






 本文详细介绍了KNN算法的基本思想,讨论了K值对模型性能的影响,以及如何用于解决分类和回归问题。通过实例展示了如何使用KNN算法进行预测,包括计算距离、多数表决(分类)和平均值(回归)。
本文详细介绍了KNN算法的基本思想,讨论了K值对模型性能的影响,以及如何用于解决分类和回归问题。通过实例展示了如何使用KNN算法进行预测,包括计算距离、多数表决(分类)和平均值(回归)。
1.KNN算法思想
K-近邻算法(K Nearest Neighbor,简称KNN),简单来说,如果一个样本在特征空间中的 k 个最相似的样本中的大多数属于某一个类别,则该样本也属于这个类别.
2.关于K值
当k值过小,相当于用较小领域中的训练实例进行预测,容易受到异常点的影响,k值的减小就意味着整体模型变得复杂,容易发生过拟合.
过拟合就是模型在训练集上表现很好、在测试集表现很差.
当k值过大,相当于用较大领域中的训练实例进行预测,受到样本均衡的问题,且k值增大就意味着整体的模型变的简单,欠拟合.
欠拟合就是模型在训练集上表现很差、在测试集表现也很差.
3.KNN算法的应用方式-解决分类问题、回归问题
分类问题的处理流程:
1.计算未知样本到每一个训练样本的距离
2.将训练样本根据距离大小升序排列
3.取出距离最近的 K 个训练样本
4.进行多数表决,统计 K 个样本中哪个类别的样本个数最多
5.将未知的样本归属到出现次数最多的类别
以下是实例,例如:x为 训练的样本,y是 其对应的值,注意:要保持个数的一致.预测下[[6]]的值为多少?
#导包
from sklearn.neighbors import KNeighborsClassifier
x = [[1],[2],[3],[4],[5]]
y = [0,0,1,1,1]
knn = KNeighborsClassifier(n_neighbors = 3)
knn.fit(x,y)
print(knn.predict([[6]])) # [1]
运行结果为[1],因为通过 欧氏距离,即两点之间的最短距离,从6到1,2,3,4,5的距离分别为,d = 5,4,3,2,1,取最近的3个值(n_neighbors = 3),即[1],[1],[1],出现次数最多的 即为结果 [1]
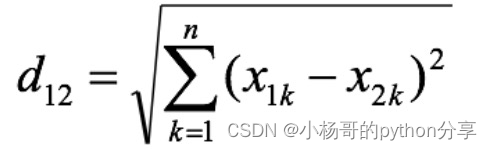
回归问题的处理流程:
1.计算未知样本到每一个训练样本的距离
2.将训练样本根据距离大小升序排列
3.取出距离最近的 K 个训练样本
4.把这个 K 个样本的目标值计算其平均值
5.作为将未知的样本预测的值
注意:回归问题和分类问题的区别就在于 第四点, 即分类问题是取 临近的k个值中出现最多的值,而回归问题是取 临近的k个值的平均值.
from sklearn.neighbors import KNeighborsRegressor
x = [[1],[2],[3],[4],[5]]
y = [0.1,0.2,0.3,0.4,0.5]
knn = KNeighborsRegressor(n_neighbors = 3)
knn.fit(x,y)
print(knn.predict([[6]]))其运行结果为:[0.4],因为通过 欧氏距离,即两点之间的最短距离,从6到1,2,3,4,5的距离分别为,d = 5,4,3,2,1,取最近的3个值(n_neighbors = 3),即[0.3],[0.4],[0.5],取三者的平均值 即为结果 [0.4]















 360
360

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









