







1、前言
PageHelper是mybatis 提供的分页插件,通过PageHelper.startPage(pageNo,pageLimit)就可以帮我们实现分页,目前支持Oracle,Mysql,MariaDB,SQLite,Hsqldb,PostgreSQL六种数据库。
pom依赖:
<dependency>
<groupId>com.github.pagehelper</groupId>
<artifactId>pagehelper</artifactId>
<version>5.3.1</version>
</dependency>
yml配置:
pagehelper:
helperDialect: mysql #数据库类型,不指定的话会解析 datasource.url进行配置
supportMethodsArguments: true
params: count=countSql
使用示例:
@Service
public class UserService {
@Autowired
private UserMapper userMapper;
/**
* 依据用户昵称进行模糊分页查询
*
* @param name
* @param page
* @param limit
* @return
*/
public PageInfo<User> findPageUsersByName(String name, int page, int limit) {
PageHelper.startPage(page, limit);
List<User> users = userMapper.selectByName(name);
PageInfo<User> pageUsers = new PageInfo<>(users);
return pageUsers;
}
}
2、基本流程
1、PageHelper向 Mybatis 注册处理分页和 count 的拦截器 PageInterceptor
2、通过 PageHelper.startPage() 方法把分页相关的参数放到 ThreadLcoal 中
3、Mybatis 执行 SQL 过程中会调用拦截器
- 3.1、根据查询 SQL 构建 count SQL
- 3.2、从 ThreadLcoal 拿出分页信息,在查询 SQL 后面拼接 limit ?, ?
- 3.3、清空 ThreadLcoal
4、 使用 Page 创建 PageInfo 对象
3、源码分析
3.1、存储分页参数
直接看PageHelper.startPage,startPage() 方法会构建一个 Page 对象,存储分页相关的参数、设置,最后调用 setLocalPage(page),将其放入ThreadLocal。由于ThreadLocal 每次查询后都会被remove掉,所以一次mapper查询对应一次PageHelper.startPage。
ThreadLocal原理可以看这篇ThreadLocal源码及其内存泄漏问题
public static <E> Page<E> startPage(int pageNum, int pageSize, boolean count, Boolean reasonable, Boolean pageSizeZero) {
Page<E> page = new Page(pageNum, pageSize, count);
page.setReasonable(reasonable);
page.setPageSizeZero(pageSizeZero);
Page<E> oldPage = getLocalPage();
if (oldPage != null && oldPage.isOrderByOnly()) {
page.setOrderBy(oldPage.getOrderBy());
}
setLocalPage(page);
return page;
}
3.2、改造SQL
PageInterceptor 实现了 org.apache.ibatis.plugin.Interceptor 接口,MyBatis 底层查询其实就是借助SqlSession调用Executor#query,mybatis 在执行查询方法的时候(method = “query”)会调用本拦截器。
/**
* Mybatis - 通用分页拦截器
*/
@SuppressWarnings({"rawtypes", "unchecked"})
@Intercepts(
{
@Signature(type = Executor.class, method = "query", args = {MappedStatement.class, Object.class, RowBounds.class, ResultHandler.class}),
@Signature(type = Executor.class, method = "query", args = {MappedStatement.class, Object.class, RowBounds.class, ResultHandler.class, CacheKey.class, BoundSql.class}),
}
)
public class PageInterceptor implements Interceptor {
// 默认为 Pagehelper
private volatile Dialect dialect;
// count 方法的后缀
private String countSuffix = "_COUNT";
// count 查询的缓存,只用于
// 本例中 key 为 com.example.pagehelper.dao.UserMapper.selectUsers_COUNT
protected Cache<String, MappedStatement> msCountMap = null;
//
private String default_dialect_class = "com.github.pagehelper.PageHelper";
...
}
进入PageInterceptor.intercept()方法,
@Override
public Object intercept(Invocation invocation) throws Throwable {
try {
// 获取方法参数
Object[] args = invocation.getArgs();
MappedStatement ms = (MappedStatement) args[0];
Object parameter = args[1];
RowBounds rowBounds = (RowBounds) args[2];
ResultHandler resultHandler = (ResultHandler) args[3];
Executor executor = (Executor) invocation.getTarget();
CacheKey cacheKey;
BoundSql boundSql;
//由于逻辑关系,只会进入一次
if (args.length == 4) {
//4 个参数时
// 拿到原始的查询 SQL
boundSql = ms.getBoundSql(parameter);
cacheKey = executor.createCacheKey(ms, parameter, rowBounds, boundSql);
} else {
//6 个参数时
cacheKey = (CacheKey) args[4];
boundSql = (BoundSql) args[5];
}
checkDialectExists();
//对 boundSql 的拦截处理
// 实际什么都没做,原样返回了
if (dialect instanceof BoundSqlInterceptor.Chain) {
boundSql = ((BoundSqlInterceptor.Chain) dialect).doBoundSql(BoundSqlInterceptor.Type.ORIGINAL, boundSql, cacheKey);
}
List resultList;
//调用方法判断是否需要进行分页,如果不需要,直接返回结果
if (!dialect.skip(ms, parameter, rowBounds)) {
//判断是否需要进行 count 查询
if (dialect.beforeCount(ms, parameter, rowBounds)) {
// 查询总数
// 见 PageInterceptor.count()
Long count = count(executor, ms, parameter, rowBounds, null, boundSql);
//处理查询总数,返回 true 时继续分页查询,false 时直接返回
if (!dialect.afterCount(count, parameter, rowBounds)) {
//当查询总数为 0 时,直接返回空的结果
return dialect.afterPage(new ArrayList(), parameter, rowBounds);
}
}
// 执行分页查询
resultList = ExecutorUtil.pageQuery(dialect, executor,
ms, parameter, rowBounds, resultHandler, boundSql, cacheKey);
} else {
//rowBounds用参数值,不使用分页插件处理时,仍然支持默认的内存分页
resultList = executor.query(ms, parameter, rowBounds, resultHandler, cacheKey, boundSql);
}
// 将count、分页 信息放入 ThreadLocal
return dialect.afterPage(resultList, parameter, rowBounds);
} finally {
if(dialect != null){
dialect.afterAll();
}
}
}
count
PageInterceptor.count()
private Long count(Executor executor, MappedStatement ms, Object parameter,
RowBounds rowBounds, ResultHandler resultHandler,
BoundSql boundSql) throws SQLException {
// countMsId = "com.example.pagehelper.dao.UserMapper.selectUsers_COUNT"
String countMsId = ms.getId() + countSuffix;
Long count;
//先判断是否存在手写的 count 查询
MappedStatement countMs = ExecutorUtil.getExistedMappedStatement(ms.getConfiguration(), countMsId);
if (countMs != null) {
// 直接执行手写的 count 查询
count = ExecutorUtil.executeManualCount(executor, countMs, parameter, boundSql, resultHandler);
} else {
// 先从缓存中查
if (msCountMap != null) {
countMs = msCountMap.get(countMsId);
}
// 缓存中没有,然后自动创建,并放入缓存
if (countMs == null) {
//根据当前的 ms 创建一个返回值为 Long 类型的 ms
countMs = MSUtils.newCountMappedStatement(ms, countMsId);
if (msCountMap != null) {
// 放入缓存
msCountMap.put(countMsId, countMs);
}
}
// 执行 count 查询
count = ExecutorUtil.executeAutoCount(this.dialect, executor, countMs, parameter,
boundSql, rowBounds, resultHandler);
}
return count;
}
ExecutorUtil.executeAutoCount()
public static Long executeAutoCount(Dialect dialect, Executor executor, MappedStatement countMs,
Object parameter, BoundSql boundSql,
RowBounds rowBounds, ResultHandler resultHandler) throws SQLException {
Map<String, Object> additionalParameters = getAdditionalParameter(boundSql);
//创建 count 查询的缓存 key
CacheKey countKey = executor.createCacheKey(countMs, parameter, RowBounds.DEFAULT, boundSql);
//调用方言获取 count sql:SELECT count(0) FROM user
// 见 PageHelper.getCountSql()
String countSql = dialect.getCountSql(countMs, boundSql, parameter, rowBounds, countKey);
//countKey.update(countSql);
BoundSql countBoundSql = new BoundSql(countMs.getConfiguration(), countSql, boundSql.getParameterMappings(), parameter);
//当使用动态 SQL 时,可能会产生临时的参数,这些参数需要手动设置到新的 BoundSql 中
for (String key : additionalParameters.keySet()) {
countBoundSql.setAdditionalParameter(key, additionalParameters.get(key));
}
//对 boundSql 的拦截处理
if (dialect instanceof BoundSqlInterceptor.Chain) {
countBoundSql = ((BoundSqlInterceptor.Chain) dialect).doBoundSql(BoundSqlInterceptor.Type.COUNT_SQL, countBoundSql, countKey);
}
//执行 count 查询
Object countResultList = executor.query(countMs, parameter, RowBounds.DEFAULT, resultHandler, countKey, countBoundSql);
Long count = (Long) ((List) countResultList).get(0);
return count;
}
3.3、分页查询
ExecutorUtil.pageQuery
public static <E> List<E> pageQuery(Dialect dialect, Executor executor, MappedStatement ms, Object parameter,
RowBounds rowBounds, ResultHandler resultHandler,
BoundSql boundSql, CacheKey cacheKey) throws SQLException {
//判断是否需要进行分页查询
if (dialect.beforePage(ms, parameter, rowBounds)) {
//生成分页的缓存 key
CacheKey pageKey = cacheKey;
//处理参数对象
parameter = dialect.processParameterObject(ms, parameter, boundSql, pageKey);
//调用方言获取分页 sql,这里是重点,是添加 limit 的地方
// pageSql = select id, name from user LIMIT ?, ?
String pageSql = dialect.getPageSql(ms, boundSql, parameter, rowBounds, pageKey);
BoundSql pageBoundSql = new BoundSql(ms.getConfiguration(), pageSql, boundSql.getParameterMappings(), parameter);
Map<String, Object> additionalParameters = getAdditionalParameter(boundSql);
//设置动态参数
for (String key : additionalParameters.keySet()) {
pageBoundSql.setAdditionalParameter(key, additionalParameters.get(key));
}
//对 boundSql 的拦截处理
if (dialect instanceof BoundSqlInterceptor.Chain) {
pageBoundSql = ((BoundSqlInterceptor.Chain) dialect).doBoundSql(BoundSqlInterceptor.Type.PAGE_SQL, pageBoundSql, pageKey);
}
//执行分页查询
return executor.query(ms, parameter, RowBounds.DEFAULT, resultHandler, pageKey, pageBoundSql);
} else {
//不执行分页的情况下,也不执行内存分页
return executor.query(ms, parameter, RowBounds.DEFAULT, resultHandler, cacheKey, boundSql);
}
}
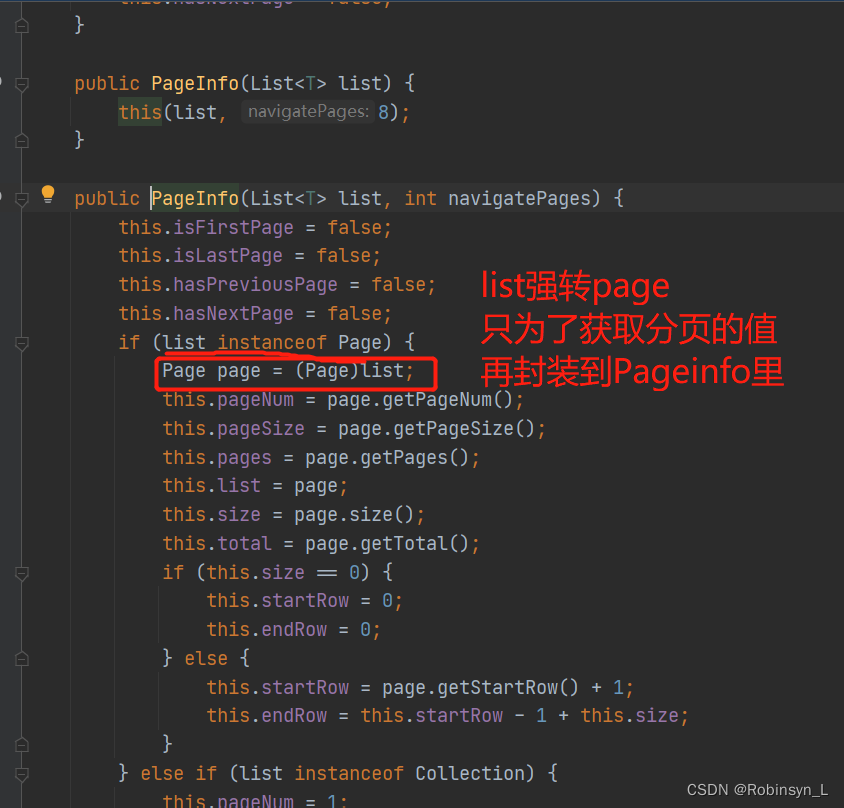
3.4、使用 Page 创建 PageInfo 对象
最后使用PageInfo<User> pageUsers = new PageInfo<>(users)获取到分页信息














 1910
1910











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









