







题目要求


数据集部分预览

pom文件:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<parent>
<artifactId>Spark</artifactId>
<groupId>org.example</groupId>
<version>1.0-SNAPSHOT</version>
</parent>
<modelVersion>4.0.0</modelVersion>
<artifactId>SparkSql</artifactId>
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>2.1.1</version>
</dependency>
</dependencies>
</project>
代码:
package com.demo
import org.apache.log4j.{Level, Logger}
import org.apache.spark
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.sql._
import org.apache.spark.storage.StorageLevel
case class log(Id:String,Content_id:String,Page_path:String,Userid:String,Sessionid:String,data_time:String)
object DataFrameTxt{
def main(args: Array[String]) {
Logger.getLogger("org.apache.spark").setLevel(Level.ERROR)
val spark = SparkSession
.builder()
.master("local[*]")
.appName("log_test")
.getOrCreate()
System.setProperty("HADOOP_USER_NAME", "root")
import spark.implicits._
val input = spark.sparkContext.textFile("C:\\Users\\Administrator\\Desktop\\jc_content_viewlog.txt")
val ds2 = input.map(_.split(",")).filter(_.length == 6).map(p =>
log(p(0),p(1),p(2).replaceAll("_[2345]+", "").replaceAll("_1..", ""),
p(3),p(4),p(5).trim.split(" ")(1).substring(0,5))).toDS //except 3
// ds2.show(5)关于之前的6
ds2.createOrReplaceTempView("ds_table2")
val Content_id_sum=spark.sql("SELECT COUNT(DISTINCT Content_id) as number FROM ds_table2 ")
Content_id_sum.rdd.repartition(1).saveAsTextFile("hdfs://hadoop102:9000/user/outfiles/out1")//网页去重
val Userid_id_sum = spark.sql("SELECT COUNT(DISTINCT Userid) FROM ds_table2")
Userid_id_sum.rdd.repartition(1).saveAsTextFile("hdfs://hadoop102:9000/user/outfiles/out2")//用户去重
val problem_4= spark.sql("SELECT Userid,COUNT(Userid) as number FROM ds_table2 group by Userid having COUNT(Userid)>50")
problem_4.persist(StorageLevel.MEMORY_ONLY) //过滤出实训访问次数在50次以上用户的记录并持久化到内存
problem_4.rdd.repartition(1)saveAsTextFile("hdfs://hadoop102:9000/user/outfiles/out4")
val res = spark.sql("SELECT first(Userid) as Userid,first(Content_id) as Content_id FROM ds_table2 " +
"group by Userid having count(Userid) >50 order by Content_id desc limit 5")
//统计访问50次以上的用户主要访问前5类网页.
res.rdd.repartition(1).saveAsTextFile("hdfs://hadoop102:9000/user/outfiles/out5")
ds2.rdd.repartition(1)saveAsTextFile("hdfs://hadoop102:9000/user/outfiles/out6") //url翻页网址
val visit_situation = spark.sql("select a.Userid , b.time_axis , count(*) as sum from ds_table2 as a ,(SELECT\n CASE\nWHEN data_time >='06:30' and data_time<'11.30' THEN\n '上午'\nWHEN data_time >= '11:30' and data_time<'14:00' THEN\n '中午'\nWHEN data_time >='14:00' and data_time<'17.30' THEN\n '下午'\nWHEN data_time >= '17:30' and data_time<'19:00' THEN\n '傍晚'\nWHEN data_time >='19:00' and data_time<'23:00' THEN\n '晚上' \nELSE\n '深夜'\nEND AS time_axis ,\nUserid, data_time \nFROM\n ds_table2) as b where a.Userid = b.Userid group by a.Userid,b.time_axis")
visit_situation.rdd.repartition(1).saveAsTextFile("hdfs://hadoop102:9000/user/outfiles/out7") //按时间统计.
println("success")
spark.stop()
}
}
注:在上述代码中第三题没有实现,因为样例类的处理不适合第三题,所以第三题我们单独创一个样例类然后执行相应的sql语句
case class log_3(Id:String,Content_id:String,Page_path:String,Userid:String,Sessionid:String,data_time:String)
val ds = input.map(_.split(",")).filter(_.length == 6).map(p =>
log_3(p(0),p(1),p(2),p(3),p(4),p(5).trim.split(" ")(0).split("-")(1))).toDS
ds.createOrReplaceTempView("ds_table")
val countby_month = spark.sql("SELECT data_time , count(*) as records FROM ds_table group by data_time ")
countby_month.show() //按月统计访问记录数
按月份统计展示

其余的结果展示
1.对访问记录中的网页去重,统计本周期内被访问网页的个数;
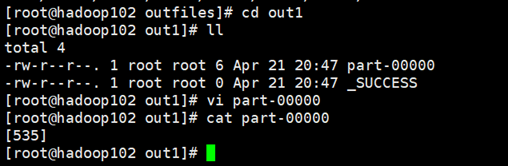
2.userid为用户注册登录的标识,对userid去重,统计登录用户的数量。

4.过滤出实训中访问次数在50次以上的用户记录并持久化到内存;

5.统计访问50次以上的用户主要访问的前5类网页;

6.合并部分网页URL后面带有_1、_2字样的翻页网址,统一为一个网址。

7.统计用户各时段访问情况

想要源文件的可以联系我 qq:1164240630
或者CSDN留言
注:如果处理好的文件放在HDFS上因为权限出错,可以参考我的上一篇博文,https://blog.csdn.net/weixin_44080445/article/details/115974528
或者你也可以将处理好的文件直接输出到windows本地.















 778
778











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









