






GBDT算法梳理
1.前向分布算法
考虑加法模型
 在给定训练数据及损失函数L(y,f(x))的条件下, 学习加法模型f(x)
在给定训练数据及损失函数L(y,f(x))的条件下, 学习加法模型f(x)
称为经验极小化即损失函数极小化问题:
 上述问题是一个复杂的优化问题. 前向分布算法(forward stagewise algorithm)求解这一优化问题的想法是: 因为学习的是加法模型, 如果能够从前向后,每一步只学习一个基函数及其系数,逐步逼近优化目标函数,那么就可以简化优化的复杂度. 也就是说前向分布算法将同时求解从m=1到M所有参数/beta_m,/gamma_m的优化问题简化为逐次求解各个/beta_m,/gamma_m的优化问题. 下图为前向分布算法
上述问题是一个复杂的优化问题. 前向分布算法(forward stagewise algorithm)求解这一优化问题的想法是: 因为学习的是加法模型, 如果能够从前向后,每一步只学习一个基函数及其系数,逐步逼近优化目标函数,那么就可以简化优化的复杂度. 也就是说前向分布算法将同时求解从m=1到M所有参数/beta_m,/gamma_m的优化问题简化为逐次求解各个/beta_m,/gamma_m的优化问题. 下图为前向分布算法

2.负梯度拟合
在上述模型中, 我们得到损失函数为
L
(
y
,
f
(
x
)
)
L(y,f(x))
L(y,f(x)), 那么如何优化损失函数呢? 提升树利用加法模型与前向分步算法实现学习的优化过程. 当损失函数是拼房损失和指数损失函数是, 每一步优化是简单的. 但对一般损失函数, 往往每一步优化并不容易, 针对这一问题, Friedman提出梯度提升, 即利用损失函数的负梯度作为当前模型的值作为残差的近似值, 这样就能保证迭代过程中损失函数不断减小.
利用损失函数的负梯度在当前模型的值

作为回归问题提升树算法中残差的近似值,拟合一个回归树.
3.损失函数
针对不同的提升树算法,损失函数的选取也是不同的.
二分类问题中的损失函数
1.0-1损失函数
2.指数损失函数
L
(
y
,
f
(
x
)
)
=
e
−
y
f
(
x
)
L(y,f(x))=e^{-yf(x)}
L(y,f(x))=e−yf(x)
3.均方损失函数
回归问题中的损失函数
1.均方损失函数
L
(
y
,
f
(
x
)
)
=
[
y
−
f
(
x
)
]
2
L(y,f(x))=[y-f(x)]^2
L(y,f(x))=[y−f(x)]2
2.绝对损失函数
L
(
y
,
f
(
x
)
)
=
∣
y
−
f
(
x
)
∣
L(y,f(x))=|y-f(x)|
L(y,f(x))=∣y−f(x)∣
4.回归
回归问题的提升树算法:

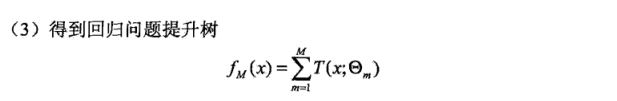
当采用平方误差损失函数时,
L
(
y
,
f
(
x
)
)
=
(
y
−
f
(
x
)
)
2
L(y,f(x))=(y-f(x))^2
L(y,f(x))=(y−f(x))2其损失变为
L
(
y
,
f
m
−
1
(
x
)
+
T
(
x
;
Θ
m
)
)
=
[
r
−
T
(
x
;
Θ
m
)
]
2
L(y,f_{m-1}(x)+T(x;\Theta_m))=[r-T(x;\Theta_m)]^2
L(y,fm−1(x)+T(x;Θm))=[r−T(x;Θm)]2 这里
r
=
y
=
f
m
−
1
(
x
)
r=y=f_{m-1}(x)
r=y=fm−1(x)是当前模型拟合数据的残差.
5.二分类,多分类
GBDT分类算法:由于样本输出不是连续的值,而是离散的类别,导致我们无法直接从输出类别去拟合类别输出的误差
主要有两个方法 :
1)指数损失函数,此时GBDT退化为Adaboost算法
2)用类似于逻辑回归的对数似然损失函数的方法
二元分类
用类似于逻辑回归的对数似然损失函数,则损失函数为: L ( y , f ( x ) ) = l o g ( 1 + e − y f ( x ) ) L(y,f(x))=log(1+e^{-yf(x)}) L(y,f(x))=log(1+e−yf(x))其中 y ∈ { − 1 , 1 } y\in\{-1,1\} y∈{−1,1}.此时的负梯度误差为: r t i = − [ ∂ L ( y , f ( x i ) ) ∂ f ( x i ) ] f ( x ) = f t − 1 ( x ) = y i 1 + e − y i f ( x i ) r_{ti}=-[\frac{\partial L(y,f(x_i))}{\partial f(x_i)}]_{f(x)=f_{t-1}(x)} =\frac{y_i}{1+e^{-y_if(x_i)}} rti=−[∂f(xi)∂L(y,f(xi))]f(x)=ft−1(x)=1+e−yif(xi)yi对于生成的决策树, 我们各个叶子节点的最佳负梯度拟合值为: c t j = a r g m i n c ∑ x i ∈ R t j l o g ( 1 + e − y i [ f t − 1 ( x i ) + c ] ) c_{tj}=argmin_c\sum_{x_i\in R_{tj}}log(1+e^{-y_i[f_{t-1}(x_i)+c]}) ctj=argmincxi∈Rtj∑log(1+e−yi[ft−1(xi)+c])除了负梯度计算和叶子节点的最佳负梯度拟合的线性搜索, 二元GBDT分类和回归算法过程相同.
多元分类
假设类别数为K, 则此时对数似然损失函数为: L ( y , f ( x ) ) = − ∑ k = 1 K y k l o g p k ( x ) L(y,f(x))=-\sum_{k=1}^{K} y_k log p_k(x) L(y,f(x))=−k=1∑Kyklogpk(x)其中, 如果样本输出类别为k, 则 y k = 1 y_k=1 yk=1. 第k类的概率 p k ( x ) p_k(x) pk(x)的表达式为: p k ( x ) = e f k ( x ) ∑ l = 1 K e f l ( x ) p_k(x)=\frac{e^{f_k(x)}}{\sum_{l=1}^{K}e^{f_l(x)}} pk(x)=∑l=1Kefl(x)efk(x)这样就可以计算出第t轮第i个样本对应类别 l l l的负梯度误差.这里的误差就是样本 i i i对应类别 l l l的真实概率和 t − 1 t-1 t−1轮预测概率的差值. 除了负梯度计算和叶子结点的最佳负梯度拟合的线性搜索, 多元GBDT分类和二元GBDT算法过程相同.
6.GBDT的正则化
一般的, 我们需要对GBDT进行正则化, 防止过拟合问题. GBDT正则化主要有三种方式:
1.加入与Adaboost类似的正则化项, 即步长或者称作learning rate.
2.通过子采样比例(subsample), 这里的子采样是不放回抽样.
3.对于弱学习器, 即CART回归树进行正则化剪枝.
7.优缺点
优点:
- 预测精度高
- 适合低维数据
- 能处理非线性数据
- 可以灵活处理各种类型的数据,包括连续值和离散值.
- 在相对少的调参时间情况下,预测的准备率也可以比较高。这个是相对SVM来说的.
- 使用一些健壮的损失函数,对异常值的鲁棒性非常强。比如 Huber损失函数和Quantile损失函数.
缺点:
- 由于弱学习器之间存在依赖关系,难以并行训练数据。不过可以通过自采样的SGBT来达到部分并行.
- 如果数据维度较高时会加大算法的计算复杂度
8.sklearn参数

因基分类器是决策树,所以很多参数都是用来控制决策树生成的,这些参数与前面决策树参数基本一致,对于一致的就不进行赘述.
- loss:损失函数度量,有对数似然损失deviance和指数损失函数exponential两种,默认是deviance,即对数似然损失,如果使用指数损失函数,则相当于Adaboost模型.
- criterion: 样本集的切分策略,决策树中也有这个参数,但是两个参数值不一样,这里的参数值主要有friedman_mse、mse和mae3个,分别对应friedman最小平方误差、最小平方误差和平均绝对值误差,friedman最小平方误差是最小平方误差的近似.
- subsample:采样比例,这里的采样和bagging的采样不是一个概念,这里的采样是指选取多少比例的数据集利用决策树基模型去boosting,默认是1.0,即在全量数据集上利用决策树去boosting.
- warm_start:“暖启动”,默认值是False,即关闭状态,如果打开则表示,使用先前调试好的模型,在该模型的基础上继续boosting,如果关闭,则表示在样本集上从新训练一个新的基模型,且在该模型的基础上进行boosting.
9.应用场景
GBDT几乎可用于所有回归问题(线性/非线性), 相对logistic regression仅能用于线性回归,GBDT的适用面非常广。亦可用于二分类问题(设定阈值,大于阈值为正例,反之为负例)。















 1236
1236











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









