







【剑指offer】两个链表的第一个公共节点
题目描述为leetcode
编写一个程序,找到两个单链表相交的起始节点。
如下面的两个链表:

在节点 c1 开始相交。
示例 1:

输入:intersectVal = 8, listA = [4,1,8,4,5], listB = [5,0,1,8,4,5], skipA = 2, skipB = 3
输出:Reference of the node with value = 8
输入解释:相交节点的值为 8 (注意,如果两个列表相交则不能为 0)。从各自的表头开始算起,链表 A 为 [4,1,8,4,5],链表 B 为 [5,0,1,8,4,5]。在 A 中,相交节点前有 2 个节点;在 B 中,相交节点前有 3 个节点。
示例 2:

输入:intersectVal = 2, listA = [0,9,1,2,4], listB = [3,2,4], skipA = 3, skipB = 1
输出:Reference of the node with value = 2
输入解释:相交节点的值为 2 (注意,如果两个列表相交则不能为 0)。从各自的表头开始算起,链表 A 为 [0,9,1,2,4],链表 B 为 [3,2,4]。在 A 中,相交节点前有 3 个节点;在 B 中,相交节点前有 1 个节点。
示例 3:
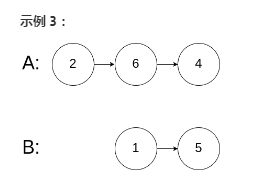
输入:intersectVal = 0, listA = [2,6,4], listB = [1,5], skipA = 3, skipB = 2
输出:null
输入解释:从各自的表头开始算起,链表 A 为 [2,6,4],链表 B 为 [1,5]。由于这两个链表不相交,所以 intersectVal 必须为 0,而 skipA 和 skipB 可以是任意值。
解释:这两个链表不相交,因此返回 null。
注意:
如果两个链表没有交点,返回 null.
在返回结果后,两个链表仍须保持原有的结构。
可假定整个链表结构中没有循环。
程序尽量满足 O(n) 时间复杂度,且仅用 O(1) 内存。
1.暴力解法。
从头开始遍历第一个链表,遍历第一个链表的每个节点时,同时从头到尾遍历第二个链表,看是否有相同的节点,第一次找到相同的节点即第一个交点。若第一个链表遍历结束后,还未找到相同的节点,即不存在交点。时间复杂度为O(m*n)。
2.借助外部空间
如果两个链表有公共结点,那么公共结点出现在两个链表的尾部。如果我们从两个链表的尾部开始往前比较,最后一个相同的结点就是我们要找的结点。But,在单链表中只能从头结点开始按顺序遍历,最后才能到达尾结点。最后到达的尾结点却要最先被比较,这是“后进先出”的特性。于是,我们可以使用栈的特点来解决这个问题:分别把两个链表的结点放入两个栈里,这样两个链表的尾结点就位于两个栈的栈顶,接下来比较两个栈顶的结点是否相同。如果相同,则把栈顶弹出接着比较下一个栈顶,直到找到最后一个相同的结点
public static ListNode FindFirstCommonNode(ListNode head1,ListNode head2) {
if(head1 == null || head2 == null){
return null;
}
Stack<ListNode> stack1 = new Stack<ListNode>();
Stack<ListNode> stack2 = new Stack<ListNode>();
while(head1 != null) {
stack1.push(head1);
head1 = head1.next;
}
while(head2 != null) {
stack2.push(head2);
head2 = head2.next;
}
ListNode node1 = null;
ListNode node2 = null;
ListNode common = null;
while(!stack1.isEmpty() && !stack2.isEmpty()) {
node1 = stack1.peek();
node2 = stack2.peek();
if(node1 == node2) {
common = node1;
stack1.pop();
stack2.pop();
}
else {
break;
}
}
return common;
}
public static void main(String[] args) {
ListNode node1 = new ListNode(1);
ListNode node2 = new ListNode(2);
ListNode node3 = new ListNode(3);
ListNode node4 = new ListNode(4);
ListNode node5 = new ListNode(5);
ListNode node6 = new ListNode(6);
ListNode node7 = new ListNode(7);
// first
node1.next = node2;
node2.next = node3;
node3.next = node6;
node6.next = node7;
// second
node4.next = node5;
node5.next = node6;
ListNode res = FindFirstCommonNode(node1,node4);
System.out.println(res.val);
}
在上述思路中,我们需要用两个辅助栈。如果链表的长度分别为m和n,那么空间复杂度是O(m+n)。这种思路的时间复杂度也是O(m+n)。和最开始的蛮力法相比,时间效率得到了提高,相当于是用空间消耗换取了时间效率。
3.不借助外界空间
我们可以首先遍历两个链表得到它们的长度,就能知道哪个链表比较长,以及长的链表比短的链表多几个结点。在第二次遍历的时候,在较长的链表上先走若干步,接着再同时在两个链表上遍历,找到的第一个相同的结点就是它们的第一个公共结点。
public static ListNode FindFirstCommonNode(ListNode head1,ListNode head2) {
//得到两个链表的长度
int len1 = GetListLength(head1);
int len2 = GetListLength(head2);
int diff = len1 - len2;
ListNode headLong = head1;
ListNode headShort = head2;
if(diff < 0) {
headLong = head2;
headShort = head1;
diff = len2 - len1;
}
//现在长链表上走几步
for (int i = 0; i < diff; i++) {
headLong = headLong.next;
}
//同时在两个链表遍历
while(headLong != null && headShort != null && headLong != headShort) {
headLong = headLong.next;
headShort = headShort.next;
}
ListNode commonNode = headLong;
return commonNode;
}
private static int GetListLength(ListNode head) {
int len = 0;
ListNode tempNode = head;
while(tempNode != null) {
tempNode = tempNode.next;
len++;
}
return len;
}
时间复杂度是o(m),m代表最长链表的长度














 1115
1115











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









