






1.HashMap1.7的简单原理实现(看图说话)
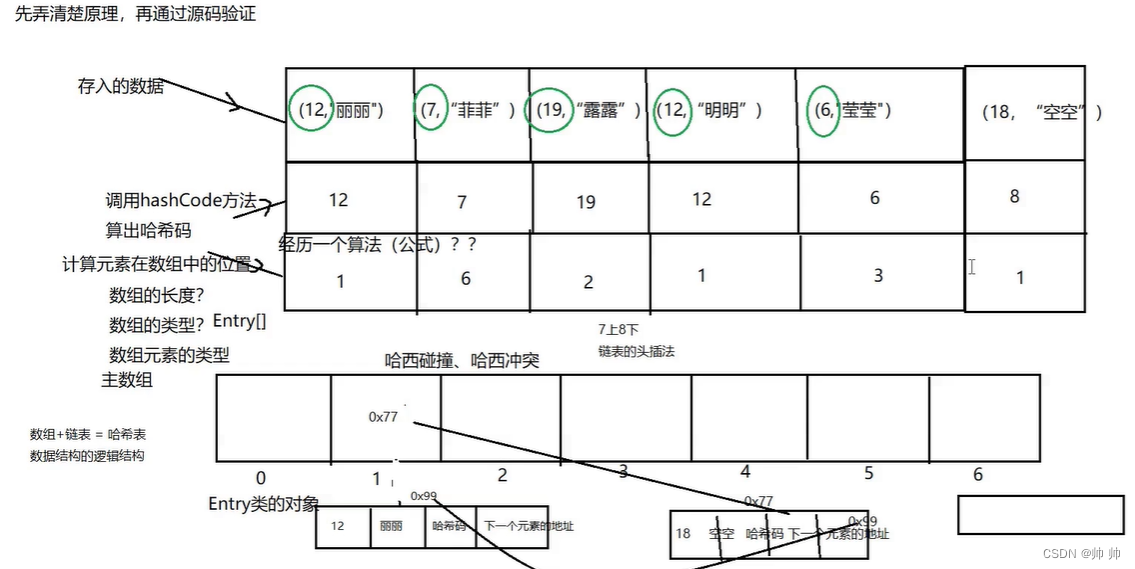
由图可以看出:
- HashMap是entry<K,V>[]数组,每一个结点包含了k,v,hashCode,以及下一个元素的地址
- 每个元素的位置通过key值算出hash值,然后通过hash算法算出在数组中的位置
- hash冲突:算出来的地址在同一个地址就会引发hash冲突,于是变成链表,并且头插法插入
- hashMap底层就是哈希表结构=数组+链表
2.hashMap源码中几个重要的属性
public class hashMap<K,V> extends AbstractMap<K,V>
implement Map<K,V>,Clonbale,Serializble{
//重要属性
- static final int default_initial_capacity=16;定义了一个16,待会赋值给数组长度
- static final int maximum_capacity=1<<30:定义了一个很大很大的数
- static final float default_load_factor=0.75f;定义了一个值0.75:负载因子
- transient entry<k,v>[];底层主数组
- transient int size;元素的数量;
- int threshold;定义了一个变量,没赋值默认值0==》用来表示数组拓容的边界值
- float final LoadFactor;用来接收负载因子
}
3.hash的构造器
//构造器 public HashMap(){ //this(数组初始长度:16,负载因子:0.75) this(DEAFAULT_INITIAL_CAPACITY,DEFAULT_LOAD_FACTOR) } //带参构造器 public HashMap(int initialCapacity,float loadfactor){ //capacity最终结果一定是2的n次幂 int capatity=1; while(capacity<initialCapacity){ //乘以2 capacity<<1; //确定了负载因子为0.75 this.loadFactor=loadFactor; //确定了数组拓容阈值为capacity*loadFactor=16*0.75=12 threshold=(int)Math.min(capacity*loadFactor,maxiMum_capacity+1) //数组初始长度为16 table=new Entry<K,V>[capacity] } }
4.hashMap的put方法以及拓容

- 先根据k获取Hash码hash(key) {
//最大程度保证hash不冲突
}
- 根据hash和数组长度计算位置

等效于对h对length取余(),但与运算效率更高
- 进入for循环执行put方法
如果该位置没有元素,那么直接put不进去for循环

如果该位置有元素了,那么替换value,不替换key
- 数组的拓容
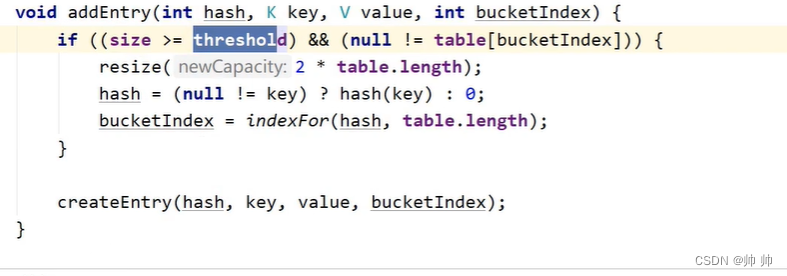
如果size大于阈值并且size里的元素不为空,那么进行2倍拓容,将老数组的数据放入新数组,再将新数组数据给老数组table=newTable;

5.HashMap经典面试题
















 7万+
7万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









