







1. HDFS写策略
第一复本写本地, 第二复本写其他机架, 第三复本写其他机架的不同节点
目的: 尽可能地容灾, 不仅防止单台机器宕机, 也防止整个机架异常; 同时保证写的速度 (本地更快)
- The class is responsible for choosing the desired number of targets for placing block replicas.
- The replica placement strategy is that if the writer is on a datanode, the 1st replica is placed on the local machine, otherwise a random datanode.
- The 2nd replica is placed on a datanode that is on a different rack.
- The 3rd replica is placed on a datanode which is on a different node of the rack as the second replica.
1.1. 本地偏好配置
dfs.namenode.block-placement-policy.default.prefer-local-node
默认为true, 当存在本地put操作时, 优先选择本机, 最终结果是本机datanode存储使用率高
Controls how the default block placement policy places the first replica of a block. When true, it will prefer the node where the client is running. When false, it will prefer a node in the same rack as the client. Setting to false avoids situations where entire copies of large files end up on a single node, thus creating hotspots.
2. 磁盘卷组选择
配置项: dfs.datanode.fsdataset.volume.choosing.policy
- RoundRobinVolumeChoosingPolicy, choose volumes with the same storage type in round-robin order
- AvailableSpaceVolumeChoosingPolicy, A DN volume choosing policy which takes into account the amount of free space on each of the available volumes when considering where to assign a new replica allocation. By default this policy prefers assigning replicas to those volumes with more available free space, so as to over time balance the available space of all the volumes within a DN
2.1 Round-Robin策略
本质就是轮询
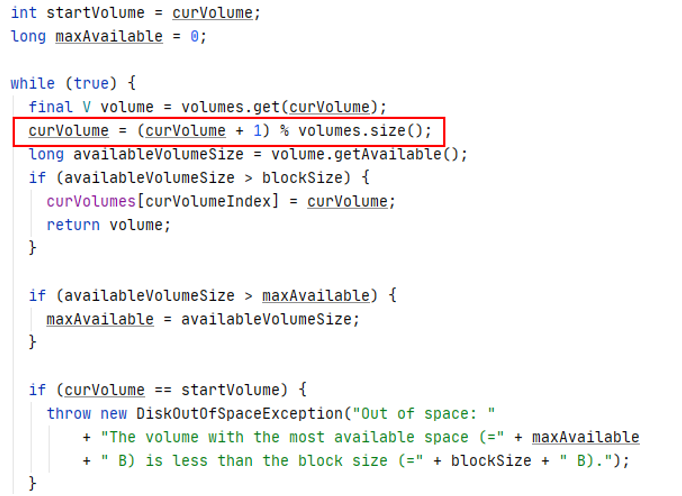
2.2. Available Space策略
- If none of the volumes with low free space have enough space for the replica, always try to choose a volume with a lot of free space
- 权重计算: (充裕磁盘数 * 0.75) / (充裕磁盘卷数 * 0.75 + 紧缺磁盘卷数 * 0.25), 通过随机数与权重比较, 从概率的角度选择磁盘
3. Balancer命令
# hdfs balancer --help
Usage: hdfs balancer
[-policy <policy>] the balancing policy: datanode or blockpool
[-threshold <threshold>] Percentage of disk capacity
[-exclude [-f <hosts-file> | <comma-separated list of hosts>]] Excludes the specified datanodes.
[-include [-f <hosts-file> | <comma-separated list of hosts>]] Includes only the specified datanodes.
[-source [-f <hosts-file> | <comma-separated list of hosts>]] Pick only the specified datanodes as source nodes.
[-idleiterations <idleiterations>] Number of consecutive idle iterations (-1 for Infinite) before exit.
[-runDuringUpgrade] Whether to run the balancer during an ongoing HDFS upgrade.This is usually not desired since it will not affect used space on over-utilized machines.
- -threshold, 磁盘使用率阀值, 范围区间[0, 100], 超过阀值的节点将向低于阀值的节点迁移数据 (遵循HDFS存储的容错规则)
- -exclude, 排除指定DataNode
- -include, 只针对指定DataNode
- -exclude和-include无法同时指定
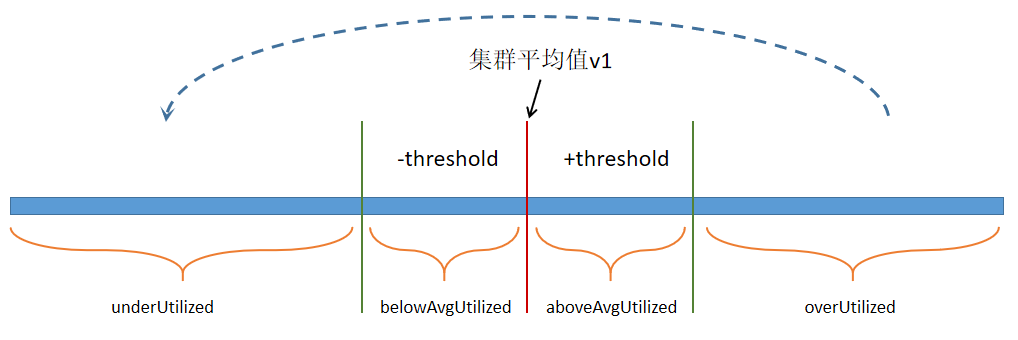
3.1. BALANCER原理
计算每个DataNode节点磁盘使用率, 并结合集群平均使用率v1, 以及配置项threshold, 将DataNode划分为四个等级
HDFS集群的平均使用率= sum(DFS Used) * 100 / sum(Capacity)
相关参数
- dfs.balancer.max-size-to-move, 最大迁移量, 默认10G
- dfs.balancer.moverThreads, mover线程数, 默认1000















 5280
5280











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









