









前言
之前看到大佬爬取维基百科获取春晚的信息,做了些数据分析,我也想跟着试一下,但是…
不过我居然在360百科上面发现了多年春晚的信息,便选择从360百科爬取。
站点分析
从网站可以看出,它的每个词条应该对应着唯一的一个html页面
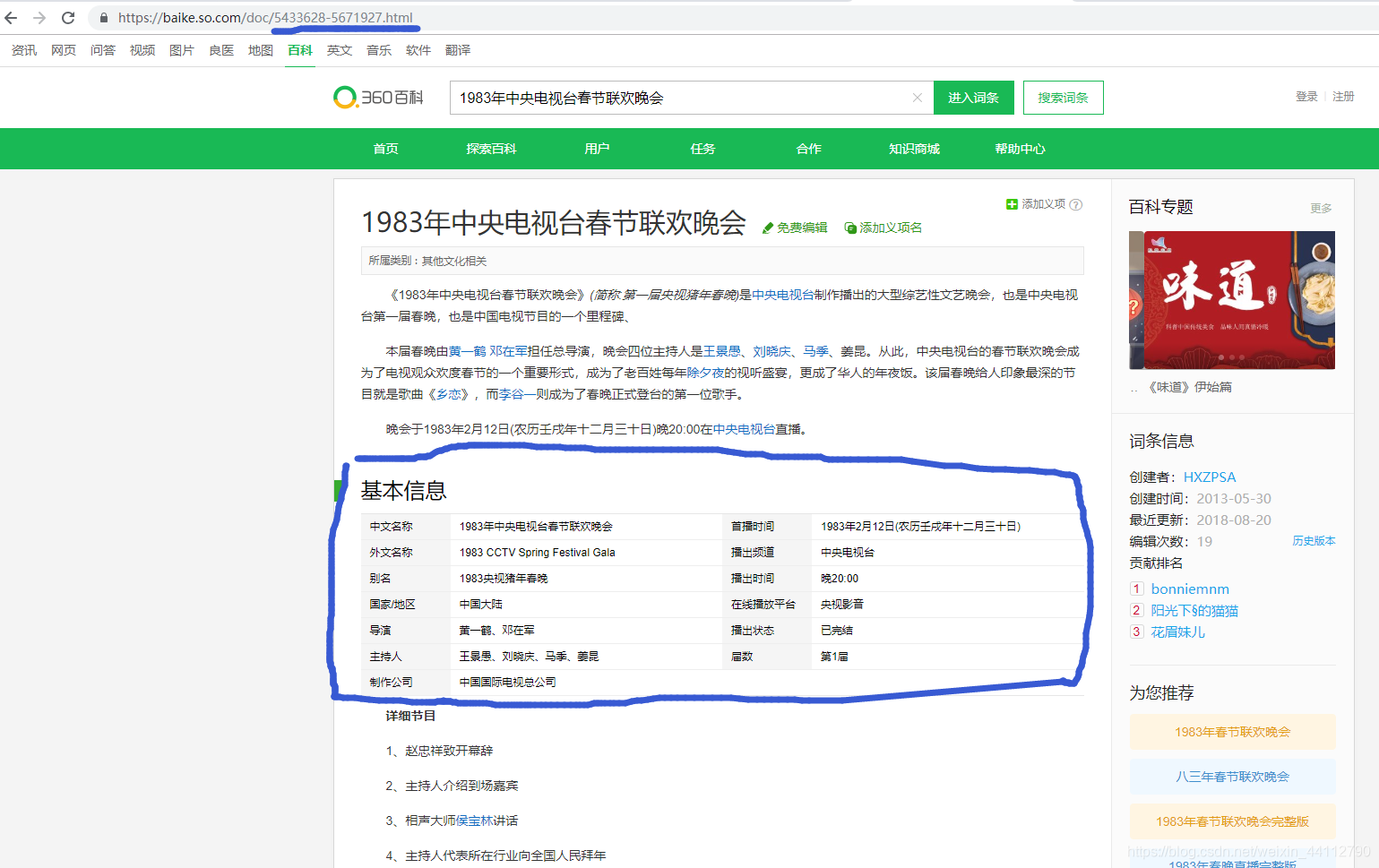
我们搜索的参数并没有直接通过get在地址栏显示出来,而是藏在了cookie当中,也就是我们可以通过修改cookie了打开不同年份的页面。
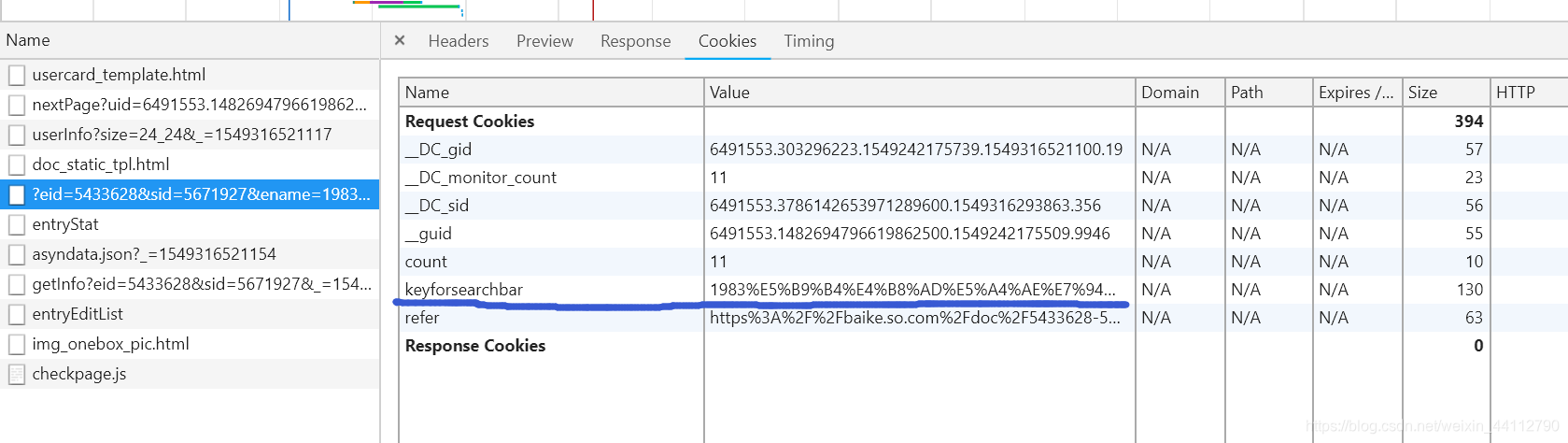
但是我图个简单没选择这种方式,而是选择直接在搜索框输入内容进行词条的切换。
数据获取
获取不同年份
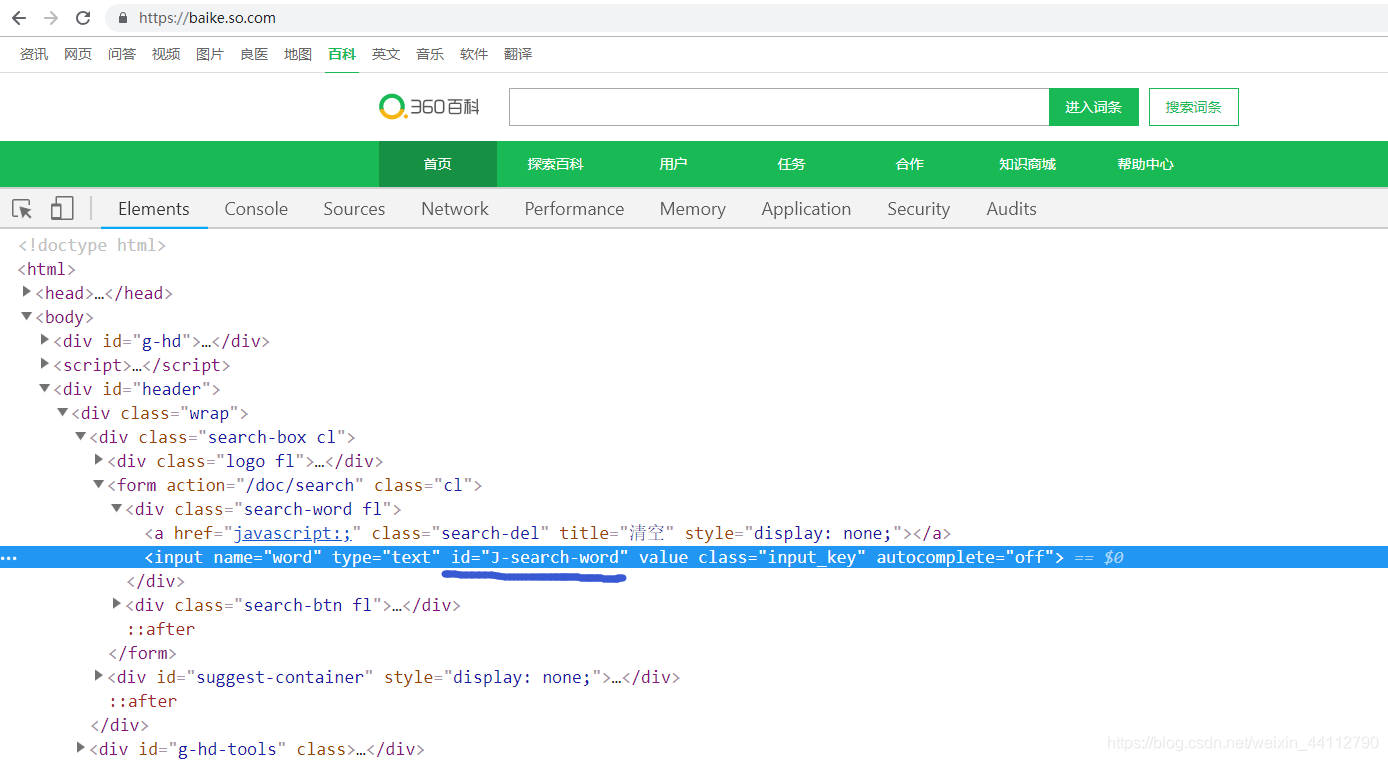
利用selenium根据这个id选中输入框,并输入相应内容
def get_url(year):
browser.get('https://baike.so.com/') #browser为全局属性browser= webdriver.Chrome()
input = wait.until( #wait为全局属性wait = WebDriverWait(browser, 10)
EC.presence_of_element_located((By.CSS_SELECTOR, '#J-search-word'))
)
input.send_keys(str(year)+KEYWORD) #KEYWORD = '年中央电视台春节联欢晚会',写在配置文件中
input.send_keys(Keys.ENTER)
return browser.current_url
通过这个方法就能获取指定年份的春晚信息了,修改KEYWORD还能获取其他词条指定年份的信息。
获取基本信息
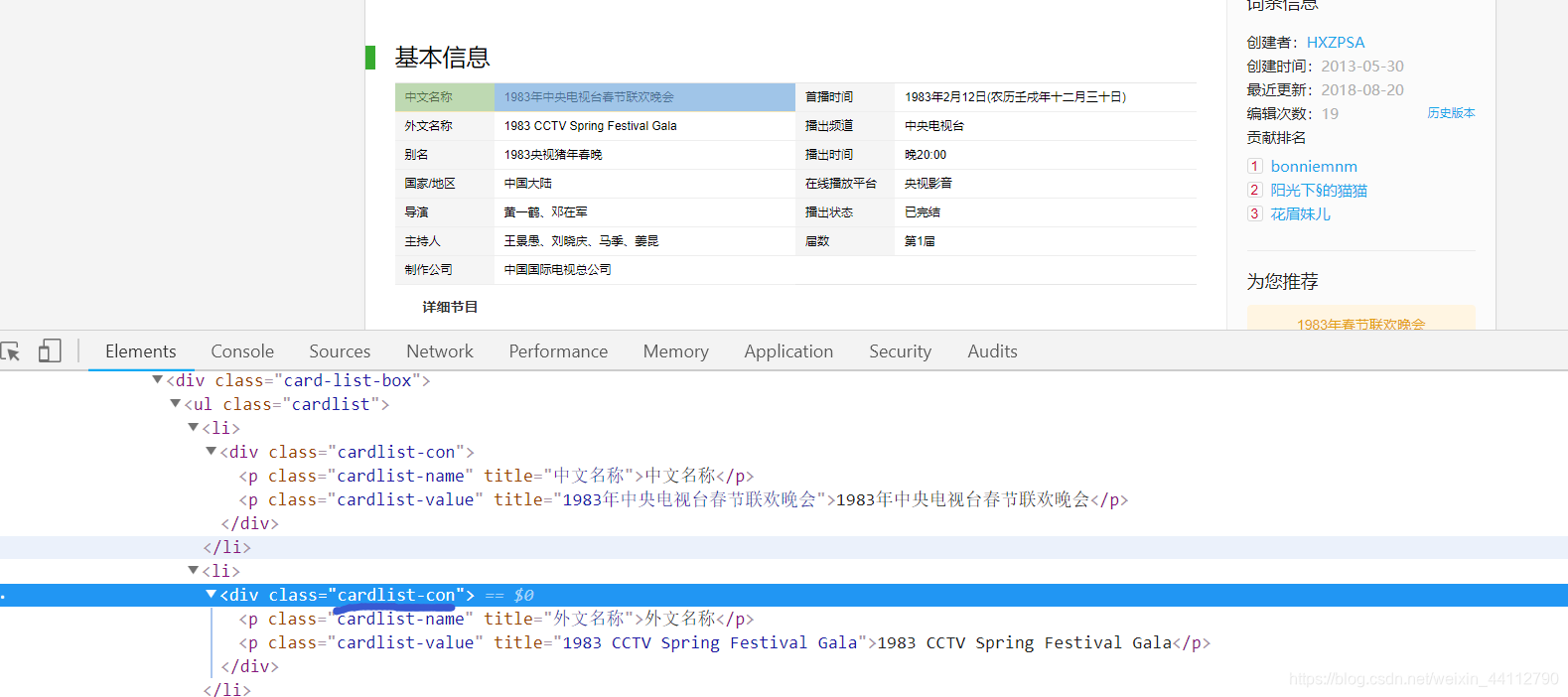
通过这个class获取一对对的基本信息用字典存了起来
def get_info(url):
browser.get(url)
html = browser.page_source
doc = pq(html)
items = doc.find('.cardlist-con').items()
dict = {}
for item in items:
dict[item.find('.cardlist-name').text()] = item.find('.cardlist-value').text()
整体运行
if __name__ == '__main__':
for year in range(1983,2020):
url = get_url(year)
print(url)
dict = get_info(url)
print(dict)
save_to_mongo('chunwan',dict)
最后通过循环整体运行起来,save_to_mongo是我自己封装的工具类,用来存到MongoDB
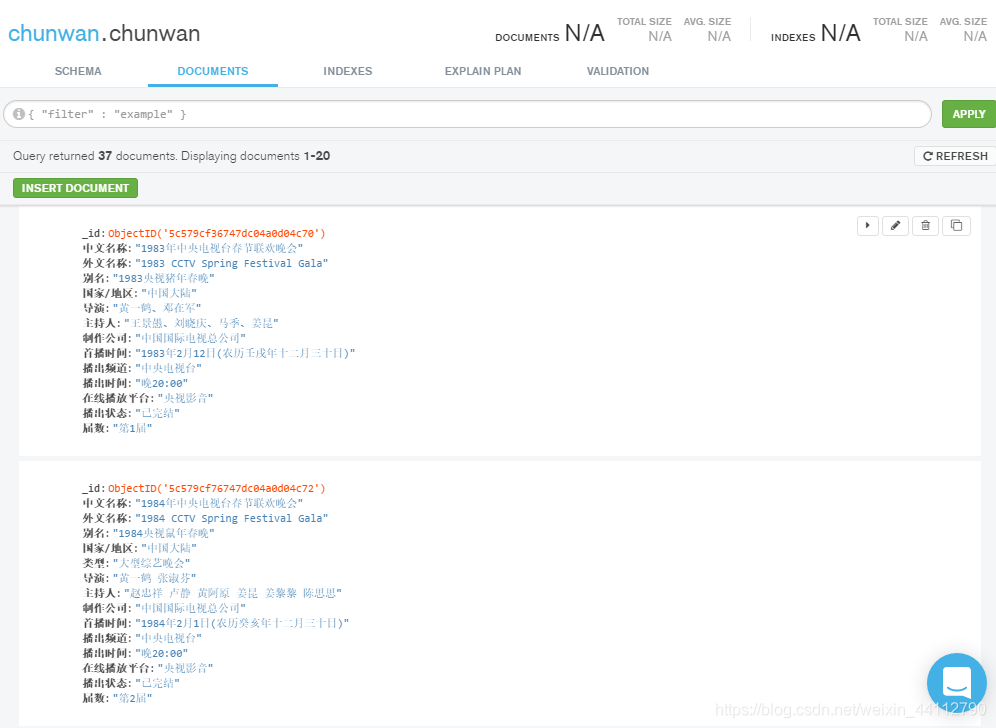
结果展示














 1738
1738











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









