







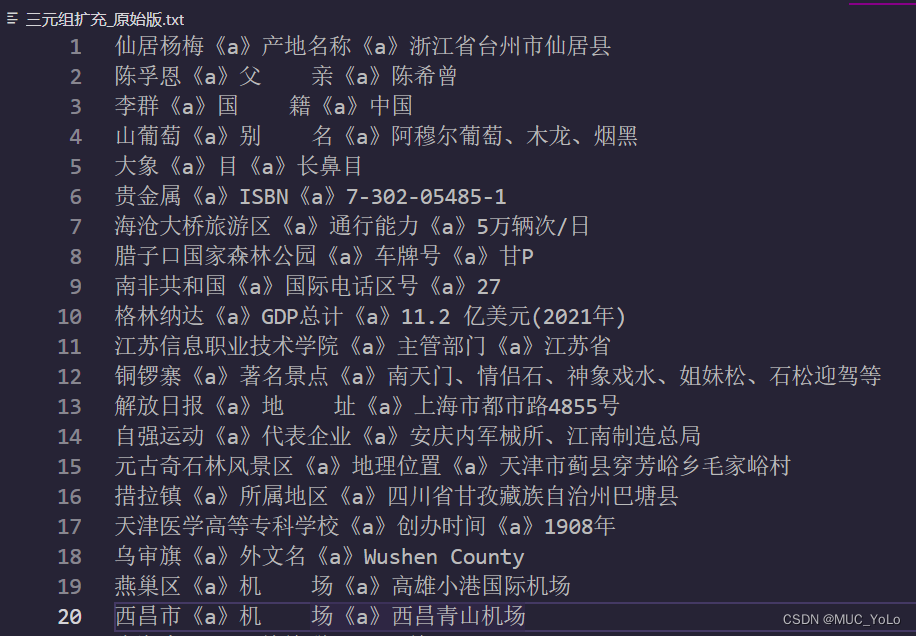
在已经爬取并保存好的三元组txt文档中,我使用了“《a》”作为分隔符(随便取分隔符,别和内容混了就行),由于我想将汉语的三元组翻译成藏语三元组,直接将下图的三元组信息放进翻译软件中,它会将一整行不通顺的内容进行翻译,连带分隔符,语义不畅通,还会出现翻译后分隔符错误的情况。
翻译后的页面截图,红框内出现翻译错误
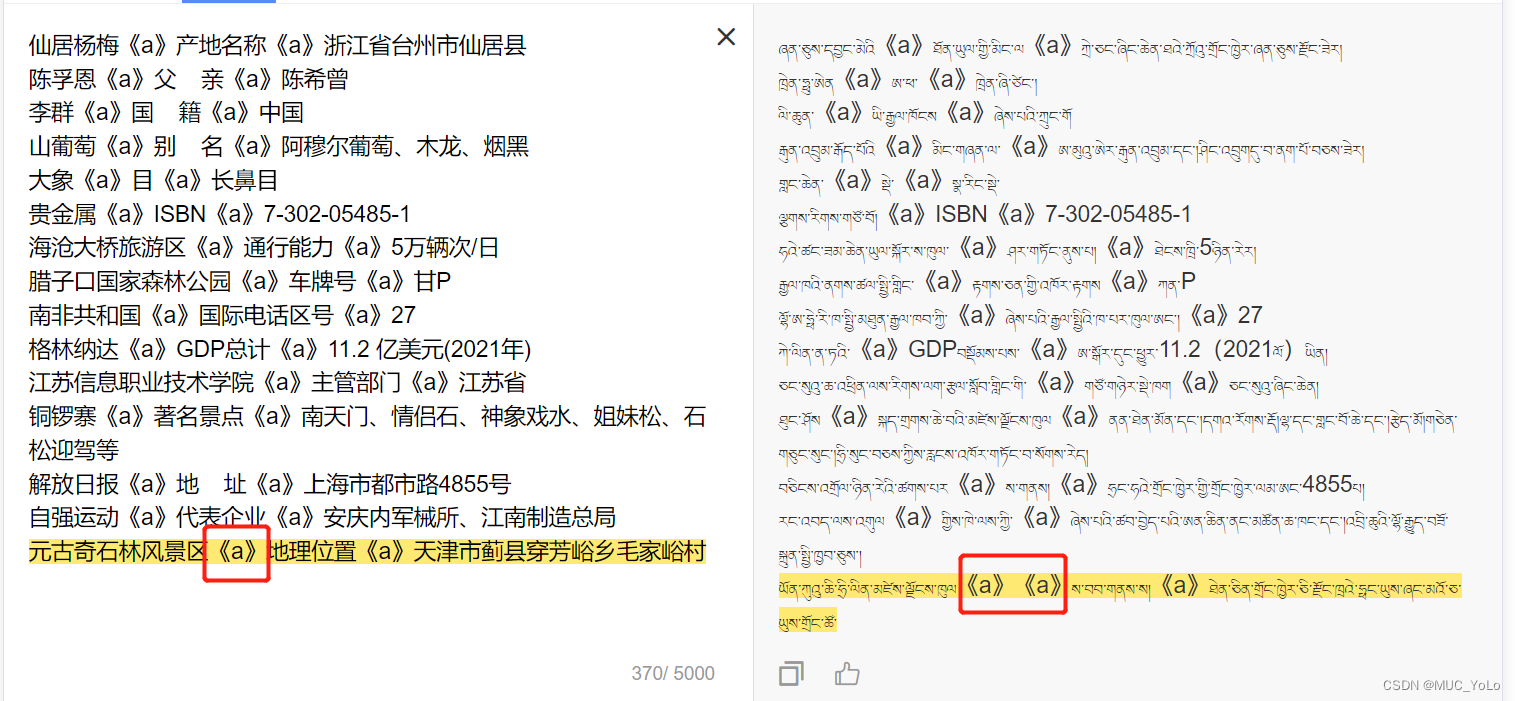
因此,想要避免这种问题发生,就需要将三元组按照分隔符进行拆分,将实体1、关系、实体2分别保存到三个文件中并单独翻译,这样将词语独立翻译才会比较准确。
完整代码如下:
with open("三元组.txt", "r") as input_file:
# 将拆分好的实体和联系分别写入新文件,没有此文件则创建
with open("三元组实体1.txt", "w") as output_file1, \
open("三元组联系.txt", "w") as output_file2, \
open("三元组实体2.txt", "w") as output_file3:
# 循环完整三元组文件的每一行
for line in input_file:
# 将三元组文件按照指定分隔符分开,譬如我使用“《a》”作为分隔符,每行有两个分隔符,拆开后得到三部分
parts = line.strip().split("《a》")
# 将每行的三部分写入对应的输出文件中
output_file1.write(parts[0] + "\n")
output_file2.write(parts[1] + "\n")
output_file3.write(parts[2] + "\n")
这样拿到三个文本文档,分别进行翻译,得到准确的词语翻译,而不是一整行不通顺连带分隔符的别扭翻译。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











