







安装集群
1、修改启动文件,改为集群模式,默认是集群模式
standalone
2、每个nacos的 conf 文件夹添加 cluster.conf 文件,配置集群各个nacos的 ip+端口号
注意:本机搭建伪集群的时候,ip需要使用192.168.1.8这样的ip,不能使用127.0.0.1。
###ip和端口号
192.168.1.8:8848
192.168.1.8:8849
192.168.1.8:8850
3、每个nacos节点都配置数据存储配置文件
spring.datasource.platform=mysql
db.num=1
db.url.0=jdbc:mysql://11.162.196.16:3306/nacos_devtest?characterEncoding=utf8&connectTimeout=1000&socketTimeout=3000&autoReconnect=true
db.user=nacos_devtest
db.password=youdontknow
4、一次启动各个nacos服务即可,至此nacos集群搭建完成。
启动成功之后,查看集群信息
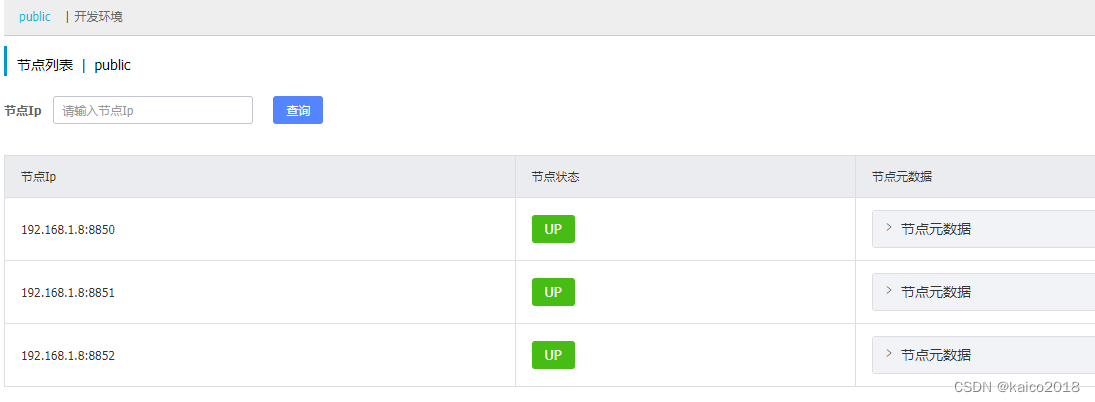
5、可以使用nginx实现单个ip或者域名映射多个ip实现访问nacos集群

集群原理
AP和CP
nacos这两种模式都支持,从1.0版本开始的。可以修改配置文件切换,默认是AP。
CAP定律
这个定理的内容是指的是在一个分布式系统中、Consistency(一致性)、 Availability(可用性)、Partition tolerance(分区容错性),三者不可得兼。
一致性 C:在分布式系统中,如果服务器集群,每个节点在同时刻访问必须要保持数据的一致性。
可用性 A:集群节点中,部分节点出现故障后任然可以使用 (高可用)
分区容错性 P:在分布式系统中网络会存在脑裂的问题,部分Server与整个集群失去节点联系,无法组成一个群体。
总结:只有在CP和AP选择一个平衡点
nacos、zookeeper、Eureka区别
中心化:必须围绕一个领导角色作为核心
去中心化:每个角色都是均等
相同点:都可以实现分布式服务注册中心
不同点:
Zookeeper采用CP保证数据的一致性的问题,原理采用Zab原子广播协议,当我们的zk领导因为某种原因宕机的情况下,会自动出发重新选一个新的领导角色,整个选举的过程为了保证数据的一致性的问题,在选举的过程中整个zk环境是不可以使用,可以短暂可能无法使用到zk.以为者微服务采用该模式的情况下,可能无法实现通讯(本地有缓存除外)。注意:可运行的节点必须满足过半机制。
Eureka采用ap的设计理念架构注册中心,完全去中心化思想,也就是没有主从之分。每个节点都是均等,采用相互注册原理,你中有我我中你,只要最后有一个eureka节点存在就可以保证整个微服务可以实现通讯。
使用注册中心,可用性在优先级最高,可以读取数据短暂不一致,但是至少要能够保证注册中心可用性。
Nacos从1.0版本支持CP和AP混合模式集群,默认是采用Ap保证服务可用性,CP 的形式底层集群raft协议保证数据的一致性的问题。
如果我们采用Ap模式注册服务的实例仅支持临时注册形式,在网络分区产生抖动的情况下任然还可以继续注册我们的服务列表。
那么选择CP模式必须保证数据的强一致性的问题,如果网络分区产生抖动的情况下,是无法注册我们的服务列表。选择CP模式可以支持注册实例持久。
如何切换AP/CP模式:使用HTTP的put请求$NACOS_SERVER:8848/nacos/v1/ns/operator/switches?entry=serverMode&value=CP
分布式一致性算法
分布式系统一-致性算法应用于系统软件实现集群保持每个节点数据的同步性。保持我们的集群中每个节点的数据的一致性的问题,专业的术语分布式一致性的算法。
应用场景:Redis集群、nacos集群、mongodb集群
分布式一致性事务和分布式一致性算法
分布式一致性事务框架:核心解决我们在实际系统中产生夸事务导致分布式事务问题。核心靠的是最终一致性。
分式系统一致性算法:解决我们系统之间集群之后每个节点保持数据的一致性:rocketmq事务消息、rabbitmq补单、lcn、seate等。
有哪些协议:raft(nacos)、zab(zookeeper)、paxos等
Raft协议
回顾一下 zab 协议:见之前的博客。
在Raft协议中分为的角色
- 状态:分为三种 跟随者、竞选者(候选人)、领导者
- 大多数: >n/2+1 (n表示集群的总数节点,这个表示满足过半机制)
- 任期:每次选举一个新的领导角色 任期都会增加。
- 竞选者谁的票数最多,谁就是为领导角色。
存在的疑问:多个竞选者,产生的票数都完全一样,这到底谁是为领导角色,服务器集群是偶数的情况下,奇数的情况下不存在这种情况。
默认情况下选举的过程:
- 默认的情况下每个节点都是为跟随者角色
- 每个节点随机生成一个选举的超时时间 大概分为100-300ms,在这个超时时间内必须要等待。
- 超时时间过后,当前节点的状态由跟随者变为竞选者角色,会给其他的节点发出选举的投票的通知,只要该竞选者有超过半数以上即可选为领导角色。
核心的设计原理其实就是靠的,谁超时时间最短谁就有非常大的概率为领导角色。
如果随机数有可能相同的情况下:
- 如果所有的节点的超时随机数都是一样的情况下, 当前投票全部作废,重新进入随机
生成超时时间。。 - 如果有多个节点生成的随机都是一样的情况下,比较谁的票数最多,谁就是为领导。。
如果票数完全一样的情况,直接作废,重新进入随机生成超时时间。
故障的重新实现选举:
如果我们跟随者节点不能够及时的收到领导角色消息,那么这时候跟随者就会将当前自己的状态由跟随者变为竞选者角色,会给其他的节点发出选举的投票的通知,只要该竞选者有超过半数以上即可选为领导角色。
数据如何保持一致性的,类似于zab两阶段提交协议。
- 所有的写的请求都是统一的交给我们的领导角色完成,写入该对应的日志,标记该日志为被提交状态。
- 为了提交该日志,领导角色就会将该日志以心跳的形式发送给其他的跟随者节点,只要超过跟随者节点写入该日志,则直接通知其他的跟随者节点同步该数据,这个过程称做为日志复制的过程。















 3129
3129











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









