







文章目录
前言
官方的架构图太过简单,没有具体的交互细节。为此,我花了一个下午时间梳理了一下详细一点的spark的运行流程架构图,然后想了个通俗易懂的比喻来拟合它们之间的关系:
一、架构图
总体架构图如下
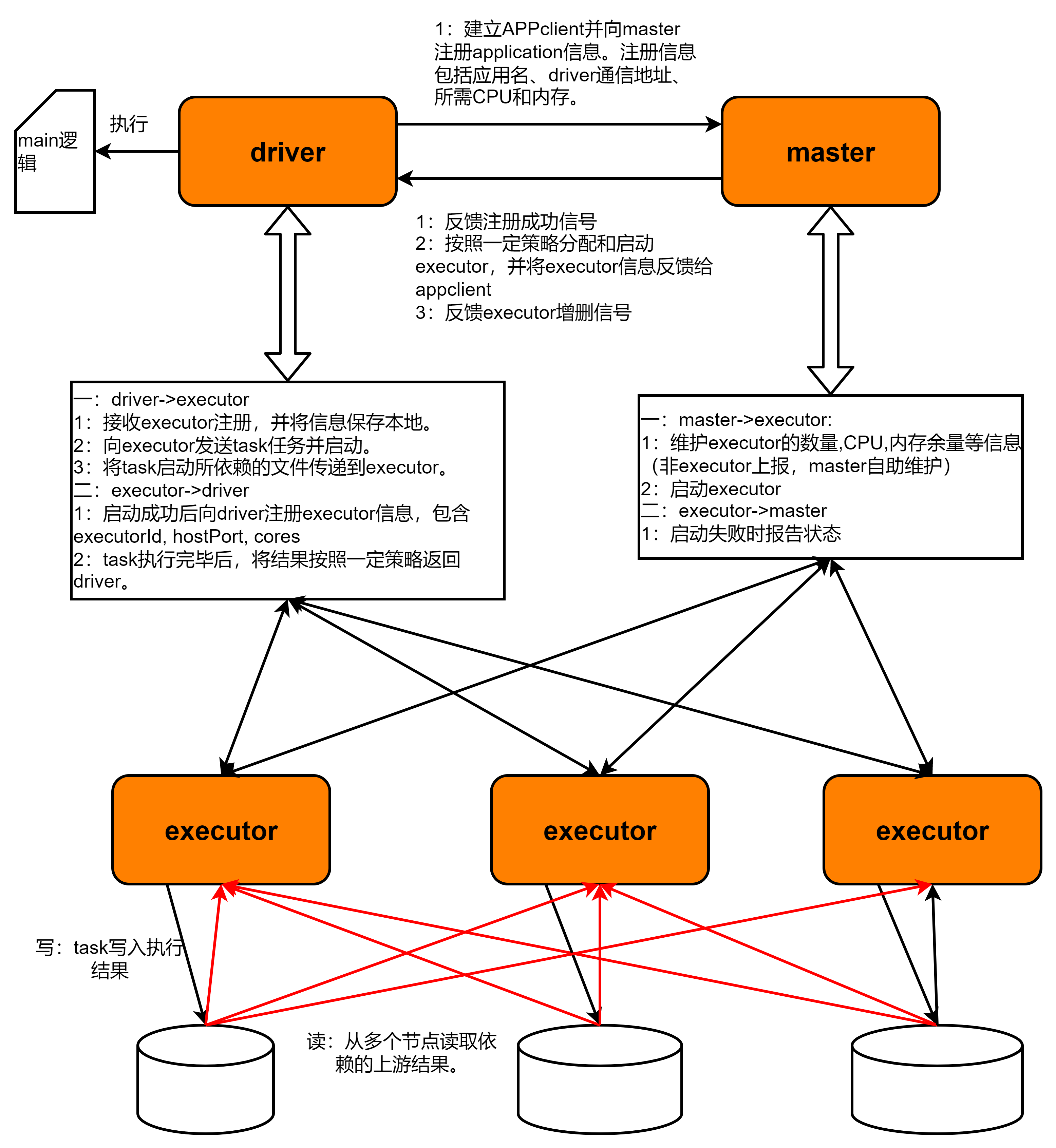
二、解释
1.主要组件及主要作用
主要由如下组件:
- driver:相当于是个项目经理,客户提交的任务后(即spark-submit xxxx),它会做具体的交付计划。它首先会把用户任务里每个需要交付的环节(即spark里面的action动作)给独立为一个项目来管理(即拆分job),每个项目(job)又可以拆分成n个实施阶段(stage),每个实施阶段再拆分成若干并行的任务(task),这些task任务可以同步执行,不相干扰。直到某个任务必须由多个施工队一起协作配合才能完成(即需要shuffle),这时就得进入下一个stage了。driver只负责主导和跟踪项目的运行流程,不负责具体的干活。那谁来干活呢,它会找外包公司的老板(即集群管理器里的master节点)申请分配若干施工队来干活。老板会按需求给它施工队的名单(即可供调度的executor列表)。它把施工队信息保存下来,然后将Task分发给各个施工队去干活。安排之后会跟踪各个施工队的进展和执行结果。用技术语言来描述的话,就是driver上负责运行用户main函数逻辑。main里面会启动SparkSession或SparkContext,它们都可以与spark集群管理器进行连接。它首先会在集群管理器上注册自己的应用信息,然后申请和保存executor资源列表。之后会把用户的任务拆分成若干job,每个job里面又根据宽依赖和窄依赖,拆分成不同的stage,stage里面又拆分成若干个可以并行计算的task。然后按顺序把task发放到executor里去执行,并跟踪进展和获取结果。driver根据deploy-mode参数的设置,可以在提交spark任务的client机器上运行,也可以由spark集群安排某个节点上运行。
- master:即集群管理器的主节点,可以比喻为外包公司的老板。它手头有公司施工人员的名单和剩余人力(即集群CPU和内存的剩余容量)。它接收项目经理的申请和注册,同时按照项目经理的需求组织起施工队队伍(即分配CPU和内存,然后启动executor进程)。然后把施工队id等信息给到项目经理,同时把项目经理的联系方式给施工队。用技术语言来描述即是,它一方面接收用户应用的注册,另一方面管理和维护着集群里各个worker节点的CPU和内存配额。然后分配资源和启动各个executor。并把executor的信息返回给driver节点。
- executor:即施工队,是干活的人。它由集群管理器的master节点启动起来后,它的信息就会被发送到项目经理那里。然后就等待接收项目经理(driver)的调度。项目经理会在合适的时机给他派活(task),告诉它这个task的执行需要什么条件,然后需要返回什么结果。executor会按照指示,从各个地方拉取数据完成依赖条件,然后执行计算任务,最终按照一定策略把计算结果返回给driver。因此,driver和executor会存在大量的数据交互。如果提交的客户端与各个executor的网络环境不好,那最好就选择cluster的deploy-mode,让driver运行在集群里。
总结
本文用通俗易懂的比喻来描述spark运行架构里面各个组件的主要作用和大致交互的逻辑,希望对读者们能有所帮助。如有错漏,还望指出。















 1872
1872











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









