个头实体标注尾实体和关系。为了同时标注尾实体和关系,提出将关系类型和尾实体的位置标签相融合,识别尾实体的同时确定关系。
输入文本:故宫博物院坐落于中国首都北京

图4.4 ETL
以图4.4为例,首先进行头实体标注,得到两个头实体“故宫博物院”和“中国”,再为“故宫博物院”和“中国”分别标注尾实体和关系,对于“故宫博物院”来说,“北京”参与了关系类型为Located-In的三元组,所以“北京”的标签是LI。这样的任务分解策略为输入文本标注2+2个序列,是文本中头实体的个数。通过任务分解,能够解决单实体重叠的问题,但是对于实体对重叠的情况,比如“中国”和“北京”之间有两种关系,则无法完成。此外,ETL将联合抽取分解为头实体抽取和尾实体-关系抽取两个级联的子任务,存在任务间的曝光偏差和级联误差。
2. 关系/实体解耦之TPLinker
为了解决实体对重叠三元组的抽取问题,同时克服曝光偏差和级联误差的影响,提出将联合抽取建模为给定关系类型下的单阶段头尾实体边界匹配任务。包含独立的两部分,首先是实体识别,构建二维矩阵标注实体的开始位置和结束位置,比如“故宫博物院”是一个实体,那么在二维表格中“故”对应的行和“院”对应的列的交叉点有标注。

图4.5 实体识别
然后对于每种关系构建二维标注矩阵,比如图4.6对应的是Located-In关系的三元组标注结果,文本中的“故宫博物院”和“北京”两个实体参与了一个类型为Located-In的三元组,那么头实体的开始词“故”和尾实体的开始词“北”在表格中的交点位置标注为一对实体的开始位置,同样,头实体的结束词“院”和尾实体的结束词“京”的交点位置标注为一对实体的结束位置。通过这种方式可以解码得到参与Located-In关系的一对实体。

图4.6 关系识别(located-in)
如图4.7所示,不同关系类型的头尾实体匹配标注相互独立,因此具有不同关系类型的同一实体对可以被同时抽取,解决了实体对重叠的问题。

图4.7 关系/实体解耦之TPLinker
3. 实验结果

图4.8 关系/实体解耦之TPLinker实验结果
05 开放抽取
在开放抽取中,主要介绍如下两篇论文:
- Semi-Open Information Extraction. WWW 2021
- Maximal Clique Based Non-Autoregressive Open Information Extraction. EMNLP 2021
1. 基于面向特定目标实体的开放抽取
首先,思考这样一个问题:三元组的开放抽取是否适用于任何场合呢?

图5.1
如果说这里我们需要关注邪教这个实体或者概念,那么我们就需要一个模型或技术从互联网文本信息中抽取出来,就是我们这里定义的半开放信息抽取任务:给定头实体,从文本中抽取对应的关系短语和尾实体。
我们面向8013个头实体标注24000个中文句子,包含61984个三元组。

图5.2
我们对半开放信息抽取任务进行任务分解:编码器得到关于目标实体的文本表示,抽取任务分解为关系短语抽取、尾实体抽取和边界对齐三个独立的子任务。

图5.3

图5.4

图5.5
2. 基于极大团查找的非自回归式开放抽取方法
在介绍基于极大团查找的非自回归式开放抽取主题之前,先介绍一下IGL-OIE和IMoJIE这两种抽取方法。
- IGL-OIE
输入文本:豫园建造于明朝嘉靖和万历年间

图5.6
- IMoJIE
输入文本:豫园建造于明朝嘉靖和万历年间

图5.7
但以上两种抽取方法都先指定了三元组的顺序。
思考:三元组的有序生成真的合理吗?
- IGL-OIE的生成顺序
输入文本:豫园建造于明朝嘉靖和万历年间

图5.8
- IMoJIE方法的生成顺序
有两种生成方式,可以是先生成嘉靖再生成万历,也可以先生成万历再生成嘉靖。

图5.9
三元组之间不应存在顺序,所以我们希望建一个非自回归式开放抽取,不要求指定三元组顺序。
为了实现头实体、关系短语、尾实体三者的准确配对,同时克服以往自回归式抽取模型中的曝光偏差和级联误差问题,提出将开放抽取建模为由三元组要素构建的事实图上的极大团查找问题,利用二维的边界对齐矩阵构建三元组要素间的连边。采用图论的思想解决开放抽取。比如在下面的图5.10所示的输入文本中有两个三元组,为这样的文本构建了一个事实图,图中的节点是三元组中的头实体、关系短语和尾实体中的片段,比如“建造于”,“豫园”,“明朝”,“明朝嘉靖”和“年间”,节点间的连边表示他们参与了同一个三元组。可以直观地发现,一个三元组的所有元素构成了一个极大团,也就是节点之间两两连边,并且从图中加入任意一个节点都会打破这样的两两连边性质,所以开放信息抽取可以转化为事实图上的极大团查找问题,这样的任务转化实现了单阶段的三元组抽取,不同的三元组的抽取之间没有相互关联性,避免了级联误差和曝光偏差。

图5.10 极大团查找
我们将建图的过程分解为两个子任务:片段识别得到图中所有节点,连边预测找到图中所有连边。

图5.11 极大团查找-建图
片段识别的二维矩阵比较简单,构建二维矩阵标注片段的开始位置和结束位置,比如“豫园”是一个三元组中的片段,那么在二维表格中“豫”对应的行和“园”对应的列的交叉点有标注。

图5.12 极大图查找——片段识别
关系的话相对复杂,我们定义了9种关系。通过这些关系,我们就知道了每个片段对之间应该是什么样的结果。二维标注的每个cell都有两个标签,分别是位置标签和类别标签。比如“豫园”和“建造于”分别是一个三元组的头实体和关系短语,所以“豫”和“建”交叉的位置上有两个标签,分别是“片段开始-片段开始”和“头实体-关系短语”。“园”和“于”交叉的位置上也有两个标签,分别是“片段结束-片段结束”和“头实体-关系短语”。通过这样的交叉匹配,我们就可以还原得到图中的所有连边。

图5.13 极大图查找——连边生成

图5.14 极大团查找性能得分
通过片段识别和连边预测的二维矩阵,还原出来最大团的算法,找出最终结果。以上是在OpenIE4和SAOKE两个数据集上计算的结果。可以看出我们的方法可以得到很好的结果。
06 总结
以上就是对关系抽取、联合抽取、开放抽取的介绍。信息抽取作为构建知识图谱中重要的环节,其意义不言而喻。要想更进一步提高信息抽取的能力,还需要做更深入的研究。有关上述报告的更多详细内容,可查阅文中所提到的数篇论文。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









