






鸽了一年没有更新了。以下内容主要分为两部分:一是写爬虫获取全国的火车站信息(包括站名、站点经纬度、经过的列车车次、车次总数量)、列车信息(列车车次、类型、出发到达时间、全程时长、沿途站点);二是利用上述信息做简单的数据展示。不多BB,上代码:
一、爬虫代码
(1)导入爬虫需要的包,设置浏览器请求头
import requests
import pandas as pd
import re
from tqdm import tqdm
#浏览器请求头
headers={
'user-agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3741.400 QQBrowser/10.5.3868.400'
}
(2)定义Train类,获取全国火车站的信息及列车信息。获取火车站信息的爬虫需要一层层写,首先获取全国省份、直辖市名字(Province_url函数),然后通过拼接网站域名获取所有的站点名(Station_name函数),最后利用爬虫获取所有火车站的信息(Station_information函数)。列车车次信息可以直接通过拼接域名直接爬取(Train_information函数)。
这里面获取经纬度时需要使用百度地图的密匙,我直接把个人的密匙放进去了可以直接用,当然还是建议自己去申请一个,免得爬的次数多了不知道会出什么幺蛾子ヽ(ー_ー)ノ。
class Train:
def __init__(self):
pass
#获取所有的省、直辖市名字
def Province_url(self):
self.province_url = []
out_url = 'https://qq.ip138.com/train/'
response = requests.get(out_url,headers = headers)
result = re.findall(r'<dd><a href="/train/(.*?)" target="', response.text)
for province in result:
self.province_url.append(out_url + province)
#获取所有车站名
def Station_name(self):
self.station_name = []
self.station_name_pinyin = []
for province_url in self.province_url[]:
try:
response = requests.get(province_url,headers = headers)
response.encoding = 'utf-8'
station_name = re.findall(r'<a href="/train/.*?" target="_blank">(.*?)</a></li>',response.text)
self.station_name.append(station_name)
station_name_pinyin = re.findall(r'<a href="/train/(.*?)" target="_blank">.*?</a></li>',response.text)
self.station_name_pinyin.append(station_name_pinyin)
except:
print('{}链接获取失败'.format(province_url))
pass
self.station_name = [item for sublist in self.station_name for item in sublist]
self.station_name_pinyin = [item for sublist in self.station_name_pinyin for item in sublist]
print('成功获取{}个站点名'.format(len(self.station_name)))
#获取所有车站的信息
def Station_information(self):
self.station_data = []
self.train_num = []
for i in tqdm(range(len(self.station_name))):
url_1 = 'https://qq.ip138.com/train/' + self.station_name_pinyin[i]
try:
response = requests.get(url_1,headers = headers)
response.encoding = 'utf-8'
train_num = re.findall(r'<a href="/train/.*?.htm" target="_blank"><b>(.*?)</b></a>',response.text)
train_num_count = len(train_num)
self.train_num.append(train_num)
except:
print('{}站车次信息获取失败'.format(self.station_name[i]))
pass
station_name = self.station_name[i] + '站'
try:
#获取经纬度,这里的AG开头后面的一长串就是百度地图密匙
url_2 = 'https://api.map.baidu.com/geocoding/v3/?address={}&output=json&ak=AG4BbquVB87KwW1hS6wCMQRx1PYKNqhj'.format(station_name)
dic = requests.get(url_2).json()
lng = dic['result']['location']['lng']
lat = dic['result']['location']['lat']
#这里面有很多站点并不是火车站,使用一个if语句过滤那些不是火车站的站点
if dic['result']['level'] == '火车站':
data = {
'station_name':station_name,
'lacation':str(lng) + ',' + str(lat),
'train_num':train_num,
'train_num_count':train_num_count
}
print(data)
self.station_data.append(data)
else:
print('{}不属于火车站!'.format(station_name))
except:
pass
self.train_num = [item for sublist in self.train_num for item in sublist]
self.train_num = list(set(self.train_num))
result = pd.DataFrame(self.station_data)
result.to_csv('Station_infomation.csv')
#获取所有的列车信息
def Train_information(self):
self.train_data = []
for train in tqdm(self.train_num[]):
try:
url = 'https://qq.ip138.com/train/' + train + '.htm'
response = requests.get(url,headers = headers)
response.encoding = 'utf-8'
train_info_1 = re.findall(r'<span>(.*?)</span>',response.text)
train_info_2 = re.findall(r'<a href="/train/.*?.htm" target="_blank">(.*?)</a>',response.text)
train_num,category,departure_time,arrival_time,elapsed_time = train_info_1[9],train_info_1[7],train_info_1[12],train_info_1[15],train_info_1[17]
data = {'train_num':train_num,
'category':category,
'departure_time':departure_time,
'arrival_time':arrival_time,
'elapsed_time':elapsed_time,
'stations_alone_way':train_info_2[2:]
}
print(data)
self.train_data.append(data)
except:
print('获取失败')
pass
train_infor = pd.DataFrame(self.train_data)
train_infor.to_csv('train_infor.csv')
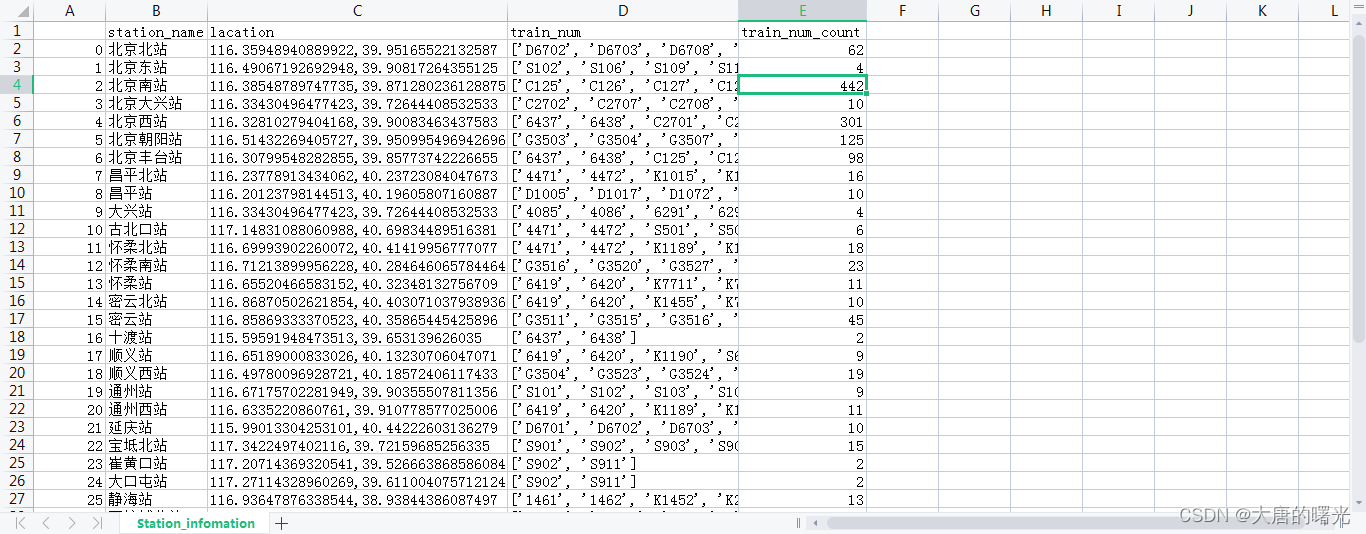
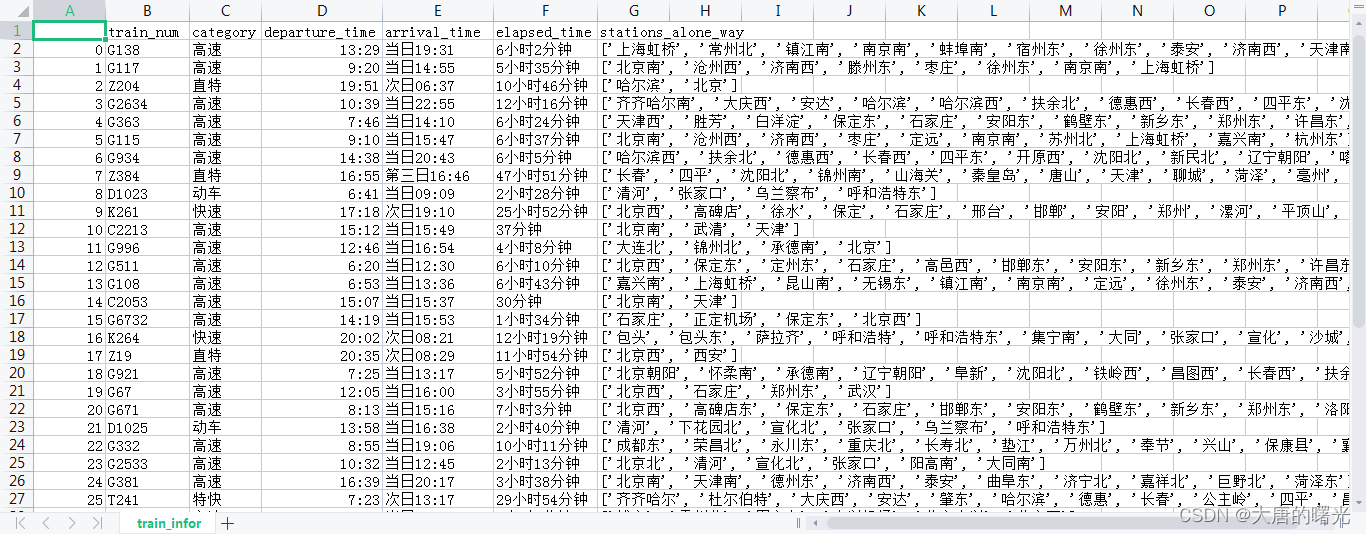
(3)运行爬虫结果如下,得到全国火车站信息以及列车车次信息。
结果全国共有3036个火车站,8157个车次。
这里只截取了部分表,整个程序跑完估计要一个小时,而且过于频繁请求人家网站容易崩(我就给整崩了3次)。
二、数据展示
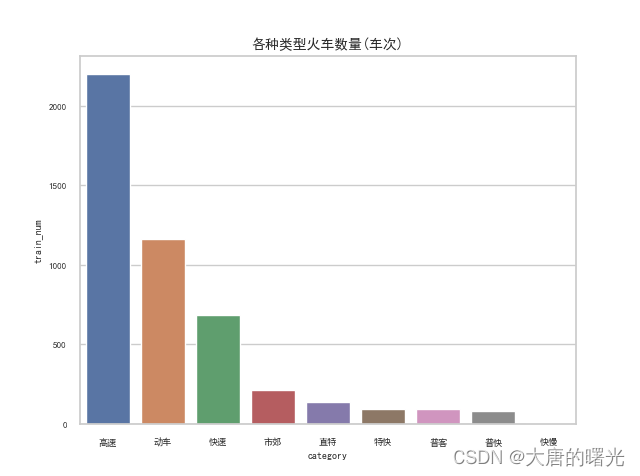
(1)来看一下全国火车各种类型的分布。可以看出高铁(高速)动车已经占绝大多数,其余的快车、特快等数量已经非常少了,虽然我从来都不坐也没见多少ヽ(ー_ー)ノ
import pandas as pd
import seaborn as sns
data = pd.read_csv('train_data_0.csv',encoding='utf-8')
sns.set(style = "whitegrid",font_scale = 0.6,font = "simhei")
df = data.groupby('category')['train_num'].count().sort_values(ascending = False).to_frame().reset_index()
sns.barplot(x = 'category',y = 'train_num',data = df.head(10)).set_title('各种类型火车数量(车次)',fontsize = 7)
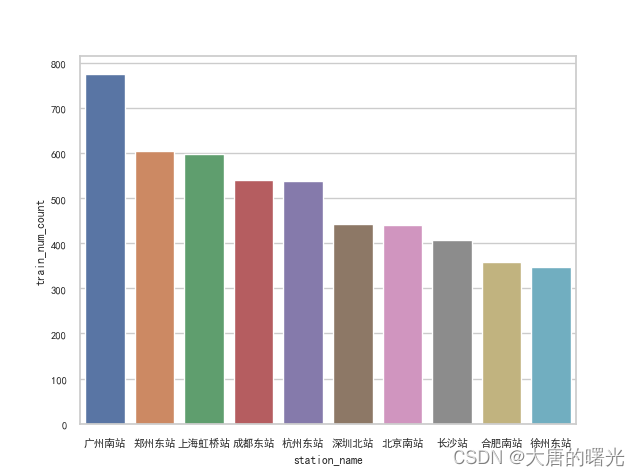
(2)上面已得出每个火车站所经过的车次,据此看一下全国哪个火车站最忙。
从下面可以看出全国最忙的车站是广州南站,有将近800趟列车会路过,其次是郑州东和上海虹桥的600趟,北上广人(da)口(gong)数(zai)最多,郑州作为全国铁路的枢纽不出意外都在榜上。
data = pd.read_csv('Station_infomation.csv')
data = data[['station_name','lacation','train_num','train_num_count']]
data.sort_values(by = 'train_num_count', inplace = True, ascending = False)
sns.barplot(x = 'station_name',y = 'train_num_count',data = data.head(10)).set_title('全国车流量前十车站(车次)',fontsize = 10)
(3)利用高德地图API,展示全国火车站:
其中点的大小表示火车站的繁忙程度,点越大经过的车次越多。
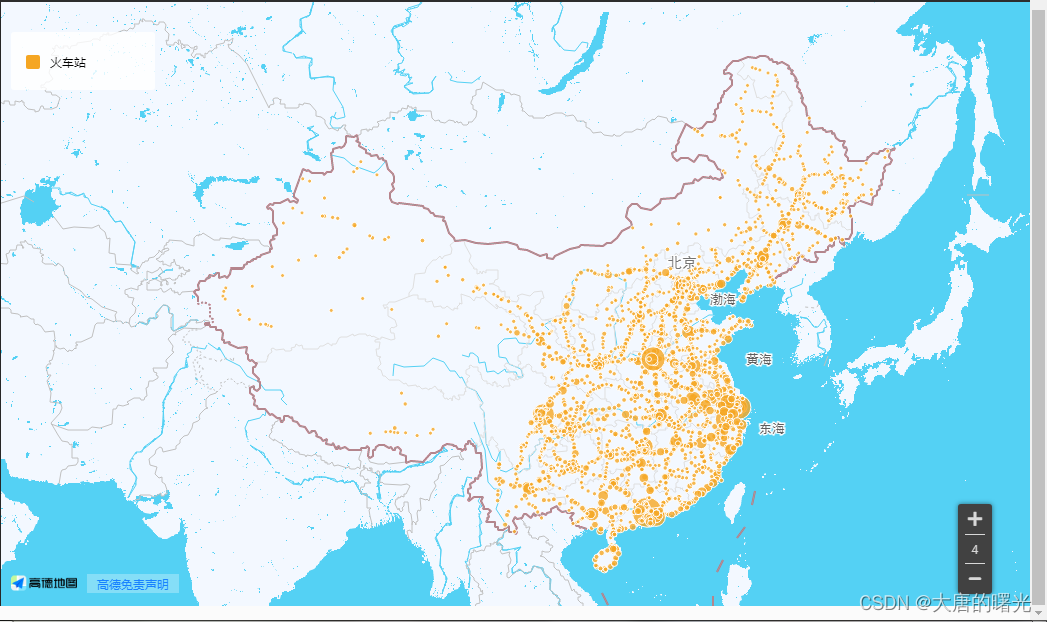
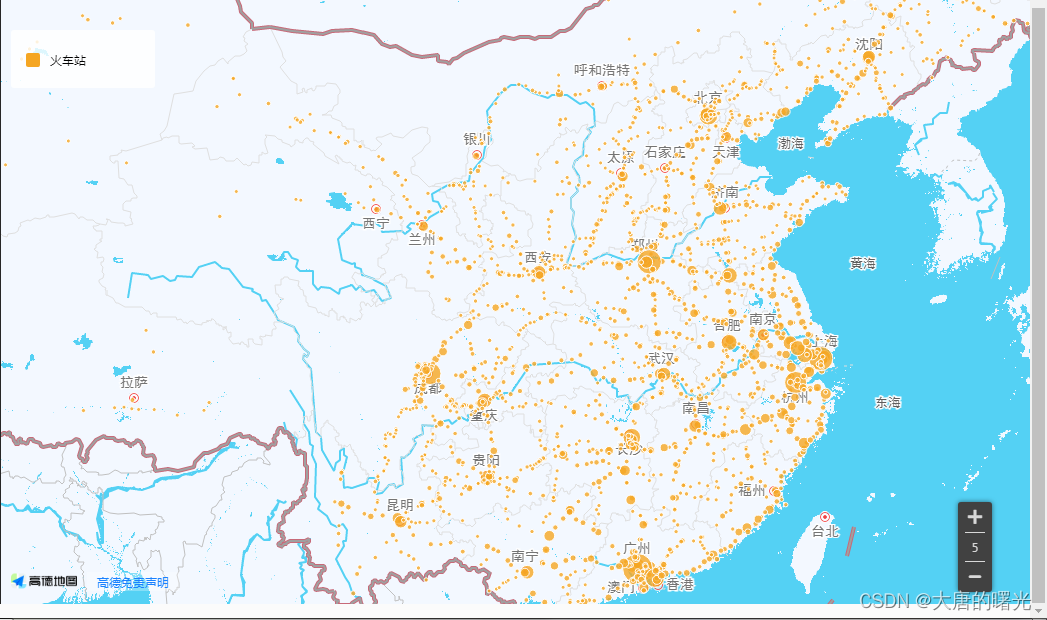
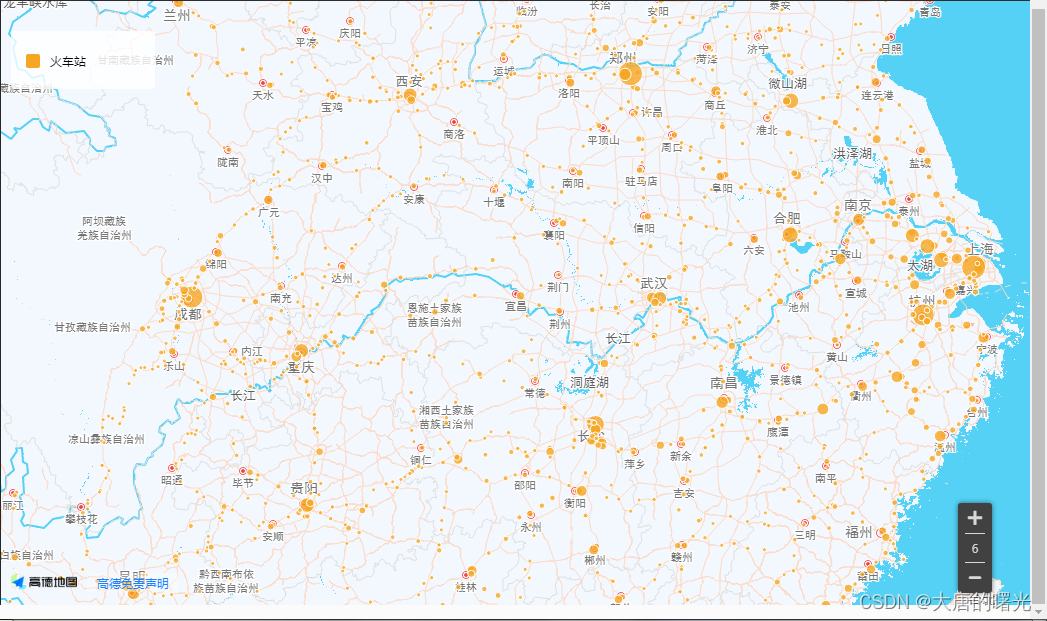
这个链接是高德地图绘制的成果,可以自行查看(虽然有可能被吞)https://visual.amap.com/share/mapv/95fd5e70a6af48bf6b0eba8f4909a729
(3)来看一下全国运行时间最长的列车是哪几个:
import numpy as np
np.set_printoptions(threshold = 1e6)
data['elapsed_time_minute'] = None
for i in range(len(data)):
if len(data['elapsed_time'][i]) > 5:
result = re.findall(r'(.*?)小时(.*?)分钟',data['elapsed_time'][i])
data['elapsed_time_minute'][i] = eval(result[0][0]) * 60 + eval(result[0][1])
else:
minute = data['elapsed_time'][i].split('分')[0][0]
data['elapsed_time_minute'][i] = int(minute)
data['start_end'] = None
for i in range(len(data)):
data['start_end'][i] = eval(data['stations_alone_way'][i])[0] + ' - ' + eval(data['stations_alone_way'][i])[-1]
data.sort_values(by = 'elapsed_time_minute', inplace = True, ascending = False)
print(data.head(10)[['train_num','elapsed_time','category','departure_time','arrival_time','start_end']])
运行结果:
train_num elapsed_time category departure_time arrival_time start_end
989 K4032 67小时54分钟 快速 13:56 第四日09:50 克拉玛依 - 济南
328 K2287 59小时41分钟 快速 18:32 第四日06:13 昆明 - 长春
547 K727 59小时3分钟 快速 10:00 第三日21:03 广州东 - 牡丹江
1517 K2288 58小时59分钟 快速 19:09 第四日06:08 长春 - 昆明
588 K998 57小时10分钟 快速 20:39 第四日05:49 成都西 - 海拉尔
991 K997 56小时32分钟 快速 7:36 第三日16:08 海拉尔 - 成都西
1018 K2387 54小时54分钟 快速 22:15 第四日05:09 南宁 - 长春
1380 K728 54小时31分钟 快速 15:08 第三日21:39 牡丹江 - 广州东
813 K2388 53小时1分钟 快速 11:46 第三日16:47 长春 - 南宁
440 T303 52小时46分钟 特快 14:07 第三日18:53 沈阳北 - 乌鲁木齐
(4)地图展示运行时间最长的列车:
import pandas as pd
import re
data = pd.read_csv('train_data_1.csv')
del data['num']
data['stations_num'] = None
for i in range(len(data)):
data['stations_num'][i] = len(eval(data['stations_alone_way'][i]))
data['elapsed_time_minute'] = None
for i in range(len(data)):
if len(data['elapsed_time'][i]) > 5:
result = re.findall(r'(.*?)小时(.*?)分钟',data['elapsed_time'][i])
data['elapsed_time_minute'][i] = eval(result[0][0]) * 60 + eval(result[0][1])
else:
minute = data['elapsed_time'][i].split('分')[0][0]
data['elapsed_time_minute'][i] = int(minute)
data['start_end'] = None
for i in range(len(data)):
data['start_end'][i] = eval(data['stations_alone_way'][i])[0] + ' - ' + eval(data['stations_alone_way'][i])[-1]
data.sort_values(by = 'elapsed_time_minute', inplace = True, ascending = False)
data_1 = data.head(10).copy()
station_name_total = []
for x in range(len(data_1)):
station_location = []
station_name = eval(data_1['stations_alone_way'].iloc[x])
station_name_total.append(station_name)
#%%
print(station_name_total[0],len(station_name_total[0]))
import requests
def Get_location(station_name_lst):
data = []
for station_name in station_name_lst:
station_name += '站'
try:
url = 'https://api.map.baidu.com/geocoding/v3/?address={}&output=json&ak=AG4BbquVB87KwW1hS6wCMQRx1PYKNqhj'.format(station_name)
dic = requests.get(url).json()
lng = dic['result']['location']['lng']
lat = dic['result']['location']['lat']
data.append('[{},{}]'.format(lng,lat))
except:
print('{}找不到'.format(station_name))
return data
data_2 = []
for i in range(len(station_name_total[0]) - 1):
da = Get_location(station_name_total[0])
data_tmp = {'start':station_name_total[0][i],
'end':station_name_total[0][i + 1],
'location':'{},{}'.format(eval(da[i]),eval(da[i + 1]))
}
data_2.append(data_tmp)
print(data_2)
data_2_df = pd.DataFrame(data_2)
data_2_df.to_csv('5.csv')
这里需要分步展示,在调用高德地图API时还需要进行相应的数据处理,处理的过程比较细碎就不放上来啦,仅仅展示最后的图,不知道为什么广州-牡丹江的车会在江西绕一个圈子:
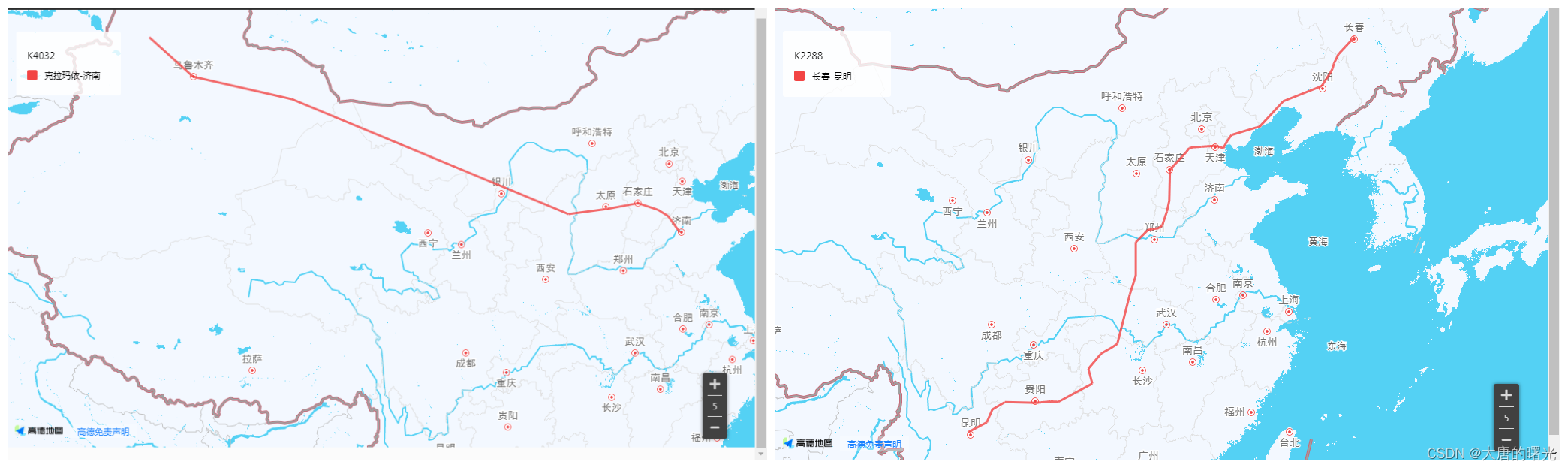
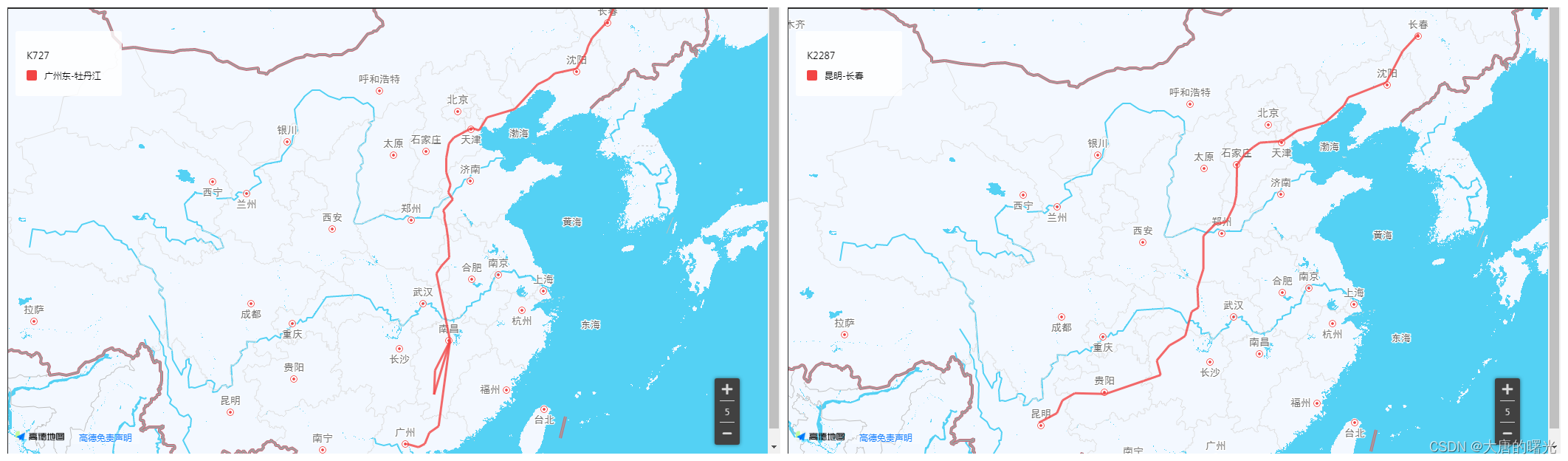
限于时间和水平,数据展示的内容就只有这么多了,终于写完啦!

















 1433
1433

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









