







PAT 链表专题 (1)
今天写了两道题,讲道理 这两道题看上去 我都觉得非常简单 但是
事实告诉我 这两道题 我花了许多时间 而且还没做对
[这是第一题A1032 Sharing](https://pintia.cn/problem-sets/994805342720868352/problems/994805460652113920)
To store English words, one method is to use linked lists and store a word letter by letter. To save some space, we may let the words share the same sublist if they share the same suffix. For example, loading and being are stored as showed in Figure 1.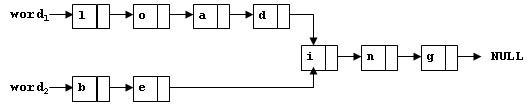
Figure 1
You are supposed to find the starting position of the common suffix (e.g. the position of i in Figure 1).
Input Specification:
Each input file contains one test case. For each case, the first line contains two addresses of nodes and a positive N (≤10^5), where the two addresses are the addresses of the first nodes of the two words, and N is the total number of nodes. The address of a node is a 5-digit positive integer, and NULL is represented by −1.
Then N lines follow, each describes a node in the format:
Address Data Next
whereAddress is the position of the node, Data is the letter contained by this node which is an English letter chosen from { a-z, A-Z }, and Next is the position of the next node.
Output Specification:
For each case, simply output the 5-digit starting position of the common suffix. If the two words have no common suffix, output -1 instead.
Sample Input 1:
11111 22222 9
67890 i 00002
00010 a 12345
00003 g -1
12345 D 67890
00002 n 00003
22222 B 23456
11111 L 00001
23456 e 67890
00001 o 00010
Sample Output 1:
67890
Sample Input 2:
00001 00002 4
00001 a 10001
10001 s -1
00002 a 10002
10002 t -1
Sample Output 2:
-1
题目大意:
告诉你 每个字母用节点来表示 连起来表示单词 然后有些单词后缀相同
所以 让你来找到那个相同后缀的开始的地址下标
题目 给了 两个单词开始的地址下标 给了多少个节点
然后每个节点都按照 address data next 的格式给你 。
我看完题目 过一会 我马上就想到了以下思路:
用个结构体数组 结构体里面有前驱下标1,以及前驱下标2
因为 最多有两个前驱下标 所以就设置两个 然后 把next==-1的节点标记下来 并且记录next==-1的节点的个数 如果个数为2 那么说明这两个单词没有交集,如果个数为1说明有交集 然后从最后一个开始循环,一直循环到前驱节点1存在,前驱节点2存在且不相等 一开始我是这样想的 然后也没想深入 就开始写了 写了之后 开始测试 结果 里面发现样例都没过去 然后开始了漫长的debug 后面发现 我中途
Node 一个新的节点 =node[xxxx]; 然后我改数据的时候 在数组那块改了 我后面用的时候理所应当的认为这个新的节点也应该改了 。然而这个非常低级的错误导致我debug了半天。太菜了。 正当我以为 我改完了 应该对了的时候发现 只对了连个样例 ,开始了漫长思考人生之路 。
回过头来 我这个思路有很多bug的地方 直接举个例子 :如果尾节点有10个 你这个程序会认为没有交集 因为你无法确定哪个是你要的尾节点 除非你把尾节点做一个数组 然后根据是否跟首节点有链接 来对数组排个序 不过你还是不能完全解决这个题目 因为 题目可能给你很多 无效节点 一个节点的前驱节点可能有很多个
(不止两个) 你也无法找到你的哪个前驱节点是有效的 所以 从后面往前找是非常的不好找的 。 于是我们换个思路
题目给了首地址 我们可以尝试按照首地址从前往后找 这个才是关键。
因为头节点一旦确定 那么我只要在这个头节点开始遍历一下把遍历到的都标记一下,那么这就是有效节点 。
然后我们再思考思考 正向标记节点 跟找 后缀有什么关系 如果后缀相同
那么我从第二个头节点开始标记的节点能确定已经被第一个头节点开始标记的话,那么这个节点就属于后缀。
简单的说 第一个链表开始标记他的节点并做记录 然后第二个链表开始标记的时候
遇到的第一个已经被标记了节点 那么这个节点就是后缀的开始。然后把这个节点输出就行
如果第二个链表遍历完了都没遇到已经被标记过的 那么就说明没有共同后缀。
输出-1
emmm中途我还遇到了 许多 低级错误导致的样例没过的情况
我tm还能再菜一点? 写在这里警示自己吧
for(;cur!=-1;cur=node[cur].next) 这是对的!!!
while(node[cur].next!=-1) 这是错的!!!
因为后者少了对当前的判断 如果一进来就是-1 那么就越界了。
#include<stdio.h>
struct Node{
int next=-3;
bool infirst=false;
}node[100000];
int main()
{
int first,second,nums;scanf("%d%d%d",&first,&second,&nums);
int cur=first;
while(nums--)
{
int address,next;
scanf("%d %*c %d",&address,&next);
node[address].next=next;
}
while(node[cur].next!=-1)//ÎÒ²»ÊÇβ½Úµãʱ
{
node[cur].infirst=true;
cur=node[cur].next;
}
node[cur].infirst=true;//β½Úµã ¸³Öµ
cur=second;
bool flag=false;
while(cur!=-1)//µ±Ç°½Úµã ²»ÊÇ-1
{
if(node[cur].infirst!=true)
cur=node[cur].next;//
else//cur dengyu jiaodian
{
break;
}
}
if(cur!=-1) printf("%05d\n",cur);
else printf("-1");
return 0;
}















 235
235

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









