







1.申明:在看本博客之前:请务必完全按照以下的步骤去做完全一样的的,不要去修改,否则容易出错。
实验环境:VMware Workstation Pro14, centos7镜像,hadoop102为主节点hadoop103和hadoop104为子节点。
符:资源下载hadoop2.7.2和jdk1.8
点我进去:提取码:t5xb
- 在VM上新建一台虚拟机hadoop100,然后从这台原始的hadoop100虚拟机上面克隆三台虚拟机,
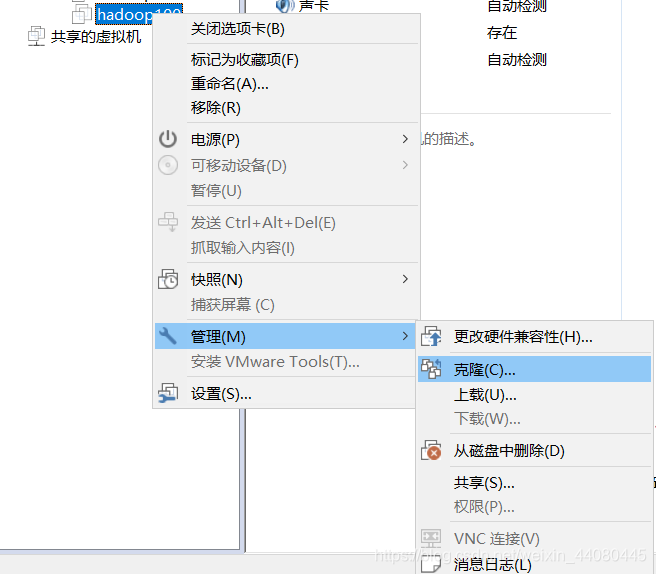
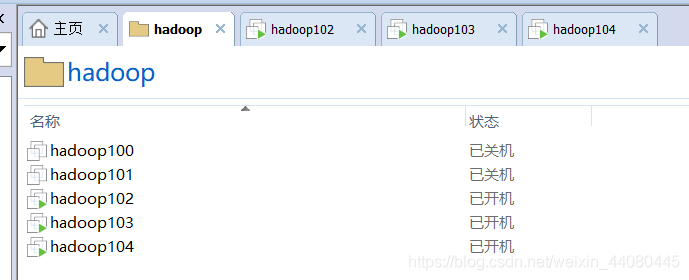
hadoop101是我搭建伪分布用的一台机器大家请忽略,102,103,104都是我用来做全分布式的机器,随后在这102,103,104三台机器上面修改网卡配置文件,网卡配置文件在/etc/sysyconfig/network-scripts/ifcfg-ens33(注,我的网卡信息是ens33,每个人的网卡信息不同,有的也可能是eth0),一定要保证你可以ping 通外网www baidu.com就可以了。
这一部分的配置信息请看我的上篇博客:
点我进去
-
*关闭防火墙:
关闭防火墙:systemctl stop firewalld.service
禁用防火墙:systemctl disable firewalld.service
查看防火墙:systemctl status firewalld.service -
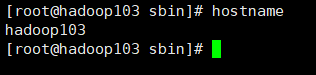
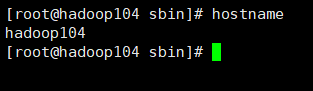
修改主机名:hostnamectl set-hostname 主机名
在hadoop102上执行hostnamectl set-hostname hadoop102
在hadoop103上执行hostnamectl set-hostname hadoop103
在hadoop104上执行hostnamectl set-hostname hadoop104
然后每台机器reboot重启在各自用hostname命令查看主机名会发现三台机器的主机名依次为hadoop102,hadoop103,hadoop104,如果发现不一样的话一定要改主机名。

- 配置ip映射
三台机器分别执行 vi /etc/hosts
加上自己虚拟机的IP地址和主机名
(**注:下面的内容没有说明在哪台虚拟机上操作时,都默认在hadoop102上面操作)*
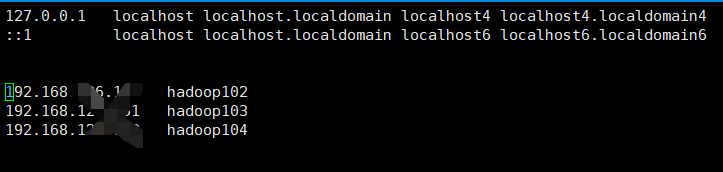
wq保存退出
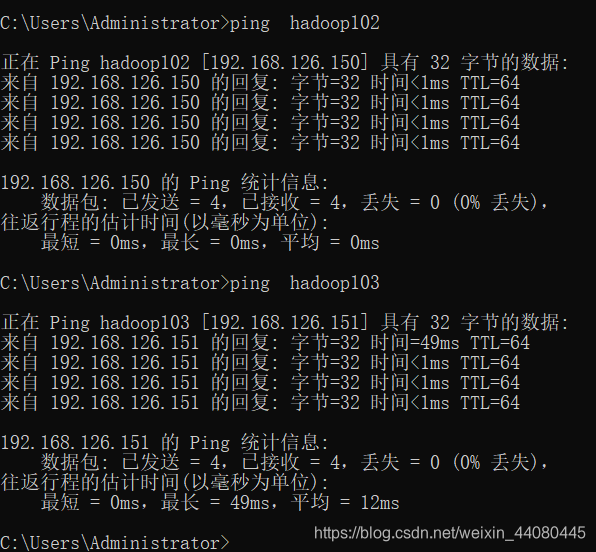
在windows里面 编辑C:\Windows\System32\drivers\etc\hosts 这个文件,然后加上IP 映射关系 ,加的内容和上面的一样,在这一步的时候做完一定要去相互ping一下,hadoop102,103,104互相用IP地址和主机名看是否能ping通,并且在windows里面也要ping下linux的hasoop102,103,104看是否能ping通,这样的话才算IP映射配成功。
6.利用远程工具连接虚拟机,这里我使用的是Xshell5连接的虚拟机,另外在下载一个filezilla这个软件,它可以和linux相互传文件。
7.在hadoop102上面的的opt目录下创建两个子目录software和module
mkdir software
mkdir module
在先用filezilla这个软件连接hadoop102,然后找到/opt/software,然后双击hadoop和jdk的tar包文件就自动保存到在了software目录里面。
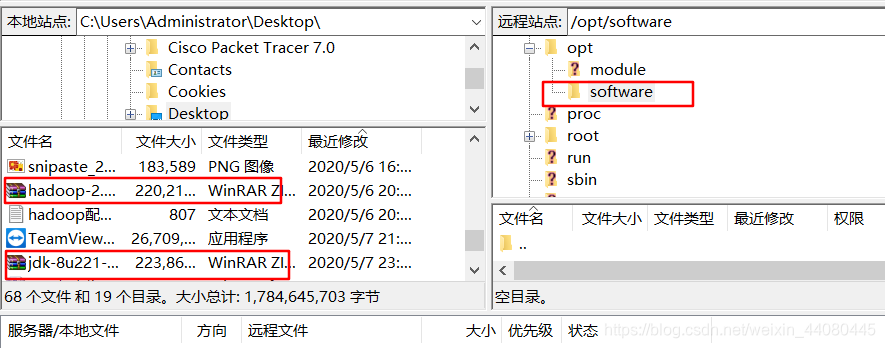
8 .分别解压jdk和hadoop到/opt/module下。


- 在hadoop102上面配置配置jdk和hadoop环境变量。
(1)配置jdk环境变量
打开/etc/profile
vi /etc/profile
进去以后先按a(插入文本)然后去文件的最后一行在里面添加如下内容(其中JAVA_HOME为安装jdk的路径)
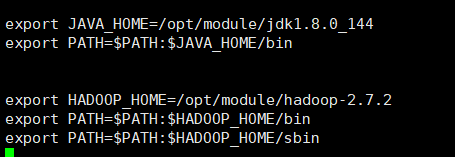
export JAVA_HOME=/opt/module/jdk1.8.0_144
export PATH=$PATH:$JAVA_HOME/bin
vi /etc/hosts
wq保存退出,然后在 source /etc/profile (目的是让修改后的文件生效)
最后输入java -version,如果出现了下图的内容说明你jdk安装成功了

(2)配置hadoop环境变量
打开/etc/profile , vi /etc/profile
进去以后再刚才添加jdk环境变量的后面添加如下内容
export HADOOP_HOME=/opt/module/hadoop-2.7.2
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
wq保存退出,然后 source /etc/profile
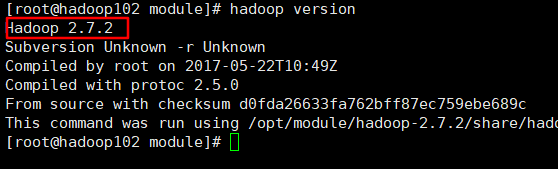
输入hadoop version,如果出现了下图的内容说明你hadoop安装成功了
- SSH 免密登录
生成公钥和私钥 : ssh-keygen -t rsa (步骤1)
然后敲三个回车,就会生成两个文件id_rsa(私钥),id_rsa.pub(公钥)
生成如下的内容。
将公钥拷贝到要免密登录的目标机器上(每次执行下面的命令要输入对应主机的密码):
ssh-copy-id hadoop102 (步骤2)
ssh-copy-id hadoop103 (步骤3)
ssh-copy-id hadoop104 (步骤4)
在hadoop103,hadoop104上面分别执行上面的步骤1,2,3,4
- 集群的规划:
namenode为主节点,SecondaryNameNode部署在hadoop104上面,
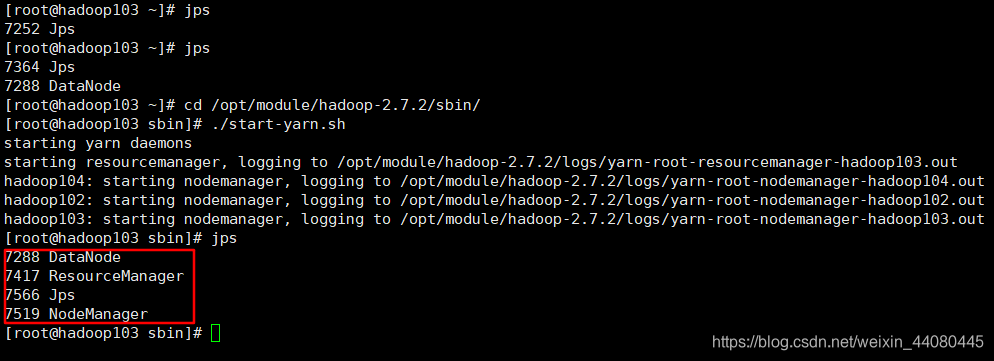
ResourceManager部署在hadoop103上面。

- 配置集群,一共要配置4个文件,这四个文件都在/opt/module/hadoop-2.7.2/etc/hadoop中。
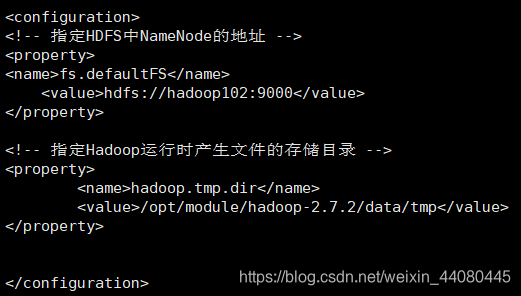
(1) 配置core-site.xml ,将如下内容添加到和中间,添加完以后别忘记了wq保存退出 (后续添加内容的话也是添加到和中)
<!-- 指定HDFS中NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop102:9000</value>
</property>
<!-- 指定Hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-2.7.2/data/tmp</value>
</property>
(2)配置 hdfs-site.xml ,添加如下内容
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!-- 指定Hadoop辅助名称节点主机配置 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop104:50090</value>
</property>
(3)配置yarn-site.xml,添加如下内容
<!-- Reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定YARN的ResourceManager的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop103</value>
</property>
<!-- 日志聚集功能使能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 日志保留时间设置7天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
(4)配置 mapred-site.xml,注意在配置这个文件之前当前目录里面是没有这个文件的,但是当前目录里面有mapred-site.xml.template这个文件。
我们先复制一份 cp mapred-site.xml.template mapred-site.xml
然后在 vi mapred-site.xml
在里面添加如下内容
<!-- 指定MR运行在YARN上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- 历史服务器端地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop102:10020</value>
</property>
<!-- 历史服务器web端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop102:19888</value>
</property>
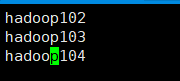
- 群起集群,在hadoop102上进入/opt/module/hadoop-2.7.2/etc/hadoop目录下找到 slaves 这个文件, vi slaves 在里面添加如下内容然后保存退出。(这一步是配置datanode节点分别是哪些)
一定要注意在写入内容时不要多出来空行和其他内容否则后面启动集群会有问题。
错误样例:
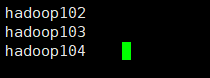
正确样例:
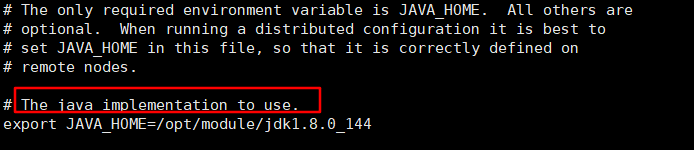
- 在hadoop102上面配置/opt/module/hadoop-2.7.2/etc/hadoop里面的三个脚本文件
hadoop-env.sh、yarn-env.sh、mapred-env.sh(先说明一下在这三个配置中都是添加 export JAVA_HOME=/opt/module/jdk1.8.0_144 这个内容) ,写入的位置还挺难找的,下面我为大家找一下。)
对于hadoop-env.sh在我标注的这一行下面加入这行内容
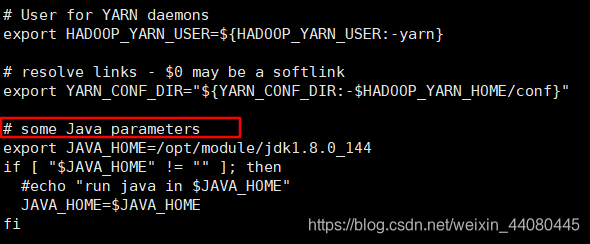
对于yarn-env.sh,大概在第20行的位置就可以看到对应的位置了(注意红框下面的一行开头注释 # 需要删掉)。
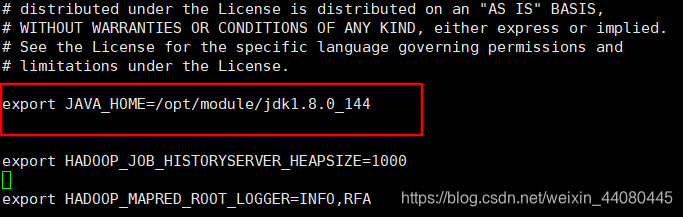
对于mapred-env.sh这个文件最好找了,直接在中间添加内容就可以了(注意开头的注释要去掉)
15.拷贝配置文件和hadoop到hadoop103和hadoop104,在hadoop102上面分别执行如下操作。(cp为拷贝,scp为安全拷贝的意思)
scp -r /etc/profile root@hadoop103:/etc/profile
scp -r /etc/profile root@hadoop104:/etc/profile
执行完以后切记一定要去hadoop103和hadoop104上面执行 source /etc/profile,要不然环境变量不会生效。
然后在hadoop103和hadoop104打开/etc/profile查看有没有如下内容,如果没有的话那就手动把第9步在走一遍.
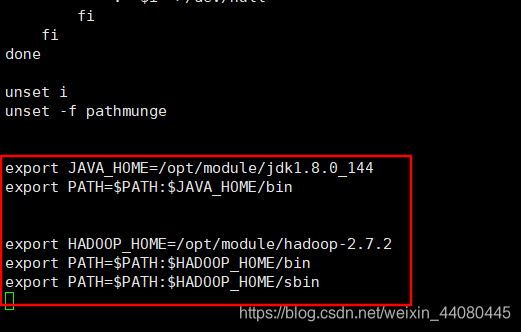
在hadoop102上面执行:
scp -r /opt/module root@hadoop103:/opt/module
scp -r /opt/module root@hadoop104:/opt/module
然后再去hadoop103和hadoop104的 /opt/module/hadoop-2.7.2/etc/hadoop查看有没有第12步中那4个文件的具体信息,和hadoop102中配置文件信息一样即为执行成功。
16 .第一次启动集群要格式化,往后在启动集群就不用了。
hadoop102进入 /opt/module/hadoop-2.7.2 这个目录执行
bin/hdfs namenode -format

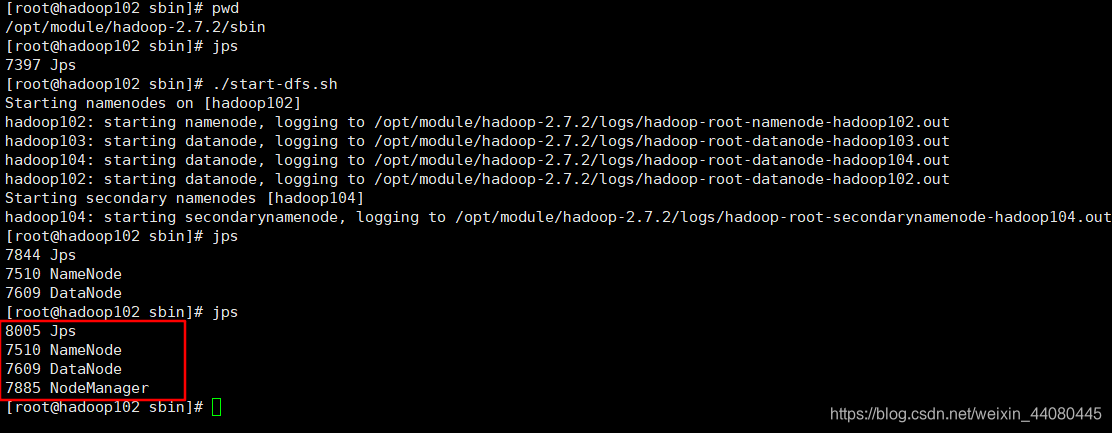
格式化完成以后就可以启动集群了,在hadoop102的/opt/module/hadoop-2.7.2/sbin 目录执行./start-dfs.sh
然后去hadoop103 的/opt/module/hadoop-2.7.2/sbin 目录执行 ./start-yarn.sh
执行结果:hadoop102:
第二次执行jps多了一个 NodeManager是因为在hadoop103中开启了yarn
hadoop103中:
hadoop104中:
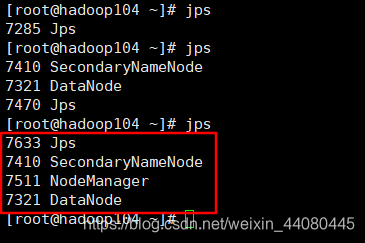
这里在次贴上之前的集群规划会发现每台集群上面的机器和部署的完全一致

最后让我们再去wed端查看一下hadoop
web端的端口为50070
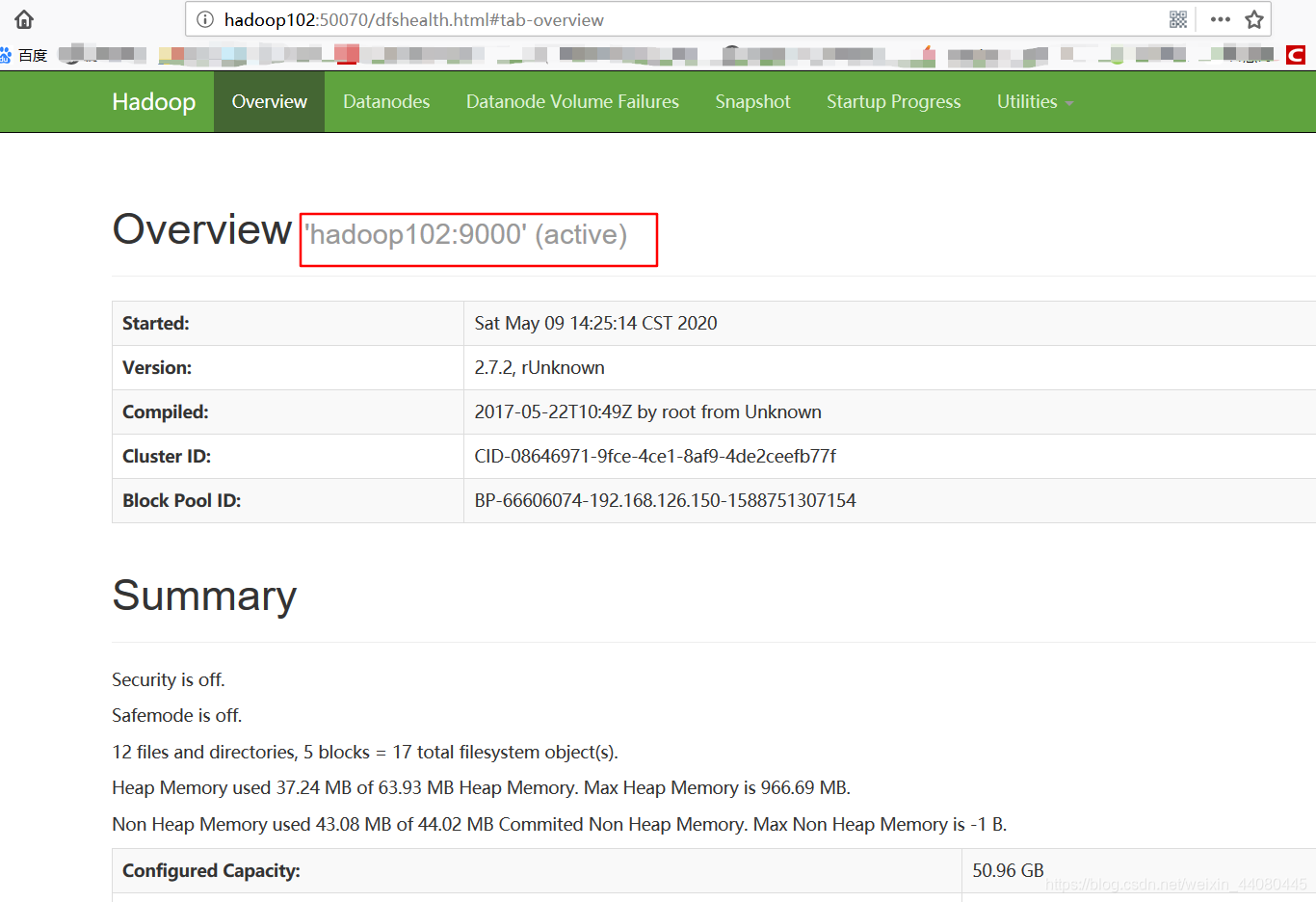
ok这就大功告成啦。
最后加上启动hadoop历史服务器的命令
sbin/mr-jobhistory-daemon.sh start historyserver
关闭
sbin/mr-jobhistory-daemon.sh stop historyserver
查看历史服务器
mapred-site.xml文件中配置的主机名:19888














 5508
5508











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









