







最近公司要求爬虫实现爬取指定网页的数据。我使用的htmlunit+jsoup 完成爬取网页数据,
个人感觉htmlunit 比较简单,容易理解,易上手操作。
步骤如下:
<dependency>
<groupId>net.sourceforge.htmlunit</groupId>
<artifactId>htmlunit</artifactId>
</dependency>
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>RELEASE</version>
</dependency>
然后创建爬取数据对象,并设置对象参数,如下代码,代码注释解释相应的参数作用,
WebClient webClient = new WebClient(BrowserVersion.CHROME); //设置模拟浏览器内核,就如打开相应的浏览器一样
webClient.getOptions().setThrowExceptionOnScriptError(false); //当JS执行出错的时候是否抛出异常
webClient.getOptions().setThrowExceptionOnFailingStatusCode(false); //当请求状态不是200时是否抛出异常信息
webClient.getOptions().setActiveXNative(false);
webClient.getOptions().setRedirectEnabled(true);//是否跳转页面
webClient.getCookieManager().setCookiesEnabled(true);//开启cookie管理
webClient.getOptions().setUseInsecureSSL(true);//忽略ssl认证
webClient.getOptions().setCssEnabled(false);//设置是否启用css
webClient.getOptions().setJavaScriptEnabled(true);//设置是否启用JavaScript
webClient.setAjaxController(new NicelyResynchronizingAjaxController());//设置支持Ajax
webClient.getOptions().setTimeout(timeOut); //设置“浏览器”的请求超时时间
webClient.setJavaScriptTimeout(waitForJavaScript); //设置JS执行的超时时间
HttpWebConnection httpwebconnection = new HttpWebConnection(webClient);
webClient.setWebConnection(httpwebconnection);
接着放入需要爬取网页的链接HtmlPage page = webClient.getPage("你的链接")
最后就是操作返回的HtmlPage 对象,里面就有相应获取标签的方法如下部分截图
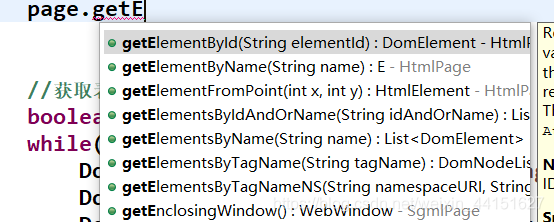
包括模拟页面点击:如下截图
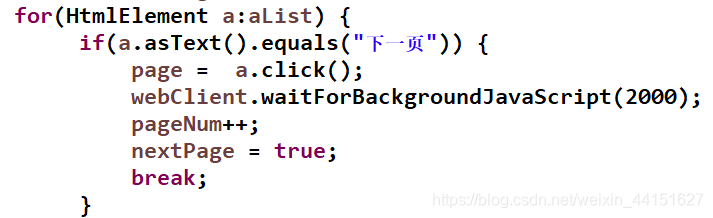
也可以执行页面js函数方法

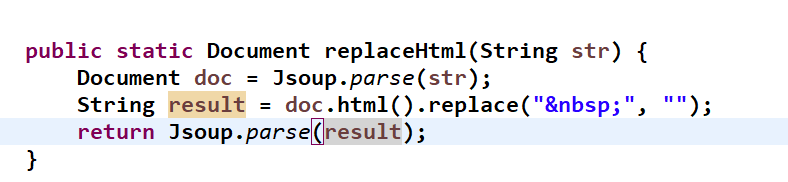
jsoup 可以将转换页面文档对象等操作
此文仅是个人在使用htmlunit 过程中的简单理解,特此记录下。














 617
617











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









