




 本文指导如何在一台仅有一块GPU的电脑上解决PyTorch分布式训练时的报错,涉及load问题的解决方案,以及如何调整`torch.distributed.launch`命令以适应单GPU环境。提供相关链接和命令示例。
本文指导如何在一台仅有一块GPU的电脑上解决PyTorch分布式训练时的报错,涉及load问题的解决方案,以及如何调整`torch.distributed.launch`命令以适应单GPU环境。提供相关链接和命令示例。
出现类似报错一般有两种可能
- 模型在服务器(多GPU)上训练完成,在自己台式机上(仅一块GPU)测试时报错。这是在load时出了问题。
解决可参考 https://blog.csdn.net/yinhui_zhang/article/details/86572232
https://blog.csdn.net/shincling/article/details/78919282 - 在进行训练时报错。报错如下:
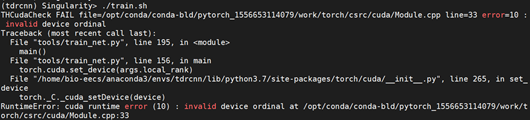
打开train.sh
下面展示一些内联代码片。
python -m torch.distributed.launch --nproc_per_node=2 --master_port=6001 tools/train_net.py --config-file self_exp/exp_1.yaml
其中--nproc_per_node=NUM_GPUS_YOU_HAVE,
因为只有一块GPU所以要将其改为1,即:
python -m torch.distributed.launch --nproc_per_node=1 --master_port=6001 tools/train_net.py --config-file self_exp/exp_1.yaml
关于Pytorch分布式训练更多的命令用法可以参考https://www.dazhuanlan.com/2019/12/24/5e0232323cbca/


















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









