







搞清楚自己用的是分类还是回归!。
搞回归的用的是scm.SVR
方法参数
sklearn.svm.SVC(C=1.0, kernel='rbf', degree=3, gamma='auto', coef0=0.0, shrinking=True, probability=False, tol=0.001, cache_size=200, class_weight=None, verbose=False, max_iter=-1, decision_function_shape=None,random_state=None)
-
C:float类型,默认值是1.0
参数表明算法要训练数据点需要作出多少调整适应,C小,SVM对数据点调整少,多半取平均,仅用少量的数据点和可用变量,C值增大,会使学习过程遵循大部分的可用训练数据点并牵涉较多变量。C值过大,有过拟合问题,C值过小,预测粗糙,不准确。 -
kernel :str类型,默认是’rbf’
核函数,可选参数有
‘linear’:线性核函数(常用)
‘poly’:多项式核函数
‘rbf’:径像核函数/高斯核(常用)
‘sigmoid’:sigmoid核函数
‘precomputed’:核矩阵
precomputed表示自己提前计算好核函数矩阵,这时候算法内部就不再用核函数去计算核矩阵,而是直接用你给的核矩阵。 -
degree :int 类型,默认为3
多项式poly函数的阶数n,选择其他核函数时会被忽略。 -
gamma :float 类型,默认为auto
核函数系数,只对‘rbf’,‘poly’,‘sigmod’有效。
如果gamma为auto,代表其值为样本特征数的倒数,即1/n_features. -
coef0 :float 类型,默认为0.0
核函数的常数项,对于‘poly’和 ‘sigmoid’有用,代表其中的参数c -
probability :bool类型,默认为False
是否采用概率估计,需要在训练fit()模型时加上这个参数,之后才能用相关的方法:predict_proba和predict_log_proba -
shrinking :bool类型,默认为True
是否采用shrinking heuristic()启发式收缩方式 -
tol :float类型,默认为1e-3
svm停止训练的误差值大小 -
cache_size :float类型,默认为200(MB)
指定训练所需要的内存,以MB为单位 -
class_weight :字典类型或’balance’字符串,默认为None
类别的权重,字典形式传递。设置第几类的参数C为weight*C(C-SVC中的C) -
verbose :bool类型,默认为False
是否启用详细输出。 此设置利用libsvm中的每个进程运行时设置,如果启用,可能无法在多线程上下文中正常工作。一般情况都设为False,不用管它。 -
max_iter :int类型, 默认为-1
最大迭代次数。-1为无限制。 -
decision_function_shape :str类型,默认为’ovr’
ovo’, ‘ovr’, default=’ovr’,是否将形状(n_samples,n_classes)的one-rest-rest(‘ovr’)决策函数作为所有其他分类器返回,或者返回具有形状的libsvm的原始one-vs-one(‘ovo’)决策函数(n_samples) ,n_classes *(n_classes - 1)/ 2)。
通俗解释:ovr即为one v rest 一个类别分别与其他类别进行划分,ovo为one v one,类别两两之间划分,用二分类的方法模拟多分类的结果 -
random_state :int类型,默认为None
伪随机数发生器的种子,在混洗数据时用于概率估计。
相关方法和属性
-
fit() 方法:用于训练SVM,具体参数已经在定义SVC对象的时候给出了,这时候只需要给出数据集X和X对应的标签y即可。
-
predict() 方法: 基于以上的训练,对预测样本T进行类别预测,因此只需要接收一个测试集T,该函数返回一个数组表示个测试样本的类别。
-
属性
svc.n_support_:各类各有多少个支持向量
svc.support_:各类的支持向量在训练样本中的索引
svc.support_vectors_:各类所有的支持向量
参数调整
1,一般推荐在做训练之前对数据进行归一化,当然测试集的数据也要做归一化
2,在特征数非常多的情况下,或者样本数远小于特征数的时候,使用线性核,效果就很好了,并且只需要选择惩罚系数C即可
3,在选择核函数的时候,如果线性拟合效果不好,一般推荐使用默认的高斯核(rbf),这时候我们主要对惩罚系数C和核函数参数 gamma 进行调参,经过多轮的交叉验证选择合适的惩罚系数C和核函数参数gamma。
4,理论上高斯核不会比线性核差,但是这个理论就建立在要花费更多的时间上调参上,所以实际上能用线性核解决的问题我们尽量使用线性核函数
对模型性能影响较大的超参数:“kernel”,“gamma”,“C”
kernel
 其中线性核函数适用于特征量较多的情况(> 1000)数据在高维空间中更可能是线性可分的
其中线性核函数适用于特征量较多的情况(> 1000)数据在高维空间中更可能是线性可分的
gamma
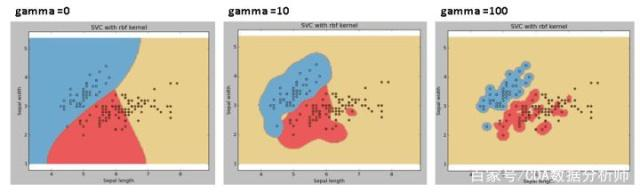
‘rbf’,'poly’和’sigmoid’的内核系数。伽马值越高,则会根据训练数据集进行精确拟合,也就是泛化误差从而导致过拟合问题。
gamma越大,支持向量越多,gamma值越小,支持向量越少。gamma越小,模型的泛化性变好,但过小,模型实际上会退化为线性模型;gamma越大,理论上SVM可以拟合任何非线性数据。
下图为gamma由低到高的图像
C
误差项的惩罚参数C,C越大,分类错误惩罚越严重,越容易过拟合,C越小越容易欠拟合。它还控制了平滑决策边界与正确分类训练点之间的权衡。
为维持模型在过拟合和欠拟合之间的平衡,往往最佳的参数范围是C比较大,gamma比较小;或者C比较小,gamma比较大。也就是说当模型欠拟合时,我们需要增大C或者增大gamma,不能同时增加,调节后如果模型过拟合,我们又很难判断是C过大了,还是gamma过大了;同理,模型欠拟合的时候,我们需要减小C或者减小gamma。
下图为C从低到高的图像

过拟合与欠拟合
如果训练集的精度就不高,模型欠拟合。那么需要增加数据特征维度、样本总数和模型复杂度。
如果训练集精度很高,但是验证集精度很低,模型过拟合。那么需要压缩数据维度,降低模型复杂度。
正常来说测试集上的准确率都会比训练集要低
预处理 - 特征值归一化
1,避免训练得到的模型权重过小,引起数值计算不稳定;
2,使参数优化时能以较快的速度收敛.
代码:x为需要进行归一化的一行/列特征值
from sklearn import preprocessing
x = preprocessing.MinMaxScaler().fit_transform(x)
eg:经典烂尾花(数据集下载)
不进行处理 VS 进行归一化处理
#-*-coding:GBK -*-
from sklearn import svm
import numpy as np
from sklearn import model_selection
from sklearn.model_selection import GridSearchCV
from sklearn.model_selection import train_test_split
from sklearn import preprocessing
def init(s):
it = {b'Iris-setosa': 0, b'Iris-versicolor': 1, b'Iris-virginica': 2}
return it[s]
def SVM():
data = np.loadtxt('iris.data', dtype=float, delimiter=',', converters={4: init})
x,y = np.split(data,(4,),axis = 1)
clf = svm.SVC()
clf.fit(x,y.ravel())
y_hat = clf.predict(x)
k = 0
for i in range (len(y_hat)):
if y_hat[i] == y[i]:
k+=1
print(float(k)/float(len(y_hat)))
for i in range(x.shape[1]):
x[:,[i]] = preprocessing.MinMaxScaler().fit_transform(x[:,[i]])
clf = svm.SVC()
clf.fit(x,y.ravel())
y_hat = clf.predict(x)
k = 0
for i in range (len(y_hat)):
if y_hat[i] == y[i]:
k+=1
print(float(k)/float(len(y_hat)))
if __name__ == '__main__':
SVM()
# 0.9733333333333334
# 0.98
Sklearn-GridSearchCV网格搜索
官方文档
GridSearchCV,枚举所有给出的参数值,最终给出最优化的结果和参数,是一种非常暴力的方法(我认为)适合于小数据集,数据量比较大的时候可以使用一个快速调优的方法——坐标下降。
注:C和gamma的有效范围是:1e-8 ~ 1e8,正常情况下,我们都会先设置C和gamma的值在0.1~10之间,然后在根据模型的表现,每次乘以0.1或者10作为一个步长,当确定大致范围后,再细化搜索区间。
eg:经典阑尾花
#-*-coding:GBK -*-
from sklearn import svm
import numpy as np
from sklearn import model_selection
from sklearn.model_selection import GridSearchCV
from sklearn.model_selection import train_test_split
def init(s):
it = {b'Iris-setosa': 0, b'Iris-versicolor': 1, b'Iris-virginica': 2}
return it[s]
def SVM():
data = np.loadtxt('iris.data', dtype=float, delimiter=',', converters={4: init})
x,y = np.split(data,(4,),axis = 1)
grid = GridSearchCV(svm.SVC(), param_grid={'C': [0.1, 1, 10], 'kernel':('linear', 'rbf'),'gamma': [1, 0.1, 0.01]}, cv=4)
grid.fit(x, y.ravel())
print("The best parameters are %s with a score of %0.2f"% (grid.best_params_, grid.best_score_))
if __name__ == '__main__':
SVM()
# The best parameters are {'C': 1, 'gamma': 1, 'kernel': 'linear'} with a score of 0.98















 452
452











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









