







PageRank
1. PageRank概念
- PageRank是Google专有的算法,用于衡量特定网页相对于搜索引擎索引中的其他网页而言的重要程度。
- 是Google创始人拉里·佩奇和谢尔盖·布林于1997年创造的。
- PageRank实现了将
链接价值概念作为排名因素。
2. PageRank算法原理
- 入链 === 投票
PageRank让链接来“投票”,到一个页面的链接相当于对该网页投一票。
- 入链数量
如果一个页面节点接收到的其他网页指向的入链数量越多,那么这个页面越重要。
- 入链质量
指向页面A的入链质量不同,质量高的页面会通过链接向其他页面传递更多的权重。所以越是质量高的页面指向页面A,则页面A越重要。
3. 网络上各个页面的连接图

4. 用代码实现PageRank
图存储
将网络上各个页面的连接图,做成数据进行存储。
方式一:存边
A-B
A-D
B-C
C-A
C-B
D-B
D-C
方式二:存顶点
A-B,D
B-C
C-A,B
D-B,C
以下采用存顶点的方式
计算过程
-
初始值
- 每个页面设置相同的PR值
- Google的PageRank算法给每个页面的PR初始值为1。
-
迭代递归计算(收敛)
- Google不断的重复计算每个页面的PageRank。那么经过不断的重复计算,这些页面的PR值会趋向于稳定,也就是收敛的状态。
- 在具体企业应用中怎么样确定收敛标准?
1.每个页面的PR值和上一次计算的PR相等。
2.设定一个差值指标(0.0001)。当所有页面和上一次计算的PR差值平均小于该标准时,则收敛。
3.设定一个百分比(99%),当99%的页面和上一次计算的PR相等。
代码实现一:无孤立网页
当网页数据为是
A-B,D
B-C
C-A,B
D-B,C
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author 郭帅帅
* @2022-01-04-20:09
*
*/
object Demo1PageRank {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf()
conf.setMaster("local")
conf.setAppName("Demo1PageRank")
val sc: SparkContext = new SparkContext(conf)
/**
* 读取数据
*
*/
val data: RDD[String] = sc.textFile("SparkLearning/src/main/data/pagerank.txt")
/**
* 整理数据,给每个网页一个初始的pr值
*/
val pageLinkRDD: RDD[(String, List[String])] = data
.map(line => {
val splits: Array[String] = line.split("-")
//当前网页
val page: String = splits(0)
//出链列表,本来split返回的是Array,为了后续方便,调用tolist方法
val linked: List[String] = splits(1).split(",").toList
(page, linked)
})
//对多次使用的RDD进行缓存
pageLinkRDD.cache()
//计算网页数量
val n: Long = pageLinkRDD.count()
/**
* 给每个网页一个初始的pr值
*
*/
var pageRDD: RDD[(String, List[String], Double)] = pageLinkRDD.map {
case (page, linked) => {
(page, linked, 1.0)
}
}
var flag = true
while (flag) {
/**
* 将每一个pr值平分给它的出链列表
*
*/
val avgPrRDD: RDD[List[(String, Double)]] = pageRDD.map {
case (page, linked, pr) => {
//计算分给出链列表多少pr值
val avgPr: Double = pr / linked.length
linked.map(p => (p, avgPr))
}
}
/**
* flatMap将数据展开
* (B,0.5)
* (D,0.5)
* (C,1.0)
* (A,0.5)
* (B,0.5)
* (B,0.5)
* (C,0.5)
*/
val avgPrFlatMapRDD: RDD[(String, Double)] = avgPrRDD.flatMap(w => w)
/**
* 计算网页新的pr值
*
* 第一次
* (B,1.5)
* (A,0.5)
* (C,1.5)
* (D,0.5)
*/
val newPagePrRDD: RDD[(String, Double)] = avgPrFlatMapRDD.reduceByKey(_ + _)
/**
* 关联出链列表
*/
val joinRDD: RDD[(String, (Double, List[String]))] = newPagePrRDD.join(pageLinkRDD)
//整理数据
val curPageRDD = joinRDD.map {
case (page: String, (pr: Double, link: List[String])) => {
(page, link, pr)
}
}
/**
* 计算当前网页pr值和上一次所有网页pr值 差值 的 平均值
*
*/
val curKv: RDD[(String, Double)] = curPageRDD.map {
case (page, link, pr) =>
(page, pr)
}
val lastKv: RDD[(String, Double)] = pageRDD.map {
case (page, link, pr) => (page, pr)
}
val prJoinRDD: RDD[(String, (Double, Double))] = curKv.join(lastKv)
//计算所有网页pr值和上一次pr值的平均值
val pageDifferenceRDD: RDD[Double] = prJoinRDD.map {
case ((page: String, (currPr: Double, lastPr: Double))) =>
Math.abs(currPr - lastPr)
}
val DifferenceAvg: Double = pageDifferenceRDD.sum() / n
if (DifferenceAvg < 0.0001) {
println(s"差值平均值: $DifferenceAvg")
flag = false
}
/**
* 整理数据,将计算结果,赋值给前面的RDD,下一次的迭代使用上一次的结果
*/
pageRDD = curPageRDD
}
pageRDD.foreach(println)
}
}
修正PageRank计算公式
由于存在一些出链为0,也就是那些不链接任何其他网页的网,也称为孤立网页,使得很多网页能被访问到。因此需要对 PageRank公式进行修正。即在简单公式的基础上增加了阻尼系数(damping factor)q, q一般取值q=0.85。
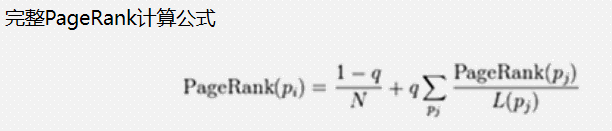
代码实现二:有孤立网页
当前网页数据为:
A-B,D
B-C
C-A,B,E
D-B,C
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author 郭帅帅
* @2022-01-04-20:09
*
*/
object Demo1PageRank2 {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf()
conf.setMaster("local")
conf.setAppName("Demo1PageRank")
val sc: SparkContext = new SparkContext(conf)
/**
* 读取数据
*
*/
val data: RDD[String] = sc.textFile("SparkLearning/src/main/data/pagerank.txt")
/**
* 整理数据,给每个网页一个初始的pr值
*/
val pageLinkRDD: RDD[(String, List[String])] = data
.map(line => {
val splits: Array[String] = line.split("-")
//当前网页
val page: String = splits(0)
//出链列表,本来split返回的是Array,为了后续方便,调用tolist方法
val linked: List[String] = splits(1).split(",").toList
(page, linked)
})
//对多次使用的RDD进行缓存
pageLinkRDD.cache()
//计算网页数量
val n: Long = pageLinkRDD.count()
val q = 0.85
/**
* 给每个网页一个初始的pr值
*
*/
var pageRDD: RDD[(String, List[String], Double)] = pageLinkRDD.map {
case (page, linked) => {
(page, linked, 1.0)
}
}
var flag = true
while (flag) {
/**
* 将每一个pr值平分给它的出链列表
*
*/
val avgPrRDD: RDD[List[(String, Double)]] = pageRDD.map {
case (page, linked, pr) => {
//计算分给出链列表多少pr值
val avgPr: Double = pr / linked.length
linked.map(p => (p, avgPr))
}
}
/**
* flatMap将数据展开
* (B,0.5)
* (D,0.5)
* (C,1.0)
* (A,0.5)
* (B,0.5)
* (B,0.5)
* (C,0.5)
*/
val avgPrFlatMapRDD: RDD[(String, Double)] = avgPrRDD.flatMap(w => w)
/**
* 计算网页新的pr值
*
* 第一次
* (B,1.5)
* (A,0.5)
* (C,1.5)
* (D,0.5)
*/
val newPagePrRDD: RDD[(String, Double)] = avgPrFlatMapRDD.reduceByKey(_ + _)
/**
* 关联出链列表
*/
val joinRDD: RDD[(String, (Double, List[String]))] = newPagePrRDD.join(pageLinkRDD)
//整理数据
val curPageRDD = joinRDD.map {
case (page: String, (pr: Double, link: List[String])) => {
//增加阻尼系数
(page, link, (1 - q) / n + q * pr)
}
}
/**
* 计算当前网页pr值和上一次所有网页pr值 差值 的 平均值
*
*/
val curKv: RDD[(String, Double)] = curPageRDD.map {
case (page, link, pr) =>
(page, pr)
}
val lastKv: RDD[(String, Double)] = pageRDD.map {
case (page, link, pr) => (page, pr)
}
val prJoinRDD: RDD[(String, (Double, Double))] = curKv.join(lastKv)
//计算所有网页pr值和上一次pr值的平均值
val pageDifferenceRDD: RDD[Double] = prJoinRDD.map {
case ((page: String, (currPr: Double, lastPr: Double))) =>
Math.abs(currPr - lastPr)
}
val DifferenceAvg: Double = pageDifferenceRDD.sum() / n
if (DifferenceAvg < 0.0001) {
println(s"差值平均值: $DifferenceAvg")
flag = false
}
/**
* 整理数据,将计算结果,赋值给前面的RDD,下一次的迭代使用上一次的结果
*/
pageRDD = curPageRDD
}
pageRDD.foreach(println)
}
}
















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











