







本文记录了自己工作中遇到的死锁场景,根据一些资料梳理后整理出来的,设计到多种场景的死锁情况。
注:以下场景隔离级别均为默认的Repeatable Read;
1. 行锁导致死锁
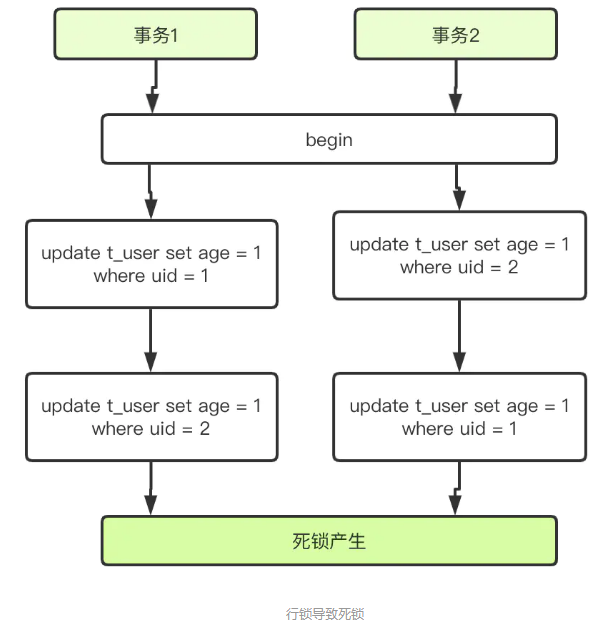
死锁原因详解:
- 两个事务执行过程时间上有交集,并且过程发生在两者提交之前
- 事务1更新uid=1的记录,事务2更新uid=2的记录,在RR级别,由于uid是唯一索引,因此两个事务将分别持有uid=1和2所在行的独占锁
- 事务1执行到第二条更新语句时,发现uid=2的行被锁住,进入阻塞等待锁释放;
- 事务2执行到第二条语句时发现uid=1的行被锁,同样进入阻塞
- 两个事务互相等待,死锁产生。
2. gap lock/next keys lock导致死锁


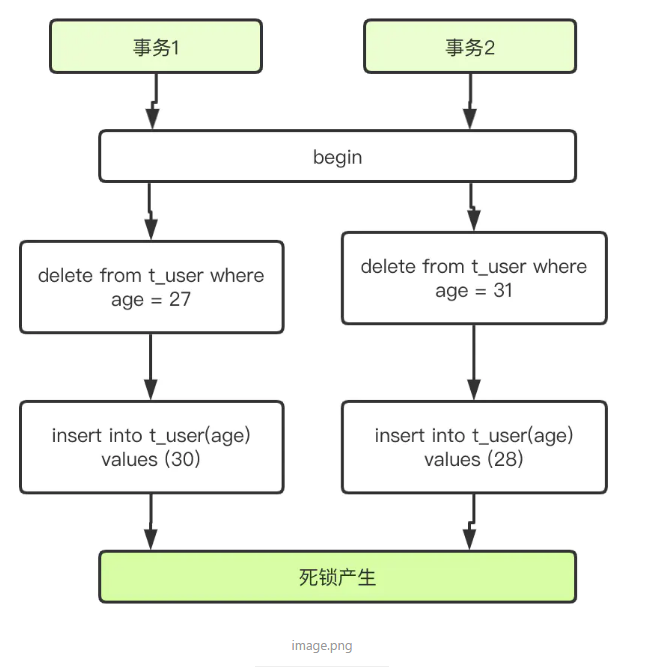
死锁原因分析:
- 事务1执行delete age = 27,务2执行delete age = 31,在RR级别,操作条件不是唯一索引时,行锁会升级为next keys lock(可以理解为间隙锁),因此事务1锁住了25到27和27到29的区间,事务2锁住了29到31的区间
- 事务1执行insert age = 30,等待事务2释放锁
- 事务2执行insert age = 28,等待事务1释放锁
- 死锁产生,死锁日志显示lock_mode X locks gap before rec insert intention waiting
3、index merge导致死锁
t_user结构改造为:

场景复现操作(几率不高):
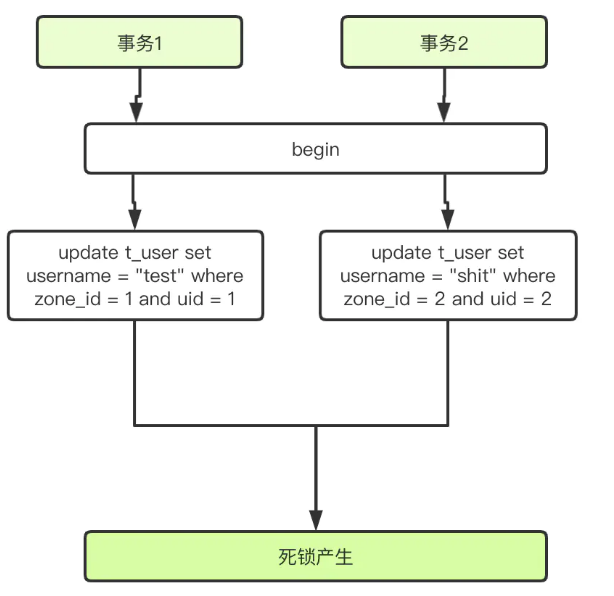
假设存在以下数据:
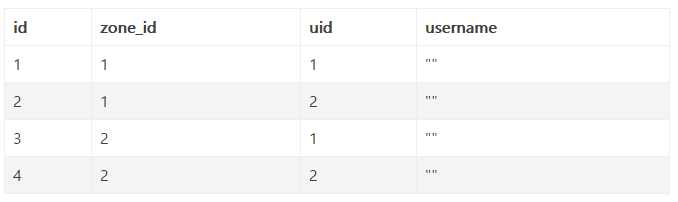
死锁分析:
- 在符合场景前提的情况下(即表数据量较大,index_merge未关闭),通过explain分析update t_user where zone_id = 1 and uid = 1可以发现type是index_merge,即会用到zone_id和uid两个索引
- 上锁的过程为:
事务1:
① 锁住zone_id=1对应的间隙锁: zoneId in (1,2)
② 锁住索引zone_id=1对应的主键索引行锁id = [1,2]
③ 锁住uid=1对应的间隙锁: uid in (1, 2)
④ 锁住uid=1对应的主键索引行锁: id = [1, 3]
事务2:
① 锁住zone_id=2对应的间隙锁: zoneId in (1,2)
② 锁住索引zone_id=2对应的主键索引行锁id = [3,4]
③ 锁住uid=2对应的间隙锁: uid in (1, 2)
④ 锁住uid=2对应的主键索引行锁: id = [2, 4]
- 如果两个事务上锁的顺序相反,则有一定的概率出现死锁。另外,index_merge的形式锁住了很多不符合条件的行,浪费了资源。一般死锁日志打印的信息为:lock_mode X locks rec but not gap waiting Record lock
注:
update table set name = "wea" where col_1 = 1 or col_2 = 2 ;
col_1和col_2为联合索引,遵循最左原则col_1会走索引,但col_2会对整个索引进行扫描,此时会对整个索引加锁。
4、唯一索引冲突导致死锁
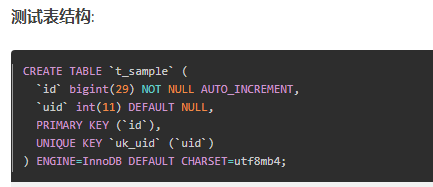
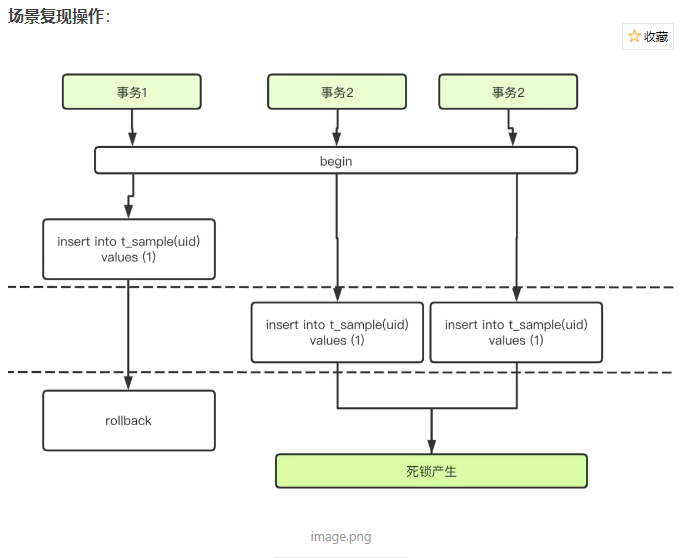
死锁分析:
- 三个事务分别尝试插入uid=1的数据,其中事务1先于后两个事务
- 由于是唯一索引,所以后两个事务会出现唯一键冲突,但是事务1并未立即提交,因此不会报错,而是将事务一insert的隐式锁升级为显式锁
- 事务二和事务三为了判断是否出现唯一键冲突,必须进行一次当前读(select...lock in share mode),加的锁是GAP S锁,所以进入阻塞,等待事务一释放锁
- 事务一回滚,此时事务二和事务三成功获取记录上的GAP S锁,并继续执行插入操作
- 插入则需要依次请求插入意向锁,而插入意向锁和GAP S锁冲突,因此两个事务相互等待,形成死锁















 331
331

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









