






0.前言
上一篇文章梳理了android中窗口触发anr的机制与处理流程,这一篇文章将对anr产生的直接原因以及应对anr的方法做一个总结与探讨。
1.anr产生原因
1.1 无焦点窗口类型anr
无焦点窗口类型anr的发生与与窗口的绘制流程以及焦点窗口切换流程密切相关,产生此类anr的原因可能发生在前面所提到流程的各个阶段。总的来说可分为窗口绘制、窗口状态切换、窗口状态同步这三个阶段。
1.1.1 窗口状态切换
WindowManagerService(WMS)中窗口状态主要有0、1、2、3、4这几种,初始状态为0,relayout流程中申请Surface去绘制后窗口状态为1,即draw_pending,也就是等待绘制。当窗口首帧绘制完成、由ViewRootImpl(VRI)通过binder通信上报到WMS中后,窗口状态会依次切换为2、3、4,窗口最终状态为4,即has_drawn。到这里,WMS中窗口状态切换流程结束。这其中有两处可能会导致窗口状态切换异常,从而导致产生anr。
1.1.1.1 VRI没有上报WMS
窗口第一帧绘制完成后,VRI会接收到底层回调的callback,表示渲染线程已经绘制完毕。此时VRI会通过binder通信去通知WMS窗口已经绘制完成,接下来可以走状态切换流程了。但是有时候在窗口绘制完成后,VRI可能不会上报,没有发起reportDrawFinished流程,这就导致窗口状态一直停留在1,那么窗口也就不可能获得焦点了。如果此时InputDispatcher准备派发key事件,那么5s后将会产生anr。
什么场景下会发生VRI不向WMS报告的情况呢?之前有遇到过这样的情况:当某个窗口包含SurfaceView时,需要窗口主Surface与SurfaceView均完成同步后,VRI才会去上报WMS,如果这个同步过程出了异常,最终将使得VRI不会上报WMS窗口绘制情况。这里的同步,涉及到SurfaceSyncer机制,是android13新增的内容,后面有机会时会梳理一下SurfaceSyncer机制。
1.1.1.2 WMS中接收到VRI上报但没有切换到最终状态
WMS接收到VRI上报后,窗口状态会立马由1切换为2,表示窗口第一帧绘制完成。接下来的流程中,窗口状态会逐渐由2切换为3、4。但有时候可能会由于某些原因最终没能切换到4,这也会使得窗口无法获得焦点,从而发生anr。这种情况比较少见,而且根据当前窗口状态,也比较容易排查到窗口状态切换异常的原因。
1.1.2 窗口信息同步
上层窗口信息由WMS通过transaction同步至底层SurfaceFlinger侧,SurfaceFlinger会将这些信息更新至InputDispatcher,然后InputDispatcher再根据这些窗口信息去更新焦点窗口。一个窗口被判断为焦点窗口,需要满足一些条件,其中一个就是visible。底层窗口的可见性与上层窗口的可见性有一些差别:如果上层窗口的可见性为true,但是其alpha为0,那么SurfaceFlinger会判断该窗口或者说对应layer是不可见的,对应layer也不会参与合成,因此这种情况的窗口也不满足成为焦点窗口的条件。
这种visible为true但是alpha为0导致窗口无法获得焦点的情况,与leash动画有关。leash动画主要是用于在不用持锁的情况下执行过渡动画或者窗口动画,以使得动画更加流畅。当动画开始前,会新创建一块surface(即leash图层)并把当前窗口的父节点reparent为leash图层,在动画过程中只需改变leash图层的属性且直接与SurfaceFlinger通信,这样执行动画的窗口的相关属性便会随着leash图层的变化而变化。当leash动画结束后,执行动画的窗口的父节点会再次执行reparent操作将父节点由leash图层恢复为原来的父节点。如果leash动画出了问题,使得后面窗口的父节点没有恢复、从而使得窗口的alpha为0,那么即使当前窗口状态达到has_drawn且为可见状态,其在SurfaceFlinger中对应的layer也会被判定为不可见,从而始终无法获得焦点。这种情况常见于monkey测试中。
1.1.3 焦点窗口
还有一种简单的情况,手机在灭屏时焦点窗口会切换为null,如果灭屏期间发送一些key事件、且key事件无法被窗口策略消费,那么超时后就会触发无焦点窗口类型anr。这种现象常见于monkey测试中在设备灭屏后发送key事件触发anr的情况。
1.2 输入事件处理超时类型anr
此类型anr,产生anr的直接原因都是因为在InputDispatcher向client派发某个input事件后、client未及时反馈处理情况给InputDispatcher导致的。而client没有及时反馈,大致可分为两种情况:一是因为app主线程已经读取了该input事件并开始处理,只是处理当前input事件超时;另一种情况是client主线程在忙于做其他事情而尚未来得及去读取该input事件、自然也就无法处理了,超时后也会发生anr。这里的client,是指对应InputChannel的拥有者,既可以是应用进程,也可以是系统进程。
1.2.1 处理当前input事件超时
以app处理当前input事件超时为例,这种情况可能是处理input事件时涉及的binder通信太多、或者某些binder通信耗时太长,也可能是主线程阻塞在单个流程中,使得当前input事件的处理耗时超过5s,从而发生anr。
1.2.2 尚未读取当前input事件
还是以app为例,这种情况就是主线程在忙于执行其他任务、尚未有空闲去读取InputDispatcher派发过来的input事件,使得input事件还没有被开始处理便发生anr了。当然,即使app主线程还没有去读取该input事件,对于发送方InputDispatcher来说是不管这些的,它会在input事件开始派发时便开始计时。
2.anr应对方法
对于无焦点窗口类型的anr,整体上是有迹可循的。如前面所说,此类anr的发生与窗口绘制流程、焦点窗口切换流程等有关,可根据log判断大致处于哪个阶段,再确认为什么下一个阶段没有执行的原因即可,整体相对来说比较好排查,这里不再展开。
对于输入事件处理超时这类anr,相对来说比较棘手,主要是因为发生anr时主线程状态基本处于黑盒状态,很难确认那5s究竟在干嘛、究竟是阻塞在哪些流程。像那种从头到尾阻塞在某一个流程、且对应堆栈也被dump出来的情况,自然很容易知道阻塞点在哪。但这种情况终究只是极少数情况,大多数时候是没法判断主线程的阻塞点的,因为可能主线程并不是在某个流程耗时,更可能是各个阶段都比较耗时,从而导致整体处理超时,这种情况应该是更加普遍、更具代表性的情况。
对于输入事件处理超时的anr,目前的主要应对方法有提前dump堆栈信息、代码执行路径上埋点添加log、抓取systrace这几种。
2.1 提前dump stack trace
anr发生后所dump的堆栈显示的代码流程,不一定就是anr期间所阻塞的流程,有可能只是快要发生anr时所正在执行的代码逻辑、然后刚好被dump到而已。因此,为了进一步确认anr期间主线程的阻塞点,增加一次堆栈的dump机会,在达到anr超时时间的一半左右时便触发dump。如果前后两次dump的堆栈中显示主线程都在执行同一代码逻辑,那么极有可能是整个5s或者说5s的大部分时间都阻塞在这里,可以重点排查此处代码逻辑是否合理。这种方法只适用于那种主线程长时间阻塞在某处代码逻辑的情况。
2.2 预定执行路径添加debug log
当anr的复现场景比较固定、或者说发生anr时代码流程比较固定时,可以在对应窗口处理input事件的代码路径上埋点添加log,特别是那种看起来比较耗时的代码逻辑处添加log,这样就能确认处理input事件时到底是那一段代码执行耗时较长,然后再进一步确认以精确到具体的代码行。这种方法只适用于app已经读取并开始处理当前input事件的情况。对于那种还没有来得及去读取input事件的情况,是没法预判主线程在做什么的,自然也就没法去代码中埋点了。
2.3 抓取systrace
前面提到,对于input事件处理超时类型的anr,难点在于难以知晓anr期间主线程都干了什么导致没有处理或者处理超时,类似于一种黑盒状态,只能从log或者所dump的堆栈信息中找到一些极为有限的线索。对于那种系统高负载场景发生anr的情况,就更难确认主线程的活动了,因为高负债场景下主线程一般是各个阶段的耗时都会变长、而非阻塞在单一流程中。高负债场景下产生的anr一般来说也是最难解决的。
如果在一开始便长时间、循环的抓取systrace(或者atrace、perfetto-trace等),等到anr产生时再停止抓取并将systrace保存下来,那么前面提到的种种困难将迎刃而解。有了对应时间段的systrace,主线程将不再处于黑盒状态,期间做了什么、哪些任务耗时长都是可以看的很清楚,因此能够更加准确的定位anr发生的原因并进行针对性的优化。
开发者选项中就可以在测试前提前打开perfetto-trace的录制,并设置为长期、循环抓取,然后在anr发生后手动停止抓取perfetto-trace。但在实际操作过程中,这种方法抓到的perfetto-trace在大多数情况下是不包含anr全过程的,也就是trace中的实际有效内容是anr发生后的一段时间,这对于分析anr产生的真正原因并没有太大的帮助。很难抓到anr全过程的trace主要有两方面的原因:一是当时系统负载已经很高了,保存的perfetto-trace文件中的实际有效时长会远远小于正常情况;二是因为anr发生后、手动去停止抓取perfetto-trace时,距离发生anr第一时间点已经过去十几秒甚至好几十秒了(因为anr弹框是在dump信息完成后才弹出的),而高负载场景抓到的perfetto-trace中有效时长往往只有几秒到十几秒钟。
因此,可以在代码中调整一下保存perfetto-trace的时机,将其提前至InputDispatcher通知到上层后、上层开始dump信息前,这样就能比之前手动保存的时间要提前十几秒甚至几十秒了,抓到anr全过程的概率大大增加。有了包含anr全过程的perfetto-trace,就能对各种input事件处理超时类型的anr进行准确的分析了,这种方法相对于前面提到的两种方法而言,是一种更加直观、更加适用于普遍情况的手段。
3.anr实例分析
以上一章中anr自动抓取systrace(后面简称trace)的方法为例,对抓到的包含anr全过程的trace进行分析,确认anr的发生原因以及解决方案。
首先,抓到的trace中去掉前面一段没有cpu信息的一段,真正有效的就只是后面的一段,有效时长大概为15s左右。所以,如前面提到的,高负载情况下抓到的trace真正有效时长是比较短的。其次,如下图所示,可以看的InputDispatcher触发了anr,即存在"notifyWindowUnresponsive"(红框中的部分)。可以以这里为anr的终点,根据log中打印的anr超时时长向前确认trace中发生anr的真正时间段。log中anr超时时间是5001ms,因此这里向前大约拉5s左右,所覆盖的时间段即为anr时间段。

如下图所示,anr上报前的5s内,InputDispatcher仍然在不断的向app派发input事件,而此时间段内SystemUI主线程却并没有去读取input事件。这就意味着,假如5s前InputDispatcher向SystemUI派发了input事件,而SystemUI主线程在接下来的5s内没有去读取并处理,那么5s后必然是会发生anr的。

而很不幸的是,trace显示5s前InputDispatcher确实是向NavigationBar窗口派发了Input事件,而NavigationBar属于SystemUI进程,也就是5s前确实向SystemUI派发了Input事件(且后面InputDispatcher仍在继续向SystemUI派发)但SystemUI主线程在5s内都没有去读取InputDispatcher派发过来的input事件。

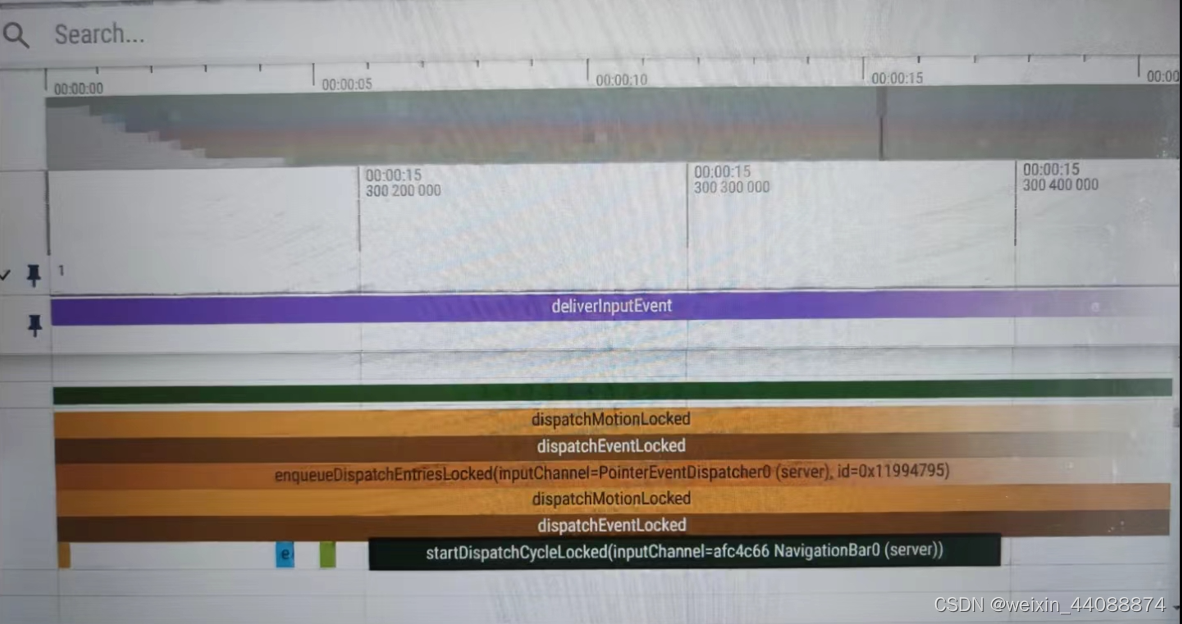
那么,这5s内SystemUI主线程究竟在做什么导致其没有去读取input事件呢?如下图所示,这5s内SystemUI主线程大多数时候在执行binder通信,其中有一段binder通信耗时特别长,这应该是导致此次anr的主要直接原因。
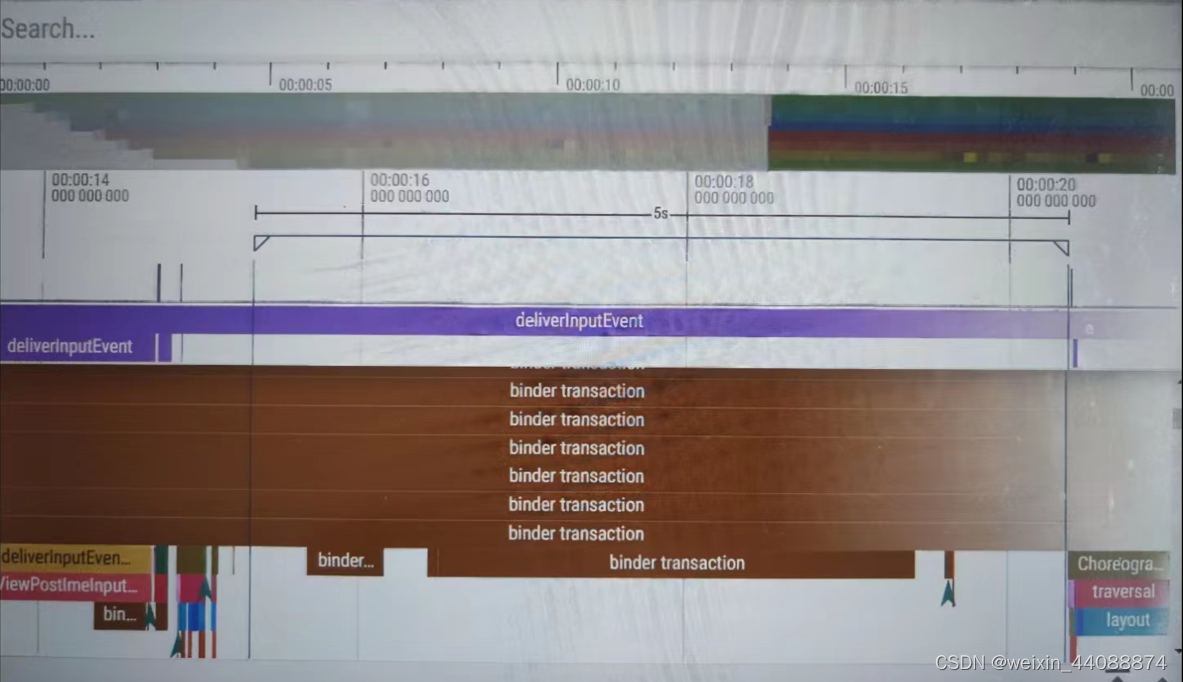
这段时间内SystemUI主线程状态如下,可以看到线程状态大多为sleeping(白色)、runnable(浅绿色)以及d状态(橘黄色),而running状态(绿色)时间却非常少,这也是系统高负载下的典型状况吧。比如cpu负载高时,主线程不会得到及时调度,其runnable状态时间会比较长;而binder对端线程也会因为runnable较长导致整个binder通信耗时长,从而使得主线程sleeping时间长;另外cpu高负载时也会使得相同的io task耗时会更长,即主线程d状态会更长。

看看最长的一段binder通信,可以看的其耗时为2.9s左右。主线程发起binder通信时会阻塞,在trace中处于白色sleeping状态。因此,可以从这最长的一段binder通信为切入点,来确认anr原因。

查看这段binder通信的对端线程状态,和对应时间段SystemUI主线程类似,大多也是处于sleeping、runnable以及d状态。不同的是,这里对端线程sleeping状态主要是在执行bitmap相关操作。

综合SystemUI主线程状态以及binder对端线程状态来看,anr时间段内(5s)SystemUI主线程执行相关业务时期,相关线程处于runnable状态的时长超过了2s(这里只是计算了SystemUI主线程以及耗时最长的binder通信对端线程的runnbale状态),这也说明了当前cpu负载确实较高,很多时候相关线程得不到cpu及时调度,只能等待,因此在执行相同task时,其耗时会比平时多出很多。因此,这就是一个典型的系统高负载时发生anr的场景。
怎么解决此类场景下的anr呢?可以从系统和应用两个层面去考虑。从系统层面来说,当前cpu的psi压力过大是因为后台存在较多进程,因此可以考虑将lmkd查杀策略设置的相对激进一些,使得后台存活的进程少一点;同时,原生lmkd只是监控了memory的psi压力,而cpu和memory的psi压力值变化并不一定是同步的,因此可以增加lmkd对cpu的psi压力的监控,使得在cpu对应psi压力较大时也能触发lmkd去kill一些后台进程。从应用层面来说,可以确认相关binder通信是否属于正常业务,以及这些binder通信是否需要等待其执行结果,如果不需要,那么可以将这些binder通信放在子线程去做,以免主线程发生阻塞。















 469
469











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









