







 本文介绍了使用Python爬虫爬取QQ音乐刘德华单曲的过程,包括目标分析、代码编写与执行。通过Selenium模拟浏览器操作,配合BeautifulSoup解析网页,将单曲信息存储到Excel中。后续计划优化下载速度和解析效率。
本文介绍了使用Python爬虫爬取QQ音乐刘德华单曲的过程,包括目标分析、代码编写与执行。通过Selenium模拟浏览器操作,配合BeautifulSoup解析网页,将单曲信息存储到Excel中。后续计划优化下载速度和解析效率。
一、前言
qq music上的音乐还是不少的,有些时候想要下载好听的音乐,但有每次在网页下载都是烦人的登录什么的。于是,来了个qqmusic的爬虫。至少我觉得for循环爬虫,最核心的应该就是找到待爬元素所在url吧。
二、Python爬取QQ音乐单曲


爬虫步骤
1.确定目标
首先我们要明确目标,本次爬取的是QQ音乐歌手刘德华的单曲。
(百度百科)->分析目标(策略:url格式(范围)、数据格式、网页编码)->编写代码->执行爬虫
2.分析目标
歌曲链接:
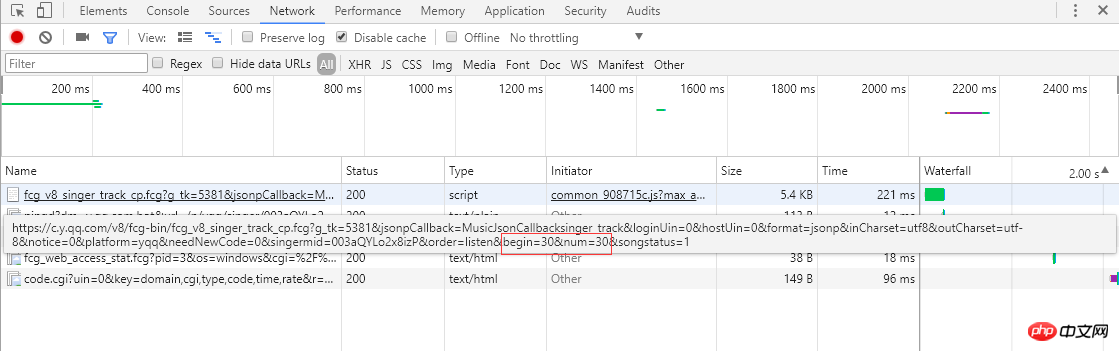
从左边的截图可以知道单曲采用分页的方式排列歌曲信息,每页显示30条,总共30页。点击页码或者最右边的">"会跳转到下一页,浏览器会向服务器发送ajax异步请求,从链接可以看到begin和num参数,分别代表起始歌曲下标(截图是第2页,起始下标是30)和一页返回30条,服务器响应返回json格式的歌曲信息(MusicJsonCallbacksinger_track({"code":0,"data":{"list":[{"Flisten_count1":......]})),如果只是单独想获取歌曲信息,可以直接拼接链接请求和解析返回的json格式的数据。这里不采用直接解析数据格式的方法,我采用的是Python Selenium方式,每获取和解析完一页的单曲信息,点击 ">" 跳转到下一页继续解析,直至解析并记录所有的单曲信息。最后请求每个单曲的链接,获取详细的单曲信息。
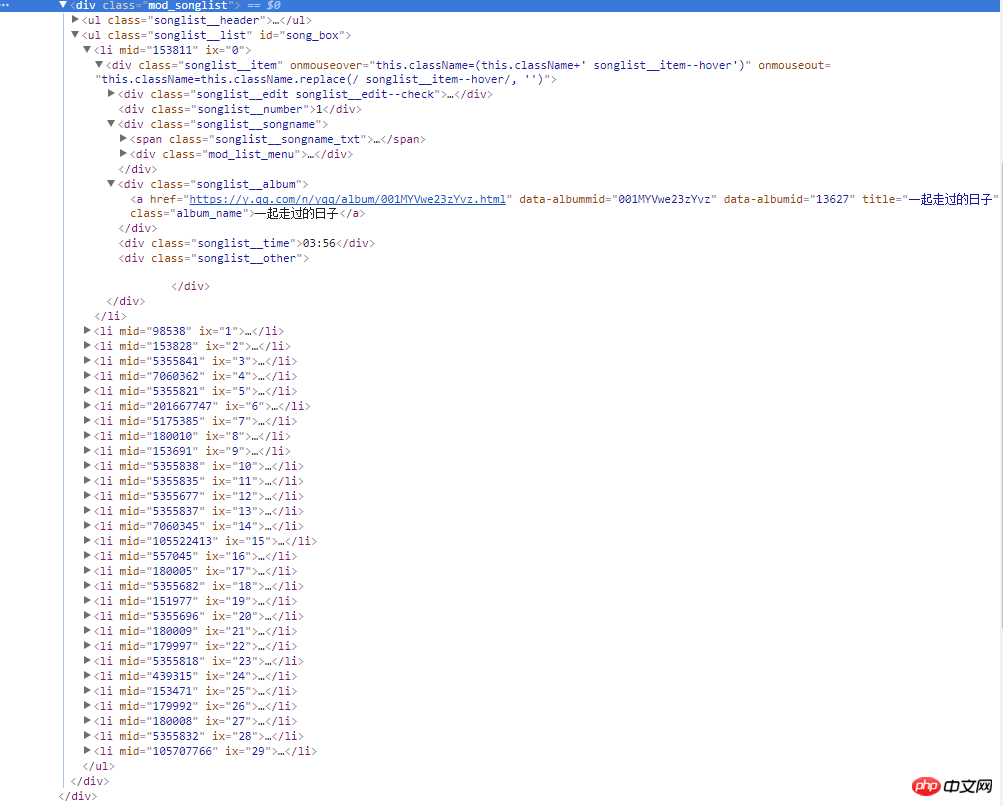
右边的截图是网页的源码,所有歌曲信息都在类名为mod_songlist的div浮层里面,类名为songlist_list的无序列表ul下,每个子元素li展示一个单曲,类名为songlist__album下的a标签,包含单曲的链接,名称和时长等。
3.编写代码
1)下载网页内容,这里使用Python 的Urllib标准库,自己封装了一个download方法:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
|
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









