







【Arxiv 大模型最新进展】打破选择困局:多智能体带你高效选择预训练数据
🌟 嗨,你好,我是 青松 !
🌈 自小刺头深草里,而今渐觉出蓬蒿。
NLP Github 项目推荐:
-
【AI 藏经阁】:https://gitee.com/fasterai/ai-e-book
介绍:该仓库主要分享了数百本 AI 领域电子书
-
【AI 算法面经】:fasterai/nlp-interview-handbook#面经
介绍:该仓库一网打尽互联网大厂NLP算法面经,算法求职必备神器
-
【大模型(LLMs)面试笔记】:https://gitee.com/fasterai/nlp-interview-handbook
介绍:该仓库汇总了 NLP 算法工程师高频面题,适合大模型初学者和正在准备面试的小伙伴希望能帮助各位同学缩短面试准备时间,不错过金三银四涨薪窗口,迅速收获心仪的Offer 🎉🎉🎉
Multi-Agent Collaborative Data Selection for Efficient LLM Pretraining
作者:Tianyi Bai, Ling Yang, Zhen Hao Wong, Jiahui Peng, Xinlin Zhuang, Chi Zhang, Lijun Wu, Jiantao Qiu, Wentao Zhang, Binhang Yuan, Conghui He
单位: Hong Kong University of Science and Technology, Shanghai AI Laboratory, Peking University
下图给出此文的整体逻辑框架。首先,对文章进行一句话总结,然后简要介绍研究内容、研究动机、技术动机、解决方案以及优势与潜力,以便读者快速了解文章脉络。
方案详解
本文提出了一种多智能体协同数据选择框架,旨在通过动态结合多种数据选择方法,提升大规模语言模型预训练中的数据选择效率。该框架通过将每种数据选择方法作为一个独立的智能体,并由一个名为“智能体控制台”的模块来整合各个智能体,从而得出最优的数据选择策略。
当前各种预训练数据选择方案往往各自独立,并且相互之间存在着个有冲突,例如高质量数据不一定对模型有显著影响、高质量数据往往缺乏话题多样性等等。但是在优化数据选择时,单纯追求某一特性(如高质量或高话题多样性)可能无法达到最优效果。因此,如何整合不同的数据选择方法,在动态预训练过程中平衡各个维度的需求非常重要。
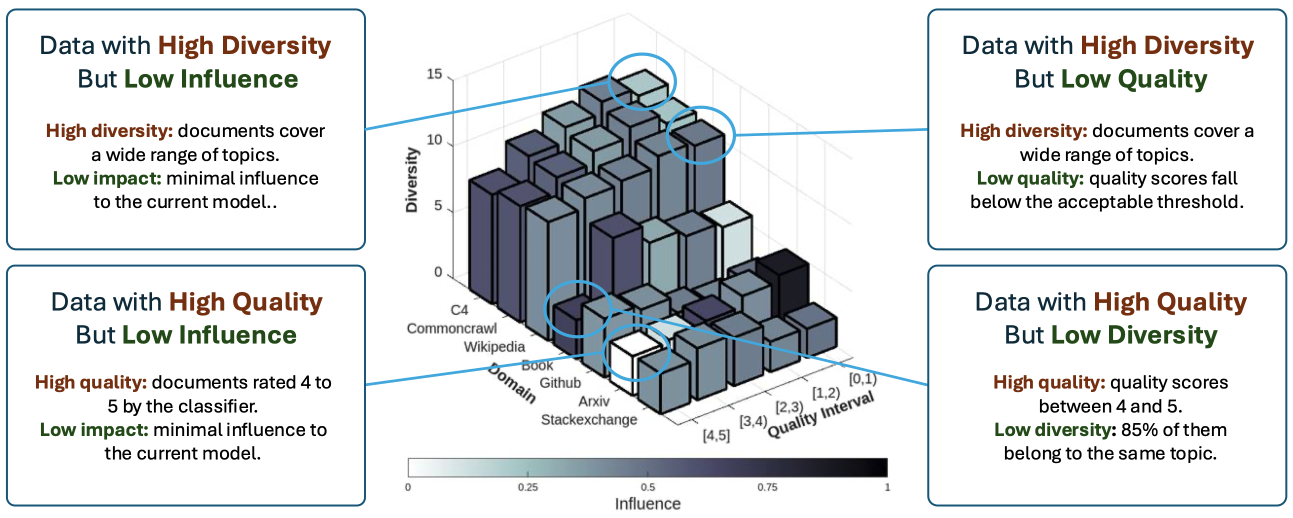
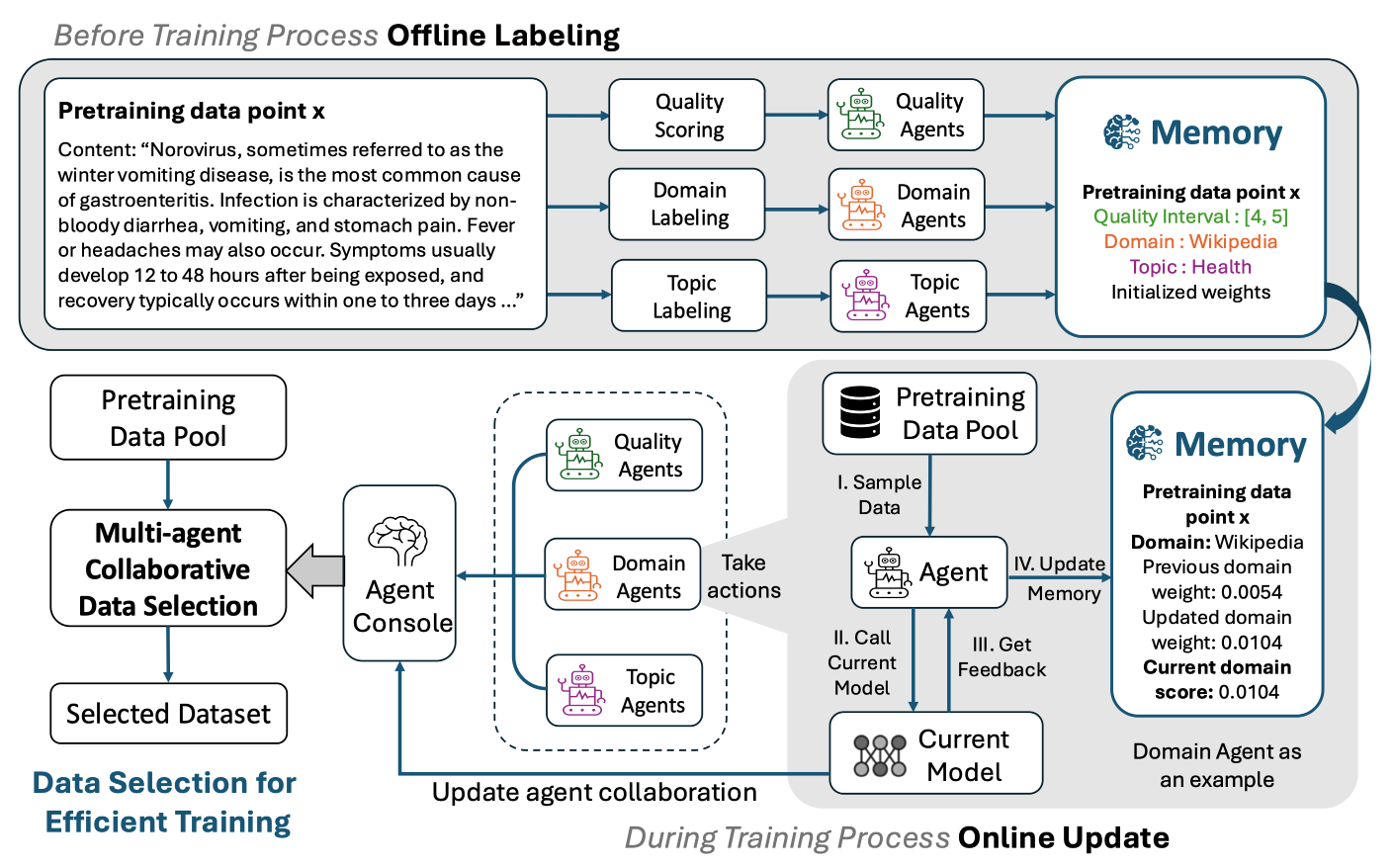
该方法为了整合这些冲突的数据选择方案,将每种方法作为一个独立的智能体,每个智能体基于其特定的数据属性(如数据质量、话题多样性和领域)对预训练数据进行评分。在训练过程中,这些智能体通过不断对数据进行分析并生成评分,最后由一个名为“智能体控制台”的模块来整合各个智能体的评分结果,最终得出最优的数据选择策略。
该方法的核心机制分为两个阶段:离线标注阶段和在线更新阶段。
- 在离线标注阶段,整个训练数据集被预先标注,智能体根据预训练数据集的质量、领域、话题等特征进行分类,并将这些标注存储在各自的记忆中。
- 在在线更新阶段,随着模型的训练进展,每个智能体会根据模型的反馈动态调整其内部权重,以提升数据选择效果。每个智能体对数据点进行独立的分析和评分,然后这些评分会经过智能体控制台的整合,产生最终的数据选择结果。
与此同时,框架中的“智能体控制台”模块会利用反馈机制来对各个智能体本身的权重进行调整,增加那些在提升模型表现上贡献较大的智能体的权重,减少贡献较小的智能体的影响。这样能够确保在训练的不同阶段,数据选择始终能最大化地促进模型的性能提升。此外,通过离线标注的数据特征记忆和在线调整的结合,框架能够实现更加灵活和高效的选择过程。
该多智能体框架的创新之处在于它解决了不同数据选择策略之间的固有冲突问题。不同的数据选择方法(如质量优先、话题多样性优先或领域特定的数据选择方法)往往在如何评估和优先排序数据方面存在冲突,而通过该框架的协作机制,可以有效结合这些冲突的策略,达到更优的选择结果。通过智能体之间的协作,框架能够有效平衡数据的质量、话题多样性和领域覆盖等因素,最终显著提升了数据选择的效率和模型训练的收敛速度。
实验结果
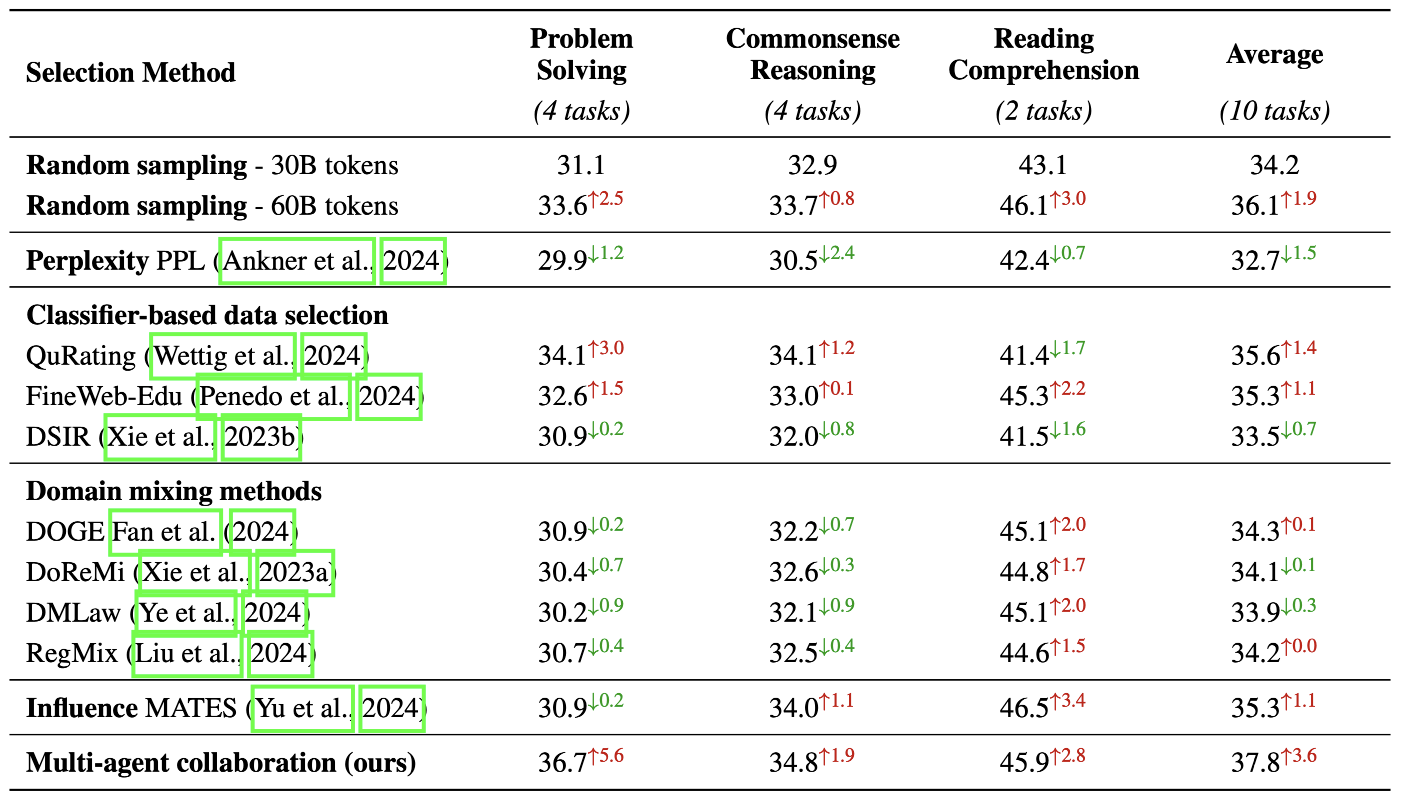
实验结果表明,与其他最先进的方法相比,多智能体协同框架在多个基准测试中显著提高了数据选择效率,并在提升预训练模型性能方面表现出色,平均性能提升达10.5%。这种框架在保持高效数据选择的同时,降低了计算开销,展现了其在大规模模型预训练中的巨大潜力。
- 原文链接: https://arxiv.org/pdf/2410.08102
- 撰稿:李佳晖



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









