






mysql自定义变量及案例(排名)
利用SQL语句将值存储在用户自定义变量中,然后再利用另一条SQL语句来查询用户自定义变量。这样以来,可以再不同的SQL间传递值。
用户自定义变量的声明方法形如:@var_name.
用户自定义变量是会话级别的变量。其变量的作用域仅限于声明其的客户端链接。当这个客户端断开时,其所有的会话变量将会被释放。
用户自定义变量是不区分大小写的。
使用 SET 语句来声明用户自定义变量:
SET @curRank := 0;
使用 子查询来声明用户自定义变量:
(SELECT @curRank :=1) a
在MySQL中实现Rank高级排名函数
使用MySQL数据库中的基本查询语句来查询普通排名,可以达到Rank函数一样的高级排名效果。
我们先创建一个我们需要进行高级排名查询的employee表,
CREATE TABLE `employee` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`name` varchar(20) DEFAULT NULL,
`salary` int(11) DEFAULT NULL,
`d_id` int(11) DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=8 DEFAULT CHARSET=utf8mb4 COMMENT='员工';
INSERT INTO `employee` (`id`, `name`, `salary`,`d_id`) VALUES
(1, 'Samual', 2500, 1),
(2, 'Vino', 2000,1),
(3, 'John', 2000,1),
(4, 'Andy', 2200,1),
(5, 'Brian', 2100,2),
(6, 'Dew', 2400,2),
(7, 'Kris', 2500,1),
(8, 'William', 2600,1),
(9, 'George', 2300,2),
(10, 'Peter', 1900,2),
(11, 'Tom', 2000,2),
(12, 'Andre', 2000,1);
1、在MySQL中实现Rank普通排名函数
在这里,我们希望获得一个排名字段的列,以及salary的升序排列。所以我们的查询语句将是:
SELECT id, name, salary, @curRank := @curRank + 1 AS rank
FROM employee e, (SELECT @curRank := 0) q
ORDER BY salary
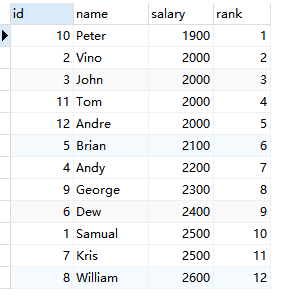
要在mysql中声明一个变量,你必须在变量名之前使用@符号。FROM子句中的(@curRank := 0)部分允许我们进行变量初始化,而不需要单独的SET命令。当然,也可以使用SET,但它会处理两个查询:
SET @curRank := 0;
SELECT id, name, salary, @curRank := @curRank + 1 AS rank
FROM employee ORDER BY salary
2、查询以降序排列
首要按salary的降序排列,其次按name进行排列,只需修改查询语句加上ORDER BY和 DESC以及列名即可。
SELECT id, name, salary, @curRank := @curRank + 1 AS rank
FROM employee e, (SELECT @curRank := 0) q ORDER BY salary DESC, name
3、在MySQL中实现Rank普通并列排名函数
现在,如果我们希望为并列数据的行赋予相同的排名,则意味着那些在排名比较列中具有相同值的行应在MySQL中计算排名时保持相同的排名(例如在我们的例子中的salary)。为此,我们使用了一个额外的变量。
SELECT id, name, salary,
CASE
WHEN @prevRank = salary THEN @curRank
WHEN @prevRank := salary THEN @curRank := @curRank + 1
END AS rank
FROM employee e,
(SELECT @curRank :=0, @prevRank := NULL) r
ORDER BY salary
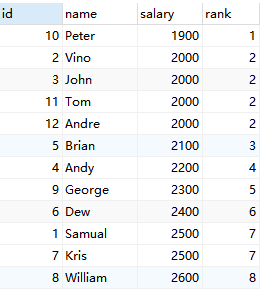
如上所示,具有相同数据和排行的两行或多行,它们都会获得相同的排名。玩家Andre, Vino, John 和Tom都有相同的salary,所以他们排名并列第二。下一个最高salary的玩家(Brian)排名第3。这个查询相当于MySQL和ORACLE 中的DENSE_RANK()函数。
4、在MySQL中实现Rank高级并列排名函数
当使用RANK()函数时,如果两个或以上的行排名并列,则相同的行都会有相同的排名,但是实际排名中存在有关系的差距。
SELECT id, name, salary, rank FROM
(SELECT id, name, salary,
@curRank := IF(@prevRank = salary, @curRank, @incRank) AS rank,
@incRank := @incRank + 1,
@prevRank := salary
FROM employee e, (
SELECT @curRank :=0, @prevRank := NULL, @incRank := 1
) r
ORDER BY salary) s
这是一个查询中的子查询。我们使用三个变量(@incRank,@prevRank,@curRank)来计算关系的情况下,在查询结果中我们已经补全了因为并列而导致的排名空位。我们已经封闭子查询到查询。这个查询相当于MySQL和ORACLE中的RANK()函数。

在这里我们可以看到,Andre,Vino,John和Tom都有相同的age,所以他们排名并列第二。下一个最高年龄的球员(Brian)排名第6,而不是第3,因为有4个人并列排名在第2。
在MySQL中实现多个部门实现分组排名
我们再插入一个department表:
CREATE TABLE `department` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`name` varchar(20) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=5 DEFAULT CHARSET=utf8mb4 COMMENT='部门;
INSERT INTO `department` (`id`, `name`) VALUES
(1, '销售'),
(2, '财务');
找出每个部门获得前三高工资的所有员工:
SELECT
d.name department, t.name employee, salary
FROM
( SELECT
*, @curRank := IF(@pId = d_id, IF(@pS = salary, @curRank, @curRank + 1 ), 1 ) AS 'rank',
@pId := d_id,
@pS := salary
FROM
employee, ( SELECT @pS := NULL, @pId := NULL, @curRank := 0 ) init
ORDER BY
d_id, salary DESC ) t
JOIN department d ON t.d_id = d.id
WHERE
t.rank <=3
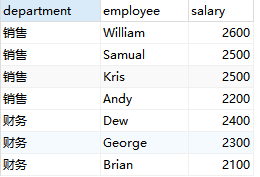
好的,我希望在这些例子后,能让你了解RANK()和DENSE_RANK()之间的区别,并且知道在哪里应使用哪个查询来获取MySQL中的rank函数。谢谢。
参考:https://www.jianshu.com/p/bb1b72a1623e














 3796
3796











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









