






相关链接
- 课程链接:GitHub - InternLM/Tutorial: LLM Tutorial
- InternLM2:2403.17297.pdf
- 课程视频:书生·浦语大模型全链路开源体系_哔哩哔哩_bilibili
课程一笔记
首先是介绍了InternLM2模型是什么。这里需要关注不同后缀的模型的区别。
- InternLM2-Base:这个名字应该是一个基座模型,效果应该是只会补全,相当于是在做完形填空。
- InternLM2:应该是在Base模型的基础上进行了增量训练,赋予了大模型各方面的能力。但是我在用的时候确实发现了一些不同,比如和他对话的时候他似乎不能理解什么是疑问句。
- InternLM2-Chat:这个可能是做过指令跟随微调了,有对话的能力。

大模型本质上是在做语言建模这件事情,给定context,预言接下来的token。因此训练的数据很重要。很多的idea其实不难想,但是如何得到相关的数据是一个很大的问题。

注意一下什么是代码解释器,代码解释器应该是lagent部分的内容。到时候需要关注一下如何搭建。
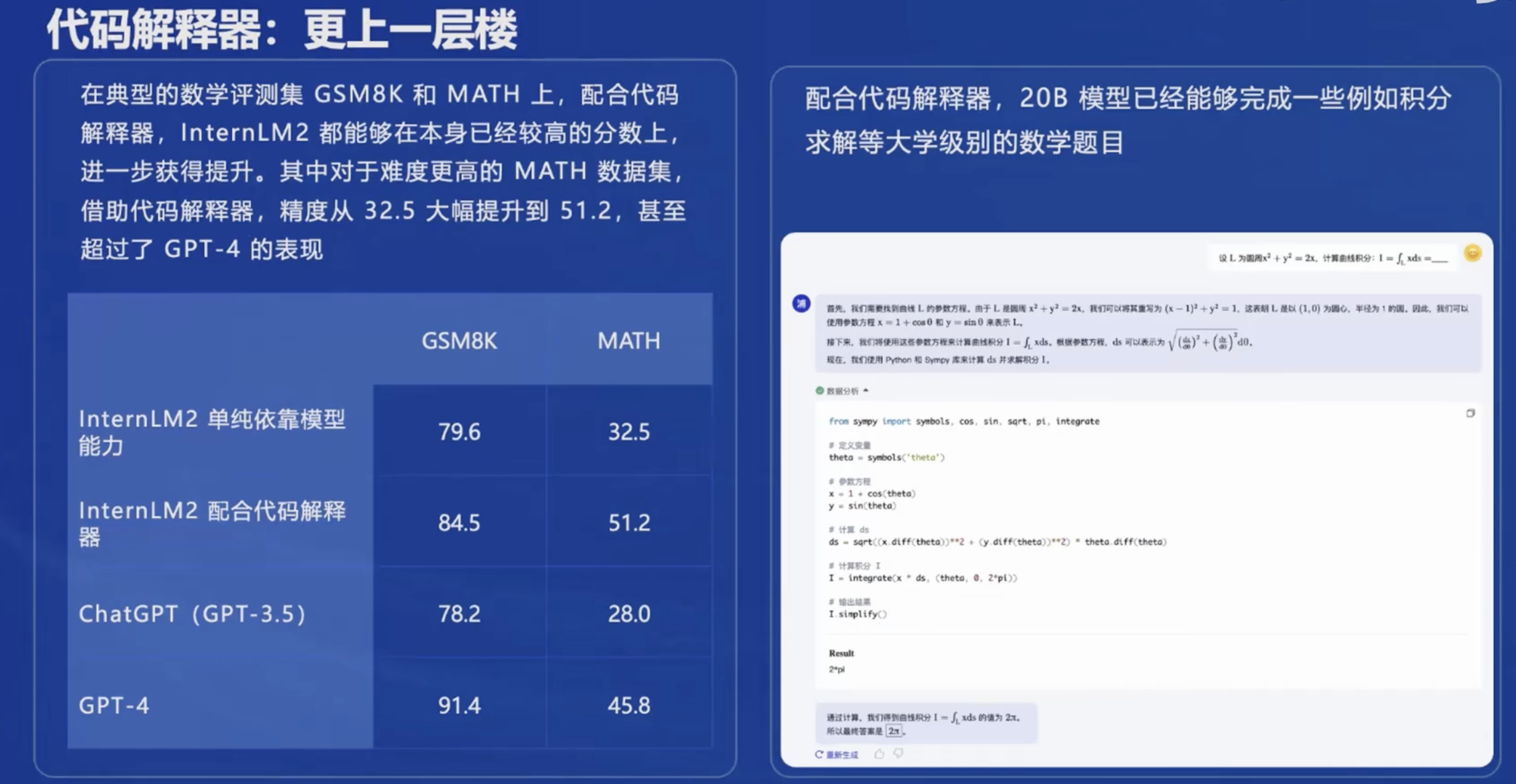
应用到部署的过程如下,注意对我而言需要重点关注模型的微调、量化部署以及智能体三方面。
在接下来的课程中需要关注构建智能体时如何调用外部的API或者工具,大模型怎么知道什么时候该调用API。
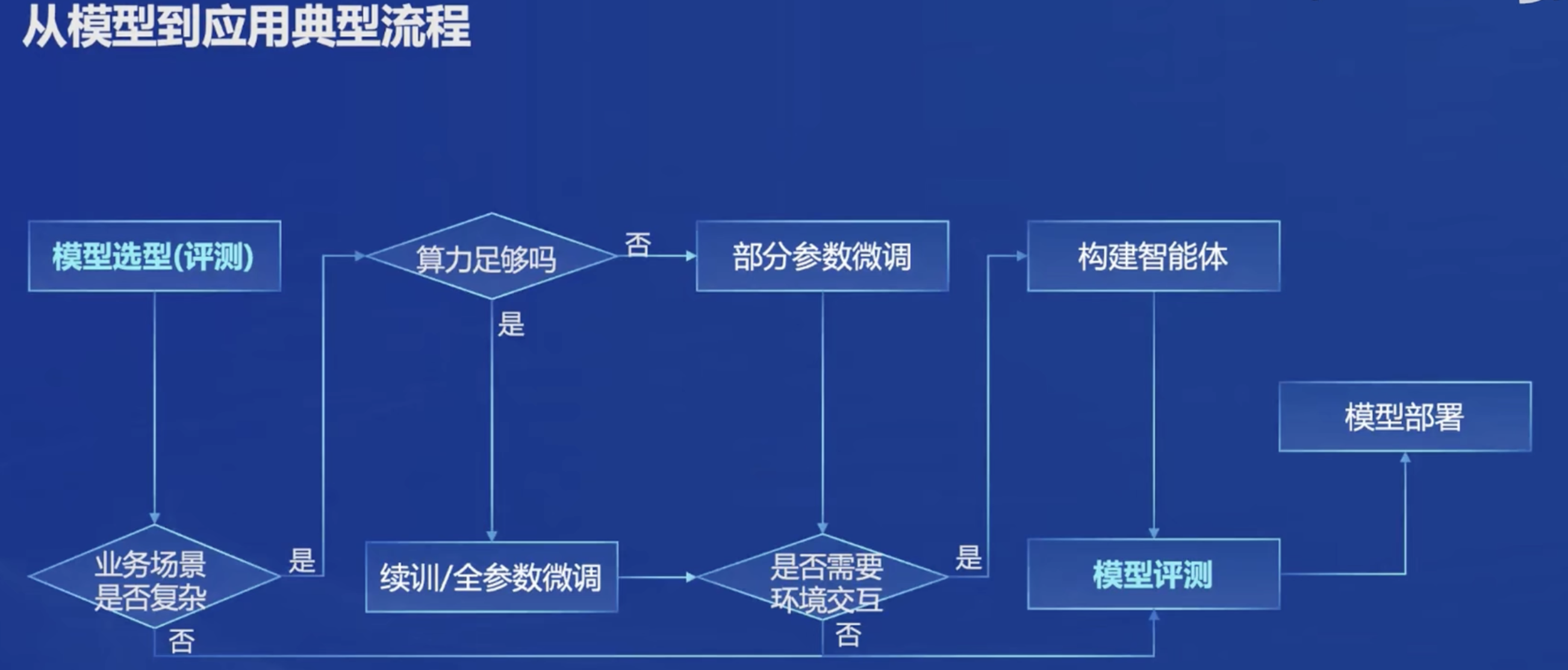
InternLM2是全链条开源的,这给了我一个很好的学习机会。

对于预训练来说,这个步骤我应该是不需要接触了,因为肯定都是从别人预训练好的模型基座上进行开发。

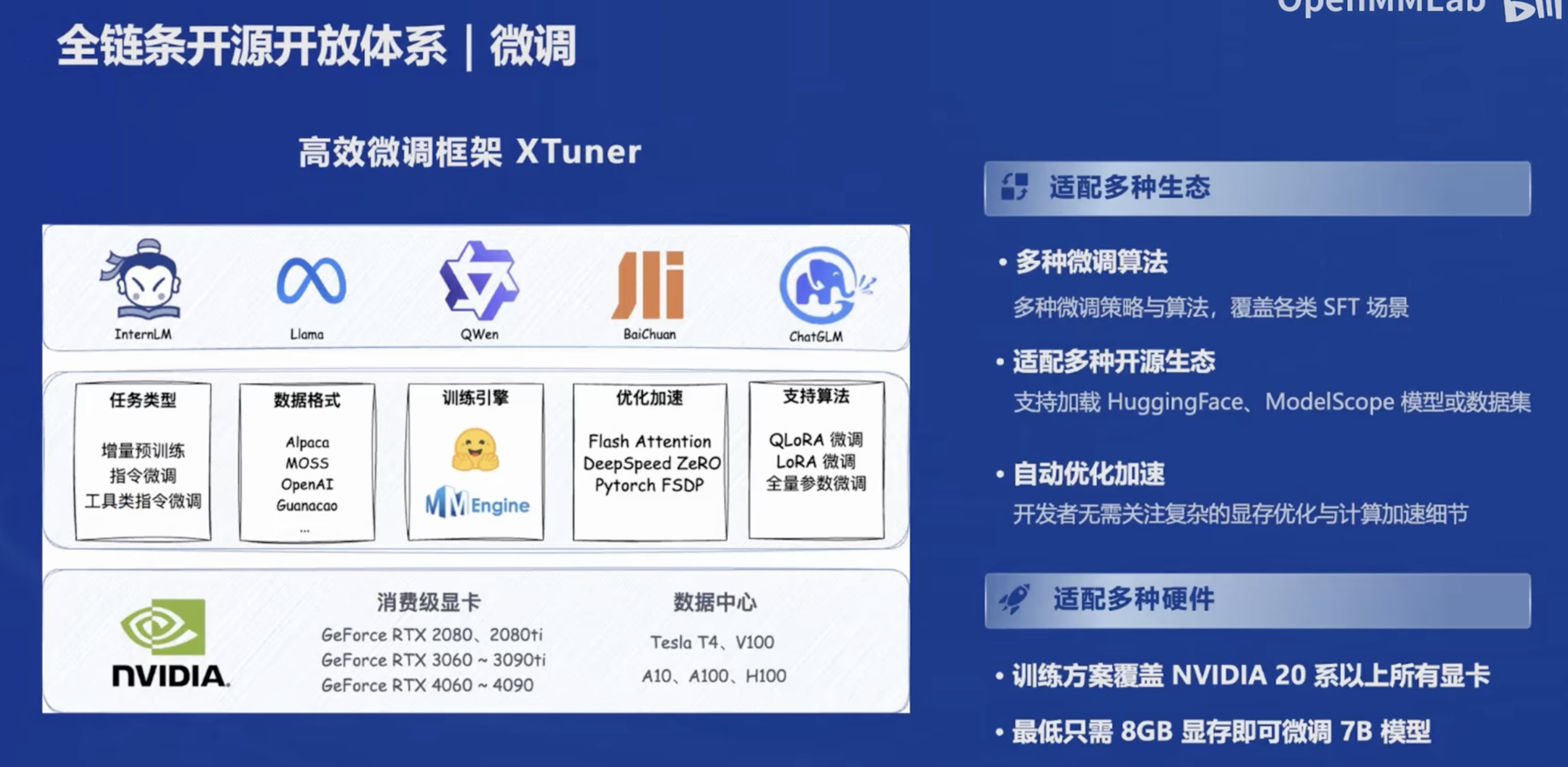
微调是使用的Xtuner,号称8G调7B!!!!!到时候一定要体验一下。而且还号称方便配置。
- 增量续训:给模型注入新知识
- 有监督微调:让模型学会对话

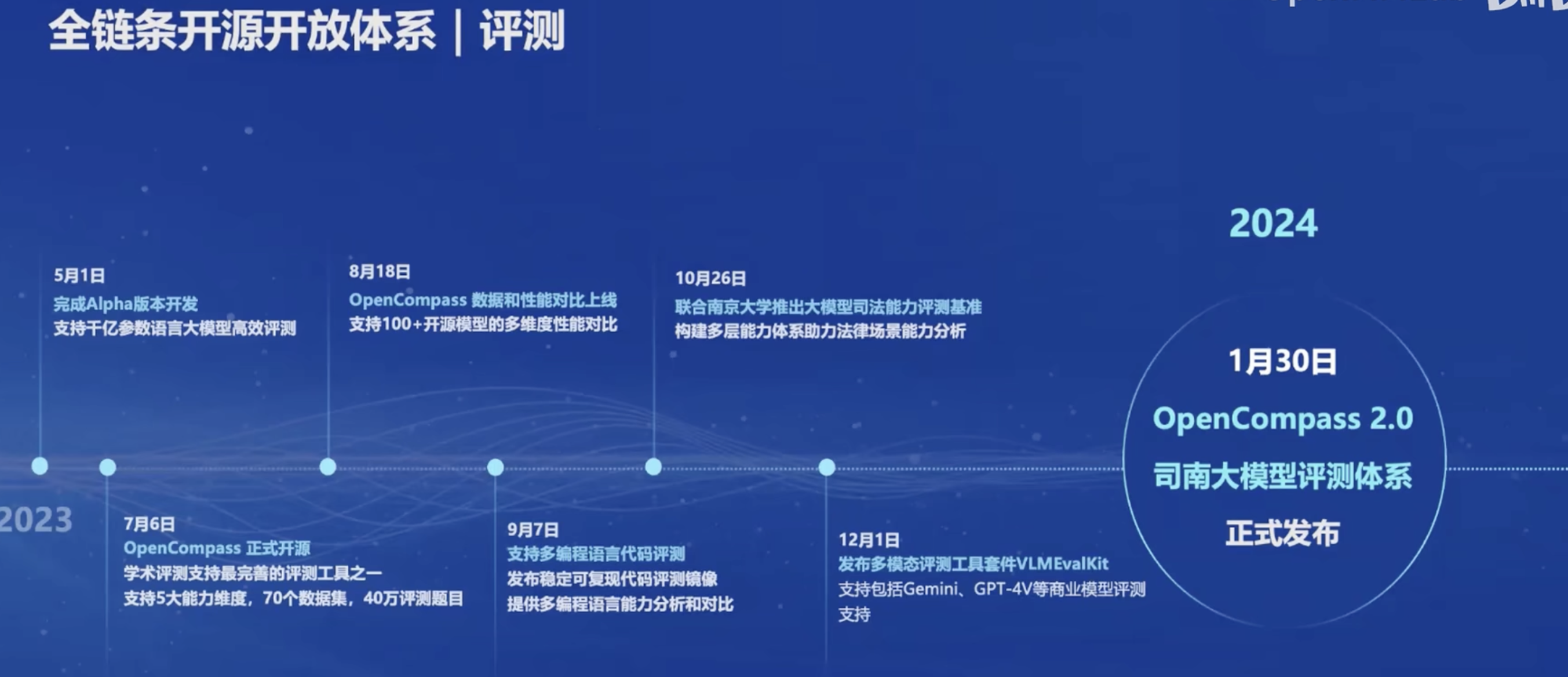
对于开源的评测方案,说是开源的OpenCompass。这个到时候体验一下,但是和我的目标关系不大。
开源的部署方案是LMDeploy,我已经尝试过了,其提供的4bit量化功能,以及加速推理的方案真的很nice。

对于智能体框架Lagent,应该也会很有用。


InternLM2阅读报告
这里记录一下自己在阅读InternLM2报告时的重点和疑问,等结营时看看自己能不能简单理解。
重点
- 大模型训练有三个主要阶段:预培训、监督微调 (SFT) 和基于人类反馈的强化学习 (RLHF)
- 预训练时,数据的质量很重要,之前的工作没怎么说准备预训练的数据,但是InternLM2介绍了。
- InternLM2的创新点主要集中在预训练阶段以及独特的优化技巧。
疑问
- 什么是RAG?
- agent到底指的是什么?
- COOL RLFH有什么区别?
- ZeRO、PPO这些术语是什么。















 156
156











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









