







上节说到在mysql中我们很容易使用group_concat(具体用法)
但是在hive中很遗憾的是没有这个函数
那我们如何在不使用UDF函数的情况下使用它呢: 那就是使用hive中自带的collect_list/collect_set加上concat_ws函数
关于collect_list/collect_set的区别请参考下此篇文章
https://blog.csdn.net/LINBE_blazers/article/details/89198019
直接上实例,先看一下我们的表数据和字段结构
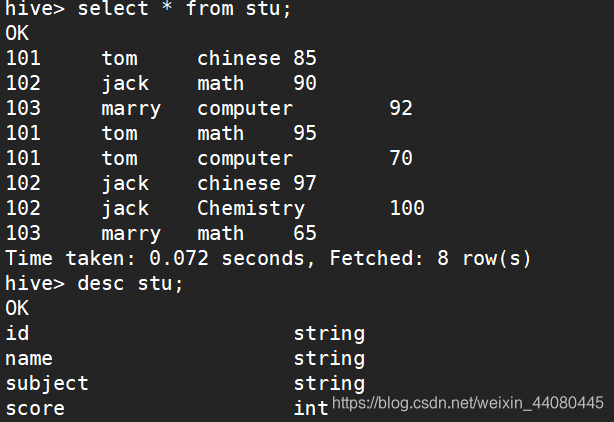
我们的需求是按名字分组,每行显示名字,所选的所有科目(要求@符号连接),所有的科目对应的成绩(要求-符号连接)
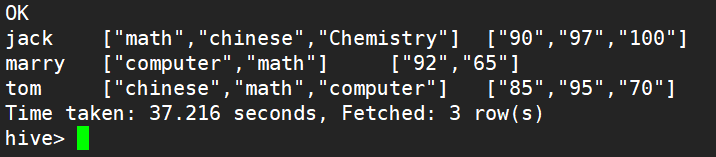
1).先使用collect_set函数使多行成为一行数组
hive> select name,collect_set(subject) res1 ,
> collect_set(cast(score as string)) res2
> from stu group by name;
2). 加上concat_ws函数可以取出数组中的每一个元素的值在用分隔符连接
hive> select name,concat_ws('@',collect_set(subject)) res1 ,
> concat_ws('-',collect_set(cast(score as string))) res2
> from stu group by name;

这样我们在hive中最终实现了mysql中的group_concat函数.














 841
841











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









