






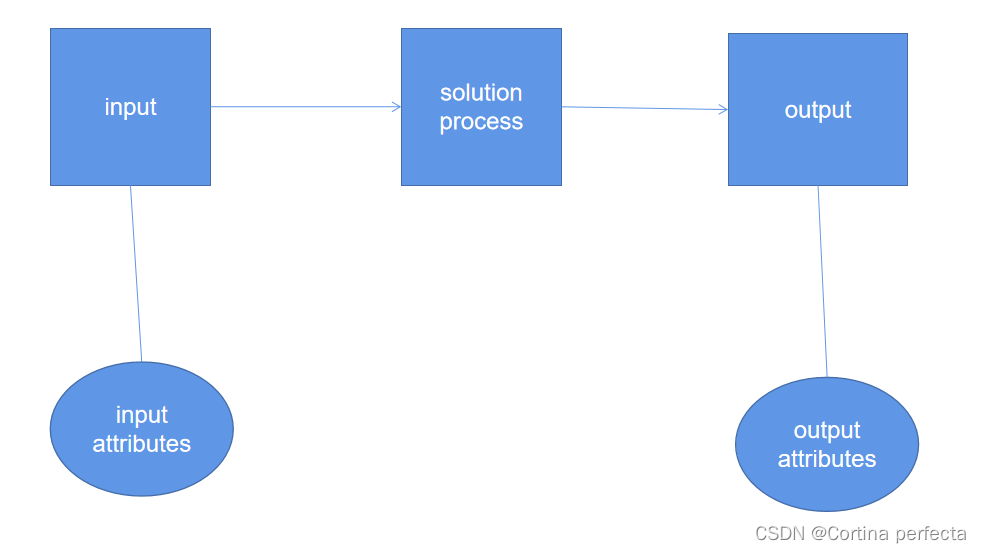
我认为算法是一个求解的过程,即表示为一个输入,一个输出,一个求解过程,而每个输入和输出都有其各自的属性,画成图就是这样,这个图和E-R图差不多。
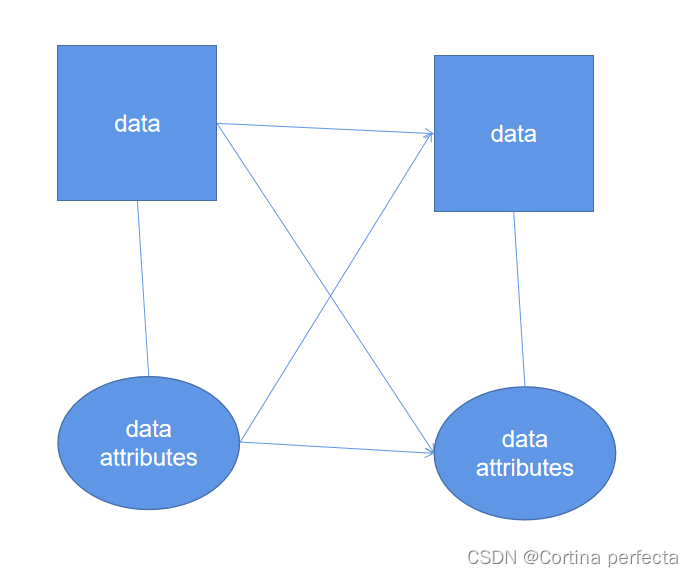
而数据,拥有者自己的性质,既可以作为输入,也可以作为输出。
数据和数据之间,数据的属性间都具有各自的联系,而这些联系大多数只能被表示成隐函数。
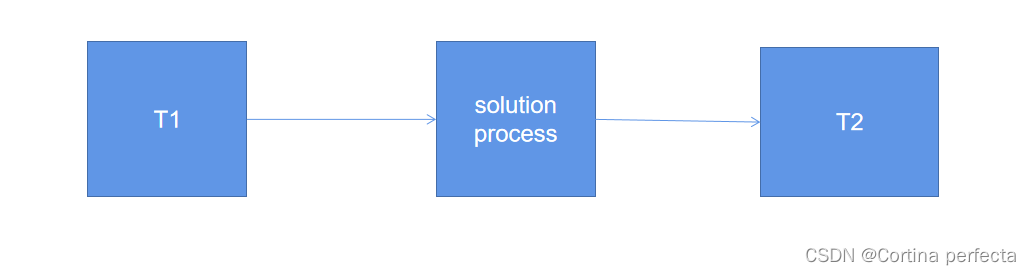
但在这里,一个困扰了我很久的问题诞生了,如果将存在一个单维的时间序列T,我将数据分成T1和T2,其中T1作为input,T2作为output,使用RNN(循环神经网络)获得了一个模型,那么我再次输入T2,得到了一个新的T3,可否理解为已经完成了拟合,T3就是我想要的结果呢?
这个问题我想了很久,我之前认为是,看似有理论推导但是我却不确定,这也就是为什么我写了这篇综述。
考虑data的属性也是学习机器学习的一个重要过程,这是我认为的,在某些理想状态下,一个算法的聚类精度会被放大,最显而易见的就是基于划分的聚类算法(kmeans,kmedoids),还有基于密度的算法(density-based),这两个算法也是下一章会提到的部分。
在这里,可以用一张图说明:

这是最为经典的螺旋图,如果是采用kmeans聚类,那么它将会被左右分成两半,这说明DBSCAN在处理这种类型的数据会有独到之处,但是“这种类型”包括什么数据,即能不能用一个公式来描述这些数据的属性具有的共同特征,或者直接用这个算法作为评判标准,很难说,但是我觉得如果用后一种作为评判,那和神经网络的拟合又接近了。
文末,贴上代码,sklearn等科学计算库确实帮了大忙
filename = r’’
input=data = np.loadtxt(filename)
scaler=MinMaxScaler(feature_range=(0,1))
scaler=scaler.fit(input)
input=scaler.transform(input)
n_components=1
pca=PCA(n_components).fit(input)
input_new = pca.transform(input)
X=input[:,1:]
t0 = time.time()
disMat = sch.distance.pdist(input_new,‘euclidean’)
Z=sch.linkage(disMat,method=‘single’)
plt.figure(num=1)
P=sch.dendrogram(Z)
plt.show()
cluster= sch.fcluster(Z, t=2, criterion=‘maxclust’)
t = time.time()-t0
plt.scatter(X[:, 0], X[:, 1], c=cluster)
plt.title(‘time : %f’%t)
plt.show()
cushu=[]
for i in range(0,len(cluster)):
for k in range(0,5):
if cluster[i]==k:
cushu.append(k-1)
count=0
for j in range(0,len(cluster)):
if cushu[j]==input[j,0]:
count=count+1
print('正确率: ',count/len(cluster))















 2579
2579











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









