






Elastic Stack从入门到实践—Elasticsearch 篇
Elasticsearch 篇
零、官网文档
elastic.co/guide/en/elasticsearch/reference/7.13/analysis-custom-analyzer.html
一、Elasticsearch与Kibana入门
1.elasticsearch地址、kibana地址
elasticsearch地址:
http://192.168.43.112:9200/
kibana地址:
http://192.168.43.112:5601/

2.CRUD
{1}创建:
POST /accounts/_doc/1
{“name”:“:json”,
"lastName:“doe”,
describution:"system administrator and linux spaeciale "}
{2}查询:
GET /accounts/_doc/1
{3}修改:
PUT /accounts/_doc/1
{
“describution”:“system administrator and linux”
}
{4}删除:
DELETE /accounts/_doc/1
/accounts 是索引代表表
/_doc 已经弃用,但是还是需要占位
/1 表示ID1
json内容是存储的数据
3.elasticSearch query
(1).query String
GET /accounts/_doc/_search?q=json
(2).query DSL
GET /accounts/_doc/_search
{
“query”:{
“match”:{
“name”:“json”
}
}
}
二、Beats、FileBeat入门
beat:轻量级的数据传输工具
主要有fileBeat(日志文件)、packageBeat(网络数据、MySQL、es)
FileBeat
1.处理流程
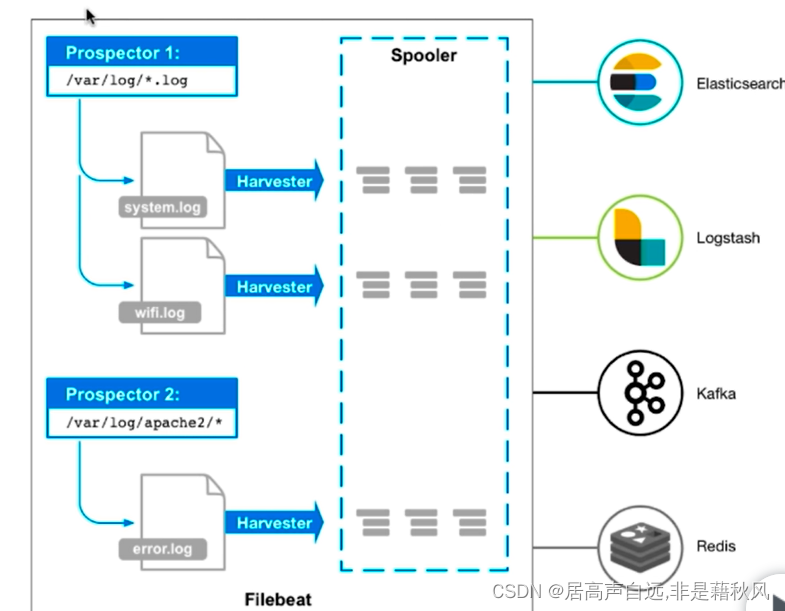
监控文件,配置观察者prospector传输到kafka/Redis/logstash/elasticsearch
三、logstash
非轻量级的数据传输、etl工具;它和Beats相比,转换的功能更加强大

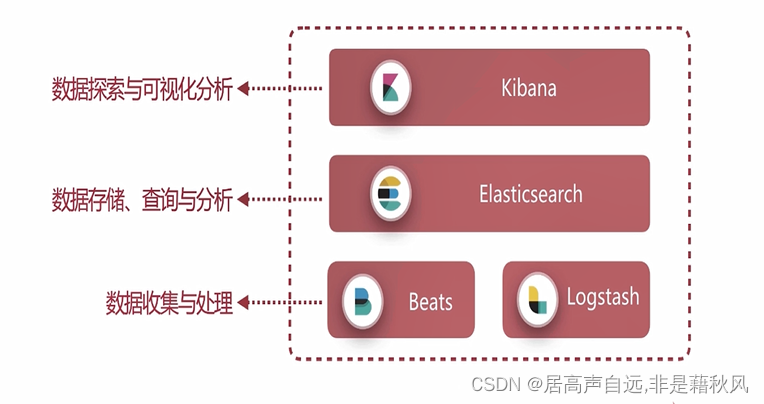
四、Elastic Stack
Elasticsearch
数据存储和查询
Logstash Beats
数据收集和处理,etl操作。
数据源多样性:数据文件:日志、Excel;数据库:MySQL、Oracle;HTTP服务;网络数据
Kibana
数据探索和可视化分析
三、ElasticSearch入门
1.常见的术语
(1)文档 document
用户存储在es中的数据文档等同于MySQL中的一行数据


(2)索引index
具有相同字段的文档列表组成,等同于MySQL中的表

(3)节点node
一个es的运行实例,是集群的构成单元
(4)集群cluster
是一个多值多个节点组成,对外提供服务
(5)field字段
文档的属性
2.restAPI
URI指定资源:index、document
http method指明操作类型:GET 获取、post 新建修改、PUT 新建修改、DELETE删除
常用的交互方式:1.curl命令行 2. kibana
(1).post和put的区别
post和put都有新建和修改的效果;区别是post可以不加ID,自动创建ID。post如果也加上ID等同于put。尽量使用put,如果需要随机创建ID的情况下在使用post
(2).索引API
用于专门的处理index的API,用于创建、更新和删除索引的操作
PUT /test_index2 创建索引
get _cat/indices 查询所有的索引
delete /test_index2 删除索引
(3).文档API
创建文件
PUT /test_index/_doc/1
{
“id”:“111”,
“name”:“zj”
}
创建文件的时候索引不存在会自动来创建索引和type
查询文档
get /test_index/_doc/1
_soucre存储了完整的原始数据
查询所有的ID
GET /test_index/_search
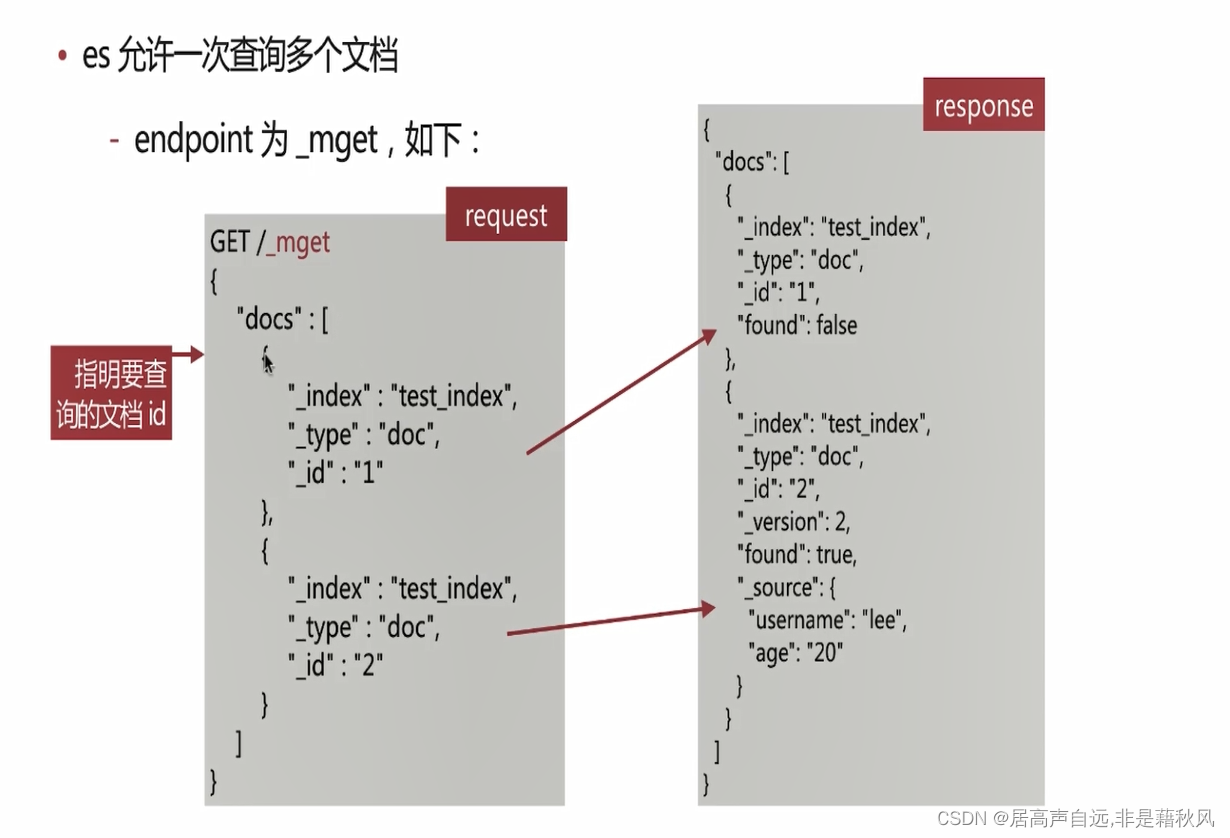
批量导入,多个json,现指定action_type; index(强制创建,如果有了覆盖)、update(更新)、create(创建,存在会报错)、delete(删除)

批量查询
Elasticsearch 倒排索引和分词
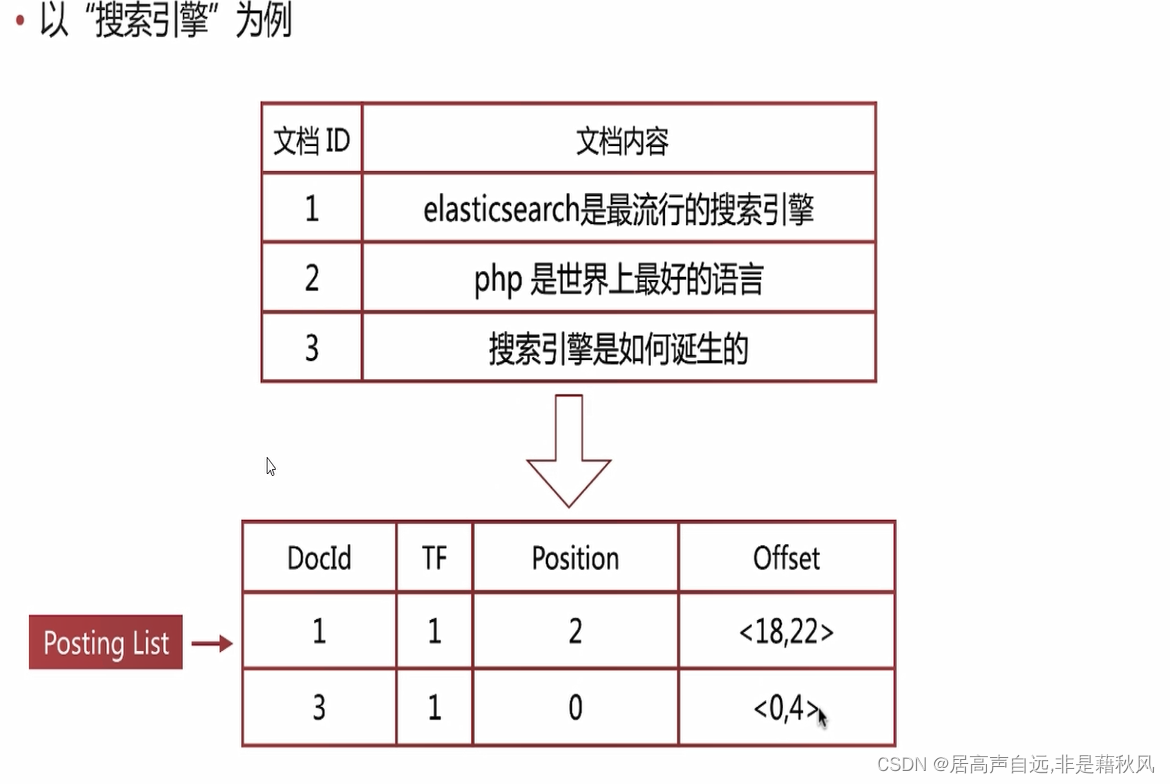
正排索引和倒排索引
文档ID到文档内容是正排索引;通过单词找到文档ID是倒排索引。
倒排索引
单词词典
所有文档的单词
单词到列表的关联信息
B+tree实现
倒排列表
倒排索引项组成
倒排索引项:
文档ID
单词频率TF
位置Position
偏移Offset
es存储是一个json格式的文档,其中包含多个字段,每个字段都会有自己的倒排索引

分词
分词就是讲文本转化成单词的过程

分词器

analyze API
es提供了一个测试分词的API接口;_analyze
针对文本进行分词测试
POST _analyze
{
“analyzer”: “standard”,
“text”: “hello world”
}
针对已创建的索引的字段进行分词测试
POST /test_index/_analyze
{
“field”: “name”,
“text”:“hello world!”
}
es自带分词器
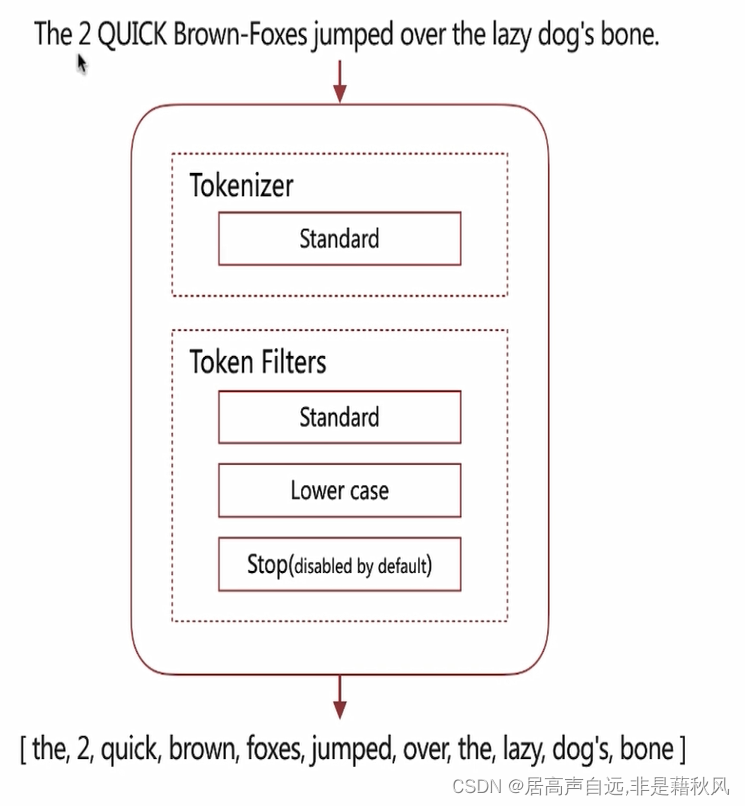
standard
默认的分词器,转小写,按词切分,支持多语言
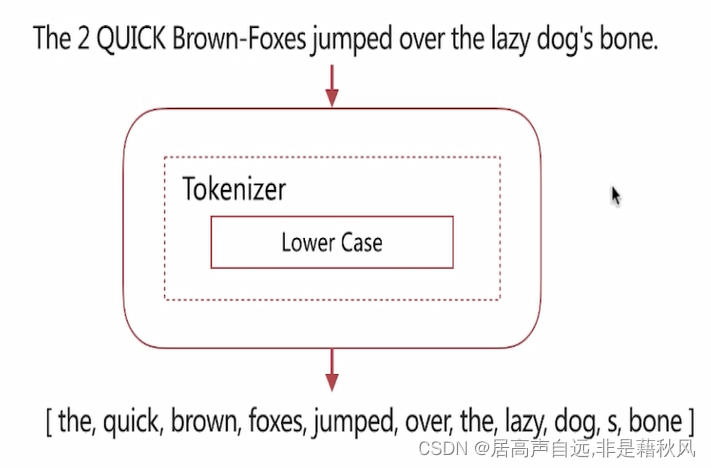
simple
按照非字母切分,小写处理
会将数字过滤掉
‘s会切分成两个词
whitespace
按照空格来切分
stop
在simple的基础上过滤掉the to 等简单的无意义的词
keyword
不分词作为一个整个单词输出
patten
通过正则表达式进行自定义切分
默认是非字符进行切分
中文分词器
ik jieba
自定义分词
当分词没法满足需求的时候,可以自定义分词
通过自定义character filter 、tokenizer、token filter实现
使用方式:
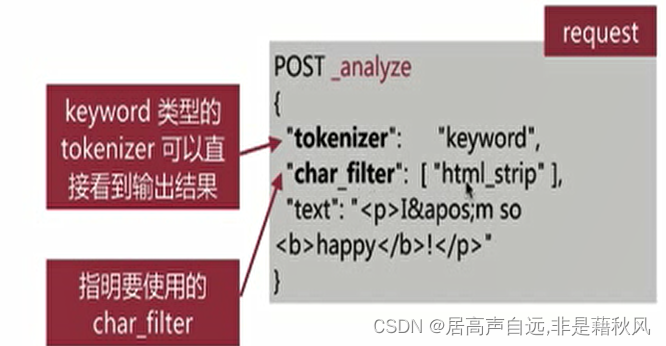
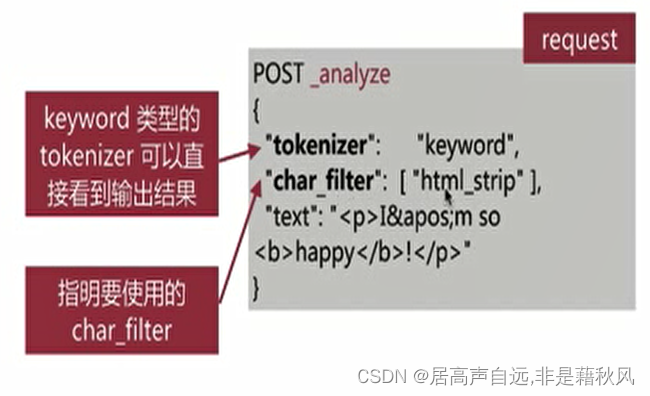
1.设置成keyword类型
2.char_filter:
character filters
是在tokenizer之前对原始文本进行处理,比如增加、删除或者替换字符等
自带的 html_strip 去除HTML标签和转换HTML实体
mapping 进行字符替换操作
pattern replace 进行正则表达式匹配替换
会影响后续tokenizer解析的position和offset信息
tokenizer
在character filters后对文本进行一定规则的切分
自带如下
standard 按照单词进行分割
letter 按照分字符类进行分割
whitspace 按照空格进行分割
UAX URL Email 按照standard进行分割,但是不分割邮箱和URL
Ngram和Edge NGram 连词分割,类似输入提示
path_hierarchy 按照文件路径进行分割
GET /_analyze
{
“tokenizer”: “path_hierarchy”,
“text”: “/one/two/three”
}
token filters
对于tokenizer 输出的单词进行增加、删除、修改操作
自带的
lowercase 将所有的文本转成小写
stop 删除 stop words
Ngram 和edge ngram连词分割
synonym 近义词
filter可以多个
GET /_analyze
{
“tokenizer”: “standard”,
“text”:“the An,a,A,AN,an ,hello,world”,
“filter”: [
“stop”,
“lowercase”,{
“type”:“ngram”,
“min_gram”:1,
“max_gram”:2
}
]
}
自定义分词
PUT /test_index_1
{
“settings”: {
“analysis”: {
“analyzer”: {
“my_custom_analysis”:{
“type”:“custom”,
“tokenizer”: “standard”,
“char_filter”: [
“html_strip”
],
“filter”: [
“lowercase”,
“asciifolding”
]
}
}
}
}
}
分词使用说明
分词在创建或者更新文档时进行分词设置,查询时会对查询语句进行分词
一般来说两者一致,创建的时候设置分词,查询的时候走默认分词
curl -X PUT “localhost:9200/my-index-000001?pretty” -H ‘Content-Type: application/json’ -d’
{
“mappings”: {
“properties”: {
“title”: {
“type”: “text”,
“analyzer”: “whitespace”
}
}
}
}
如果不需要分词Type设置成keyword,可以节省空间和提高写性能
mapping
类似数据库中的表结构定义
定义index下的字段名
定义字段的类型
定义倒排索引的相关设置,比如是否索引等
获取mapping
get /test_index/_mapping
mapping 中的字段类型一旦设置以后,禁止修改
如果想修改,需要建立新的索引,然后reindex操作
dynamic
通过dynamic参数来控制字段的新增
true默认允许自动新增字段
false 不允许自动新增字段,但是文档可以正产写入,但是无法对字段进行查询操作
strict文档不能写入,报错
PUT /mapping_index
{
“mappings”: {
“dynamic”:“strict”,
“properties”: {
“id”:{
“type”: “text”
},
“name”:{
“type”: “keyword”
},
“age”:{
“type”:“integer”
}
}
}
}
copy_to
将该字段的值复制到指定目标字段,不会出现在_source中,只能用来搜索。
index
当前字段是否索引,默认是true,即纪录索引,false不记录,即不可搜索
适用于敏感数据不想被搜索
节省空间,false后不进行倒排索引
index_options 用于控制倒排索引记录的内容
- docs 只记录docID
- freqs 纪录doc id和词频
- positions 纪录文档ID和词频和位置
- offsets纪录文档ID和词频和位置和偏移量
- text类型默认的是positions,其他默认是docs
- 纪录内容越多,占用的空间越大
null_value
当字段遇到null值的时候,默认是null 也就是空值,es会忽略该值,也可以通过设定该字段的默认值
数据类型
核心数据类型
- 字符串类型 text、keyword
- 数值型 long、integer、short、byte、double、float、half_float、scaled_float
- 日期类型 date
- 布尔类型 boolean
- 二进制类型 binary
- 范围类型 integer_range、float_range、long_range、double_range、date_rangge
复杂数据类型 - 数组类型 array
- 对象类型 object
- 嵌套类型 nested_object
- 地理位置类型 geo_point、geo_shape
专用类型 - 纪录IP地址IP
- 实现自动补全 completion
- 纪录分词数 token_count
- 记录字符串hash值
多字段特性 multi_fields
允许对同一个字段采用不同的配置,比如分词,拼音和中文的同时搜索,只需要在人名汇总新郑一个子字段为pinyin即可

dynamic mapping
es默认会根据字段类型推测创建字段
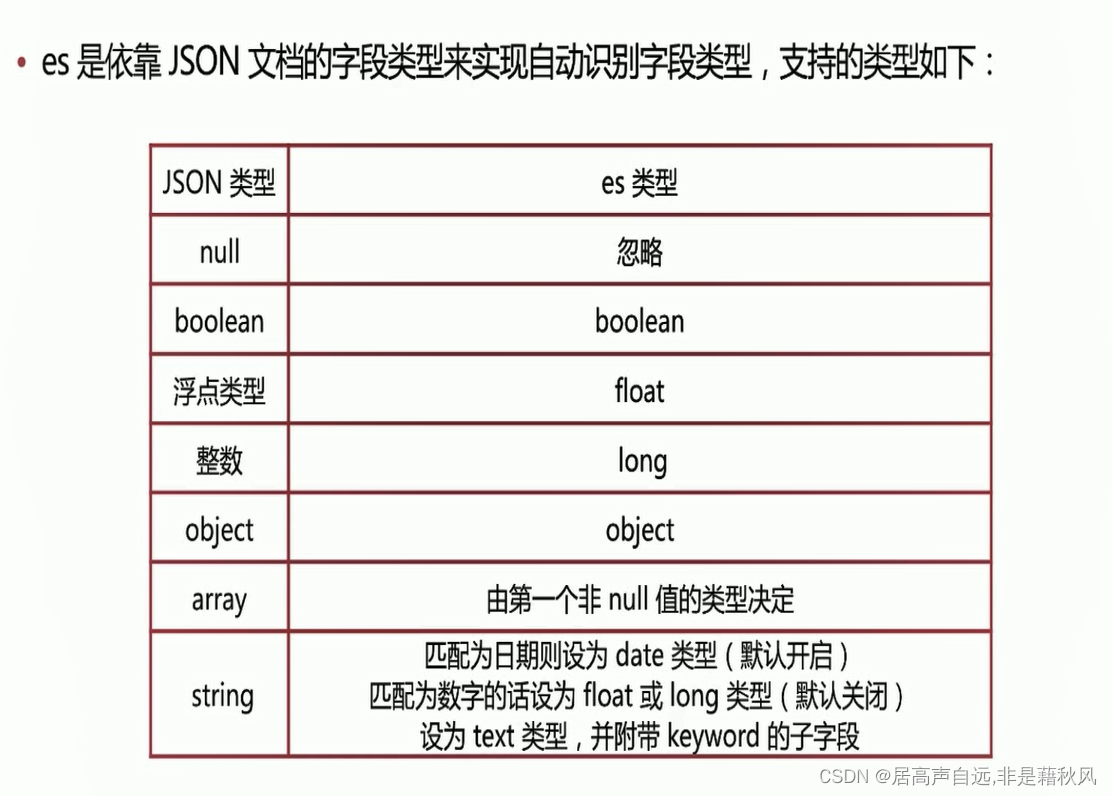
自定义mapping模板
PUT /my_index_03
{
“mappings”: {
“dynamic_templates”: [
{
“strings_as_ip”: {
“match_mapping_type”: “string”,
“mapping”:{
“type”:“keyword”
}
}
}
],
“properties”: {
“full_name”:{
“type”: “text”
}
}
}
}
Search API
_search
- get /_search
- get /my_index/_search
- get /my_index,my_index2/_search
- get /my_*/_search
主要的查询形式
url search
操作简单,但是只能部分语法支持
get /my_index/_search?q=ouser
requestbody search
完备的查询语法
get /my_index/_search
{
“query”:{
"term:{}}
}
query 字段类查询
全文匹配
针对text类型的字段进行全文检索,会对查询语句进行分词处理,如:match、match_phrase等query类型
GET /my_index_03/_search
{
“query”: {
“match”: {
“last_name”: “TEXT”
}
}
}
match匹配流程
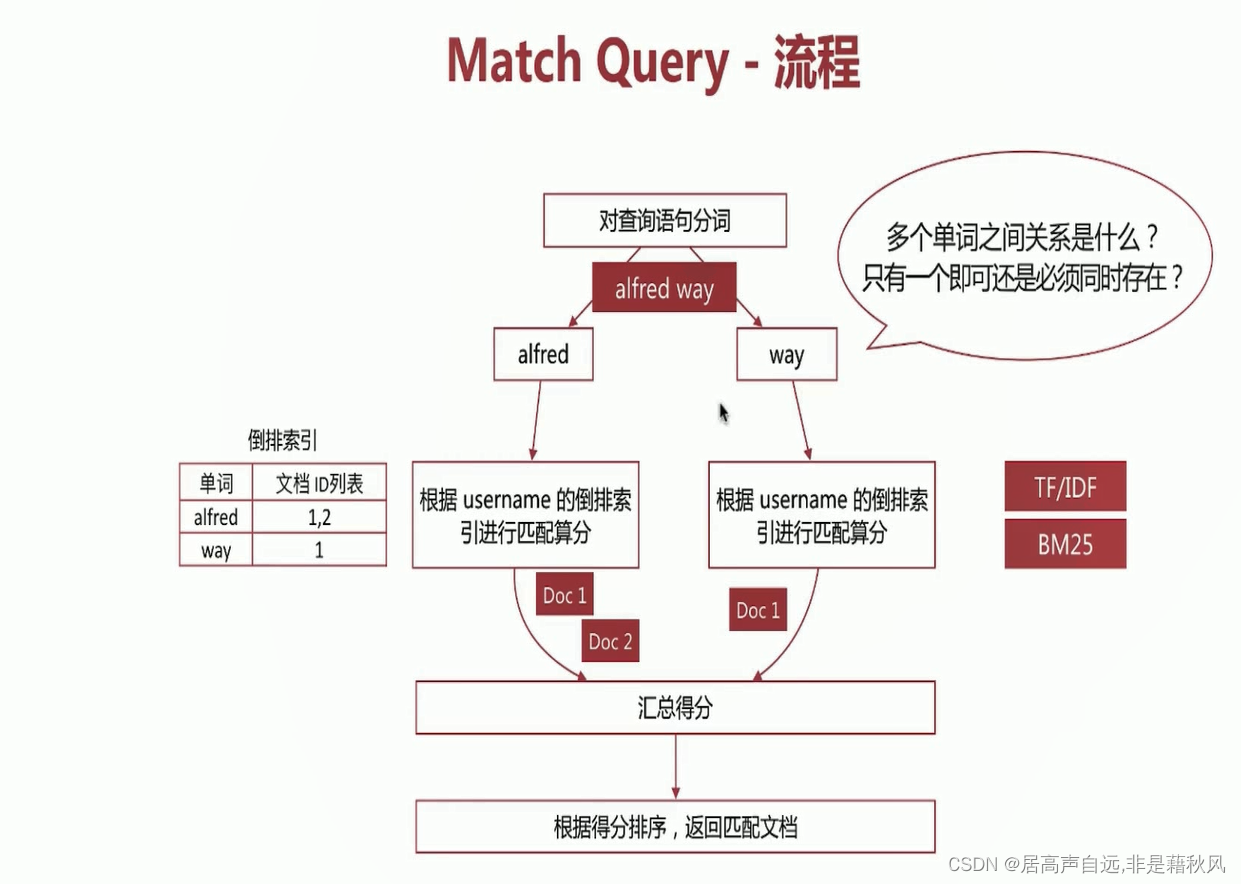
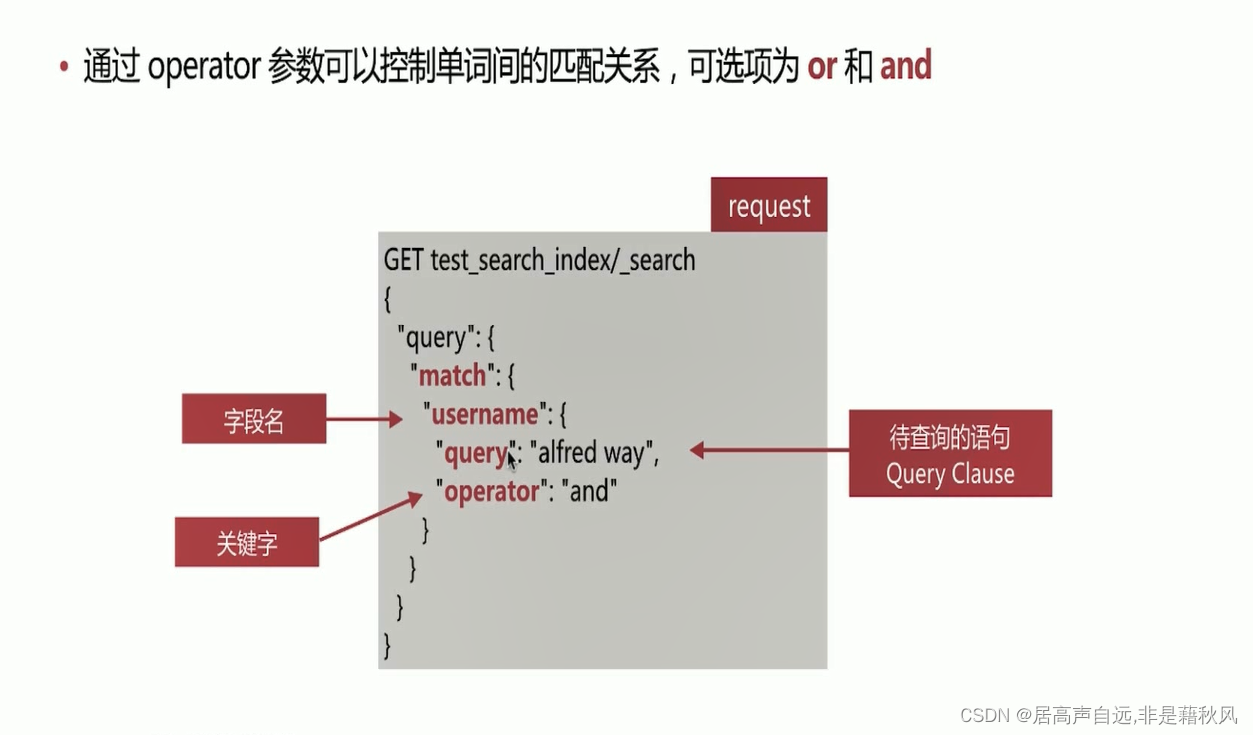
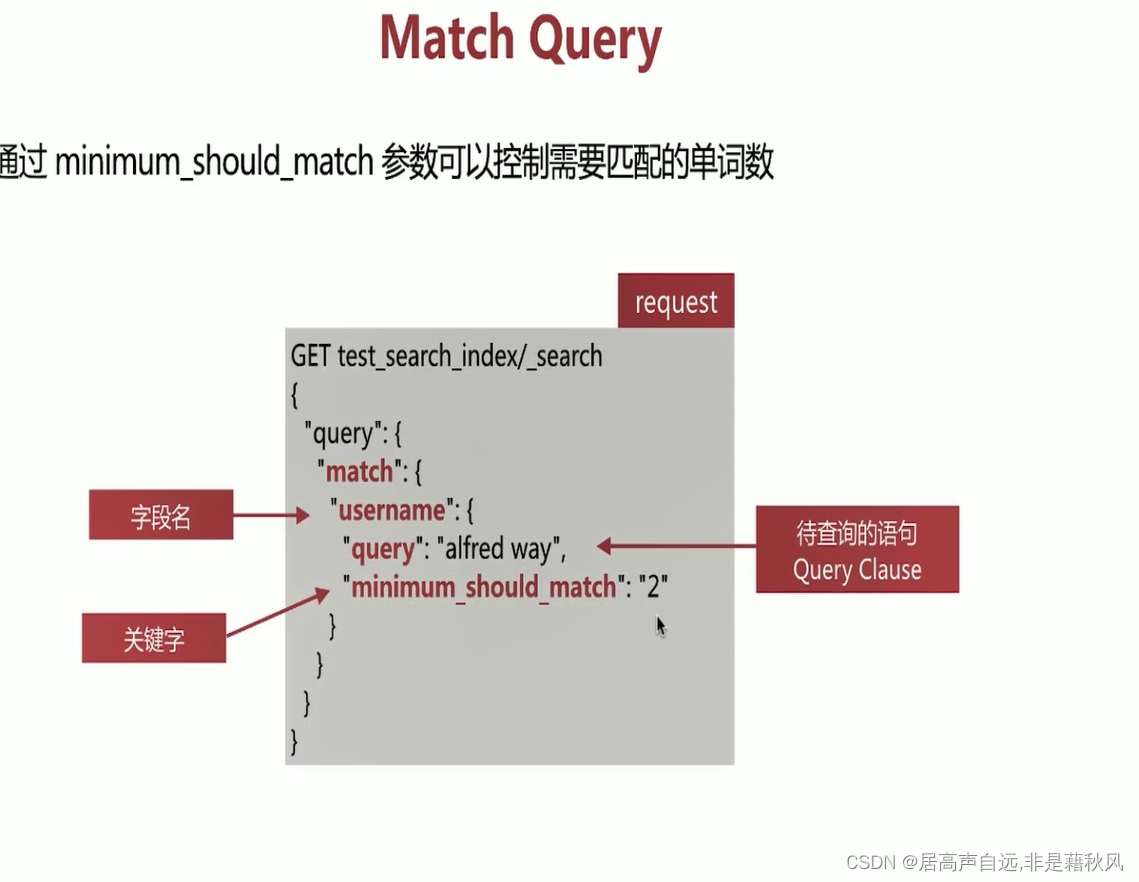
match_phrase
对字段检索时有顺序要求,搭配slop可以控制单词间的间隔
query string query
类似于uri search中的q参数查询
term
term是对查询语句不进行分词,直接整体进行查询
注意:term是要和存储的倒排索引进行匹配,所以如果索引时分词无法匹配到查询时的整个语句是查询不出来的
GET /comp_jz_index/_search
{
"query": {
"term": {
"full_name": {
"value": "横琴"
}
}
}
}
range query
用于数值类型和日期类型的比较查询
GET /test_index/_search
{
"query":{
"range": {
"id": {
"gte": 11,
"lte": 22
}
}
}
}
复合查询
复合查询是指包含字段类查询或者复合查询的类型
constant _score query
该查询将内部的查询结果文档得分都会设置成1或者是boost的值,多用于结合bool查询实现自定义得分
GET /comp_jz_index/_search
{
"query": {
"constant_score": {
"filter": {
"match":{
"full_name":"珠海"
}
},
"boost": 1.2
}
}
}
bool query
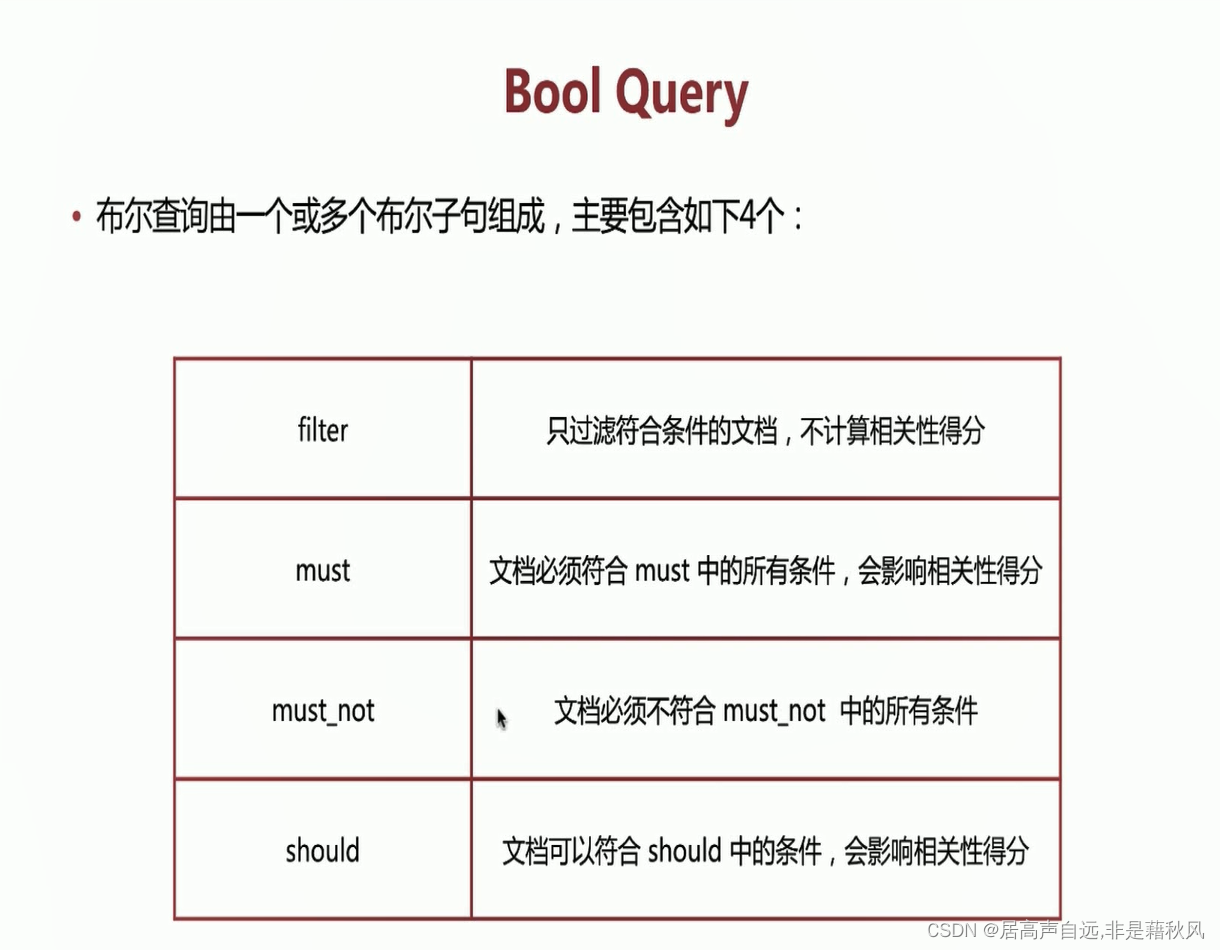
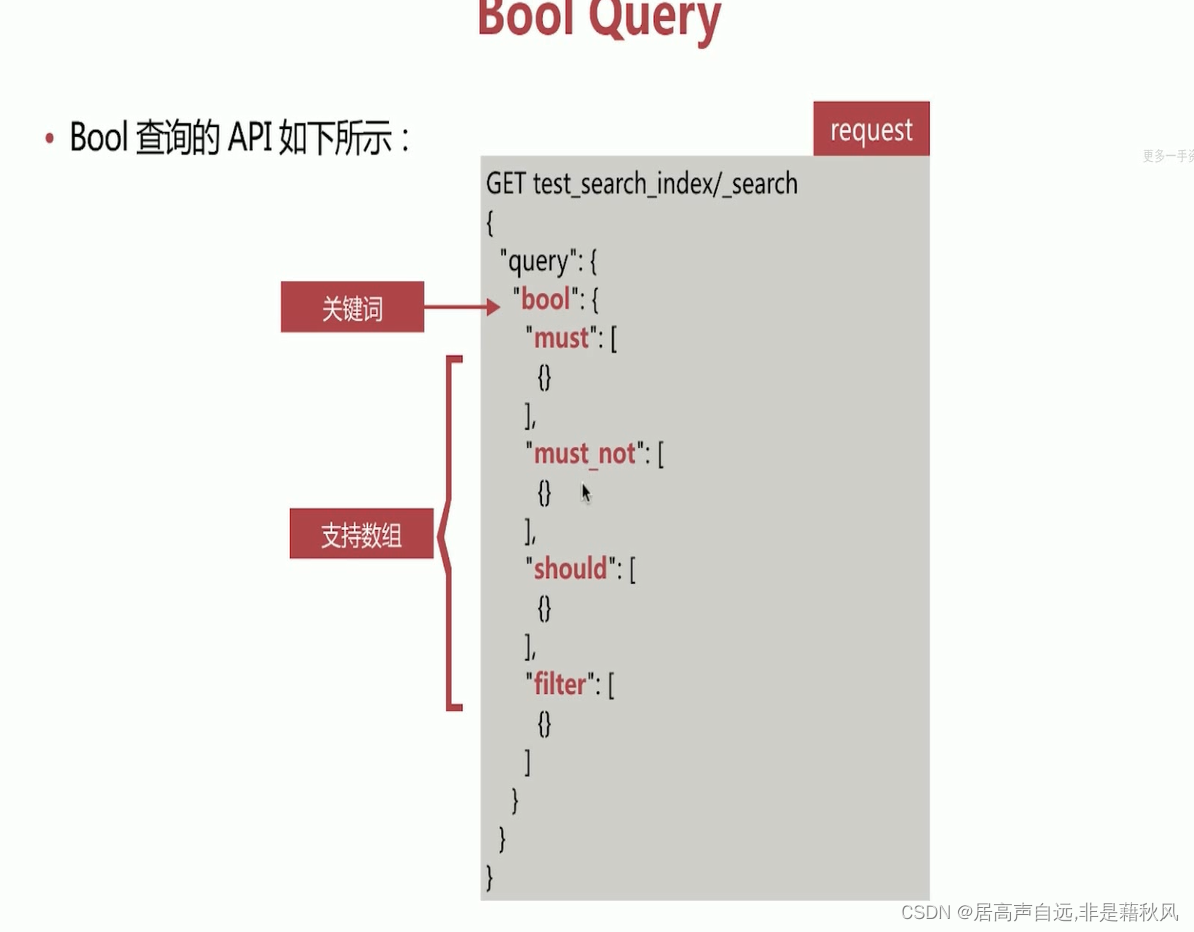
filter
filter查询只过滤复合条件的文档,不会进行相关性得分。
- es针对filter会有智能缓存,因此执行效率高
- 做简单匹配查询不许需要考虑得分,推荐使用filter
GET /comp_jz_index/_search
{
“query”: {
“constant_score”: {
“filter”: {
“match”:{
“full_name”:“珠海”
}
},
“boost”: 1.2
}
}
}
must
两个match query文档最终得分为得分加和
GET /comp_jz_index/_search
{
“query”: {
“bool”: {
“must”: [
{
“match”: {
“full_name”: “珠海”
}
},
{
“match”: {
“name”: “芯”
}
}
]
}
}
}
should
同时包含should和must时,文档不需要满足should中的条件,但是如果满足条件,会增加相关性得分
GET /comp_jz_index/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"full_name": "珠海"
}
}
],
"should": [
{
"match": {
"name":"龙马智芯"
}
}
]
}
}
}
count
GET /comp_index/_count
_source
可以过滤出想要返回的字段,节省网络开销
GET /comp_jz_index/_search
{
“_source”: [“full_name”],
“query”: {
“bool”: {
“must”: [
{
“match”: {
“full_name”: “珠海”
}
}
]
}
}
}
单词匹配
不会对查询语句做分词处理,直接去匹配字段的倒排索引,如term、terms、range等query类型
#AND OR要大写
GET /my_index_03/_search
{
"profile": true,
"query": {
"query_string": {
"fields": ["full_name","last_name"],
"query": "full1 AND last1"
}
}
}
相关性算分
- 词频,单词在该文档出现的次数越高,相关性越高
- 文档频率,单词出现的文档数
- 逆向文档频率,单词出现的文档数越少,相关性越高
- 文档越短,相关性越高
两个相关性算分模型
TF/IDF模型
BM25 5以后默认的模型
BM25是对TF/IDF的一个优化,在词频无线大的时候得分不会在指数性增长,会趋于稳定
可以通过explain参数来查看具体的计算方法
es算分是按照shard进行的,每个shard的分数是相互对立的,所以在使用explain的时候需要注意分片
search 的运行机制
search的运行机制-query阶段
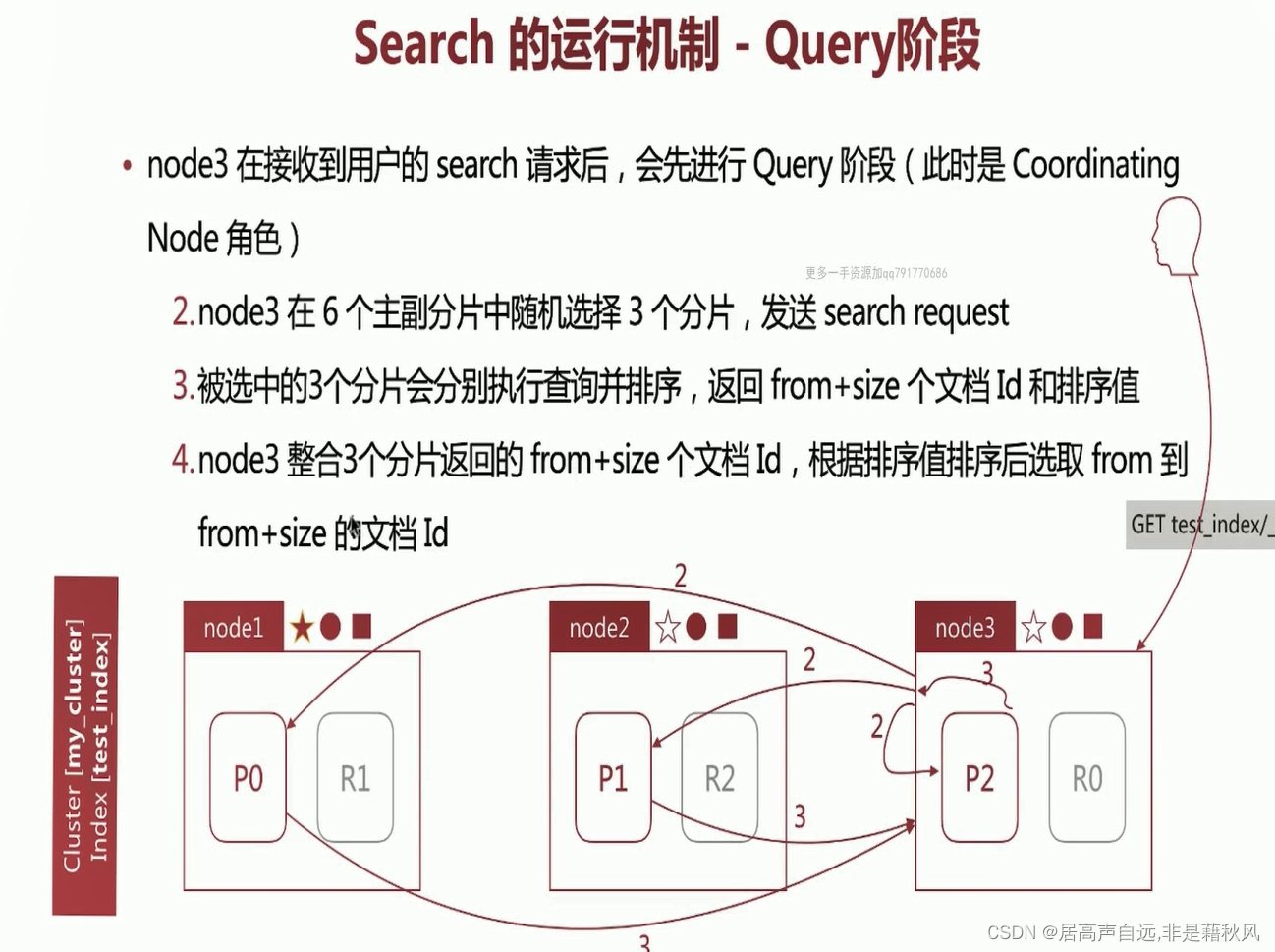
search运行机制-fetch阶段
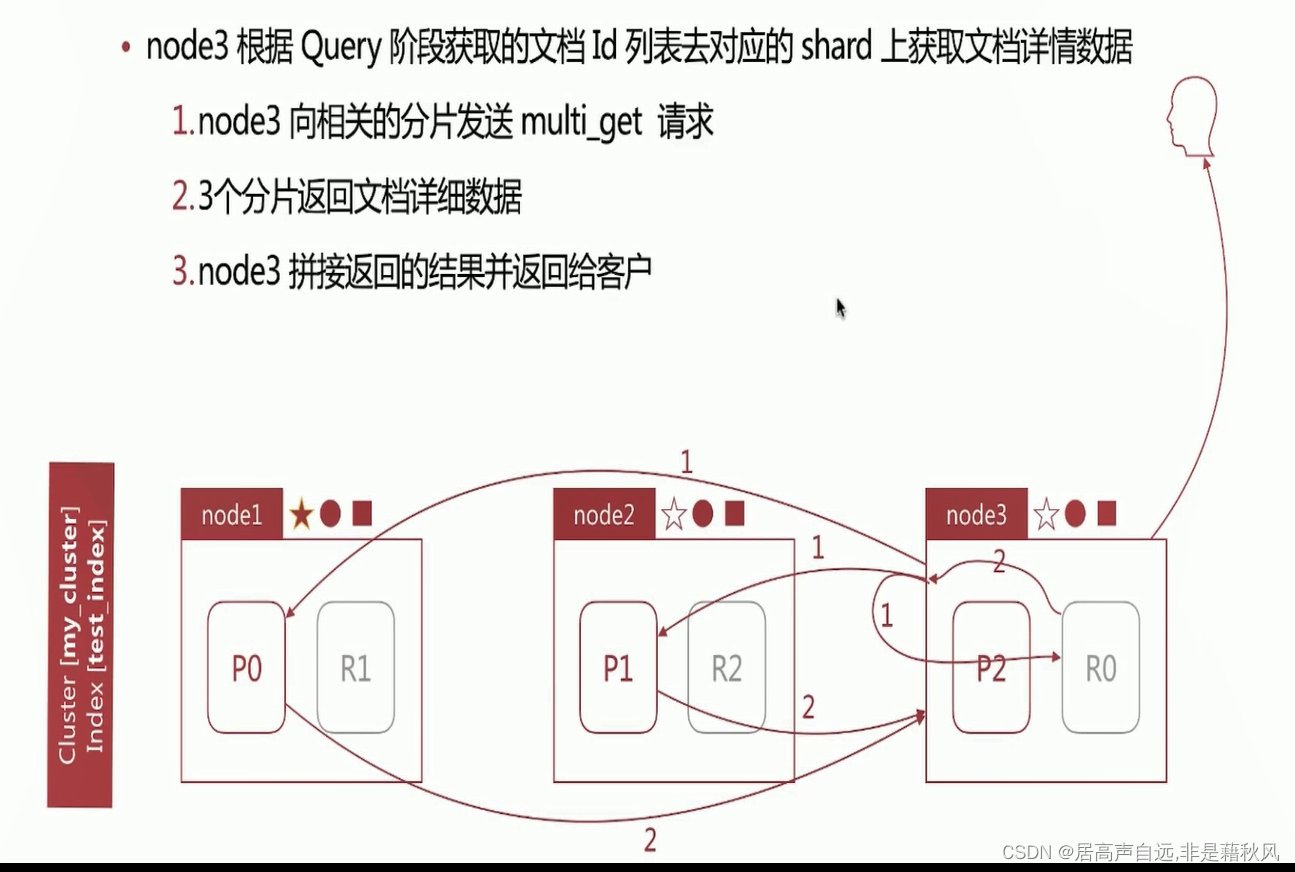
search的运行机制-相关性算分问题
相关性算分在shard和shard之间是相互独立的,也就是一个term的idf值在shard上是不同的,文档的相关性算分和它所处的shard相关
文档数量少的时候,会导致相关性算分严重不准的情况
相关性算分解决方式
- 设置分片为1,但是一个分片适合存放千万级别以下的文档数量
- 使用query-then-fetch查询方式
排序
在这里插入图片描述
遍历和分页
from/size
从0开始 获取前三个 from0 size3
深度分页问题:获取前10个文档,需要从每个分片上获取10个然后在汇总获取10个文档。
当页数越深,需要处理的文档就越多,耗时更长,尽量避免深度分页
scroll
使用快照的方式避免深度分页,数据不是实时的,尽量避免_sort条件
search_after
实时获取下一页的文档,缺点是不能指定from参数,也就是不能指定页数
只能下一页不能上一页
聚合分析
聚合分析-分类
bucket,分桶类型类似sql中的groupby语法
metric
metric,指标分析类型,计算最大值,最小值
主要是两类:
单值分析,只能出一个分析结果
min、max、avg、sum
cardinality(distinct count)
多值分析,输出多个分析结果
stats、extended stats
percentile/percentile rank
top hits
查询最小值
GET /my_index_01/_search
{
“size”: 0,
“aggs”: {
“min_age”: {
“min”: {
“field”: “age”
}
}
}
}
stats
一次返回最大值、最小值、平均值、综合
GET /my_index_01/_search
{
“size”: 0
, “aggs”: {
“stats_age”: {
“stats”: {
“field”: “age”
}
}
}
}
exaterned_stats
在stats的基础上返回方差、标准差等指标
pipeline,管道分析类型,基于上一级的集合分析结果进行在分析
bucket
分桶
bucket+metric聚合分析
分桶后再对数据进行指标分析
pipeline
针对聚合分析的结果再次进行聚合分析
pipeline的分类
pipeline的分析结果会输出到原结果中,根据书输出的位置不同,分为两类
parent结果内嵌到现有的聚合分析结果中
- derivative
- moving average
- cumulative sum
sibling结果和现有的聚合分析结果同级
- max、min、AVg、sum bucket
- stats、extended stats
bucket
桶,按照一定的规则吧数据分在不同的桶里面
terms
直接按照term来分桶,如果是text类型,按照分词后的结果分桶。
GET /my_index_01/_search
{
"size": 0
, "aggs": {
"jobs": {
"terms": {
"field": "firstname.keyword",
"size": 10
}
}
}
}
range
获取范围分桶
date_range
根据时间获取范围分桶
historgram
固定间隔进行分桶
date historgram
按照时间进行固定间隔的分桶
数据建模
数据建模的过程
- 概念建模 确定系统核心需求和范围边界,设计实体和实体之间的关系
- 逻辑建模 梳理每个实体之间的属性和关系和约束关系等
- 物理建模 结合具体的数据库产品,在能满足需求的前提下确定最中的建表语句
mapping字段的相关设置
- enbaled
-
true|false -
仅存储,不做搜索或者聚合分析,false节省磁盘空间 - index
-
true|false -
是否构建倒排索引 - index_options
-
docs、freqs、positions、offsets -
存储倒排索引的哪些信息 - norms
-
true|false -
是否存储归一化相关参数,如果不仅用于过滤和聚合分析 - doc_values
-
true|false -
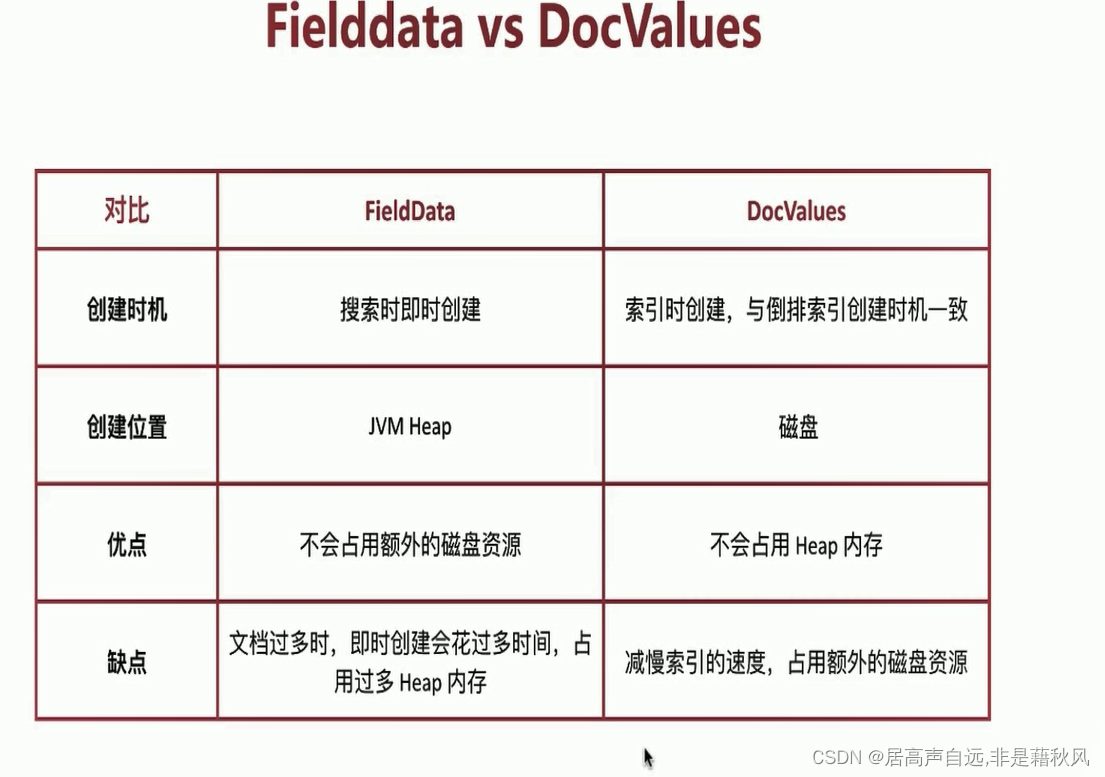
是否启用doc_values,用于排序和聚合分析 - field_data
-
false|true -
是否为text类型启用fielddata,实现排序和聚合分析 - store
-
false|true -
是否存储该字段 - coerce
-
true|false -
是否开启自动数据类型转换功能,比如字符串转为数字、浮点转整型等 - dynamic
-
true|false|strict -
控制mapping自动更新,true自动更新,falsemapping不更新但是不报错,strict严格模式报错 - date_detection
-
true|false -
是否自动识别日期类型
mapping字段属性的设定流程
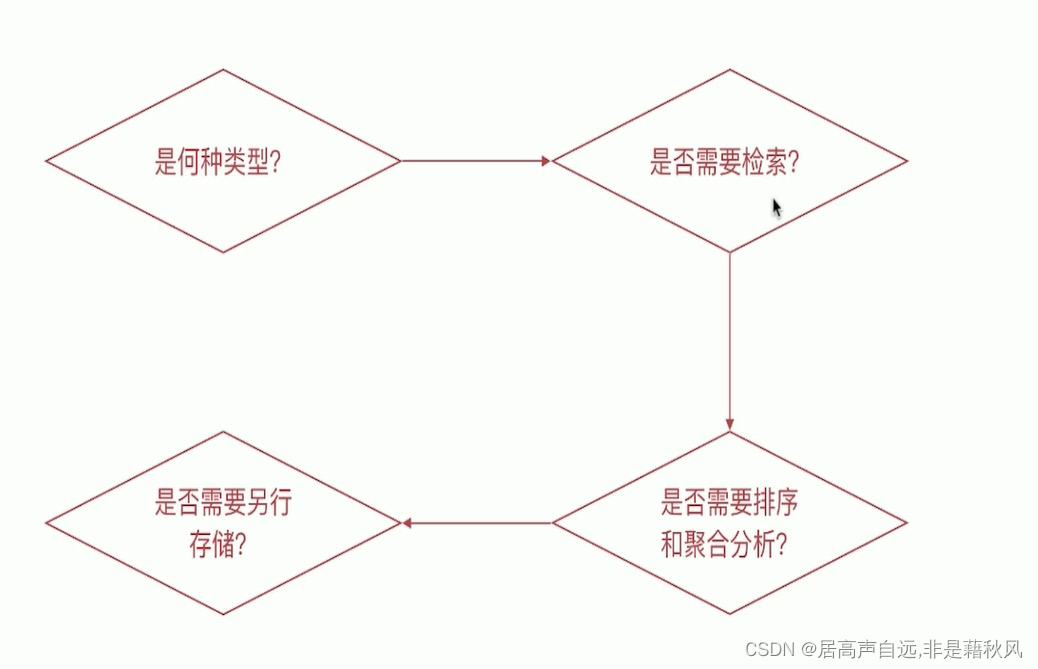
是何种类型?
- 字符串类型
-
需要分词设置成text类型,不需要设置成keyword类型 - 枚举类型
-
基于性能考虑设置成keyword类型,即便是整型的也考虑设置成keyword类型 - 数值类型
-
尽量选择贴近的类型,能确定是byte就不要用long - 其他类型
-
比如布尔类型、日期、地理位置数据等
是否需要要检索?
- 完全不许哟啊检索、排序、聚合分析的字段
-
enabled设置成false - 不需要检索的字段
-
index设置成false - 需要检索的字段,可以通过以下的配置设定需要的存储粒度
-
index_options 结合需要设定 -
norms 不需要归一化数据时关闭即可
是否需要排序和聚合分析
- 不需要排序或者觉和分析功能
-
doc_valuses 设定成false -
fielddate设定成false
是否需要另行存储?
- 需要专门存储当前字段的数据
- store设定成true,可存储该字段的原始内容(与_source中的不相关)
- 一般结合_source的enabled设定成false使用
实例
#对于title字段我们想要分词并且加一个子字段能进行正文匹配
#对于author字段设置成keyword,不进行分词
# url 设置成只做展示
# es数据默认是存在_source中的,如果有某个字段数据量很大,性能影响很大,source返回是全量字段返回的,哪怕是过滤也是内部全量,展示简单过滤。
#store是另行存储的意思,store会将字段单独存储一份,字段间进行解耦,想获取哪个字段获取哪个字段,好处是效率高,尤其是有大字段的情况下,缺点是获取的时候稍微复杂一点。读取的时候不一样,需要指定字段
PUT blog_index
{
"mappings": {
"_source": {
"enabled": false
},
"properties": {
"title":{
"store": true,
"type": "text",
"fields": {
"keyword":{
"type":"keyword"
}
}
},
"publishj_date":{
"store": true,
"type":"date"
},
"author":{
"store": true,
"type":"keyword"
},
"abstract":{
"store": true,
"type":"text"
},
"content":{
"store": true,
"type":"text"
},
"url":{
"type":"keyword",
"doc_values": false,
"norms": false,
"store": true
}
}
}
}
#读取方式
GET blog_index/_search
{
"stored_fields": [
"title"
],
"query": {
"term": {
"author": "作2者"
}
}
}
关联关系处理
Nested Object
PUT nested_object_index
{
"mappings": {
"properties": {
"title":{
"type": "text",
"fields": {
"keyword":{
"type":"keyword"
}
}
},
"publishj_date":{
"type":"date"
},
"author":{
"type":"keyword"
},
"abstract":{
"type":"text"
},
"content":{
"type":"text"
},
"url":{
"type":"keyword"
},
"comments":{
"type": "nested",
"properties": {
"username":{
"type":"keyword"
},
"date":{
"type":"date"
},
"content":{
"type":"text"
}
}
}
}
}
}
PUT nested_object_index/_doc/1
{
"title":"blog number one",
"auther":"alfred",
"comments":[
{"username":"lee","date":"2017","content":"awesome article"},
{
"username":"fax","date":"2018","content":"thanks"
}
]
}
GET nested_object_index/_search
{
"query": {
"nested": {
"path": "comments",
"query": {
"bool": {
"must": [
{
"match": {
"comments.username": "lee"
}
},
{
"match": {
"comments.content": "awesome"
}
}
]
}
}
}
}
}
Parent/child
#join关键字,Type设置父类的key,relations里面父类的标识:子类的标识
DELETE blog_index_parent_child
PUT blog_index_parent_child
{
"mappings": {
"properties": {
"join":{
"type": "join",
"relations":{
"blog":"comment"
}
}
}
}
}
#添加主类,建索引时Type:join,索引主类需要join key,relations中是blog:comment,所以父类value是blog
PUT blog_index_parent_child/_doc/1
{
"title":"blog1",
"join":"blog"
}
PUT blog_index_parent_child/_doc/2
{
"title":"blog2",
"join":"blog"
}
#子类的索引要和父类区分开,同事routing设置成父类的ID,目的是能和父类在同一个分片上,避免异常
PUT blog_index_parent_child/_doc/child-1?routing=1
{
"comment":"comment world",
"join":{
"name":"comment",
"parent":1
}
}
PUT blog_index_parent_child/_doc/child-2?routing=2
{
"comment":"comment hello",
"join":{
"name":"comment",
"parent":2
}
}
GET blog_index_parent_child/_search
#查询父类ID是2的数据
GET blog_index_parent_child/_search
{
"query": {
"parent_id":{
"type":"comment",
"id":2
}
}
}
#查询父类数据
GET blog_index_parent_child/_search
{
"query": {
"has_child": {
"type": "comment",
"query": {
"match": {
"comment": "hello"
}
}
}
}
}
#查询主类数据
GET blog_index_parent_child/_search
{
"query": {
"has_parent": {
"parent_type": "blog",
"query": {
"match": {
"title": "blog2"
}
}
}
}
}

reindex
指重建所有的数据过程,一般发生在如下情况,重新创建一个索引库,将数据复制到新的索引库中
mapping设置变更,比如字段类型变化,分词器字典更新等
index设置变更,比如分片数更改等
迁移数据
es有现成的api用于完成这个工作
_update_by_query 在现有索引上重建
_reindex 在其他索引长重建
reindex
#将source中的数据重建到dest中
POST _reindex
{
"source": {
"index": "reindex_index2"
},
"dest": {
"index": "reindex_index1"
}
}
#也可以部分数据迁移
POST _reindex
{
"source": {
"index": "reindex_index2",
"query": {
"term": {
"auther": {
"value": "auther3"
}
}
}
},
"dest": {
"index": "reindex_index1"
}
}
















 2111
2111











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











