







数据的导入:
1.向已经建立好的表中加载数据:
语法: load data [local] inpath ‘/opt/module/datas/student.txt’ [overwrite] | into table tablename [partition (partcol1=val1,…)];
中括号代表可以省略。
参数意义:
local: 表示从本地加载数据到hive表;否则从HDFS加载数据到hive表。
overwrite:表示覆盖表中已有数据,否则表示追加。
partition:表示上传到指定分区。
2.直接插入数据或者是通过查询语句向表中插入数据:
1)直接插入数据:
insert into table tab1 values(101,‘tom’);
2)通过查询语句向表中插入数据:
insert into table tab1 select * from tab2;
2)通过查询语句向表中追加数据:
insert overwrite table tab1 select * from tab2;
(这时从表2查询的字段数必须和表1的字段数相同)
带有分区的表:
insert overwrite table student partition(month=‘201708’)
select id, name from student where month=‘201709’;
3.查询语句中创建表并加载数据(As Select)
根据查询结果创建表(查询的结果会添加到新创建的表中)
create table if not exists test3 as select id,name from test1;
4.创建表时通过Location指定加载数据路径
1)创建表,并指定在hdfs上的位置
create table if not exists test3(id int ) row format delimited fields terminated by ‘\t’ location ‘/mo/hive/test3’;(注意这里还要在hive的里面再加一个目录才行,不加的话建表以后看不到表)
2).上传数据到hdfs上
dfs -put /demo/b.txt /mo/hive/test7;(注意这里必须是dfs ,前面加一个hdfs反而会报错)
3).查询数据
5.Import数据到指定Hive表中。
数据的导出:
1.Insert导出
1).将查询的结果导出到本地
insert overwrite local directory ‘/opt/module/datas/export/student’
select * from student; (不加local的话导出到hdfs文件系统中去)
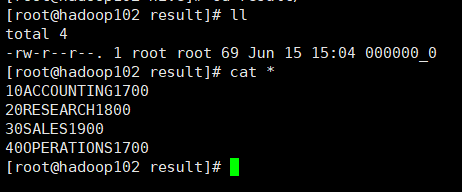
2)将查询的结果格式化导出到本地(对于1来说,导出的数据不会按照我们想要的格式给我们整理好,需要我们手动指明如何格式化数据)

其实Insert导出数据有一个小坑,链接地址。
2.通过Hadoop命令导出到本地。
dfs -get /user/hive/warehouse/test3/000000_0
/demo/hive/aaa.txt;
3.使用 Hive Shell 命令导出。
基本语法:(hive -f/-e 执行语句或者脚本 > file)
bin/hive -e ‘select * from default.student;’ >
/opt/module/datas/export/student4.txt;
4.Export导出到HDFS上
export table default.student to
‘/user/hive/warehouse/export/student’;
5.Sqoop导出
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









