






048 基于Python机器学习的电影票房数据分析系统-设计展示
项目概述
本项目构建了一个基于 Python 机器学习的电影票房数据分析系统,整合多领域技术,全方位剖析电影票房数据,为电影行业从业者、研究者及爱好者提供深度洞察与决策支持。通过系统性的数据抓取、多元的分析手段、直观的可视化呈现以及精准的预测模型,挖掘电影市场的潜在规律与商业价值。
数据支撑
系统的数据基础源于精心设计的Movie模型,涵盖电影的丰富属性。从电影的基本标识(如 ID)、核心信息(类型、导演、名称、上映日期、评分等),到票房相关数据(预售票房、总票房),再到观众特征数据(性别占比、城市占比)以及扩展信息(描述、额外信息)等,一应俱全。目前已成功抓取 2015 - 2025 年的 4400 部电影数据,并借助 Scrapy 爬虫实现定时更新,确保数据的时效性与完整性。
核心功能解析
- 数据抓取:运用 Scrapy 框架编写高效爬虫,能够自动且周期性地抓取历年电影票房数据。不仅覆盖了模型中定义的所有字段,还能根据设定的时间计划,及时更新最新电影数据,为系统后续的分析与应用提供持续的数据源泉。
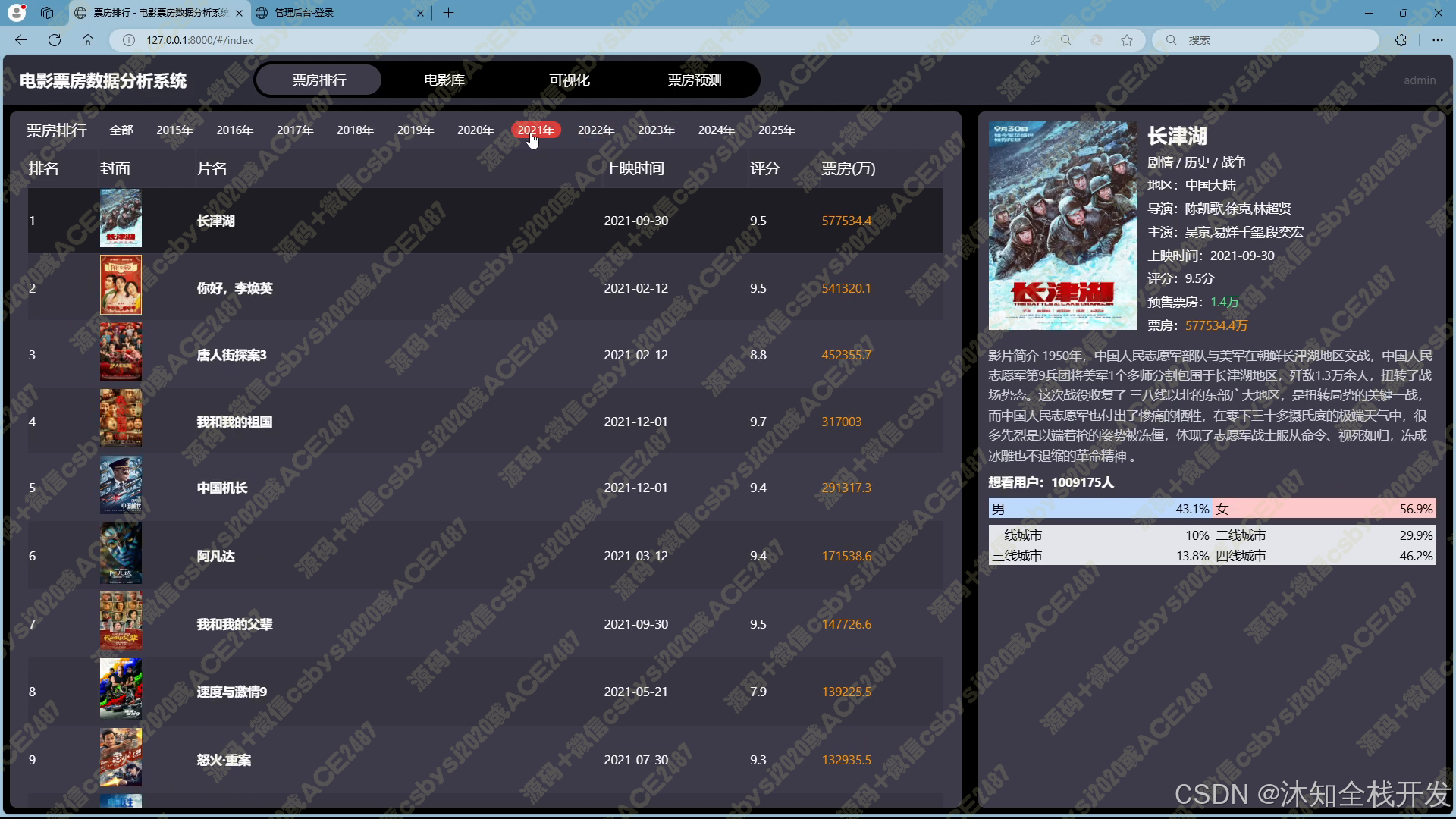
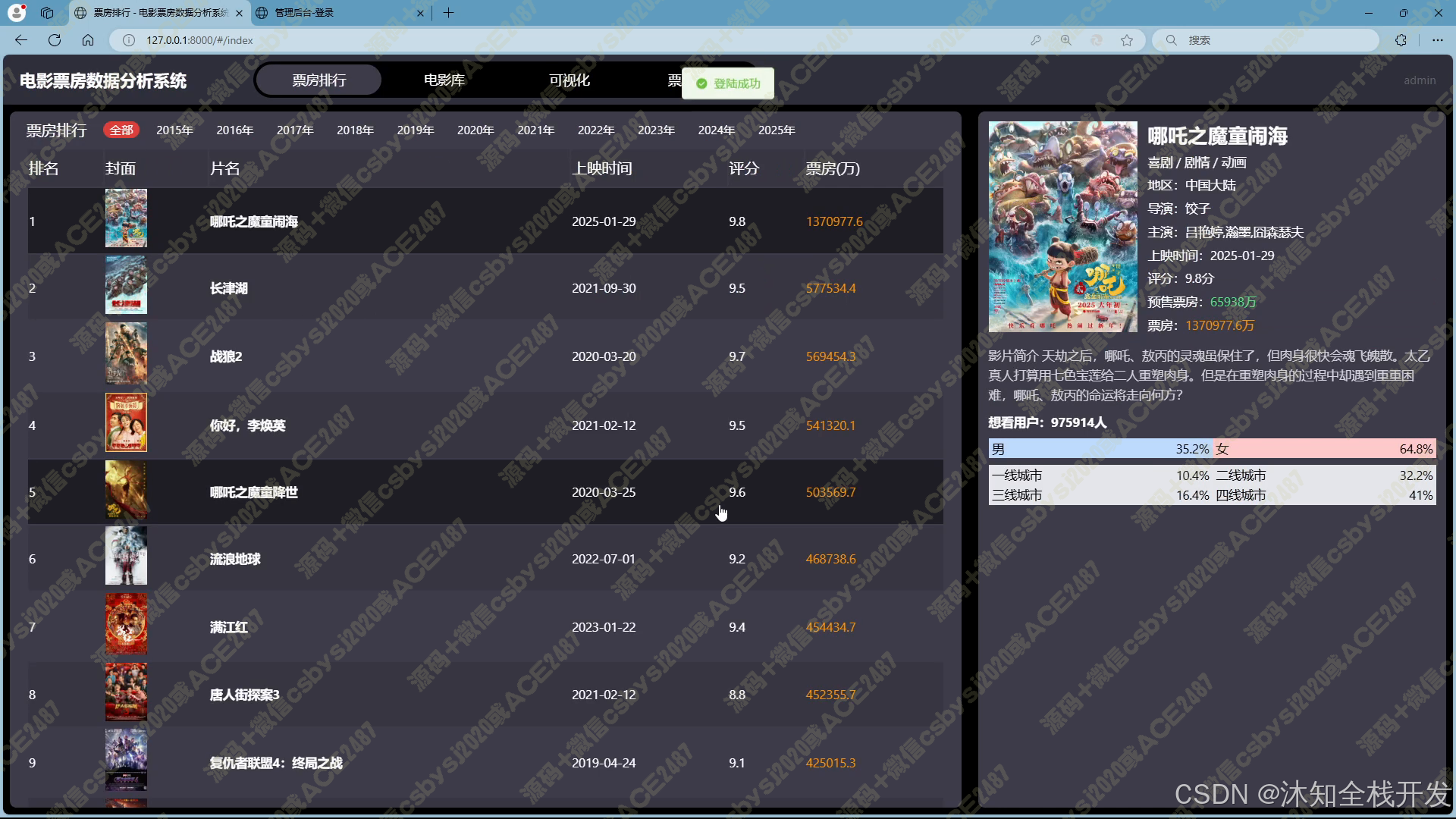
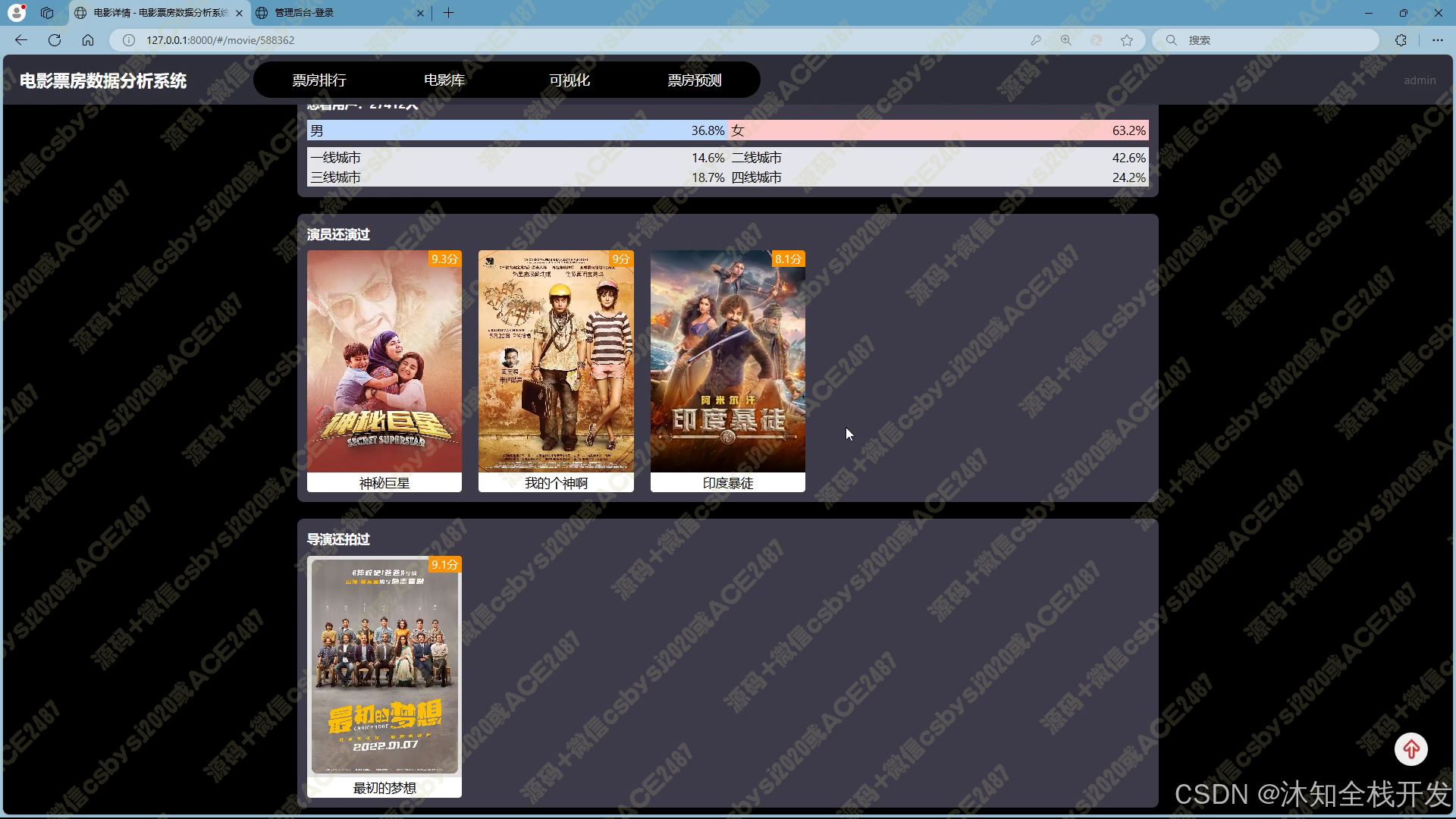
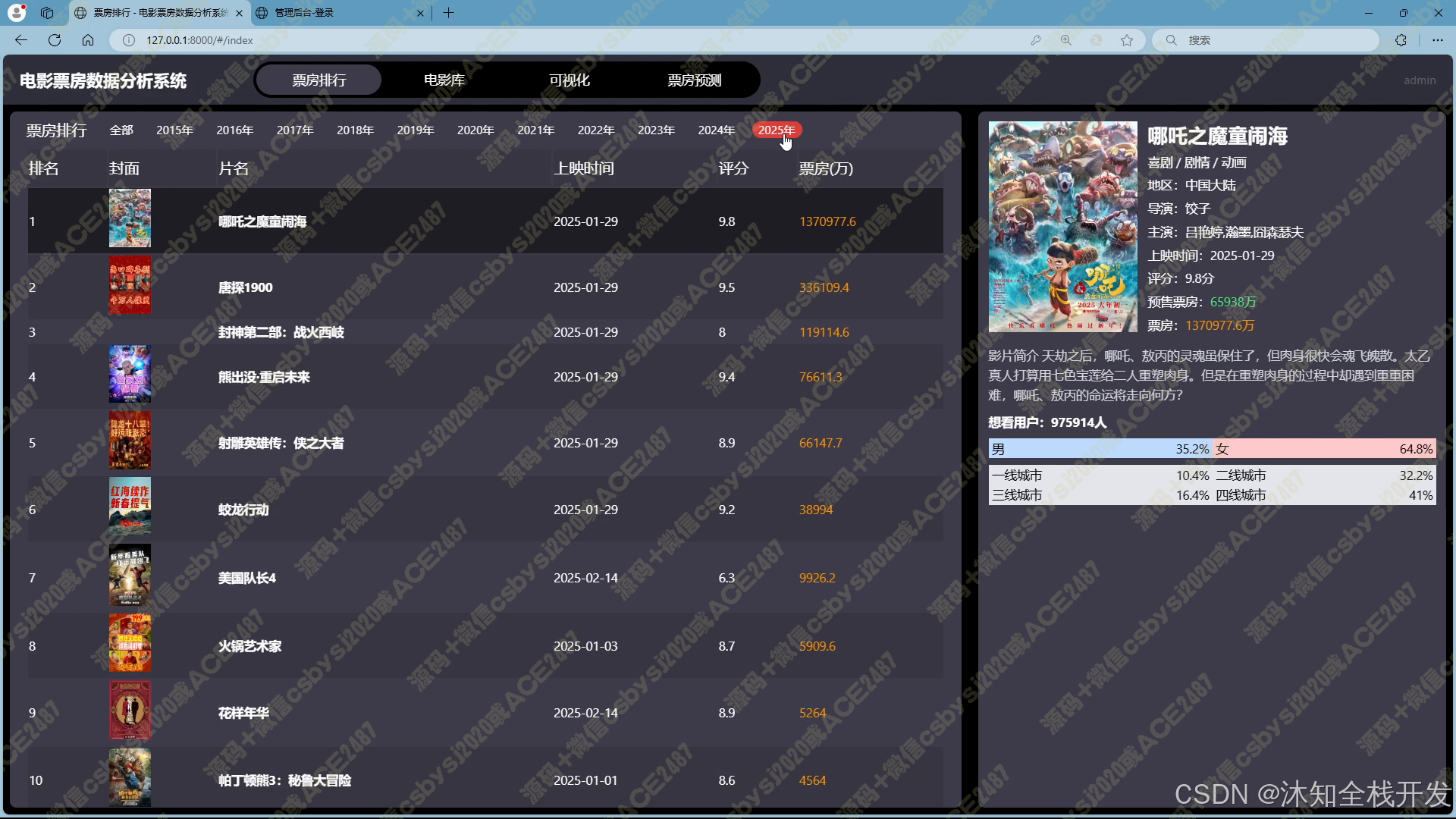
- 票房排行:提供灵活的票房排名展示模式。用户既可以纵观历史上所有电影的票房排名,把握电影行业的整体票房格局;也能够聚焦特定年份,深入了解当年电影的票房表现。展示界面采用左右布局,左侧清晰呈现电影排行榜,包含关键信息;右侧则在用户选中电影后,详细展示电影从创作人员到观众特征等多维度的详细数据,方便用户对比与分析。
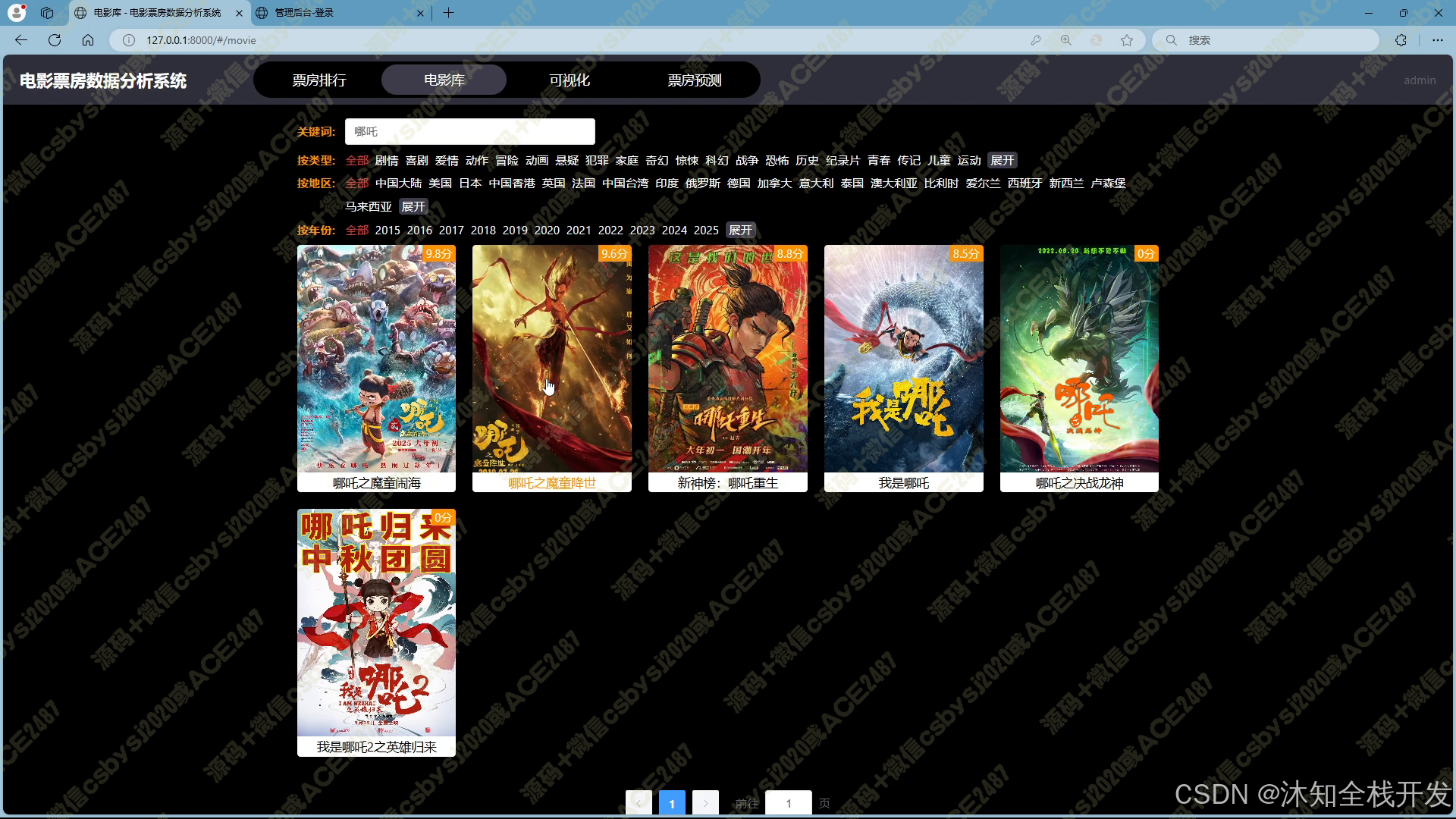
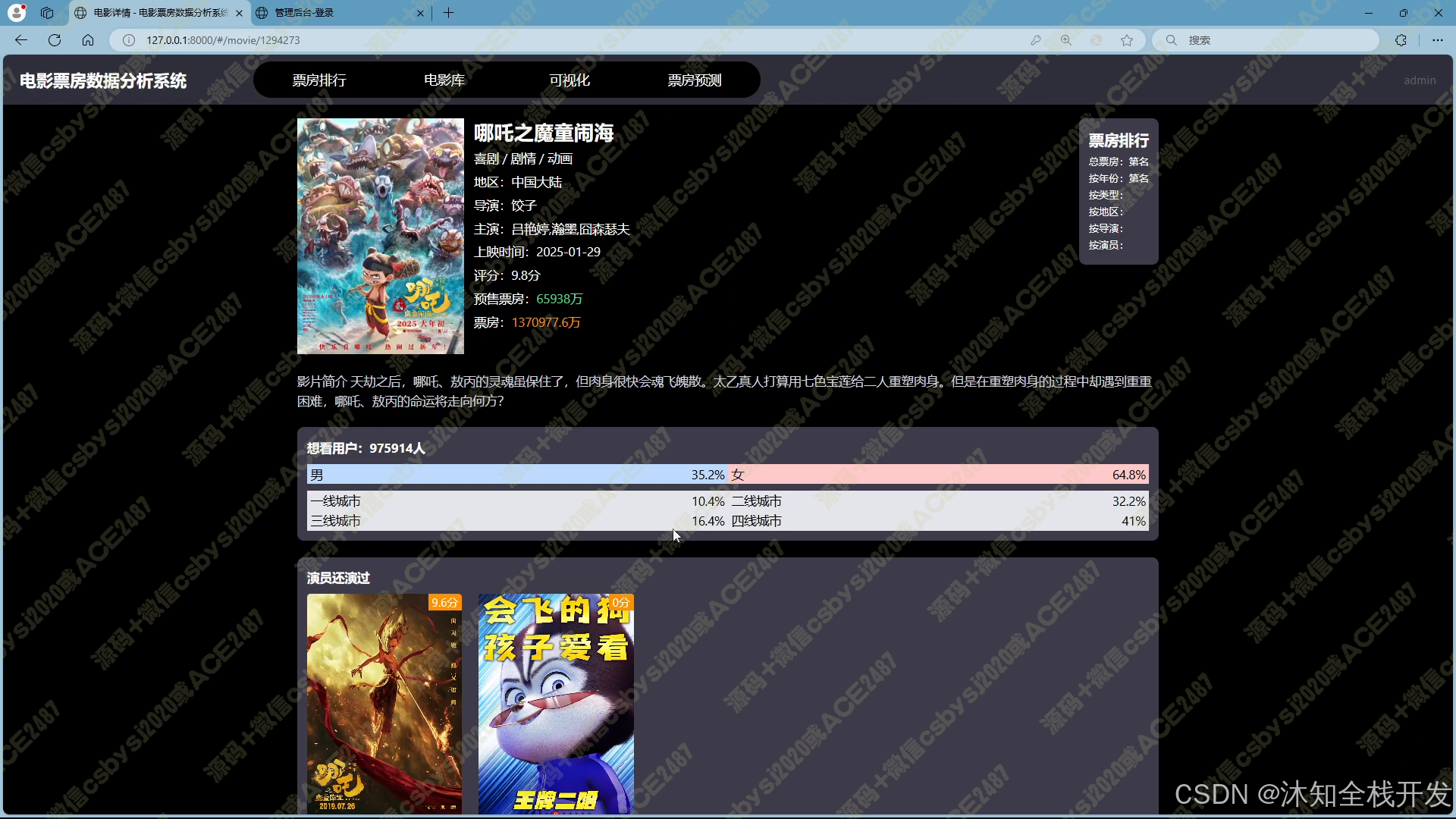
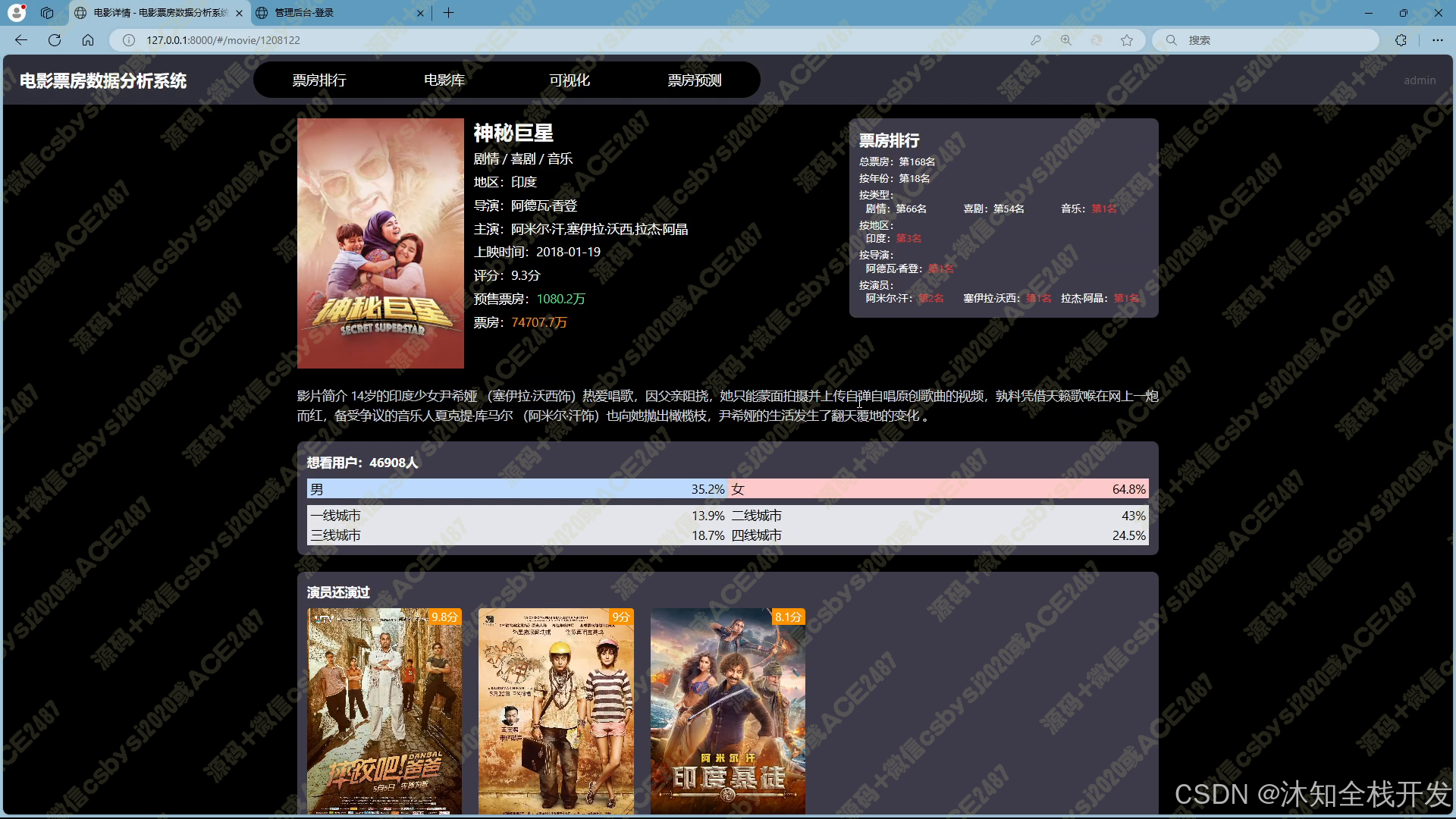
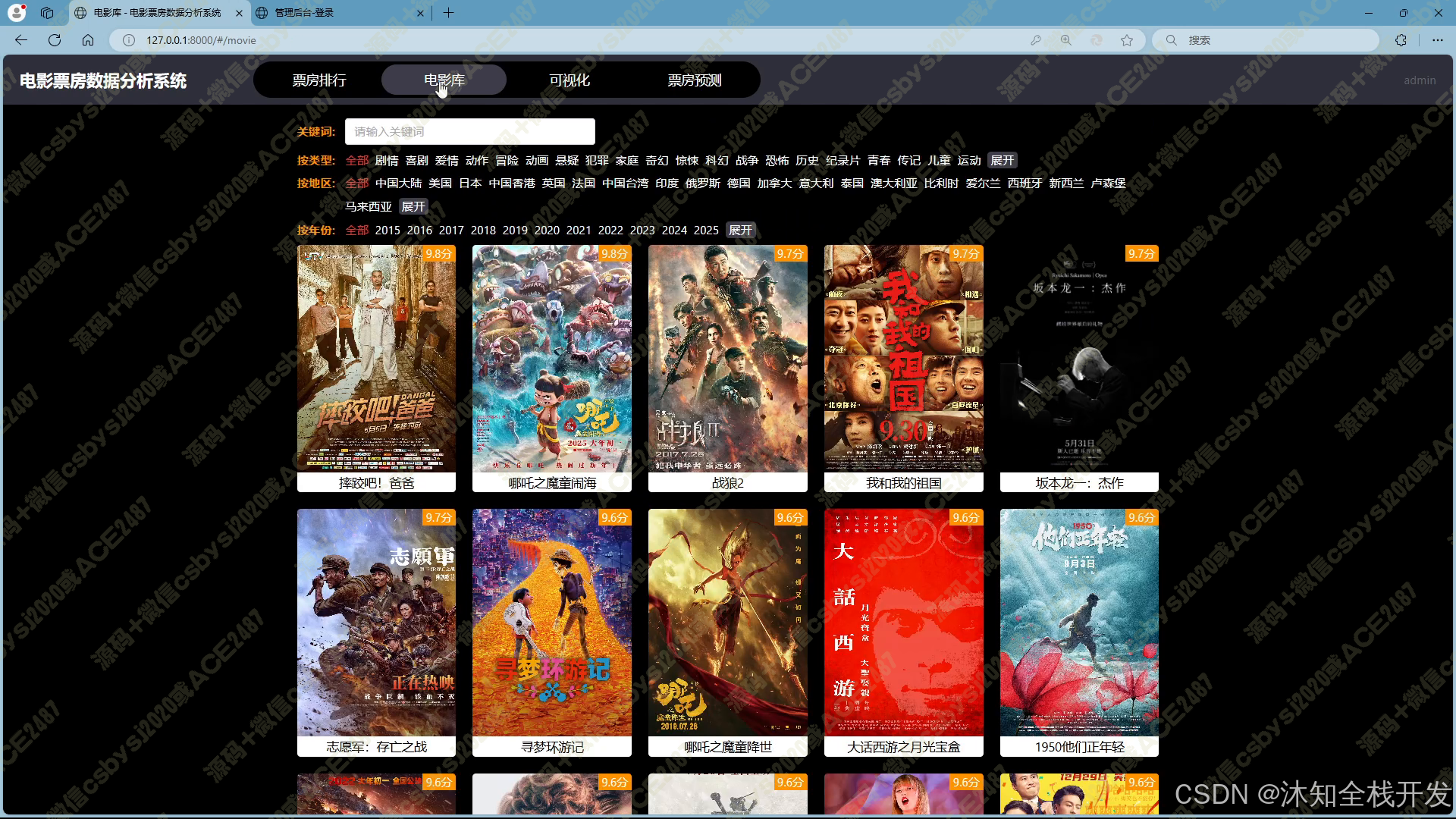
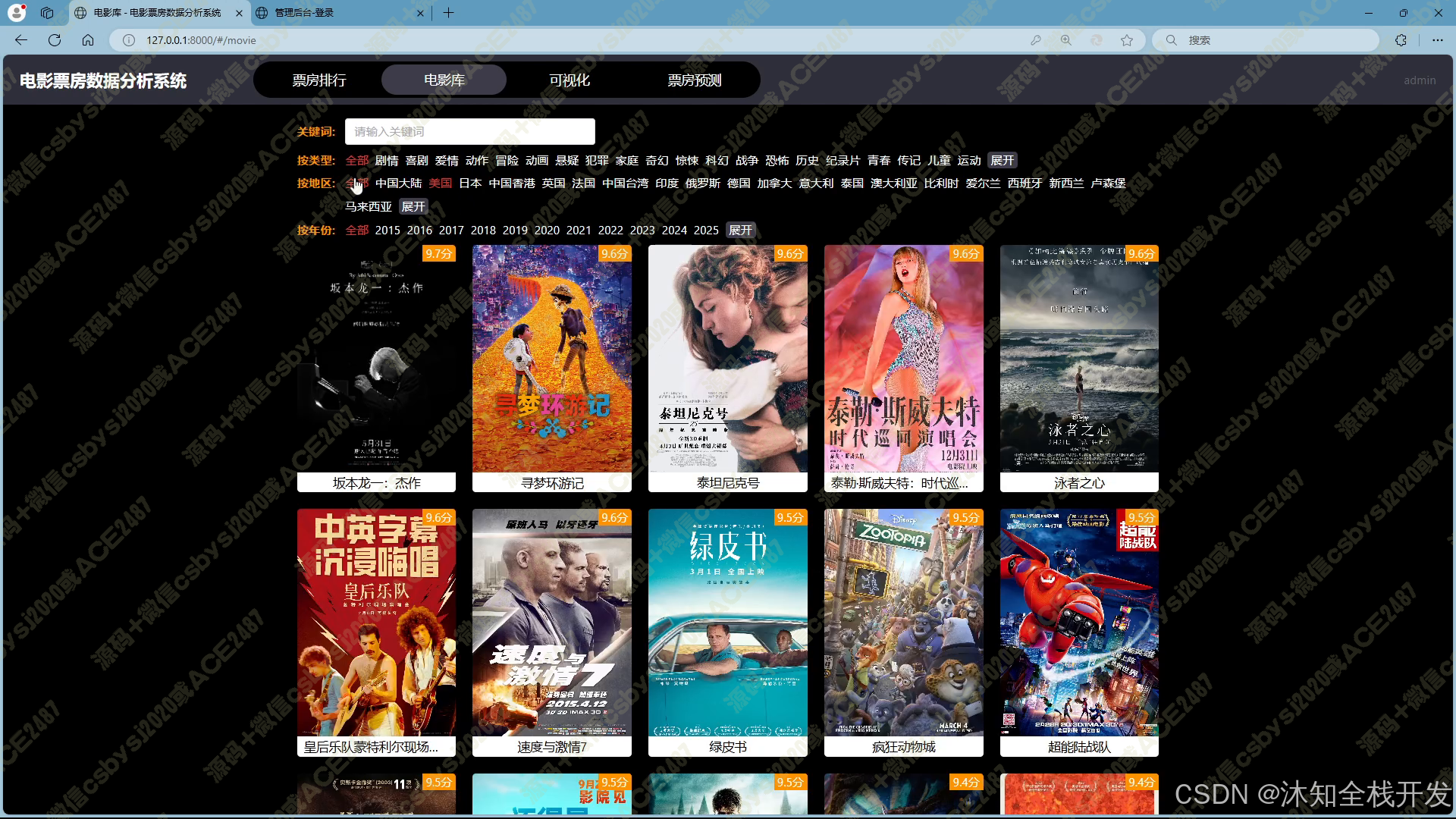
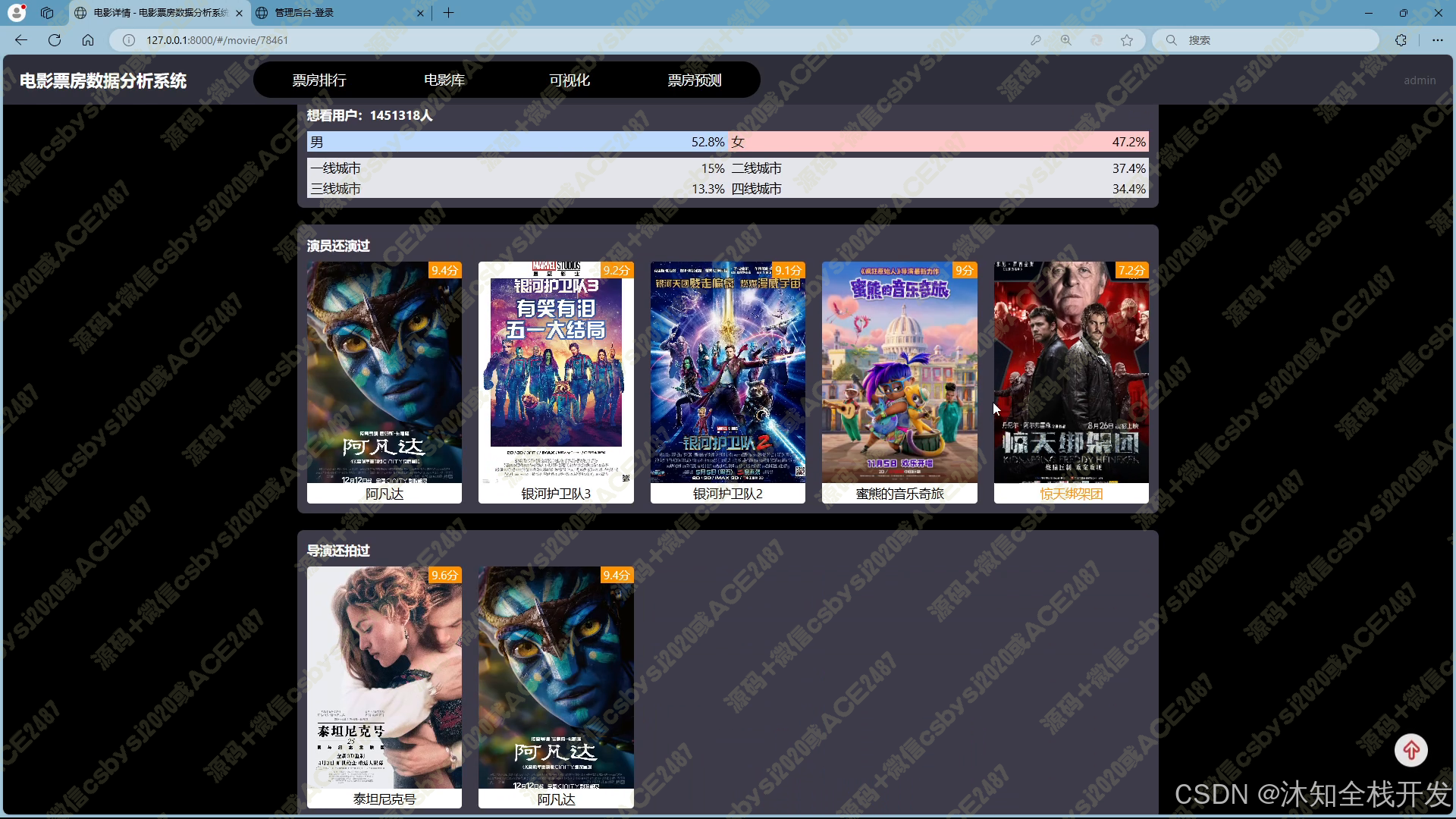
- 电影库:支持多条件筛选查询,用户可通过关键词、电影类型、所属地区、上映年份等条件,精准定位所需电影数据。电影数据以网格布局展示,并配备分页功能,便于浏览。进入电影详情页面,除基本信息外,还呈现该电影在票房、年份等多维度的排名情况,以及导演和主演的相关作品信息,为用户提供全面的电影信息视角。
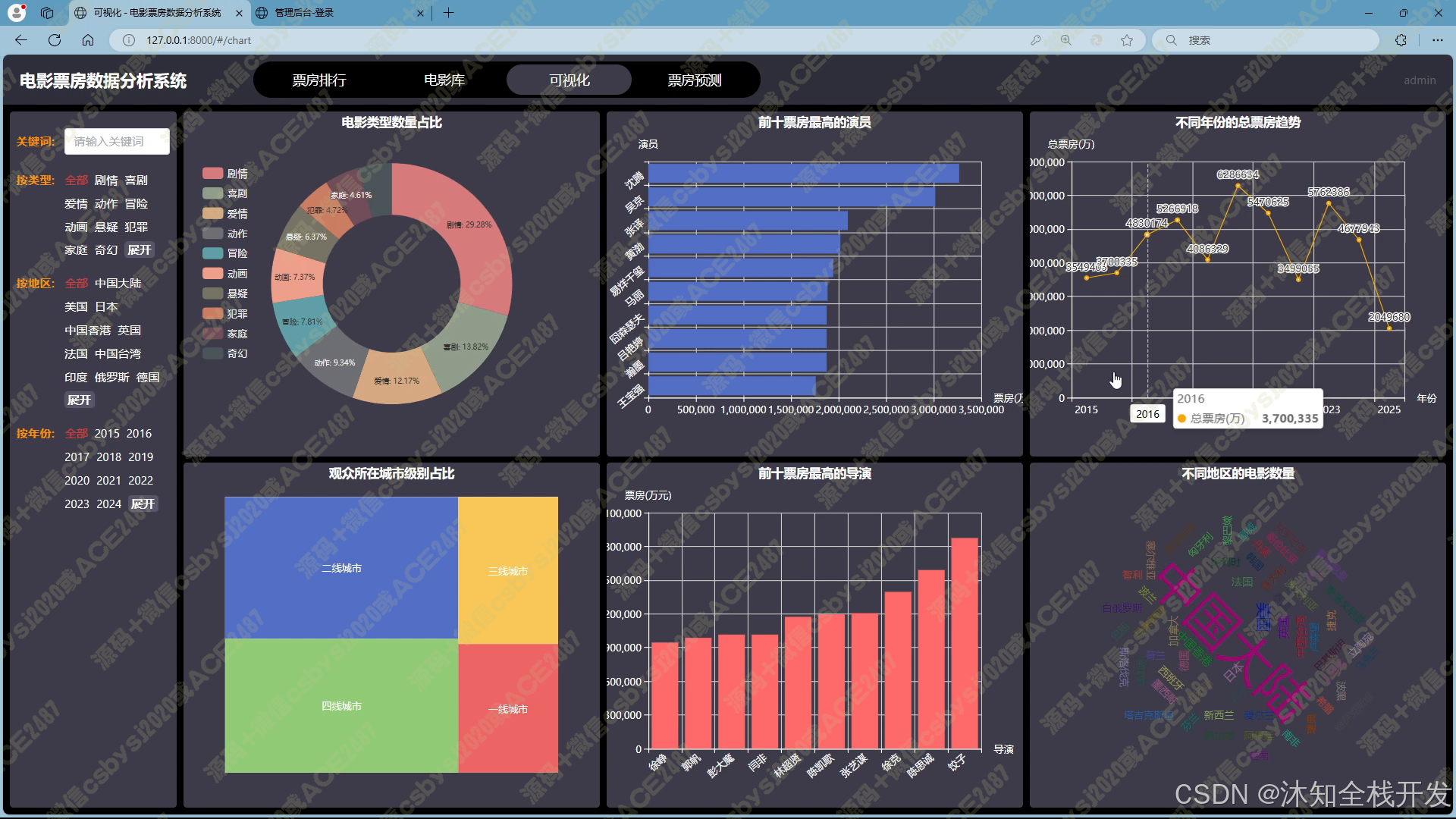
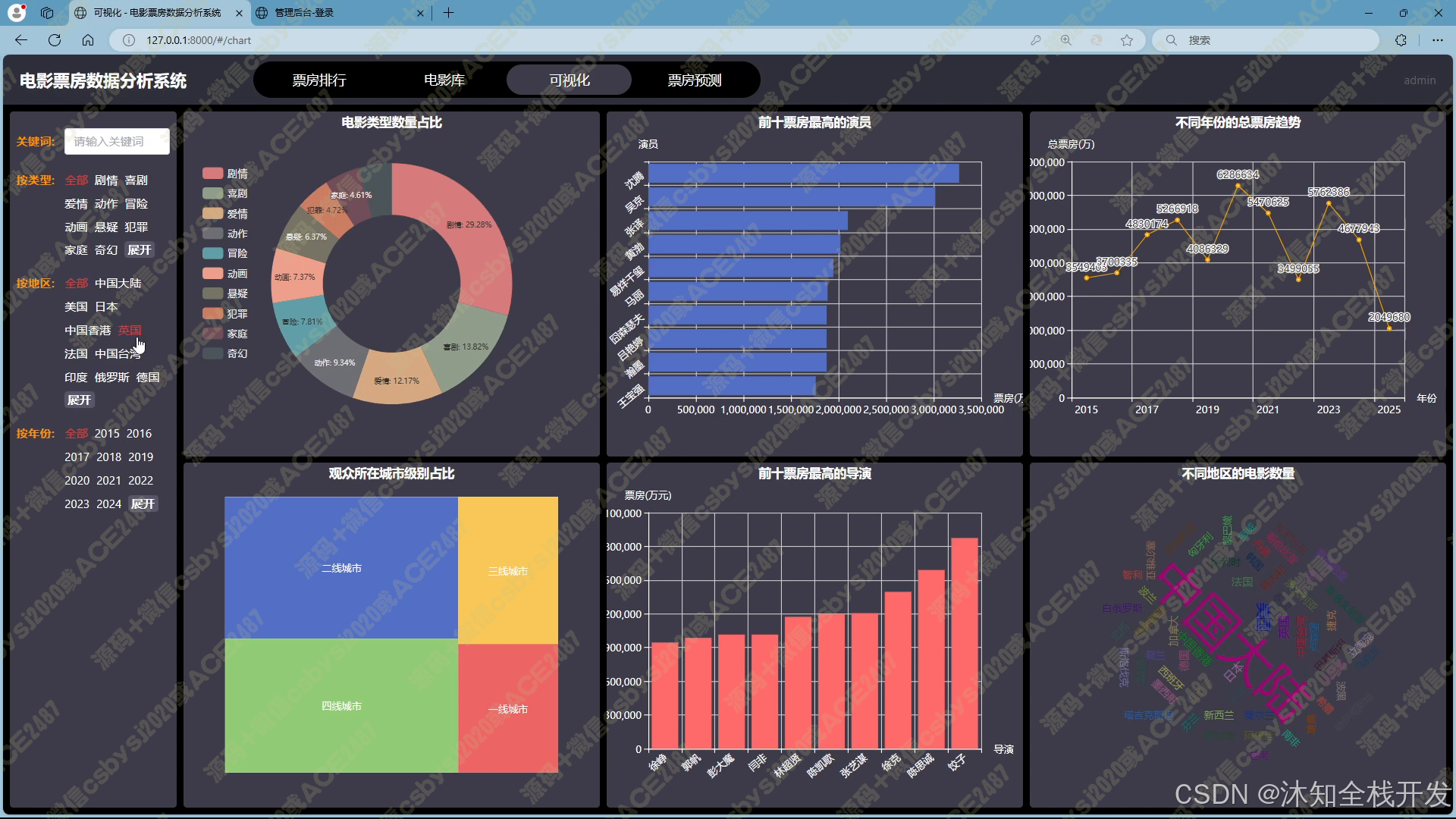
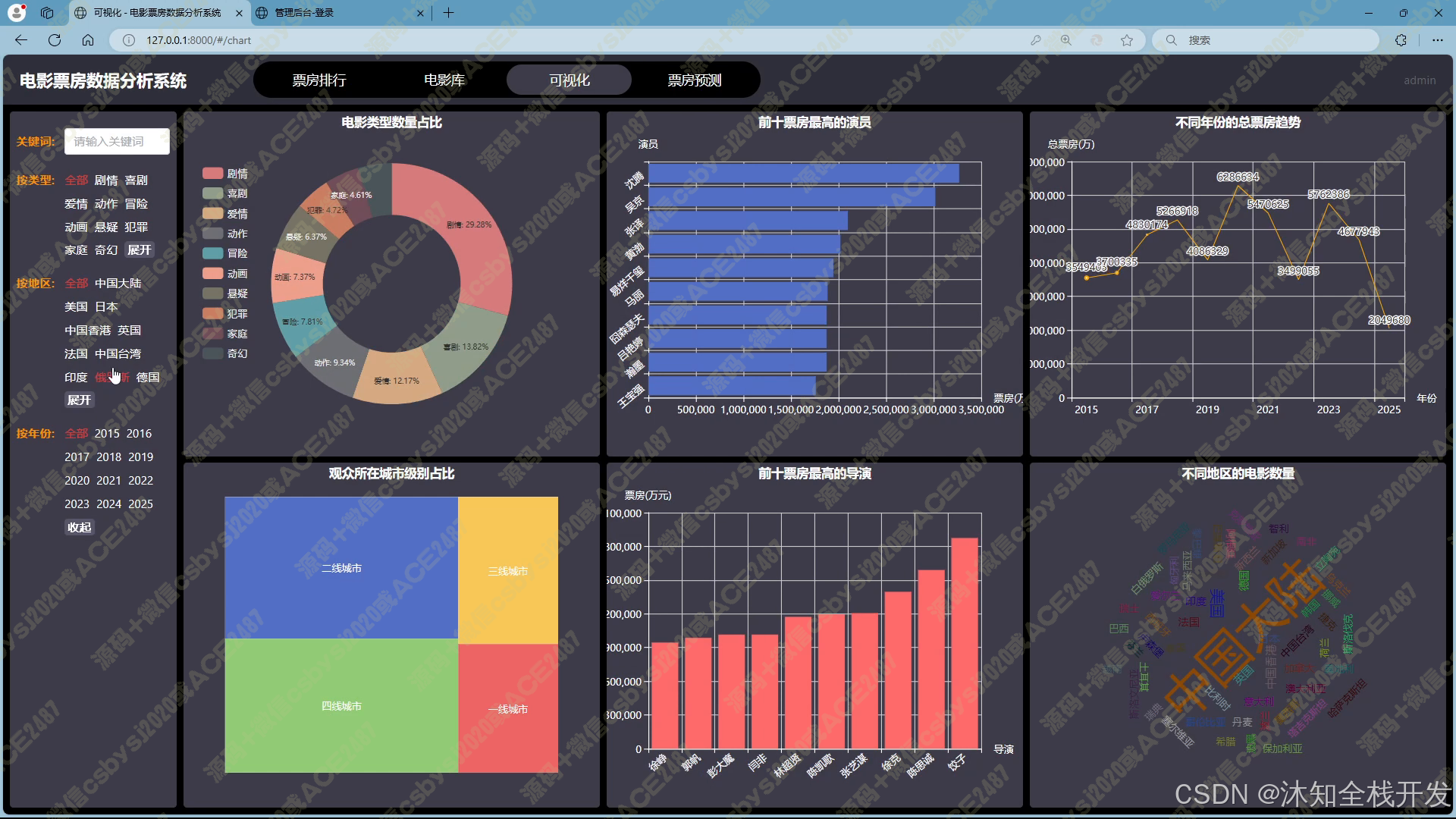
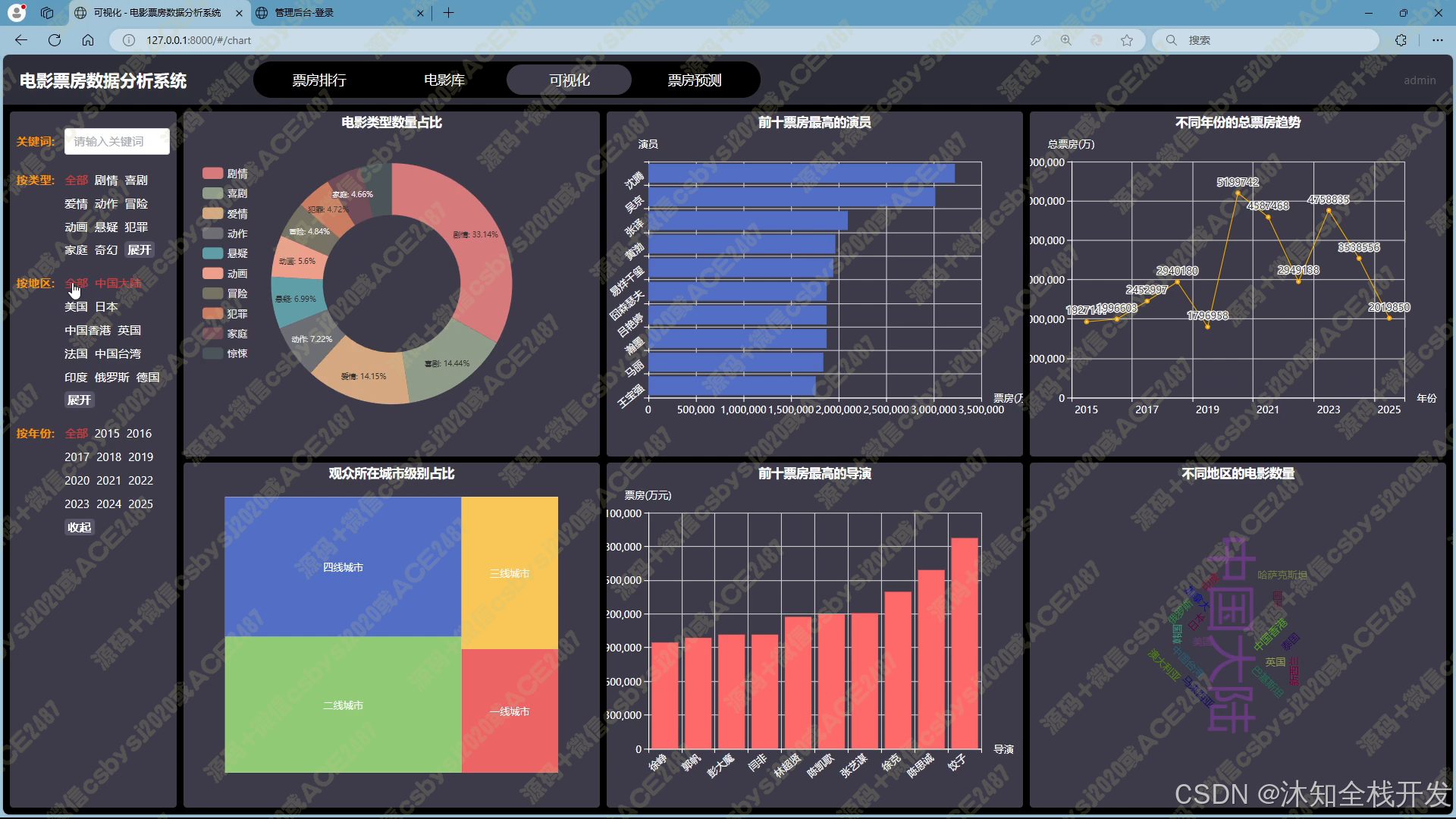
- 可视化:借助 Echarts 强大的可视化能力,将筛选后的电影数据以直观的图表形式呈现。包括电影类型占比饼状图、前十票房最高演员横向柱状图、不同年份票房趋势折线图、观众所在城市占比矩阵图、前十票房最高导演竖向柱状图、不同地区电影数量词云图等,帮助用户快速理解数据背后的特征与趋势。
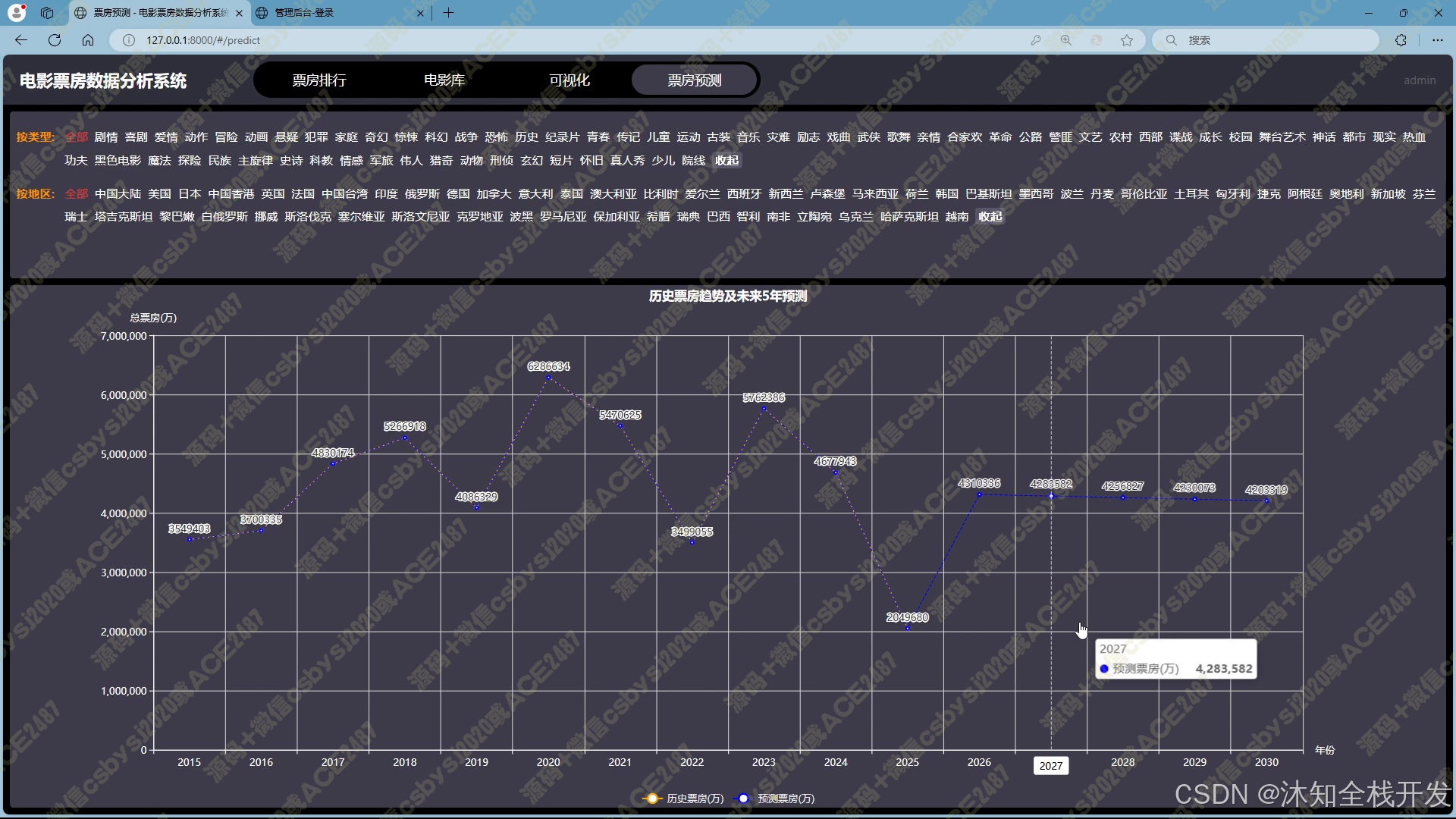
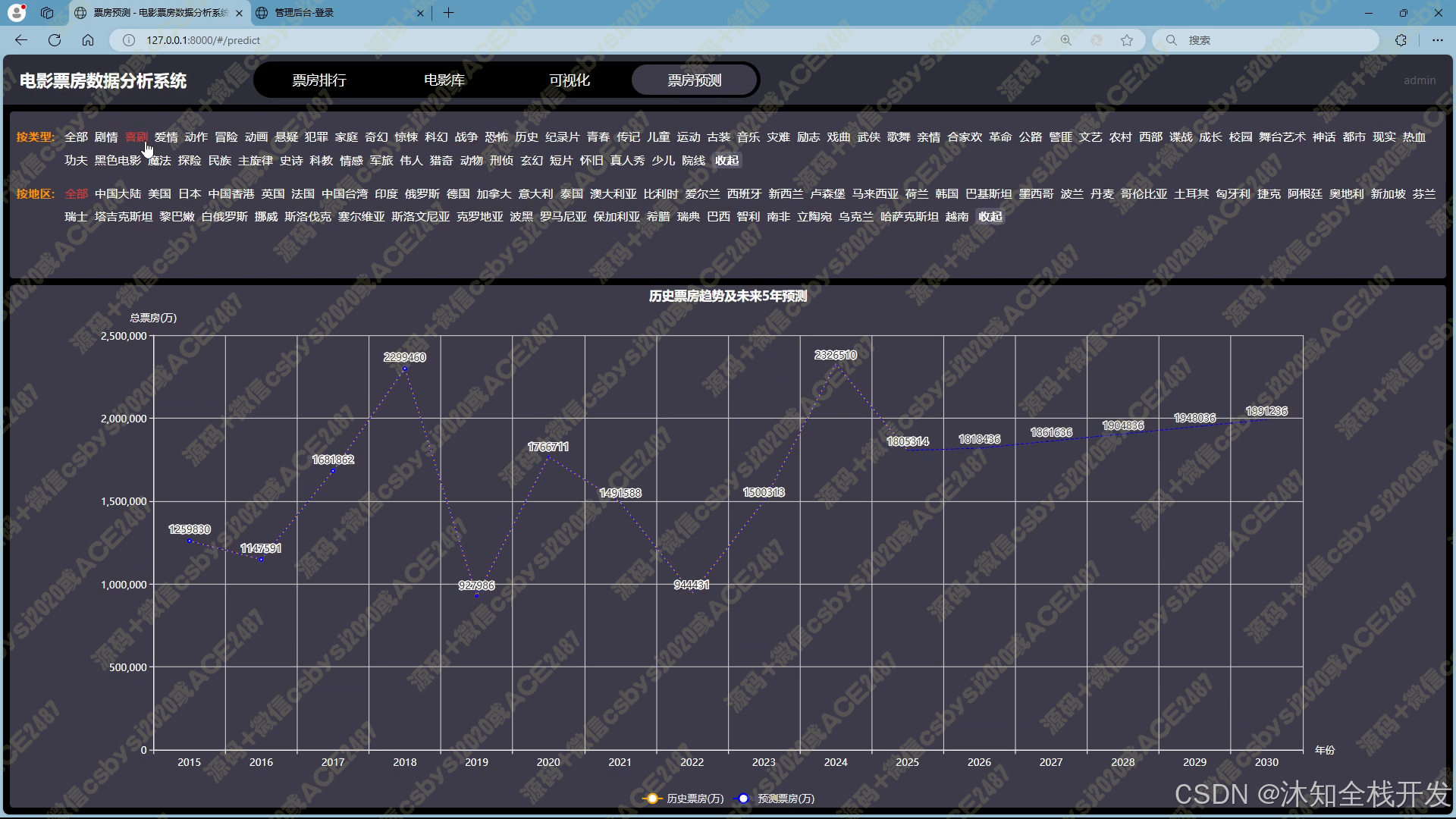
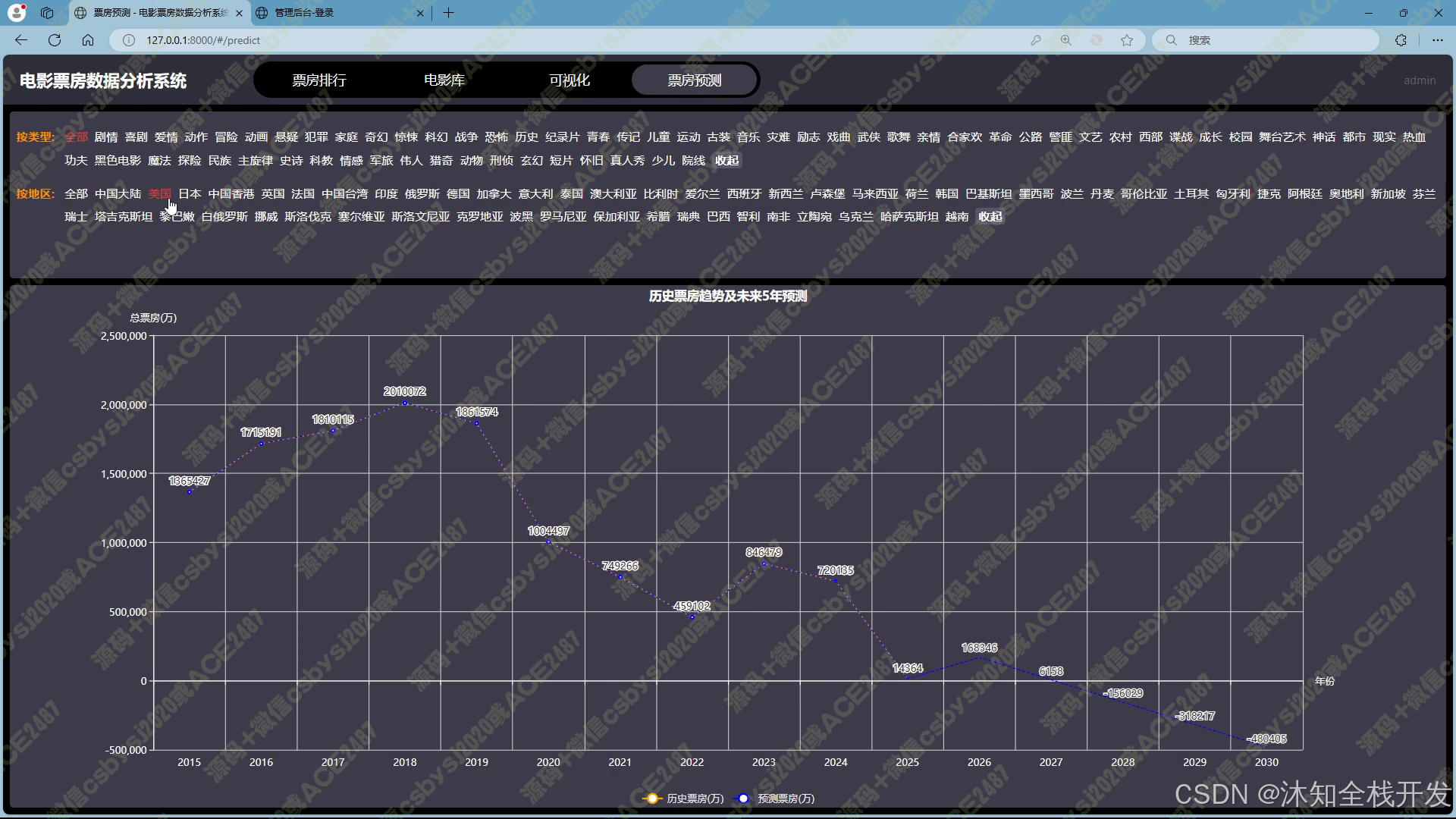
- 票房预测:利用机器学习中的线性回归算法,用户通过电影类型、所属地区筛选数据后,系统能够预测未来 5 年的电影票房趋势走向,并以折线图展示预测结果。这为电影制作方、投资方等提供了重要的决策参考依据,助力其提前规划与布局。
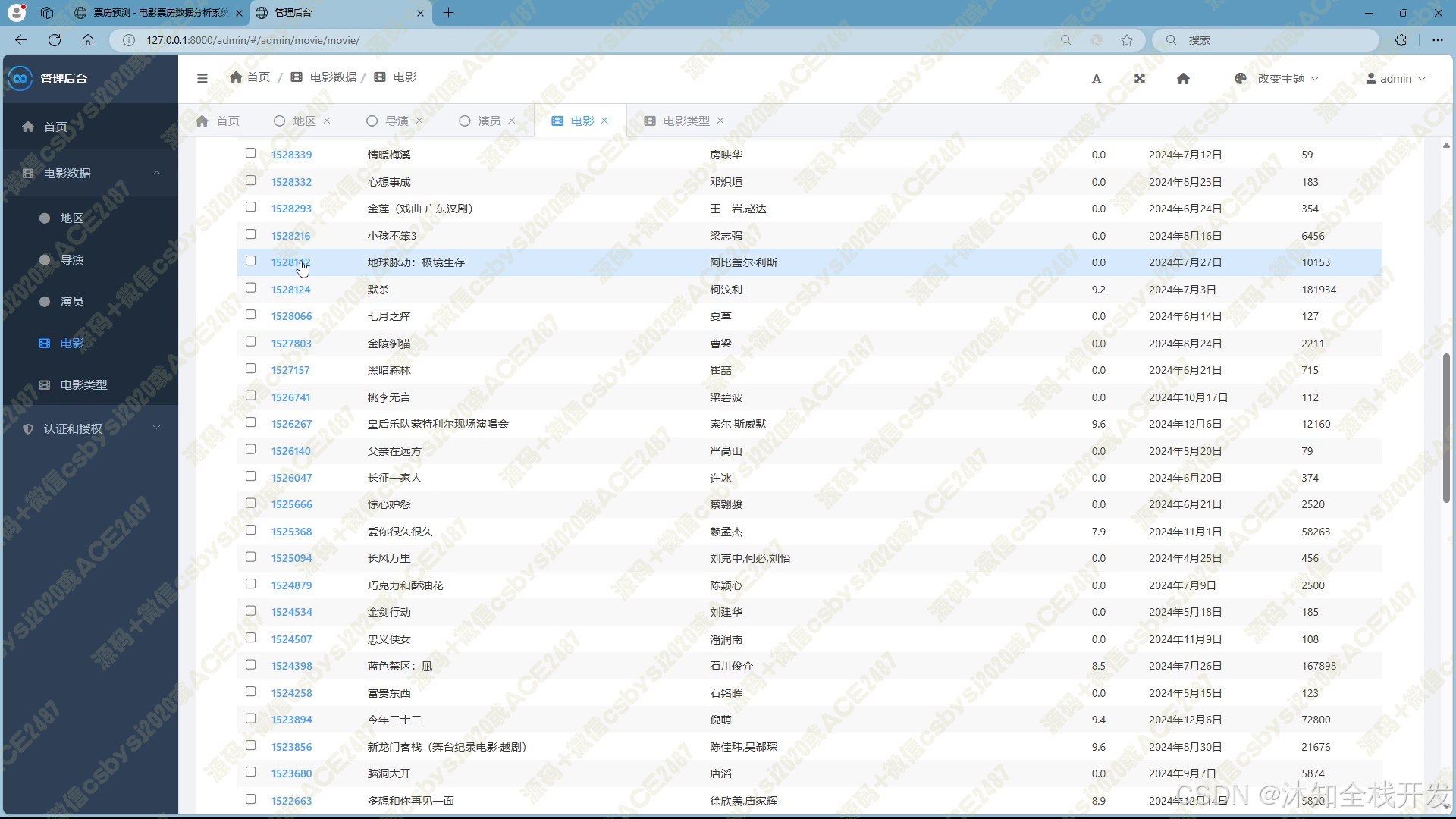
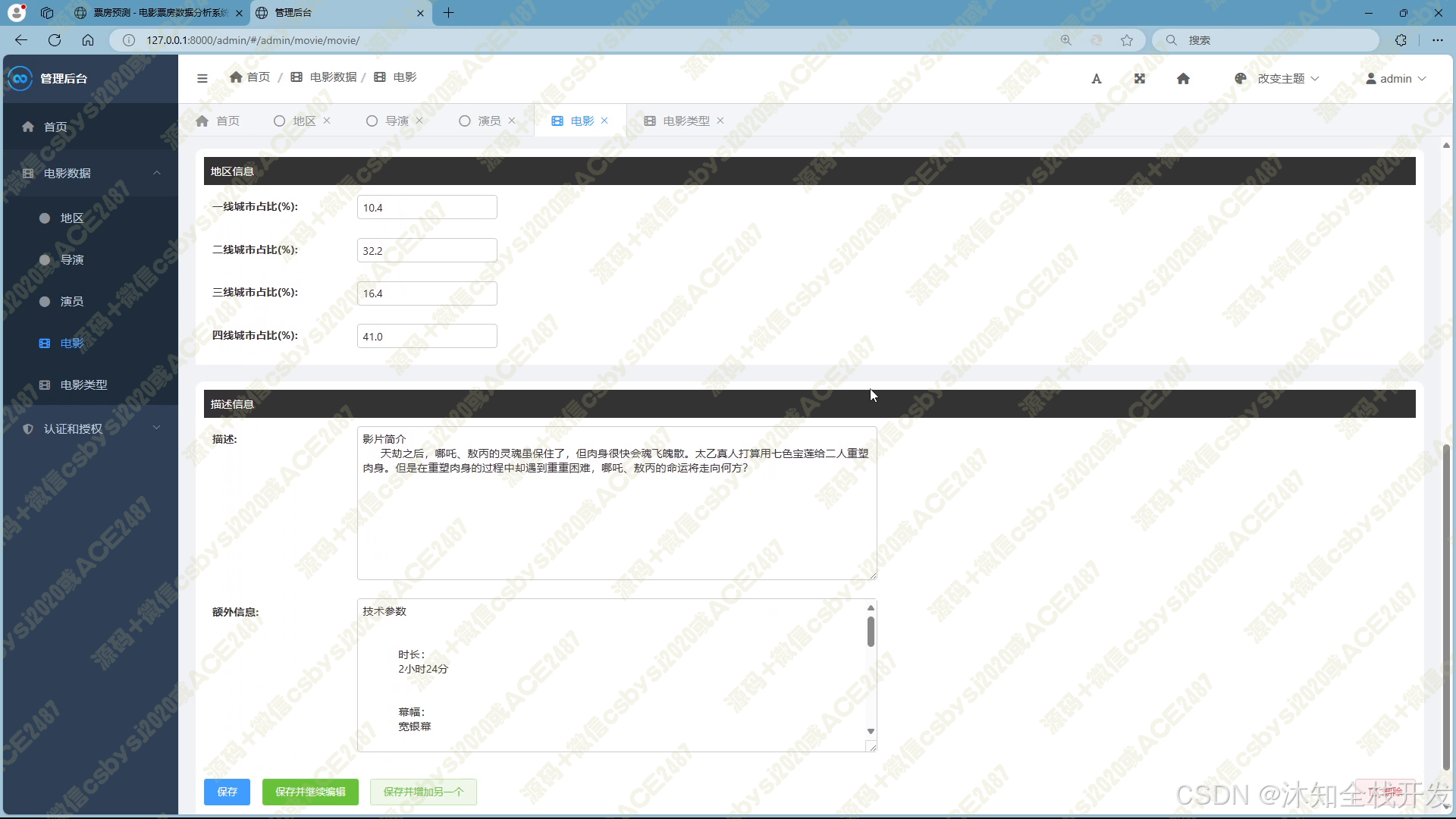
- 后台管理:超级管理员拥有全面的后台管理权限,可对地区、导演、演员、电影、电影类型、用户等各类数据进行增删改查操作,确保系统数据的准确性、完整性与安全性。
技术栈运用
- 编程语言:Python 作为项目的核心编程语言,凭借其简洁的语法、丰富的库以及强大的生态系统,为数据处理、机器学习算法实现以及系统开发提供了坚实基础。
- Web 框架:Django 用于搭建系统后端架构,其高效的开发模式、丰富的插件以及强大的数据库管理功能,保障了系统的稳定运行与可扩展性。
- 可视化库:Echarts 实现了精美的数据可视化效果,通过丰富的图表类型和交互功能,将复杂的数据转化为直观易懂的图形,提升用户对数据的理解与分析效率。
- 爬虫框架:Scrapy 负责高效抓取电影票房数据,其异步处理机制和灵活的配置选项,能够快速、稳定地获取并更新数据,满足系统对数据及时性的要求。
- 机器学习库:Scikit - learn(sklearn)提供了丰富的机器学习算法,其中线性回归算法被用于构建票房预测模型,为系统赋予了智能预测的能力。
- 前端框架:Vue.js 搭配 Element - Plus 组件库,打造了用户友好、交互流畅的前端界面。Vue.js 的响应式设计和组件化开发模式,结合 Element - Plus 丰富的组件资源,提升了用户的使用体验。
- 数据库:MySQL 作为关系型数据库,用于存储和管理大量的电影数据。其成熟的技术体系、高效的数据存储与查询性能,保障了数据的安全存储与快速访问。
本电影票房数据分析系统融合前沿技术与实用功能,为电影行业提供了全面、深入的数据研究与决策支持工具,助力从业者更好地把握市场动态,挖掘潜在商业价值,推动电影行业的数字化发展。
截图



















 1296
1296

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











