







 本文介绍了参加Kaggle的TMDB电影票房预测比赛的过程,包括数据探索(EDA)、特征工程和模型训练。通过分析发现票房与预算、观众打分数量呈正相关,而票房分布右偏,可通过转换实现正态化。特征工程中创建了197个数值型特征,并使用xgboost、lightGBM和catboost构建融合模型进行预测,最终在比赛中取得了较好的初步排名。
本文介绍了参加Kaggle的TMDB电影票房预测比赛的过程,包括数据探索(EDA)、特征工程和模型训练。通过分析发现票房与预算、观众打分数量呈正相关,而票房分布右偏,可通过转换实现正态化。特征工程中创建了197个数值型特征,并使用xgboost、lightGBM和catboost构建融合模型进行预测,最终在比赛中取得了较好的初步排名。
最近在kaggle上找项目练习,发现一个 TMDB电影票房预测项目比较适合练手。这里记录在下。
目标是通过train集中的数据训练模型,将test集数据导入模型得出目标值revenue即票房,上传结果得到分数和排名。
数据可以从kaggle网站上直接下载,文中用到的额外数据可从
https://www.kaggle.com/kamalchhirang/tmdb-competition-additional-features
和
https://www.kaggle.com/kamalchhirang/tmdb-box-office-prediction-more-training-data
下载。
EDA
train.info()
载入数据并整理后大体观察
<class 'pandas.core.frame.DataFrame'>
Int64Index: 3000 entries, 0 to 2999
Data columns (total 53 columns):
id 3000 non-null int64
belongs_to_collection 604 non-null object
budget 3000 non-null int64
genres 3000 non-null object
homepage 946 non-null object
imdb_id 3000 non-null object
original_language 3000 non-null object
original_title 3000 non-null object
overview 2992 non-null object
popularity 3000 non-null float64
poster_path 2999 non-null object
production_companies 2844 non-null object
production_countries 2945 non-null object
release_date 3000 non-null object
runtime 2998 non-null float64
spoken_languages 2980 non-null object
status 3000 non-null object
tagline 2403 non-null object
title 3000 non-null object
Keywords 2724 non-null object
cast 2987 non-null object
crew 2984 non-null object
revenue 3000 non-null int64
logRevenue 3000 non-null float64
release_month 3000 non-null int32
release_day 3000 non-null int32
release_year 3000 non-null int32
release_dayofweek 3000 non-null int64
release_quarter 3000 non-null int64
Action 3000 non-null int64
Adventure 3000 non-null int64
Animation 3000 non-null int64
Comedy 3000 non-null int64
Crime 3000 non-null int64
Documentary 3000 non-null int64
Drama 3000 non-null int64
Family 3000 non-null int64
Fantasy 3000 non-null int64
Foreign 3000 non-null int64
History 3000 non-null int64
Horror 3000 non-null int64
Music 3000 non-null int64
Mystery 3000 non-null int64
Romance 3000 non-null int64
Science Fiction 3000 non-null int64
TV Movie 3000 non-null int64
Thriller 3000 non-null int64
War 3000 non-null int64
Western 3000 non-null int64
popularity2 2882 non-null float64
rating 3000 non-null float64
totalVotes 3000 non-null float64
meanRevenueByRating 8 non-null float64
dtypes: float64(7), int32(3), int64(25), object(18)
memory usage: 1.2+ MB
主要的几项特征:
- budget:预算
- revenue:票房
- rating:观众打分
- totalVotes:观众打分数量
- popularity:流行系数(怎么得出的暂未可知)
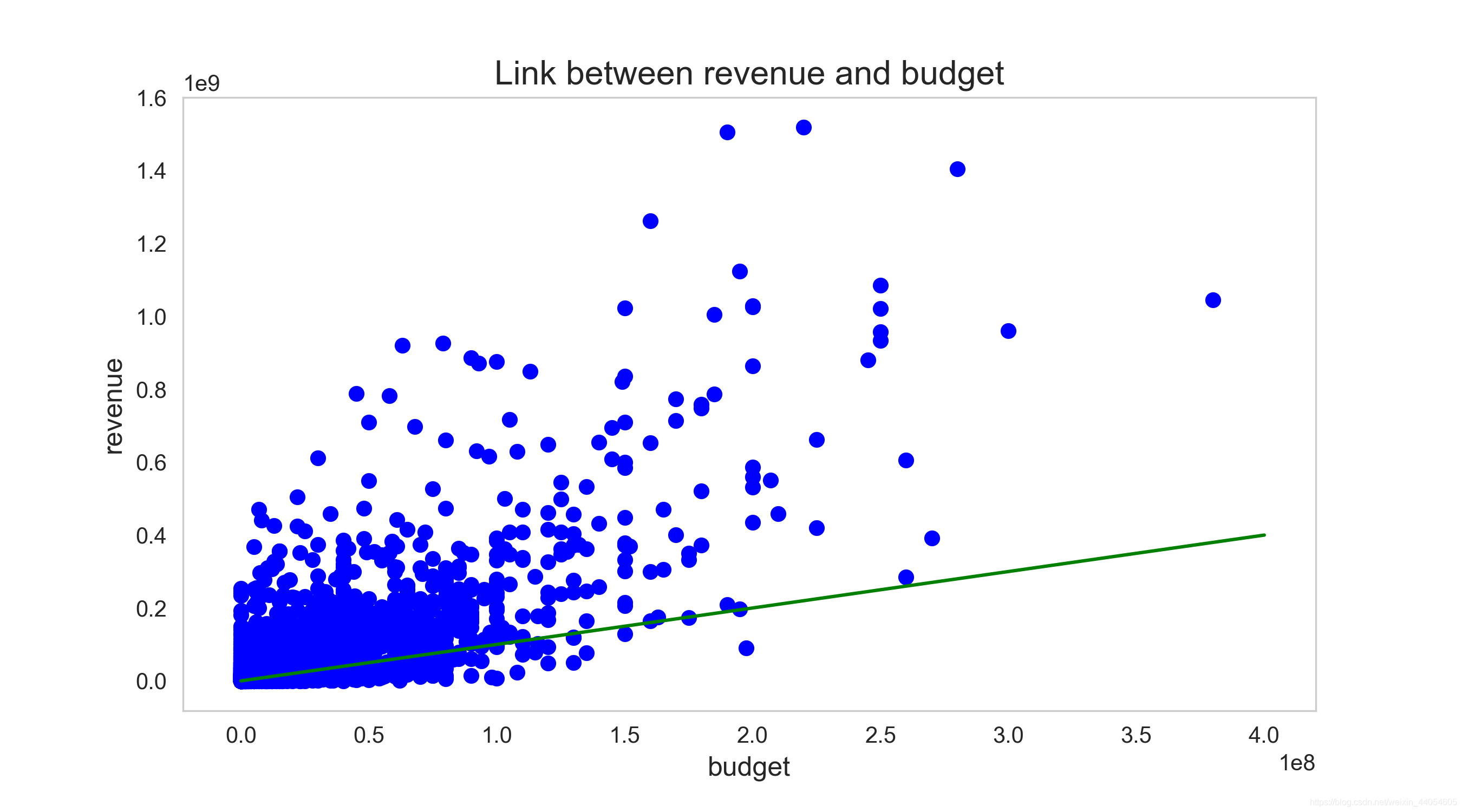
票房和预算呈较明显的正相关关系。这很符合常识,但也不定,现在也挺多投资高票房低的烂片的。
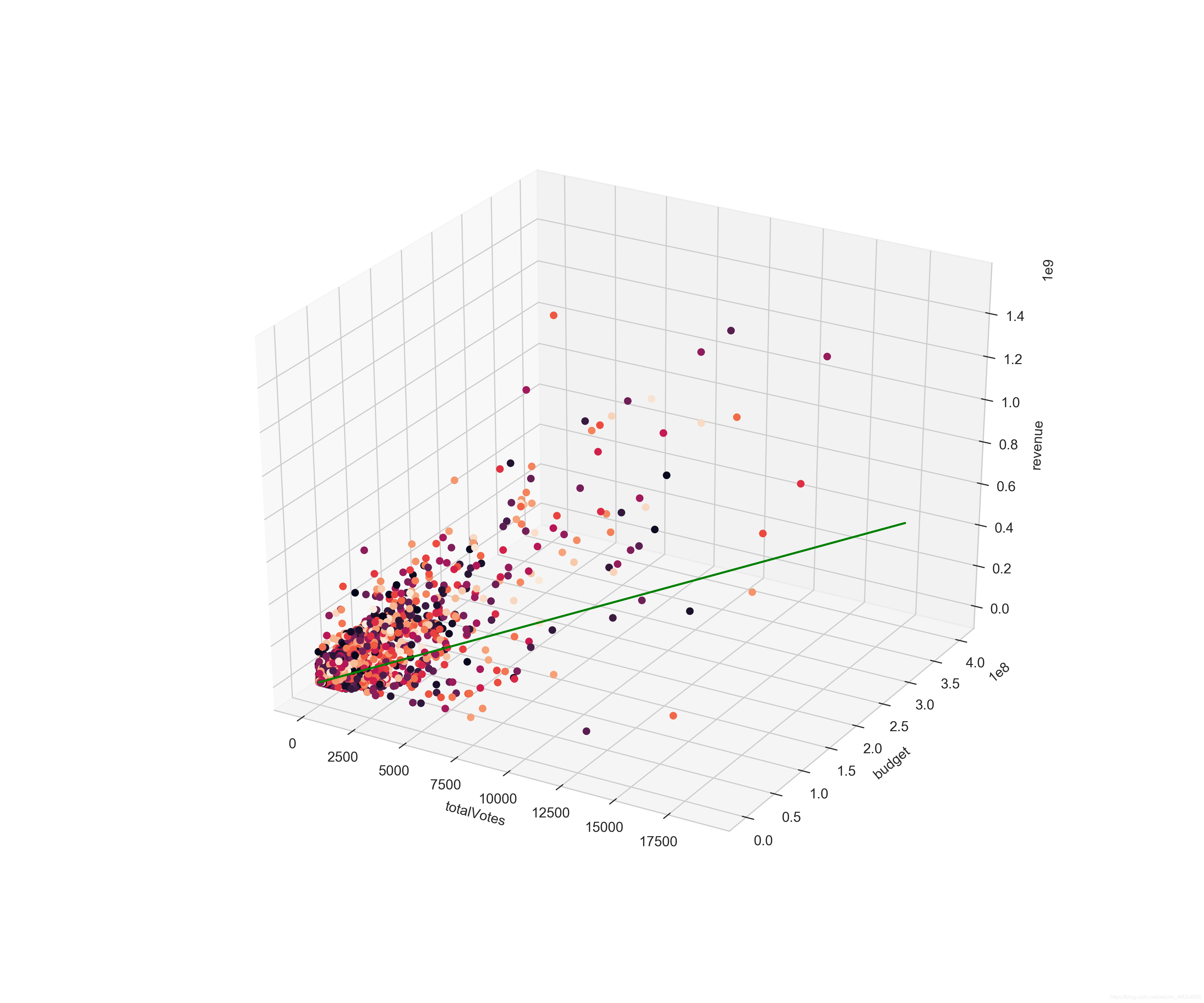
除了预算外,票房和观众打分数量也有一定关系。这也符合常识,不管观众打分高低,只要有大量观众打分,就说明该电影是舆论热点,票房就不会太低。
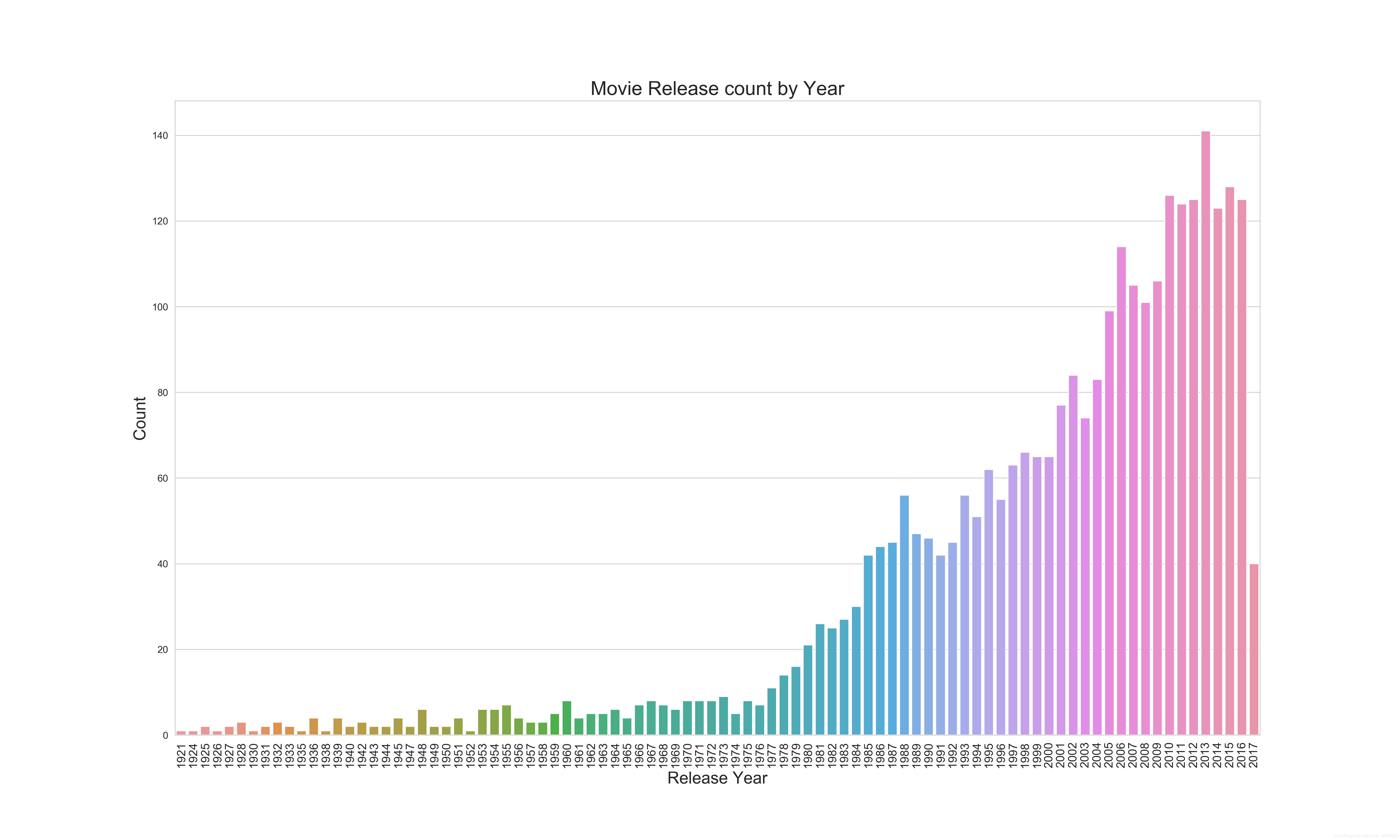
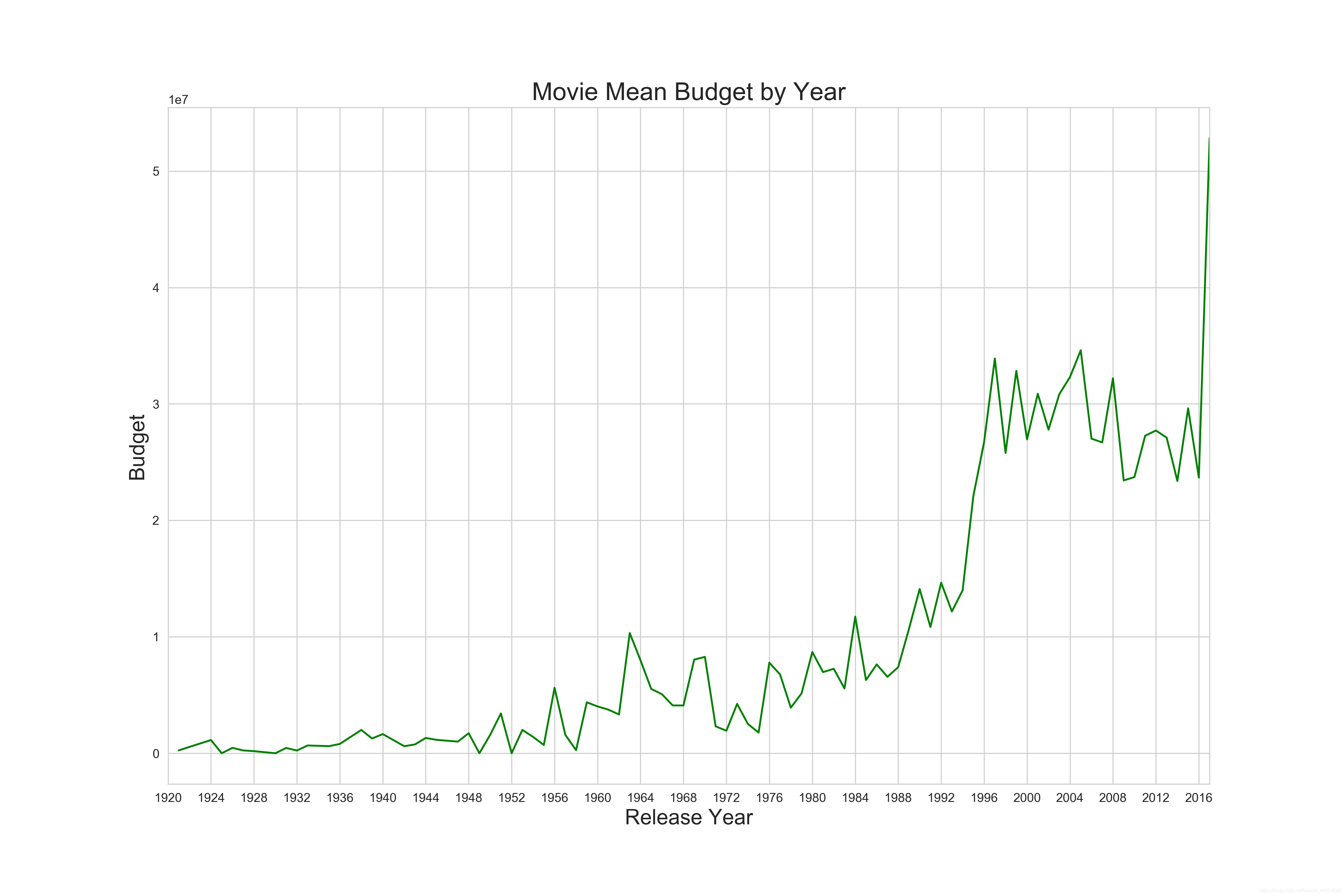
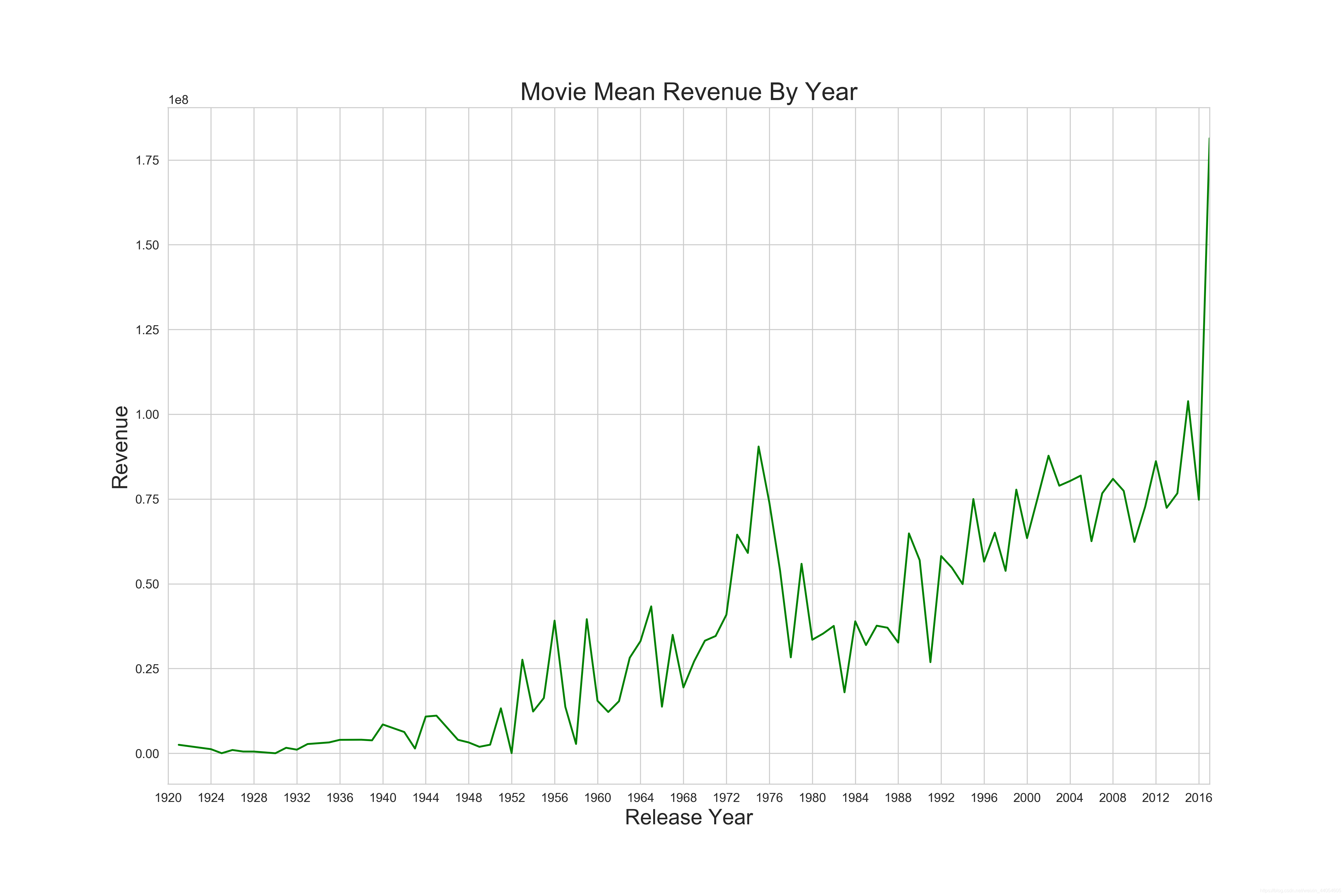
近几年的电影市场无论是投资还是票房都有比较大的增长,说明了电影市场的火爆。也提醒我们后续的特征工程需要关注电影上映年份。
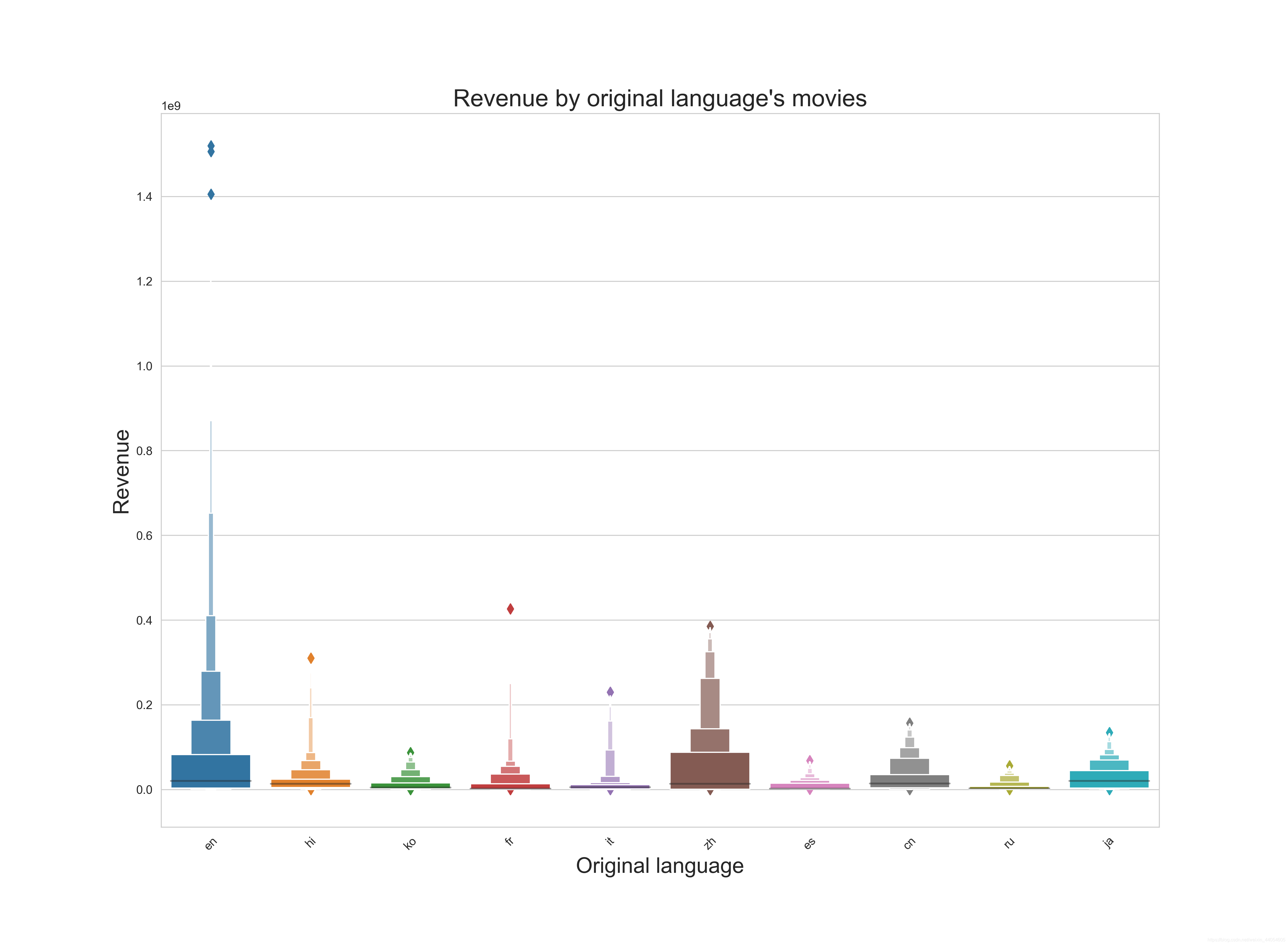
通过电影的语言来看票房。en表示英语。毕竟世界语言,无论是票房的体量还是高票房爆款,都独占鳌头。zh就是你心里想的那个,中文。可见华语电影对于english可以望其项背了。语言对票房也有一定反映。
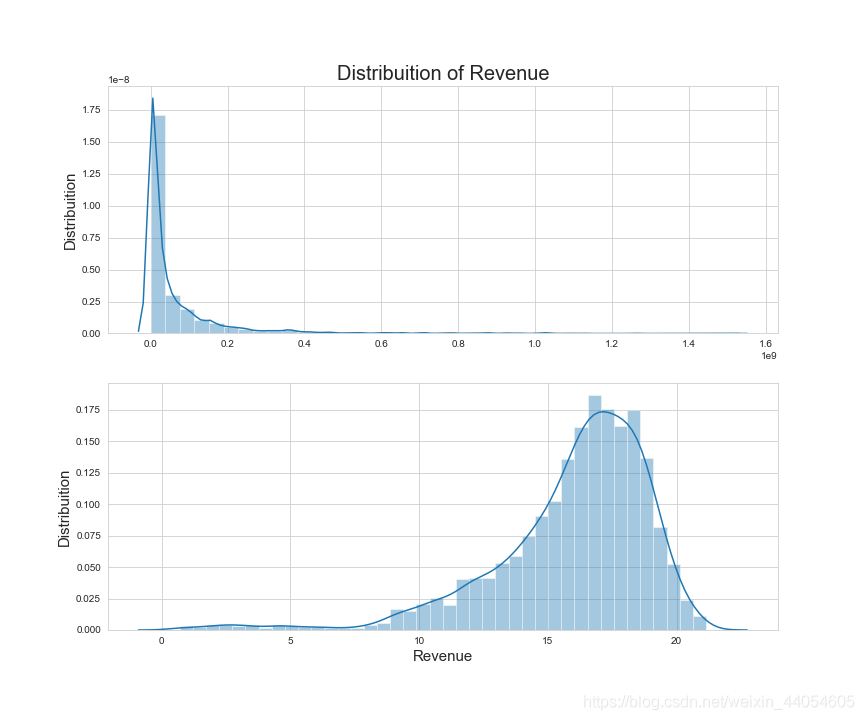
票房的分布明显右偏,可以通过np.logp1方法转换为对数形式实现数据的正态化,但记得在得到最后的预测数据后再用np.expm1方法转换回来。
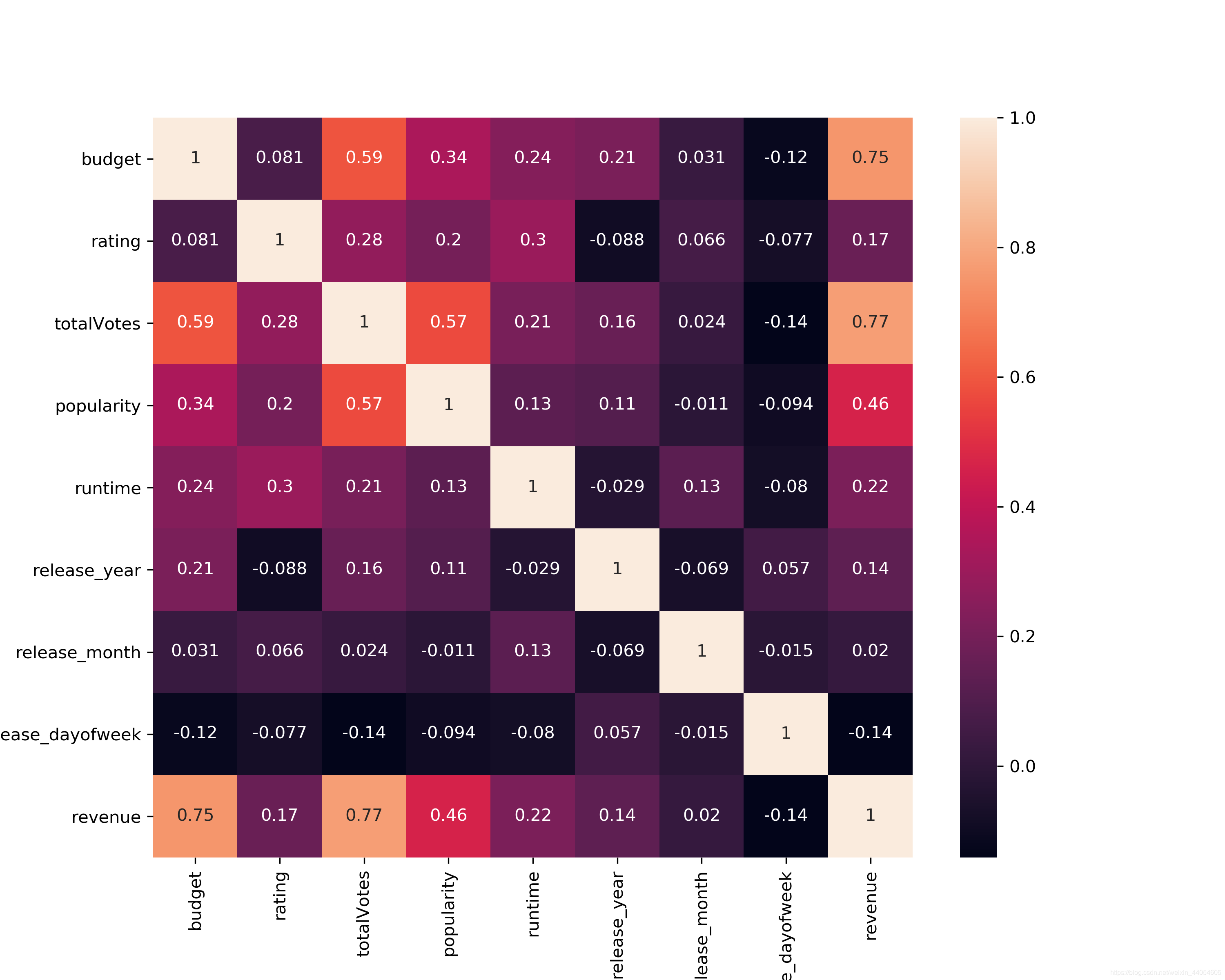
通过热力图观察几个主要特征跟票房的皮尔逊系数(线性相关系数),及其彼此的系数。可见跟票房revenue最相关的为budget,totalVotes,popularity。
特征工程
特征工程太过繁琐,不一一叙述,直接上整体代码。
import numpy as np
import pandas as pd
import warnings
from tqdm import tqdm
from sklearn.preprocessing import LabelEncoder
warnings.filterwarnings("ignore")
def prepare(df):
global json_cols
global train_dict
df['rating'] = df['rating'].fillna(1.5)
df['totalVotes'] = df['totalVotes'].fillna(6)
df['weightedRating'] = (df['rating'] * df['totalVotes'] + 6.367 * 300) / (df['totalVotes'] + 300)
df[['release_month', 'release_day', 'release_year']] = df['release_date'].str.split('/', expand=True).replace(
np.nan, 0).astype(int)
df['release_year'] = df['release_year']
df.loc[(df['release_year'] <= 19) & (df['release_year'] < 100), "release_year"] += 2000
df.loc[(df['release_year'] > 19) & (df['release_year'] < 100), "release_year"] += 1900
releaseDate = pd.to_datetime(df['release_date'])
df['release_dayofweek'] = releaseDate.dt.dayofweek
df['release_quarter'] = releaseDate.dt.quarter
df['originalBudget'] = df['budget']
df['inflationBudget'] = df['budget'] + df['budget'] * 1.8 / 100 * (
2018 - df['release_year']) # Inflation simple formula
df['budget'] = np.log1p(df['budget'])
df['genders_0_crew'] = df['crew'].apply(lambda x: sum([1 for i in x if i['gender'] == 0]))
df['genders_1_crew'] = df['crew'].apply(lambda x: sum([1 for i in x if i['gender'] == 1]))
df['genders_2_crew'] = df['crew'].apply(lambda x: sum([1 for i in x if i['gender'] == 2]))
df['_collection_name'] = df['belongs_to_collection'].apply(lambda x: x[0]['name'] if x != {
} else '').fillna('')
le = LabelEncoder()
df['_collection_name'] = le.fit_transform(df['_collection_name'])
df['_num_Keywords'] = df['Keywords'].apply(lambda x: len(x) if x != {
} else 0)
df['_num_cast'] = df['cast'].apply(lambda x: len(x) if x != {
} else 0)
df['_popularity_mean_year'] = df['popularity'] / df.groupby("release_year")["popularity"].transform('mean')
df['_budget_runtime_ratio'] = df['budget'] / df['runtime']
df['_budget_popularity_ratio'] = df['budget'] / df['popularity']
df['_budget_year_ratio'] = df['budget'] / (df['release_year'] * df['release_year'])
df['_releaseYear_popularity_ratio'] = df['release_year'] / df['popularity']
df['_releaseYear_popularity_ratio2'] = df['popularity'] / df['release_year']
df['_popularity_totalVotes_ratio'] = df['totalVotes'] / df['popularity']
df['_rating_popularity_ratio'] = df['rating'] / df['popularity']
df['_rating_totalVotes_ratio'] = df['totalVotes'] / df['rating']
df['_totalVotes_releaseYear_ratio'] = df['totalVotes'] / df['release_year']
df['_budget_rating_ratio'] = df['budget'] / df['rating']
df['_runtime_rating_ratio'] = df['runtime'] / df['rating']
df['_budget_totalVotes_ratio'] = df['budget'] / df['totalVotes']
df['has_homepage'] = 1
df.loc[pd.isnull(df['homepage']), "has_homepage"] = 0
df['isbelongs_to_collectionNA'] = 0
df.loc[pd.isnull(df['belongs_to_collection']), "isbelongs_to_collectionNA"] = 1
df['isTaglineNA'] = 0
df.loc[df['tagline'] == 0, "isTaglineNA"] = 1
df['isOriginalLanguageEng'] = 0
df.loc[df['original_language'] == "en", "isOriginalLanguageEng"] = 1
df['isTitleDifferent'] = 1
df.loc[df['original_title'] == df['title'], "isTitleDifferent"] = 0
df['isMovieReleased'] = 1
df.loc[df['status'] != "Released", "isMovieReleased"] = 0
# get collection id
df['collection_id'] = df['belongs_to_collection'].apply(lambda x: np.nan if len(x) == 0 else x[0]['id'])
df['original_title_letter_count'] = df['original_title'].str.len()
df['original_title_word_count'] = df['original_title'].str.split().str.len()
df['title_word_count'] = df['title'].str 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 8152
8152

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









