






描述下我的场景:
数据库服务器在远程机器上,数据库使用的Oracle,字符集是ZHS16GBK,但保存韩文、俄文、日文等字段A的数据类型是nvarchar(120),而nvarchar使用的是Unicode 编码,有点乱。。
遇到的问题:
我在本地机器idea上配置的tomcat9.0.52,启动项目后,获取字段A发现韩文会乱码。
解决办法:
Oracle客户端保存unicode字符有时需要加ORA_NCHAR_LITERAL_REPLACE=true类似参数。
只需要在idea的tomcat配置页面加下面内容即可:再次启动项目,获取字段A,韩文会正常显示。
-Doracle.jdbc.defaultNChar=true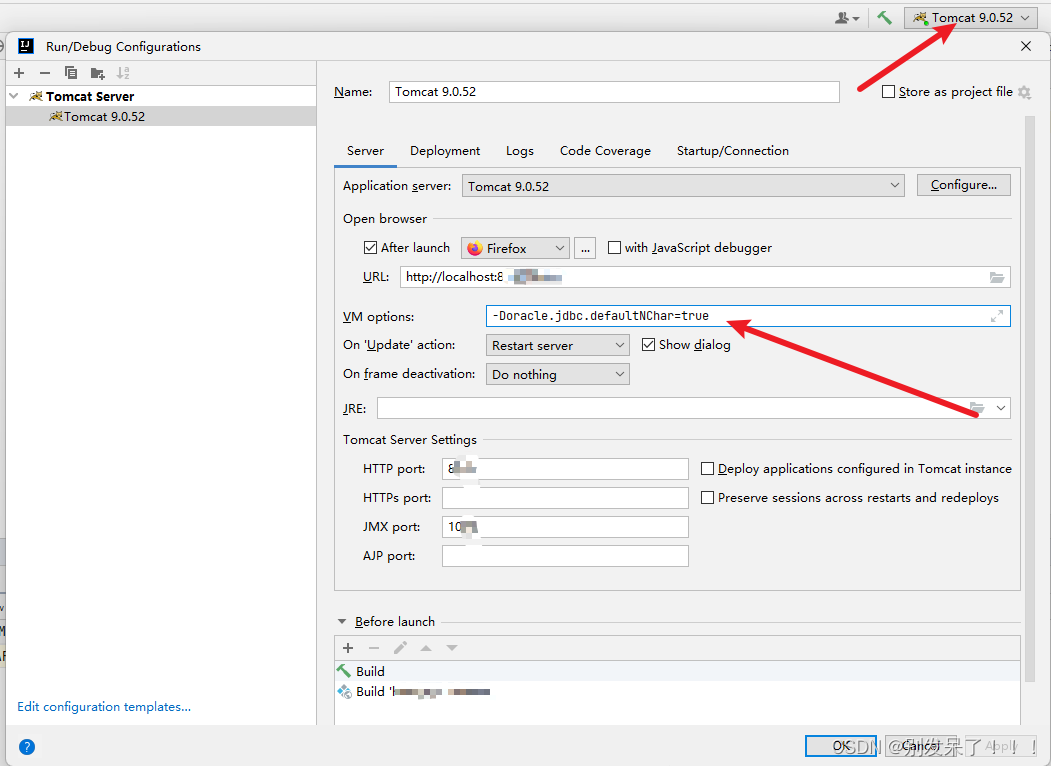















 6202
6202











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









