







文章目录
简介
Spark基于内存运算的分布式计算引擎
解决海量数据计算问题
集群角色
Master : 常驻进程,守护进程。 管理worker,接收提交的任务,进行任务的分配调度。
Worker : 常驻进程,守护进程。 报活;管理自己节点上的executor
运行模式
Local模式
local:单线程
local[K]:自定义多线程
local[*]:自适应多线程
Standalone模式
资源调度,测试效率高于YARN,但只支持FIFO
Master+Slave
YARN模式
yarn-client希望立即看到app输出
yarn-cluster生产环境,稳定
Mesos模式
国内不常用
搭建Standalone集群
解压
tar -zxvf spark-2.1.3-bin-hadoop2.7.tgz -C /opt/modules
修改conf
进入conf目录
首先cp log4j.properties.template log4j.properties设置好log4j的配置文件
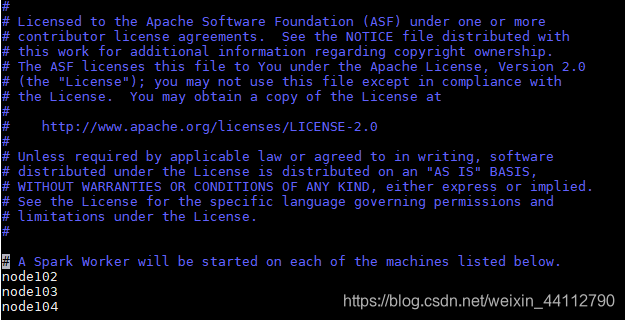
然后我这里采用Standalone模式,修改slaves
其次修改 spark-env.sh
cp spark-env.sh.template spark-env.sh
vim spark-env.sh
添加如下内容,修改为自己的ip
SPARK_MASTER_HOST=node102
SPARK_MASTER_PORT=7077

centos还需要在当中添加JAVA_HOME

最后再分发到其他结点
环境变量
先解决和hadoop过时脚本的冲突

## SPARK_HOME
export SPARK_HOME=/opt/modules/spark-2.1.3
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
修改并分发

运行
在spark目录下
./sbin/start-all.sh启动集群
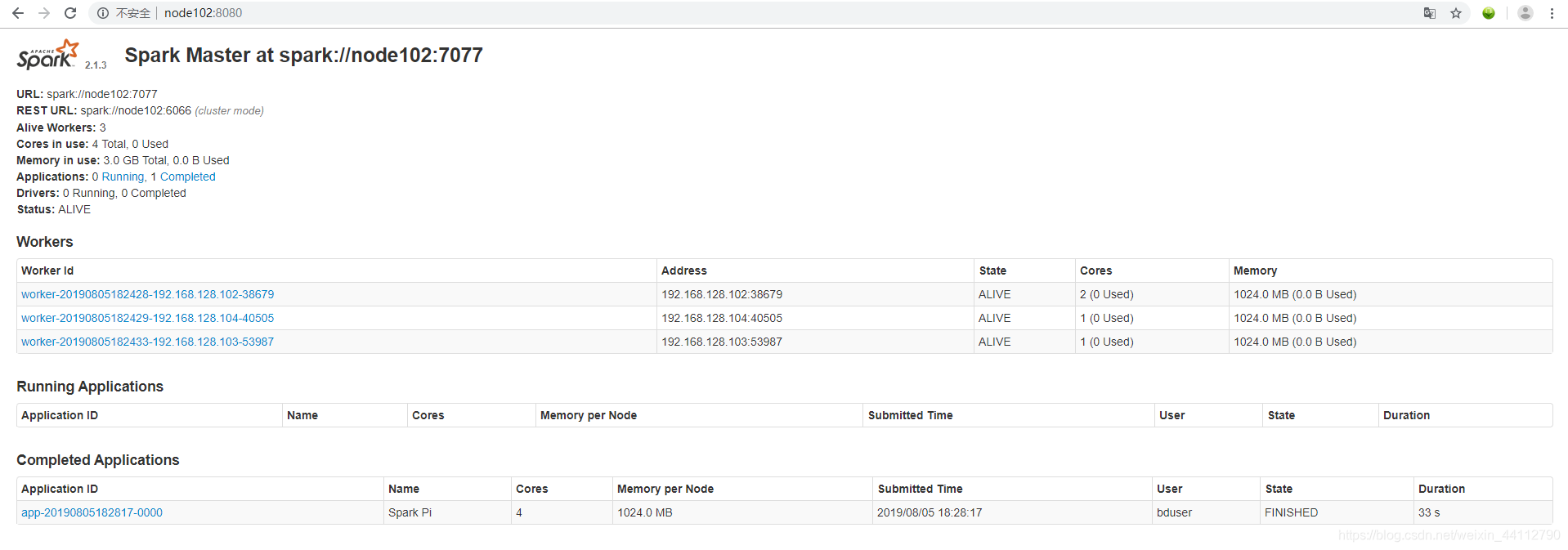
可以去webUI界面查看运行情况
./bin/spark-submit --class org.apache.spark.examples.SparkPi --master spark://node102:7077 ./examples/jars/spark-examples_2.11-2.1.3.jar 100计算PI
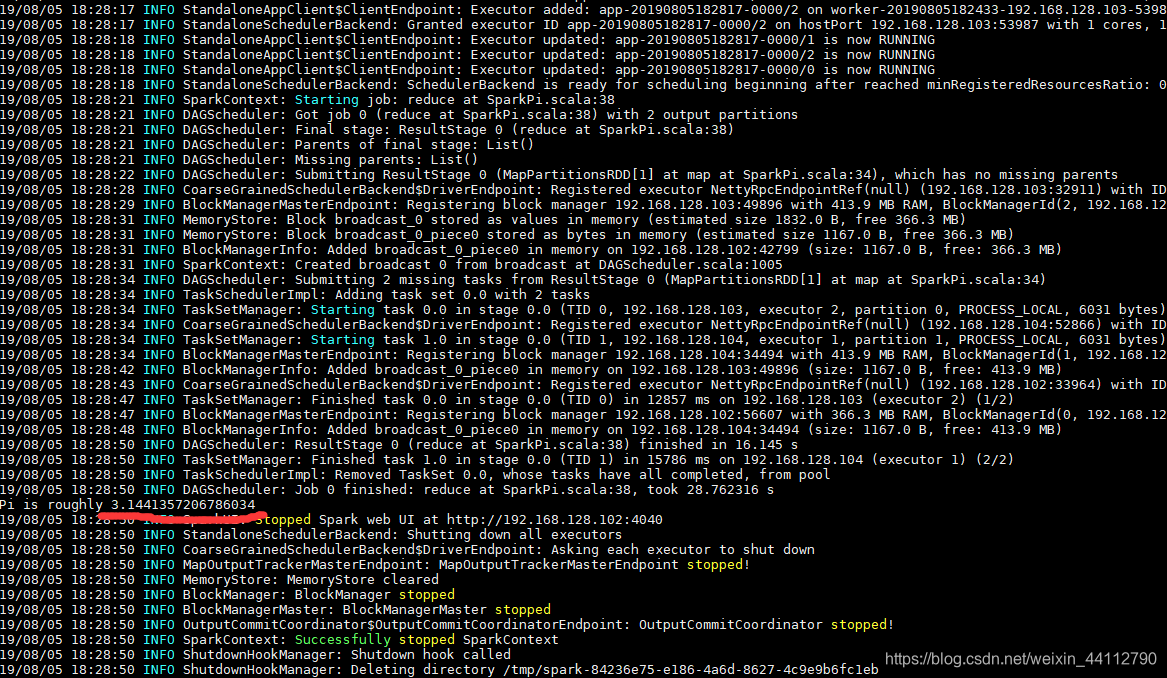
SHELL操作
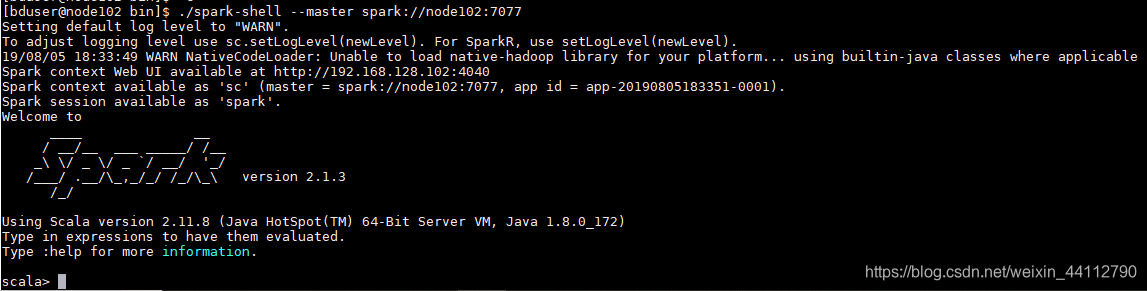
进入spark的bin目录
./spark-shell --master spark://node102:7077
我这里准备选取spark目录下的RELEASE演示一次wordcount

利用scala编写wordcount程序,我在bin目录下进的spark-shell,这里用的相对路径。
注意:spark-shell启动的目录是运行spark程序的目录
sc.textFile("../RELEASE").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).collect
运行可得到

搭建历史服务器
首先修改default

其次修改env
export SPARK_HISTORY_OPTS="-Dspark.history.ui.port=4000 -Dspark.history.retainedApplications=3 -Dspark.history.fs.logDirectory=hdfs://node102:8020/user/spark/hi story"
这里的4000是我自己选择的webUI访问端口

然后启动hdfs,并创建历史记录文件夹
hadoop fs -mkdir -p /user/spark/history
完成后依旧需要分发
最后进入sbin目录start-history-server.sh开启历史服务器
接着运行一下之前计算PI的任务,去webUI界面可以看到历史记录。
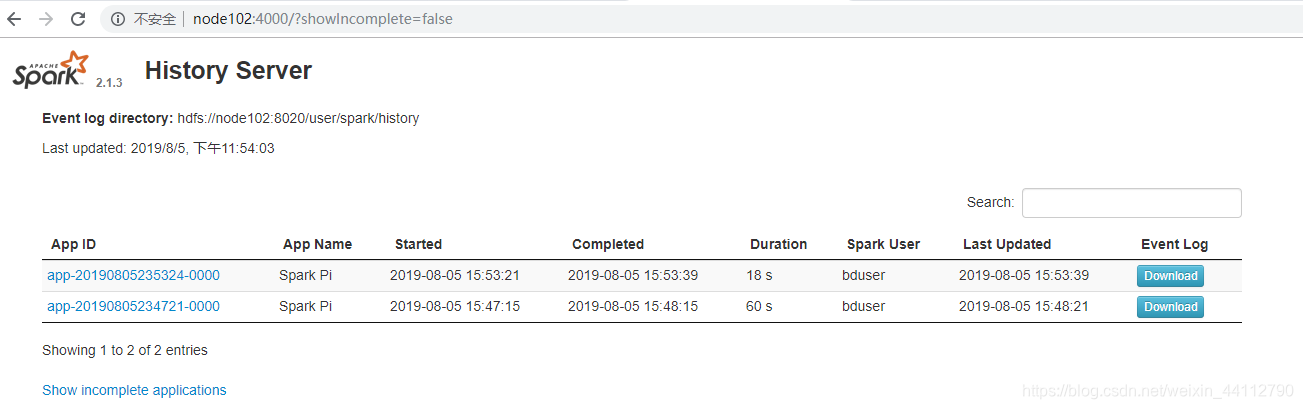
搭建高可用
需要关掉运行着的spark,并且注释掉之前的master
并且添加如下内容
export SPARK_DAEMON_JAVA_OPTS=" -Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=node102,node103,node104 -Dspark.deploy.zookeeper.dir=/spark"
依旧需要分发到其他节点
其次启动zookeeper
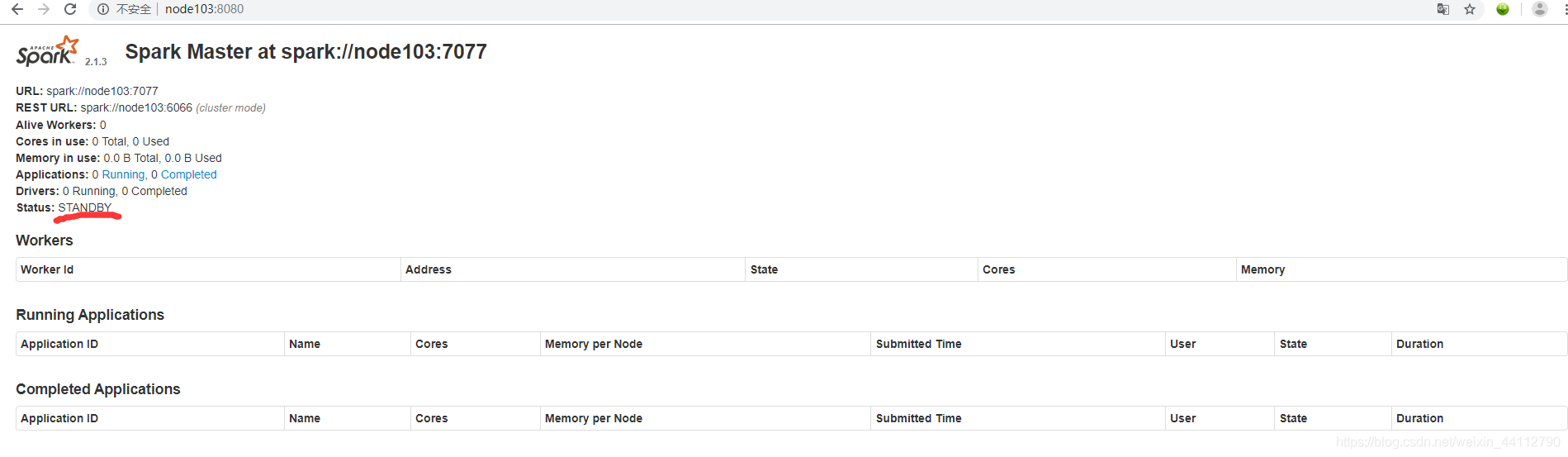
然后启动all,再去另一台机器单独启动一个Master,可以看到两个Master在运行
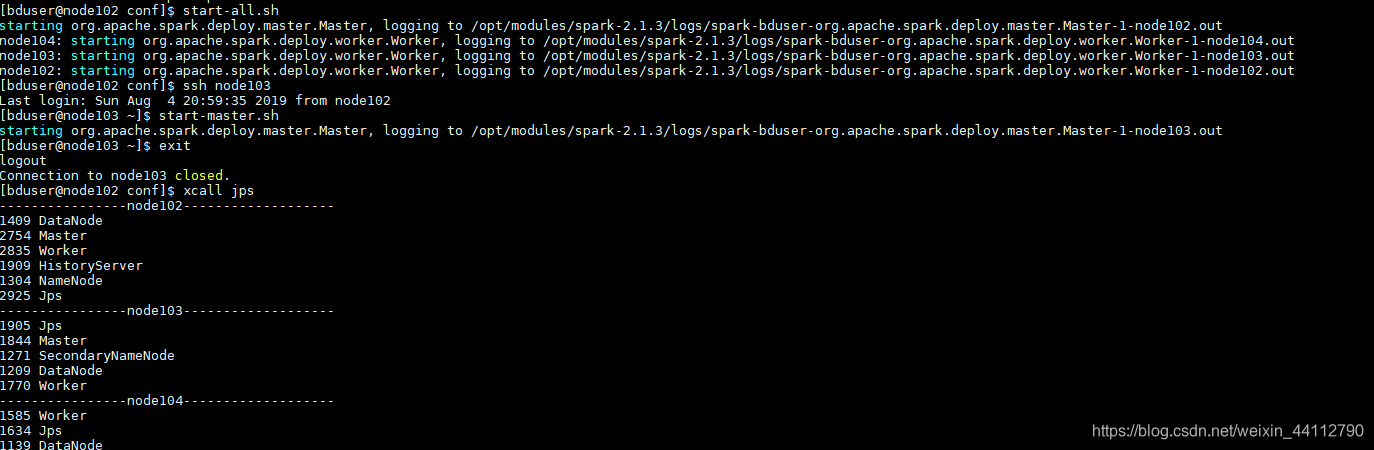
去webUI界面可以看到单独启动的node103的Master在待命状态。
YAEN模式运行
首先修改 hadoop 配置文件 yarn-site.xml,添加如下内容:
<!--是否启动一个线程检查每个任务正使用的物理内存量,如果任务超出分配值, 则直接将其杀掉,默认是 true -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<!--是否启动一个线程检查每个任务正使用的虚拟内存量,如果任务超出分配值, 则直接将其杀掉,默认是 true -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
然后在spark-env.sh添加如下内容
# YARN模式
HADOOP_CONF_DIR=/opt/modules/hadoop-2.7.6/etc/hadoop
YARN_CONF_DIR=/opt/modules/hadoop-2.7.6/etc/hadoop
分发之前修改的文件
之后启动HDFS和YARN即可运行程序
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode client \
./examples/jars/spark-examples_2.11-2.1.3.jar \
100
可以看到计算结果,也能看到确实是YARN执行的任务















 1568
1568











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









